Cet article a été publié dans le cadre du Blogathon Data Science.
- Overview
- Prérequis pour cet article:
- INTRODUCTION
- Problème avec la ligne linéaire:
- Pourquoi n’utilisons-nous pas `l’erreur quadratique moyenne comme fonction de coût dans la régression logistique ?
- Qu’est-ce que la perte logarithmique ?
- Quelles sont les probabilités corrigées?
- Les avantages de prendre le logarithme se révèlent lorsque vous regardez les graphiques de la fonction de coût pour la classe réelle 1 et 0 :
Overview
-
Défis si nous utilisons le modèle de régression linéaire pour résoudre un problème de classification.
-
Pourquoi MSE n’est pas utilisé comme fonction de coût dans la régression logistique ?
-
Cet article couvrira les mathématiques derrière la fonction de perte logarithmique avec un exemple simple.
Prérequis pour cet article:
-
Régression linéaire
-
Régression logistique
-
Descente de gradient
INTRODUCTION
`L’hiver est là`. Accueillons les hivers avec un problème de science des données chaleureux 😉
Prenons l’étude de cas d’une entreprise de vêtements qui fabrique des vestes et des cardigans. Ils veulent avoir un modèle qui peut prédire si le client va acheter une veste (classe 1) ou un cardigan(classe 0) à partir de leur modèle comportemental historique afin de pouvoir donner des offres spécifiques en fonction des besoins du client. En tant que data scientist, vous devez les aider à construire un modèle prédictif.
Lorsque nous commençons les algorithmes d’apprentissage automatique, le premier algorithme que nous apprenons est la `Régression linéaire` dans laquelle nous prédisons une variable cible continue.
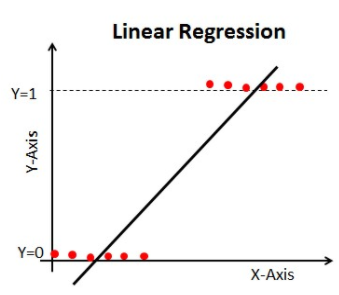
Si nous utilisons la régression linéaire dans notre problème de classification, nous obtiendrons une ligne de meilleur ajustement comme ceci:
Z = ßX + b
Problème avec la ligne linéaire:
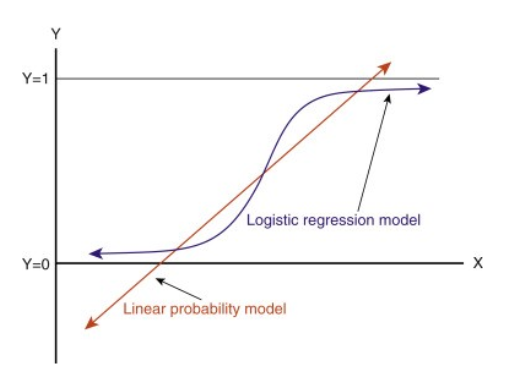
Lorsque vous étendez cette ligne, vous aurez des valeurs supérieures à 1 et inférieures à 0, qui n’ont pas beaucoup de sens dans notre problème de classification. Cela fera de l’interprétation d’un modèle un défi. C’est là que la `Régression logistique` entre en jeu. Si nous avions besoin de prédire les ventes d’un point de vente, alors ce modèle pourrait être utile. Mais ici, nous avons besoin de classer les clients.
-Nous avons besoin d’une fonction pour transformer cette ligne droite de telle sorte que les valeurs seront comprises entre 0 et 1:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (Fonction Sigmoïde)
Ŷ =1/1+ e-z
-Après transformation, nous obtiendrons une ligne qui reste entre 0 et 1. Un autre avantage de cette fonction est que toutes les valeurs continues que nous obtiendrons seront comprises entre 0 et 1, ce que nous pouvons utiliser comme probabilité pour faire des prédictions. Par exemple, si la valeur prédite est à l’extrême droite, la probabilité sera proche de 1 et si la valeur prédite est à l’extrême gauche, la probabilité sera proche de 0.
