Acest articol a fost publicat în cadrul Data Science Blogathon.
- Overview
- Precondiții pentru acest articol:
- INTRODUCERE
- Problemă cu linia liniară:
- De ce nu folosim `Mean Squared Error ca funcție de cost în Regresia Logistică?
- Ce este Log Loss?
- Care sunt probabilitățile corectate?
- Beneficiile luării logaritmului se dezvăluie atunci când ne uităm la graficele funcției de cost pentru clasa reală 1 și 0 :
Overview
-
Provocări dacă folosim modelul de regresie liniară pentru a rezolva o problemă de clasificare.
-
De ce nu se folosește MSE ca funcție de cost în Regresia Logistică?
-
Acest articol va acoperi matematica din spatele funcției Log Loss cu un exemplu simplu.
Precondiții pentru acest articol:
-
Regresie liniară
-
Regresie logistică
-
Gradient Descent
INTRODUCERE
`A sosit iarna`. Să întâmpinăm iernile cu o problemă caldă de știință a datelor 😉
Să luăm un studiu de caz al unei companii de îmbrăcăminte care produce jachete și cardigane. Aceștia doresc să aibă un model care să poată prezice dacă clientul va cumpăra o jachetă (clasa 1) sau un cardigan(clasa 0) pornind de la modelul comportamental istoric al acestuia, astfel încât să poată oferi oferte specifice în funcție de nevoile clientului. În calitate de cercetător de date, trebuie să îi ajutați să construiască un model predictiv.
Când începem algoritmii de învățare automată, primul algoritm pe care îl învățăm este `Regresia liniară` în care prezicem o variabilă țintă continuă.
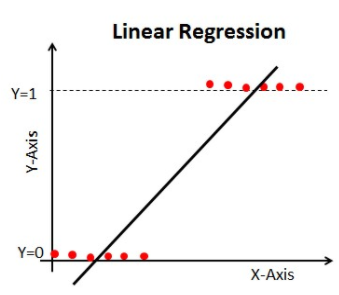
Dacă folosim Regresia Liniară în problema noastră de clasificare, vom obține o linie de cel mai bun ajustament ca aceasta:
Z = ßX + b
Problemă cu linia liniară:
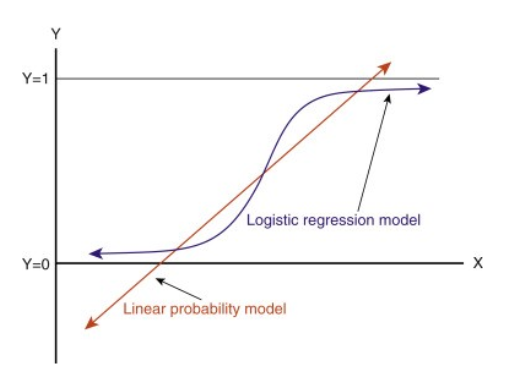
Când prelungiți această linie, veți avea valori mai mari decât 1 și mai mici decât 0, care nu prea au sens în problema noastră de clasificare. Aceasta va face ca interpretarea unui model să fie o provocare. Aici intervine `Regresia logistică`. Dacă am avea nevoie să prezicem vânzările pentru un punct de vânzare, atunci acest model ar putea fi util. Dar aici avem nevoie să clasificăm clienții.
-Avem nevoie de o funcție care să transforme această linie dreaptă în așa fel încât valorile să fie între 0 și 1:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (Funcție Sigmoid)
Ŷ =1/1+ e-z
-După transformare, vom obține o linie care rămâne între 0 și 1. Un alt avantaj al acestei funcții este că toate valorile continue pe care le vom obține vor fi cuprinse între 0 și 1, pe care le putem folosi ca probabilitate pentru a face predicții. De exemplu, dacă valoarea prezisă se află în extrema dreaptă, probabilitatea va fi apropiată de 1, iar dacă valoarea prezisă se află în extrema stângă, probabilitatea va fi apropiată de 0.
Selectarea modelului potrivit nu este suficientă. Aveți nevoie de o funcție care să măsoare performanța unui model de învățare automată pentru datele date. Funcția de cost cuantifică eroarea dintre valorile prezise și valorile așteptate.
`Dacă nu o poți măsura, nu o poți îmbunătăți.`
-Un alt lucru care se va schimba odată cu această transformare este funcția de cost. În Regresia liniară, folosim `Mean Squared Error` pentru funcția de cost dată de:-
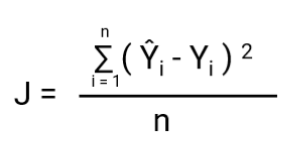
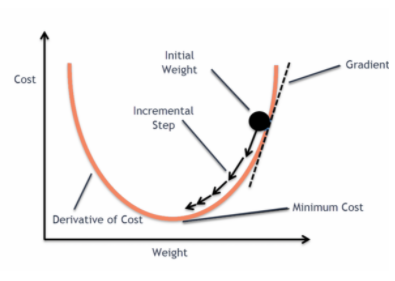
și când această funcție de eroare este reprezentată grafic în raport cu parametrii de greutate ai modelului de regresie liniară, aceasta formează o curbă convexă, ceea ce o face eligibilă pentru aplicarea algoritmului de optimizare Gradient Descent Optimization pentru a minimiza eroarea prin găsirea minimelor globale și ajustarea ponderilor.
De ce nu folosim `Mean Squared Error ca funcție de cost în Regresia Logistică?
