Tämä artikkeli julkaistiin osana Data Science Blogathonia.
- Yleiskatsaus
- Edellytykset tälle artikkelille:
- ESITTELY
- Problematiikka lineaarisen viivan kanssa:
- Miksi emme käytä `Mean Squared Error -kustannusfunktiota logistisessa regressiossa?
- Mikä on Log Loss?
- Mitkä ovat korjatut todennäköisyydet?
- Logaritmin ottamisen hyödyt paljastuvat, kun tarkastellaan kustannusfunktion kuvaajia todellisille luokille 1 ja 0 :
Yleiskatsaus
-
Haasteita, jos käytämme lineaarista regressiomallia luokitusongelman ratkaisemiseen.
-
Miksi MSE:tä ei käytetä kustannusfunktiona logistisessa regressiossa?
-
Tässä artikkelissa käsitellään Log Loss -funktion taustalla olevaa matematiikkaa yksinkertaisen esimerkin avulla.
Edellytykset tälle artikkelille:
-
Lineaarinen regressio
-
Logistinen regressio
-
Gradientti laskeutuminen
ESITTELY
`Talvi on täällä`. Toivotetaan talvi tervetulleeksi lämpimällä datatieteen ongelmalla 😉
Vastaanotetaan tapaustutkimus vaatetusyrityksestä, joka valmistaa takkeja ja neuletakkeja. He haluavat mallin, joka pystyy ennustamaan, ostaako asiakas takin (luokka 1) vai villatakin(luokka 0) heidän historiallisen käyttäytymismallinsa perusteella, jotta he voivat antaa erityisiä tarjouksia asiakkaan tarpeiden mukaan. Tietotutkijana sinun on autettava heitä rakentamaan ennustava malli.
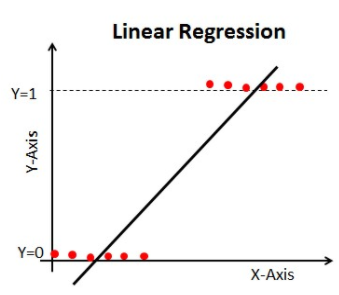
Kun aloitamme koneoppimisen algoritmit, ensimmäinen algoritmi, johon tutustumme, on `Linear Regression`, jossa ennustetaan jatkuvaa kohdemuuttujaa.
Jos käytämme lineaarista regressiota luokitusongelmassamme, saamme tällaisen parhaiten sopivan viivan:
Z = ßX + b
Problematiikka lineaarisen viivan kanssa:
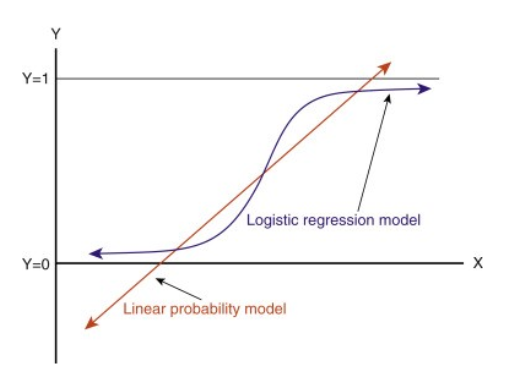
Jatkaessamme tätä viivaa, saamme arvoja, jotka ovat isompia kuin 1 ja pienempiä kuin 0, mikä ei ole luokitusongelmassamme järkevää. Se tekee mallin tulkinnasta haastavaa. Tässä kohtaa `Logistinen regressio` tulee kuvaan mukaan. Jos meidän pitäisi ennustaa myyntipisteen myyntiä, tämä malli voisi olla hyödyllinen. Mutta tässä meidän on luokiteltava asiakkaita.
– Tarvitsemme funktion, joka muuntaa tämän suoran siten, että arvot ovat 0:n ja 1:n välillä:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (Sigmoidi-funktio)
Ŷ =1/1+ e-z
-Transformaation jälkeen saamme suoran, joka pysyy 0:n ja 1:n välissä. Tämän funktion etuna on myös se, että kaikki saamamme jatkuvat arvot ovat 0:n ja 1:n välillä, mitä voimme käyttää todennäköisyytenä ennusteiden tekemisessä. Esimerkiksi jos ennustettu arvo on äärioikealla, todennäköisyys on lähellä 1 ja jos ennustettu arvo on ääri vasemmalla, todennäköisyys on lähellä 0.
