Dit artikel is gepubliceerd als onderdeel van de Data Science Blogathon.
- Overzicht
- Voorwaarden voor dit artikel:
- INLEIDING
- Probleem met de lineaire lijn:
- Waarom gebruiken we `Mean Squared Error’ niet als kostenfunctie in Logistische Regressie?
- Wat is logverlies?
- Wat zijn de gecorrigeerde kansen?
- De voordelen van het nemen van de logaritme openbaren zich als je kijkt naar de kostenfunctiegrafieken voor de werkelijke klasse 1 en 0 :
Overzicht
-
Uitdagingen als we het lineaire regressiemodel gebruiken om een classificatieprobleem op te lossen.
-
Waarom wordt MSE niet gebruikt als kostenfunctie in Logistische Regressie?
-
In dit artikel wordt de wiskunde achter de logverliesfunctie behandeld aan de hand van een eenvoudig voorbeeld.
Voorwaarden voor dit artikel:
-
Lineaire regressie
-
Logistische regressie
-
Gradient Descent
INLEIDING
`De winter is aangebroken`. Laten we de winter verwelkomen met een warm data science probleem 😉
Laten we een case study nemen van een kledingbedrijf dat jassen en vesten maakt. Ze willen een model hebben dat kan voorspellen of de klant een jas (klasse 1) of een vest(klasse 0) zal kopen op basis van hun historisch gedragspatroon, zodat ze specifieke aanbiedingen kunnen geven op basis van de behoeften van de klant. Als data scientist moet je hen helpen om een voorspellend model te bouwen.
Wanneer we beginnen met Machine Learning algoritmen, is het eerste algoritme waar we over leren `Lineaire Regressie` waarin we een continue doelvariabele voorspellen.
Als we lineaire regressie gebruiken in ons classificatieprobleem, krijgen we een best-fit lijn zoals deze:
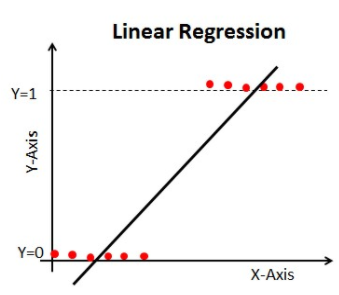
Z = ßX + b
Probleem met de lineaire lijn:
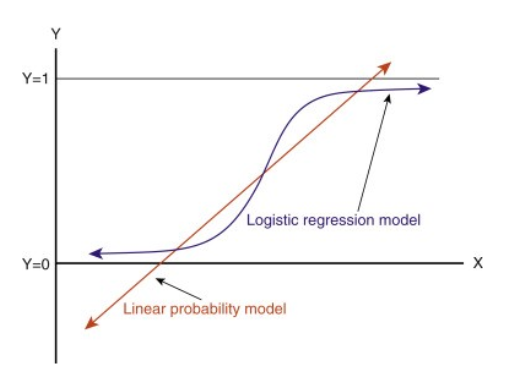
Als u deze lijn doortrekt, krijgt u waarden groter dan 1 en kleiner dan 0, die niet veel zin hebben in ons classificatieprobleem. Het zal een model interpretatie een uitdaging maken. Dat is waar `Logistische Regressie` om de hoek komt kijken. Als we de verkoop van een verkooppunt moesten voorspellen, dan zou dit model nuttig kunnen zijn. Maar hier moeten we klanten classificeren.
-We hebben een functie nodig om deze rechte lijn zo te transformeren dat de waarden tussen 0 en 1 liggen:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (Sigmoid-functie)
Ŷ =1/1+ e-z
-Na transformatie krijgen we een lijn die tussen 0 en 1 blijft. Een ander voordeel van deze functie is dat alle continue waarden die we krijgen tussen 0 en 1 liggen, wat we kunnen gebruiken als een waarschijnlijkheid om voorspellingen te doen. Als de voorspelde waarde bijvoorbeeld uiterst rechts ligt, zal de waarschijnlijkheid dicht bij 1 liggen en als de voorspelde waarde uiterst links ligt, zal de waarschijnlijkheid dicht bij 0 liggen.