Sélectionner le bon modèle n’est pas suffisant. Vous avez besoin d’une fonction qui mesure la performance d’un modèle de Machine Learning pour des données données données. La fonction de coût quantifie l’erreur entre les valeurs prédites et les valeurs attendues.
`Si vous ne pouvez pas le mesurer, vous ne pouvez pas l’améliorer.`
-Une autre chose qui va changer avec cette transformation est la fonction de coût. Dans la régression linéaire, nous utilisons `l’erreur quadratique moyenne` pour la fonction de coût donnée par:-
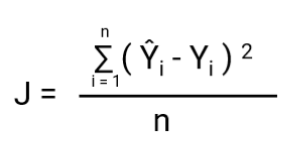
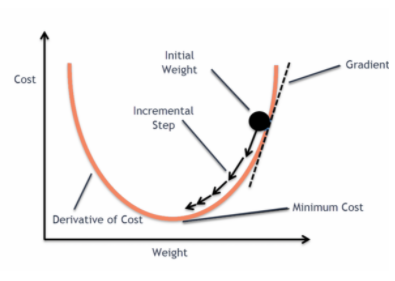
et lorsque cette fonction d’erreur est tracée par rapport aux paramètres de poids du modèle de régression linéaire, elle forme une courbe convexe qui la rend éligible pour appliquer l’algorithme d’optimisation de descente de gradient pour minimiser l’erreur en trouvant les minima globaux et en ajustant les poids.
Pourquoi n’utilisons-nous pas `l’erreur quadratique moyenne comme fonction de coût dans la régression logistique ?
Dans la régression logistique Ŷi est une fonction non linéaire(Ŷ=1/1+ e-z), si nous mettons cela dans l’équation MSE ci-dessus, cela donnera une fonction non convexe comme indiqué :
-
Lorsque nous essayons d’optimiser les valeurs en utilisant la descente de gradient, cela créera des complications pour trouver les minima globaux.
-
Une autre raison est que dans les problèmes de classification, nous avons des valeurs cibles comme 0/1, Donc (Ŷ-Y)2 sera toujours entre 0-1 ce qui peut rendre très difficile le suivi des erreurs et il est difficile de stocker des nombres flottants de haute précision.
La fonction de coût utilisée dans la régression logistique est la perte logarithmique.
Qu’est-ce que la perte logarithmique ?
La perte logarithmique est la plus importante métrique de classification basée sur les probabilités. Il est difficile d’interpréter les valeurs brutes de log-loss, mais le log-loss reste une bonne métrique pour comparer les modèles. Pour tout problème donné, une valeur de perte log plus faible signifie de meilleures prédictions.
Interprétation mathématique:
La perte log est la moyenne négative du log des probabilités prédites corrigées pour chaque instance.
Comprenons-la avec un exemple:
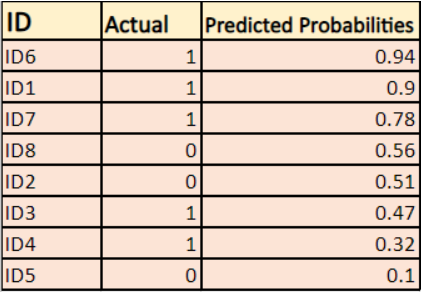
Le modèle donne des probabilités prédites comme indiqué ci-dessus.
Quelles sont les probabilités corrigées?
-> Par défaut, la sortie du modèle de régression logistique est la probabilité que l’échantillon soit positif(indiqué par 1) c’est-à-dire que si un modèle de régression logistique est entraîné à classer sur un `ensemble de données d’entreprise` alors la colonne de probabilité prédite dit Quelle est la probabilité que la personne ait acheté une veste. Ici, dans l’ensemble de données ci-dessus, la probabilité qu’une personne avec ID6 achète une veste est de 0,94.
De la même manière, la probabilité qu’une personne avec ID5 achète une veste (c’est-à-dire qu’elle appartienne à la classe 1) est de 0,1 mais la classe réelle pour ID5 est 0, donc la probabilité pour la classe est (1-0,1)=0,9. 0,9 est la probabilité correcte pour ID5.