Oikean mallin valitseminen ei riitä. Tarvitaan funktio, joka mittaa koneoppimismallin suorituskykyä annetussa datassa. Kustannusfunktio kvantifioi ennustettujen arvojen ja odotettujen arvojen välisen virheen.
`Jos et voi mitata sitä, et voi parantaa sitä.`
-Muutos muuttaa myös kustannusfunktiota. Lineaarisessa regressiossa käytämme `Mean Squared Error` kustannusfunktiota, joka annetaan seuraavasti:-
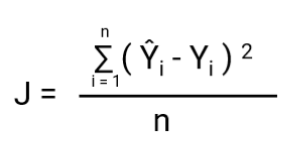
ja kun tämä virhefunktio piirretään lineaarisen regressiomallin painoparametrien suhteen, se muodostaa kuperan käyrän, mikä tekee siitä kelvollisen soveltamaan Gradient Descent Optimization Algorithmia virheen minimoimiseksi etsimällä globaaleja minimejä ja säätämällä painoja.
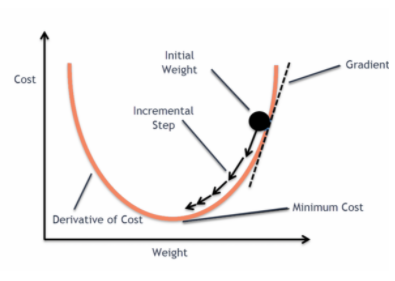
Miksi emme käytä `Mean Squared Error -kustannusfunktiota logistisessa regressiossa?
Logistisessa regressiossa Ŷi on epälineaarinen funktio(Ŷ=1/1+ e-z), jos laitamme tämän yllä olevaan MSE-yhtälöön, saadaan ei-konveksaalinen funktio kuten kuvassa:
-
Kun yritämme optimoida arvoja gradienttilaskeutumisen avulla, syntyy komplikaatioita globaalien minimien löytämisessä.
-
Toinen syy on se, että luokitusongelmissa meillä on tavoitearvoja, kuten 0/1, joten (Ŷ-Y)2 on aina 0-1:n välissä, mikä voi tehdä virheiden seuraamisen hyvin vaikeaksi ja korkean tarkkuuden liukulukujen tallentaminen on vaikeaa.
Logistisessa regressiossa käytetty kustannusfunktio on Log Loss.
Mikä on Log Loss?
Log Loss on tärkein todennäköisyyksiin perustuva luokittelumittari. Log-lossin raakoja arvoja on vaikea tulkita, mutta log-loss on silti hyvä metriikka mallien vertailuun. Minkä tahansa ongelman kohdalla pienempi log Loss -arvo tarkoittaa parempia ennusteita.
Matemaattinen tulkinta:
Log Loss on kunkin tapauksen korjattujen ennustettujen todennäköisyyksien login negatiivinen keskiarvo.
Ymmärtäkäämme sitä esimerkin avulla:
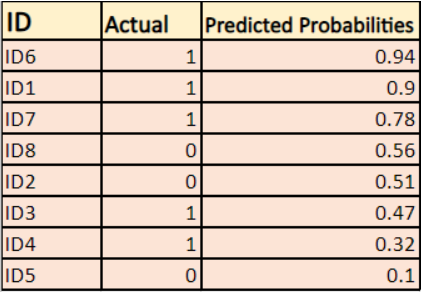
Malli antaa ennustettuja todennäköisyyksiä yllä olevan kuvan mukaisesti.
Mitkä ovat korjatut todennäköisyydet?
-> Oletusarvoisesti logistisen regressiomallin tuloste on todennäköisyys, että otos on positiivinen(merkitään 1:llä) eli jos logistinen regressiomalli koulutetaan luokittelemaan `yritysdatasetilla`, niin ennustettu todennäköisyys -sarake sanoo Mikä on todennäköisyys, että henkilö on ostanut takin. Tässä yllä olevassa aineistossa todennäköisyys sille, että henkilö, jolla on ID6, ostaa takin, on 0.94.