Het juiste model selecteren is niet voldoende. U hebt een functie nodig die de prestaties van een Machine Learning-model voor gegeven gegevens meet. De kostenfunctie kwantificeert de fout tussen de voorspelde waarden en de verwachte waarden.
`Als je het niet kunt meten, kun je het ook niet verbeteren.`
Een ander ding dat met deze transformatie zal veranderen, is de kostenfunctie. Bij lineaire regressie gebruiken we de `gemiddelde kwadratische fout` voor de kostenfunctie, gegeven door:-
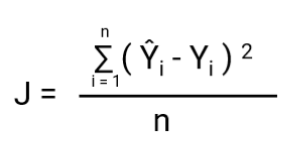
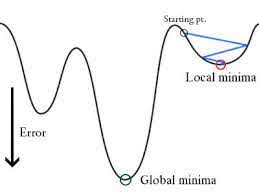
en wanneer deze foutfunctie wordt uitgezet tegen de gewichtsparameters van het lineaire regressiemodel, vormt deze een convexe curve, waardoor deze in aanmerking komt om het Gradient Descent Optimalisatiealgoritme toe te passen om de fout te minimaliseren door globale minima te vinden en de gewichten aan te passen.
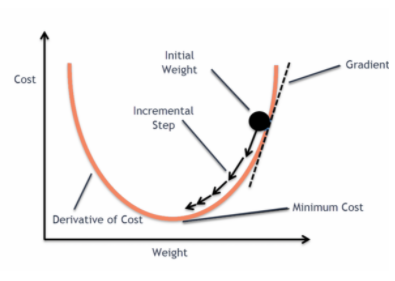
Waarom gebruiken we `Mean Squared Error’ niet als kostenfunctie in Logistische Regressie?
In Logistische Regressie is Ŷi een niet-lineaire functie(Ŷ=1/1+ e-z), als we dit in de bovenstaande MSE-vergelijking plaatsen, geeft dit een niet-convexe functie zoals weergegeven:
-
Wanneer we proberen waarden te optimaliseren met behulp van gradiëntafdaling, zal dit complicaties opleveren bij het vinden van globale minima.
-
Een andere reden is dat we bij classificatieproblemen streefwaarden als 0/1 hebben, dus (Ŷ-Y)2 zal altijd tussen 0-1 liggen, waardoor het erg moeilijk kan zijn om fouten bij te houden en het moeilijk is om hoge-precisie drijvende getallen op te slaan.
De kostenfunctie die bij logistische regressie wordt gebruikt, is logverlies.
Wat is logverlies?
Logverlies is de belangrijkste classificatiemetriek op basis van waarschijnlijkheden. Het is moeilijk om ruwe log-loss waarden te interpreteren, maar log-loss is nog steeds een goede metric voor het vergelijken van modellen. Voor een gegeven probleem betekent een lagere log-loss waarde betere voorspellingen.
Mathematische interpretatie:
Log Loss is het negatieve gemiddelde van de log van gecorrigeerde voorspelde kansen voor elke instantie.
Laten we het begrijpen met een voorbeeld:
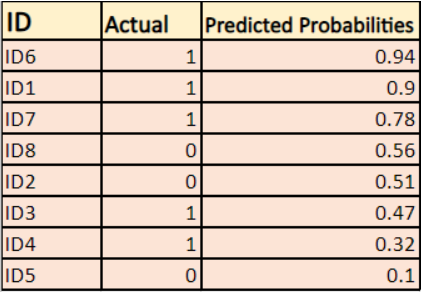
Het model geeft voorspelde kansen zoals hierboven getoond.
Wat zijn de gecorrigeerde kansen?
-> Standaard is de output van het logistische regressiemodel de kans dat de steekproef positief is (aangegeven met 1), d.w.z. als een logistisch regressiemodel is getraind om te classificeren op een `bedrijfsdataset`, dan zegt de voorspelde kans-kolom Wat is de kans dat de persoon een jasje heeft gekocht. Hier in de bovenstaande dataset is de kans dat een persoon met ID6 een jasje koopt 0.94.