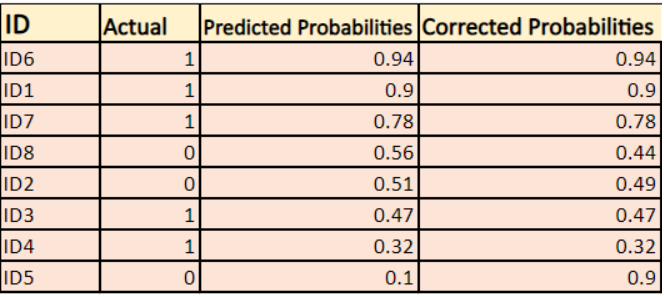
Nous allons trouver un log des probabilités corrigées pour chaque instance.
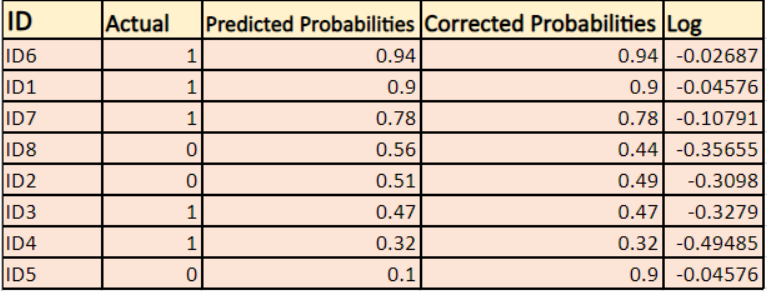
Comme vous pouvez le voir ces valeurs log sont négatives. Pour traiter le signe négatif, nous prenons la moyenne négative de ces valeurs, pour maintenir une convention commune selon laquelle des scores de perte plus faibles sont meilleurs.
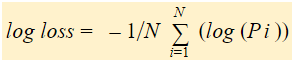
En bref, il y a trois étapes pour trouver la perte logarithmique:
-
Pour trouver les probabilités corrigées.
-
Prendre un log des probabilités corrigées.
-
Prendre la moyenne négative des valeurs que l’on obtient à la 2e étape.
Si nous résumons toutes les étapes ci-dessus, nous pouvons utiliser la formule:-
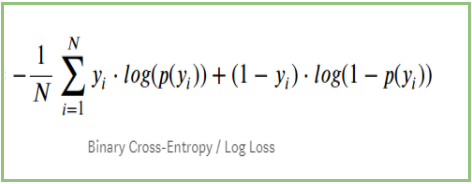
Ici Yi représente la classe réelle et log(p(yi)est la probabilité de cette classe.
-
p(yi) est la probabilité de 1.
-
1-p(yi) est la probabilité de 0.
Maintenant, voyons comment fonctionne la formule ci-dessus dans deux cas :
-
Lorsque la classe réelle est 1 : le deuxième terme de la formule serait 0 et il nous restera le premier terme c’est-à-dire yi.log(p(yi)) et (1-1).log(1-p(yi) ce sera 0.
-
Lorsque la classe réelle est 0 : Le premier terme serait 0 et il restera le second terme c’est-à-dire (1-yi).log(1-p(yi)) et 0.log(p(yi)) ce sera 0.