Samoin todennäköisyys sille, että henkilö, jolla on ID5, ostaa takin (eli kuuluu luokkaan 1) on 0.1, mutta ID5:n todellinen luokka on 0, joten luokan todennäköisyys on (1-0.1)=0.9. 0.9 on oikea todennäköisyys ID5:lle.
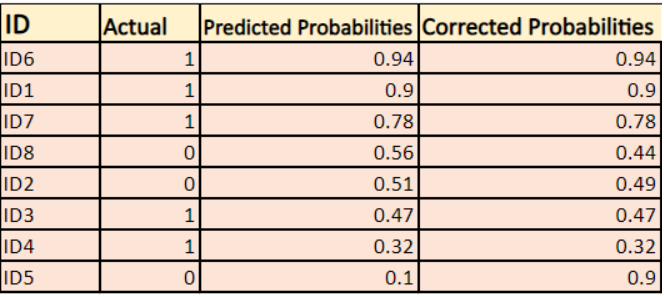
Löydämme kunkin tapauksen korjattujen todennäköisyyksien logaritmin.
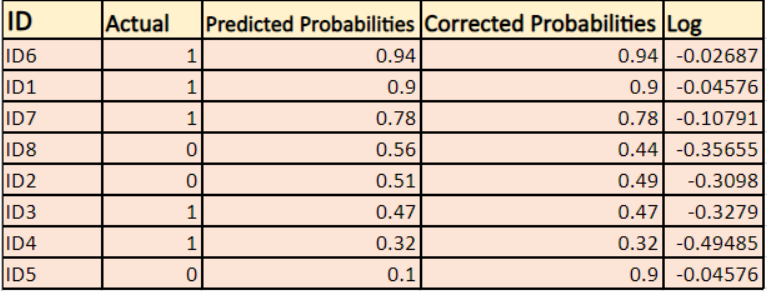
Kuten näet, nämä logaritmin arvot ovat negatiivisia. Negatiivisen merkin käsittelemiseksi otamme näiden arvojen negatiivisen keskiarvon, jotta säilytämme yleisen konvention, jonka mukaan pienemmät tappioarvot ovat parempia.
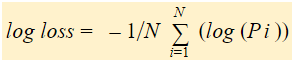
Lyhyesti sanottuna log-häviön löytämiseksi on kolme vaihetta:
-
Korjattujen todennäköisyyksien löytämiseksi.
-
Valitaan korjattujen todennäköisyyksien logaritmi.
-
Voidaan ottaa 2. vaiheessa saatujen arvojen negatiivinen keskiarvo.
Jos teemme yhteenvedon kaikista edellä mainituista vaiheista, voimme käyttää kaavaa:-
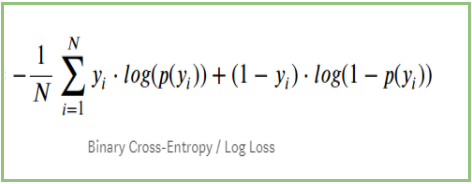
Tässä Yi edustaa todellista luokkaa ja log(p(yi)on kyseisen luokan todennäköisyys.
-
p(yi) on todennäköisyys 1.
-
1-p(yi) on todennäköisyys 0.
Katsotaan nyt, miten yllä oleva kaava toimii kahdessa tapauksessa:
-
Kun varsinainen luokka on 1: kaavan toinen termi olisi 0 ja meille jäisi ensimmäinen termi eli yi.log(p(yi)) ja (1-1).log(1-p(yi) tämä on 0.
-
Kun varsinainen luokka on 0: Ensimmäinen termi olisi 0 ja jäljelle jää toinen termi eli (1-yi).log(1-p(yi)) ja 0.log(p(yi)) on 0.