Op dezelfde manier is de kans dat een persoon met ID5 een jasje koopt (d.w.z. tot klasse 1 behoort) 0.1 maar de werkelijke klasse voor ID5 is 0, dus de kans voor de klasse is (1-0.1)=0.9. 0.9 is de correcte kans voor ID5.
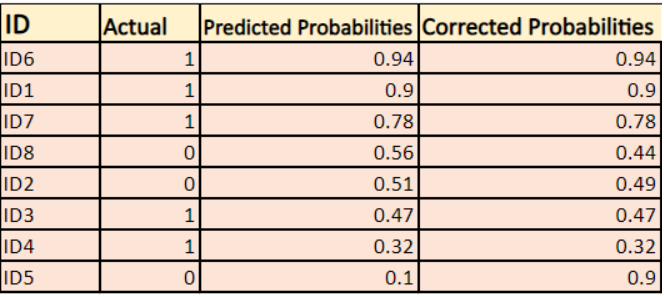
We vinden een log van de gecorrigeerde kansen voor elke instantie.
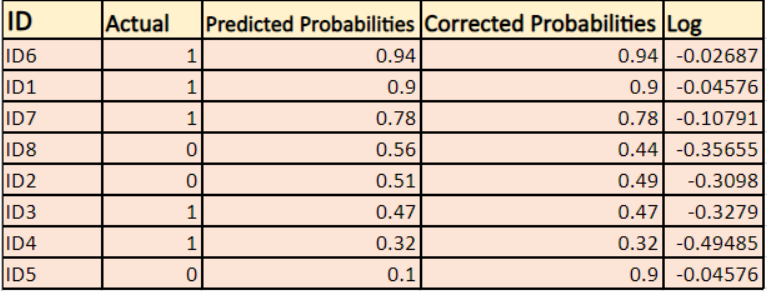
Zoals u kunt zien zijn deze log-waarden negatief. Om met het negatieve teken om te gaan, nemen we het negatieve gemiddelde van deze waarden, om een gemeenschappelijke conventie te behouden dat lagere verliesscores beter zijn.
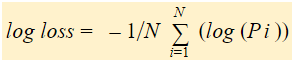
Kortom, er zijn drie stappen om Log Loss te vinden:
-
Om gecorrigeerde waarschijnlijkheden te vinden.
-
Neem een log van de gecorrigeerde waarschijnlijkheden.
-
Neem het negatieve gemiddelde van de waarden die we in de tweede stap hebben verkregen.
Als we alle bovenstaande stappen samenvatten, kunnen we de volgende formule gebruiken:-
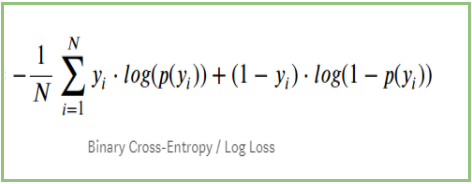
Hierin stelt Yi de werkelijke klasse voor en log(p(yi)is de waarschijnlijkheid van die klasse.
-
p(yi) is de kans op 1.
-
1-p(yi) is de kans op 0.
Nu eens kijken hoe de bovenstaande formule in twee gevallen werkt:
-
Wanneer de werkelijke klasse 1 is: tweede term in de formule zou 0 zijn en we houden de eerste term over, d.w.z. yi.log(p(yi)) en (1-1).log(1-p(yi) dit zal 0 zijn.
-
Wanneer de werkelijke klasse 0 is: Eerste-term zou 0 zijn en zal overblijven met de tweede term d.w.z. (1-yi).log(1-p(yi)) en 0.log(p(yi)) zal 0 zijn.