wow ! !! nous sommes revenus à la formule originale de l’entropie croisée binaire/log perte 🙂
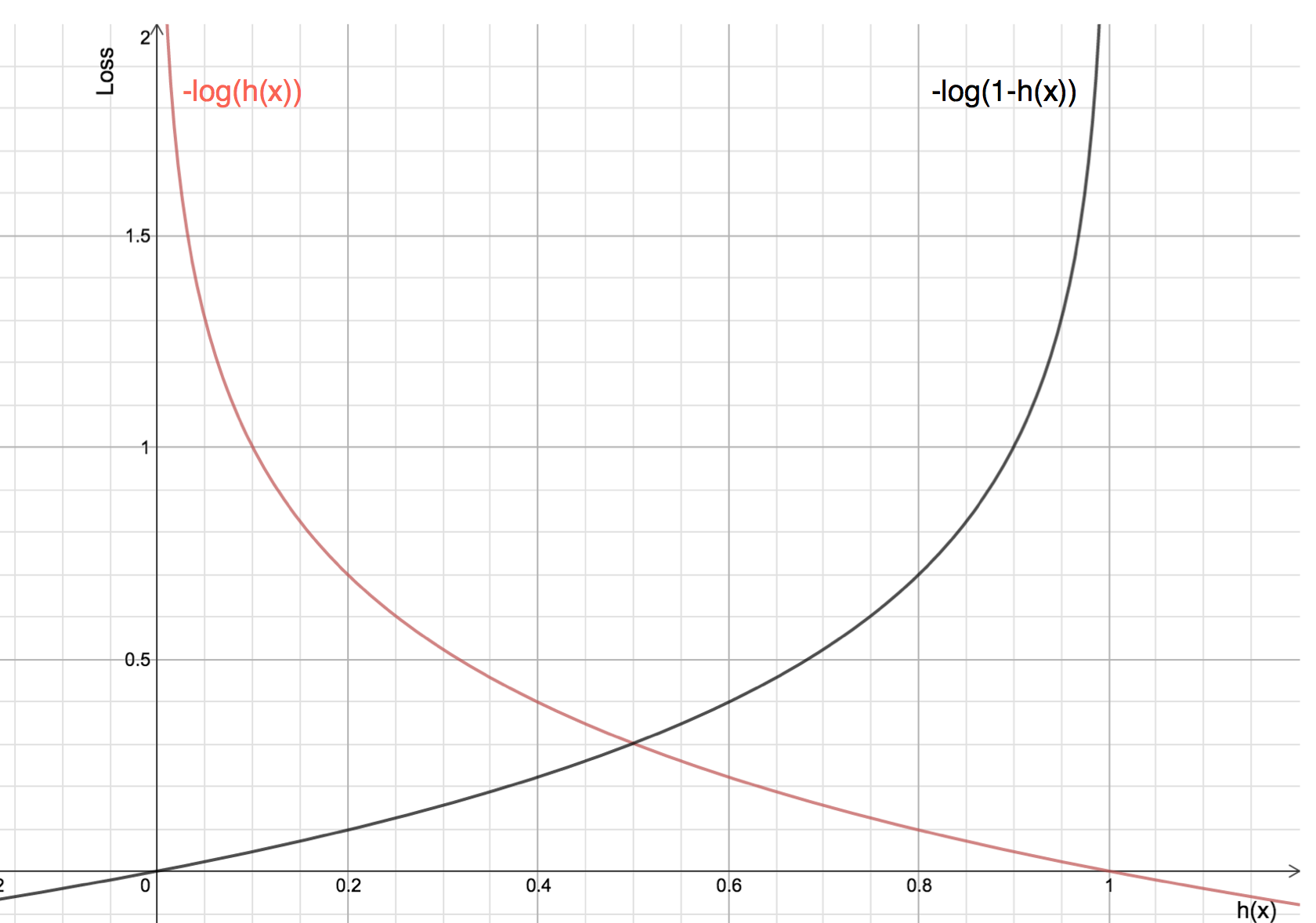
Les avantages de prendre le logarithme se révèlent lorsque vous regardez les graphiques de la fonction de coût pour la classe réelle 1 et 0 :
-
La ligne rouge représente la classe 1. Comme nous pouvons le voir, lorsque la probabilité prédite (axe des abscisses) est proche de 1, la perte est moindre et lorsque la probabilité prédite est proche de 0, la perte s’approche de l’infini.
-
La ligne noire représente 0 classe. Comme nous pouvons le voir, lorsque la probabilité prédite (axe des x) est proche de 0, la perte est moindre et lorsque la probabilité prédite est proche de 1, la perte s’approche de l’infini.
.