wow!!! pääsimme takaisin alkuperäiseen kaavaan binäärisen ristiinentropian/log-häviön 🙂
Logaritmin ottamisen hyödyt paljastuvat, kun tarkastellaan kustannusfunktion kuvaajia todellisille luokille 1 ja 0 :
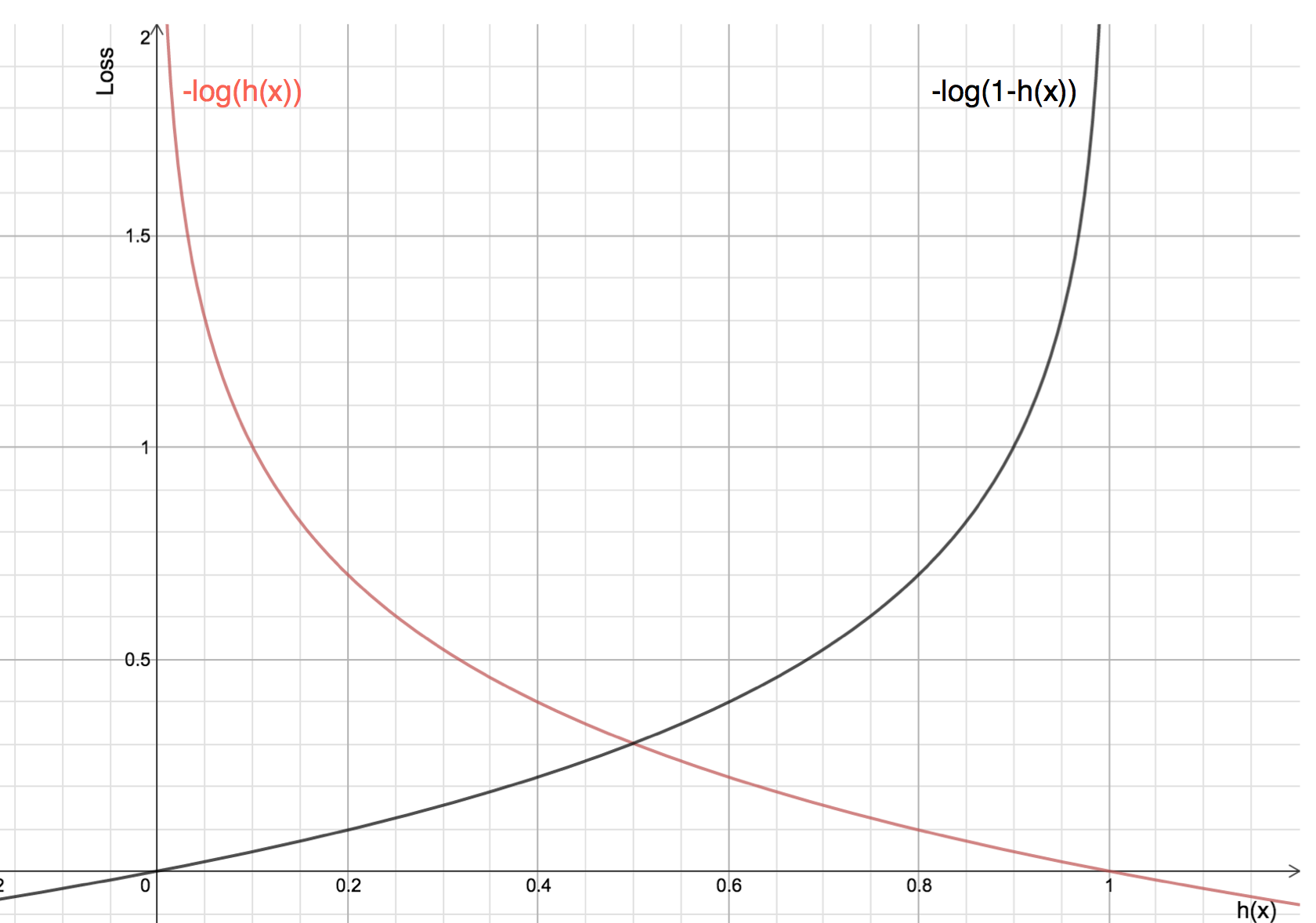
-
Punainen viiva edustaa 1 luokkaa. Kuten näemme, kun ennustettu todennäköisyys (x-akseli) on lähellä 1, tappio on pienempi ja kun ennustettu todennäköisyys on lähellä 0, tappio lähestyy ääretöntä.
-
Musta viiva edustaa 0 luokkaa. Kuten näemme, kun ennustettu todennäköisyys (x-akseli) on lähellä 0, tappio on pienempi ja kun ennustettu todennäköisyys on lähellä 1, tappio lähestyy ääretöntä.