wauw!!! we zijn terug bij de oorspronkelijke formule voor binaire cross-entropie/log verlies 🙂
De voordelen van het nemen van de logaritme openbaren zich als je kijkt naar de kostenfunctiegrafieken voor de werkelijke klasse 1 en 0 :
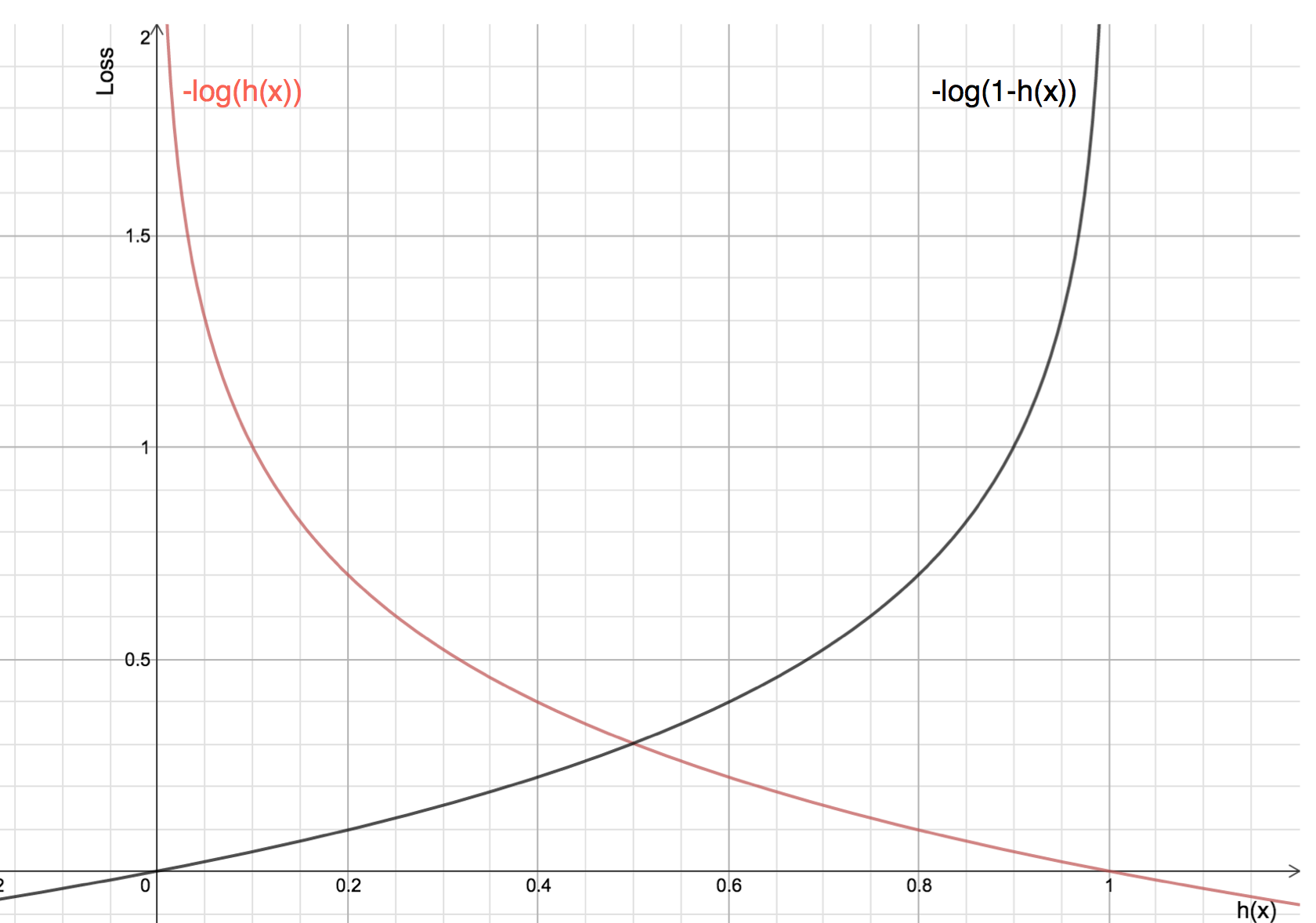
-
De rode lijn vertegenwoordigt de klasse 1. Zoals we kunnen zien, is het verlies kleiner wanneer de voorspelde waarschijnlijkheid (x-as) dicht bij 1 ligt en wanneer de voorspelde waarschijnlijkheid dicht bij 0 ligt, nadert het verlies oneindig.
-
De zwarte lijn vertegenwoordigt de 0-klasse. Zoals we kunnen zien, is het verlies kleiner wanneer de voorspelde waarschijnlijkheid (x-as) dicht bij 0 ligt en wanneer de voorspelde waarschijnlijkheid dicht bij 1 ligt, nadert het verlies oneindig.