În Regresia Logistică Ŷi este o funcție neliniară (Ŷ=1/1+ e-z), dacă punem acest lucru în ecuația MSE de mai sus va da o funcție neconvexă, așa cum se arată:
-
Când încercăm să optimizăm valorile folosind coborârea gradientului se vor crea complicații pentru a găsi minimele globale.
-
Un alt motiv este în problemele de clasificare, avem valori țintă precum 0/1, Deci (Ŷ-Y)2 va fi întotdeauna între 0-1, ceea ce poate face foarte dificilă urmărirea erorilor și este dificil de stocat numere flotante de mare precizie.
Funcția de cost utilizată în Regresia Logistică este Log Loss.
Ce este Log Loss?
Log Loss este cea mai importantă metrică de clasificare bazată pe probabilități. Este greu de interpretat valorile brute ale log-loss, dar log-loss este totuși o metrică bună pentru compararea modelelor. Pentru orice problemă dată, o valoare mai mică a log loss înseamnă predicții mai bune.
Interpretare matematică:
Log Loss este media negativă a logaritmului probabilităților prezise corectate pentru fiecare instanță.
Să o înțelegem cu un exemplu:
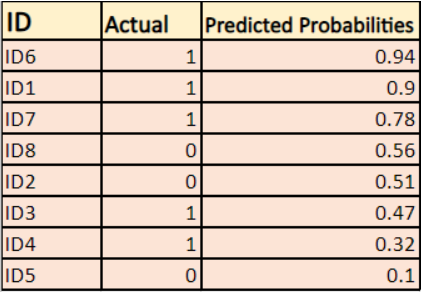
Modelul oferă probabilități prezise așa cum se arată mai sus.
Care sunt probabilitățile corectate?
-> În mod implicit, rezultatul modelului de regresie logistică este probabilitatea ca eșantionul să fie pozitiv (indicat cu 1), de exemplu, dacă un model de regresie logistică este antrenat pentru a clasifica pe un set de date `companie`, atunci coloana de probabilitate prezisă spune Care este probabilitatea ca persoana să fi cumpărat o jachetă. Aici, în setul de date de mai sus, probabilitatea ca o persoană cu ID6 să cumpere o jachetă este de 0,94.
În același mod, probabilitatea ca o persoană cu ID5 să cumpere o jachetă (adică să aparțină clasei 1) este de 0,1, dar clasa reală pentru ID5 este 0, deci probabilitatea pentru clasă este (1-0,1)=0,9. 0,9 este probabilitatea corectă pentru ID5.
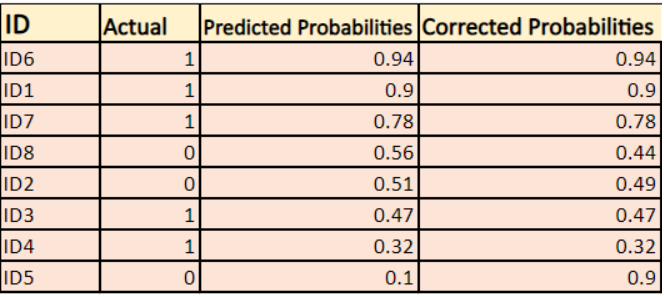
Vom găsi un logaritm al probabilităților corectate pentru fiecare instanță.
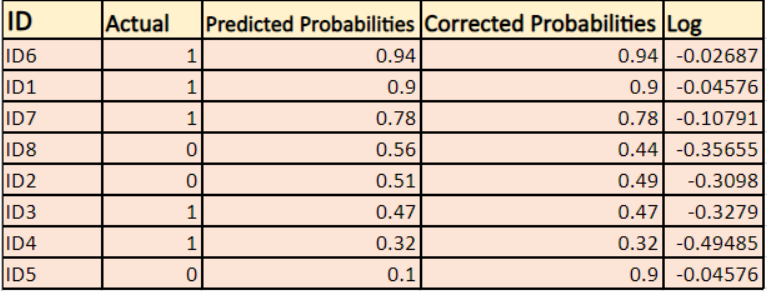
După cum puteți vedea, aceste valori logaritmice sunt negative. Pentru a face față semnului negativ, luăm media negativă a acestor valori, pentru a menține o convenție comună conform căreia scorurile de pierdere mai mici sunt mai bune.
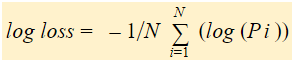
În concluzie, există trei pași pentru a găsi Log Loss:
-
Pentru a găsi probabilitățile corectate.
-
Să luăm un logaritm al probabilităților corectate.
-
Să luăm media negativă a valorilor pe care le obținem în pasul 2.
Dacă rezumăm toți pașii de mai sus, putem folosi formula:-
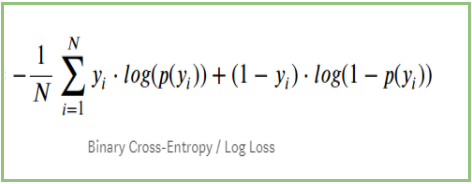
Aici Yi reprezintă clasa reală și log(p(yi)este probabilitatea acelei clase.
-
p(yi) este probabilitatea lui 1.
-
1-p(yi) este probabilitatea lui 0.
Acum să vedem cum funcționează formula de mai sus în două cazuri:
-
Când clasa reală este 1: al doilea termen din formulă ar fi 0 și vom rămâne cu primul termen adică yi.log(p(yi)) și (1-1).log(1-p(yi) acesta va fi 0.
-
Când clasa reală este 0: Primul termen va fi 0 și va rămâne cu al doilea termen adică (1-yi).log(1-p(yi)) și 0.log(p(yi)) va fi 0.
wow!!! ne-am întors la formula inițială pentru entropia încrucișată binară/log loss 🙂
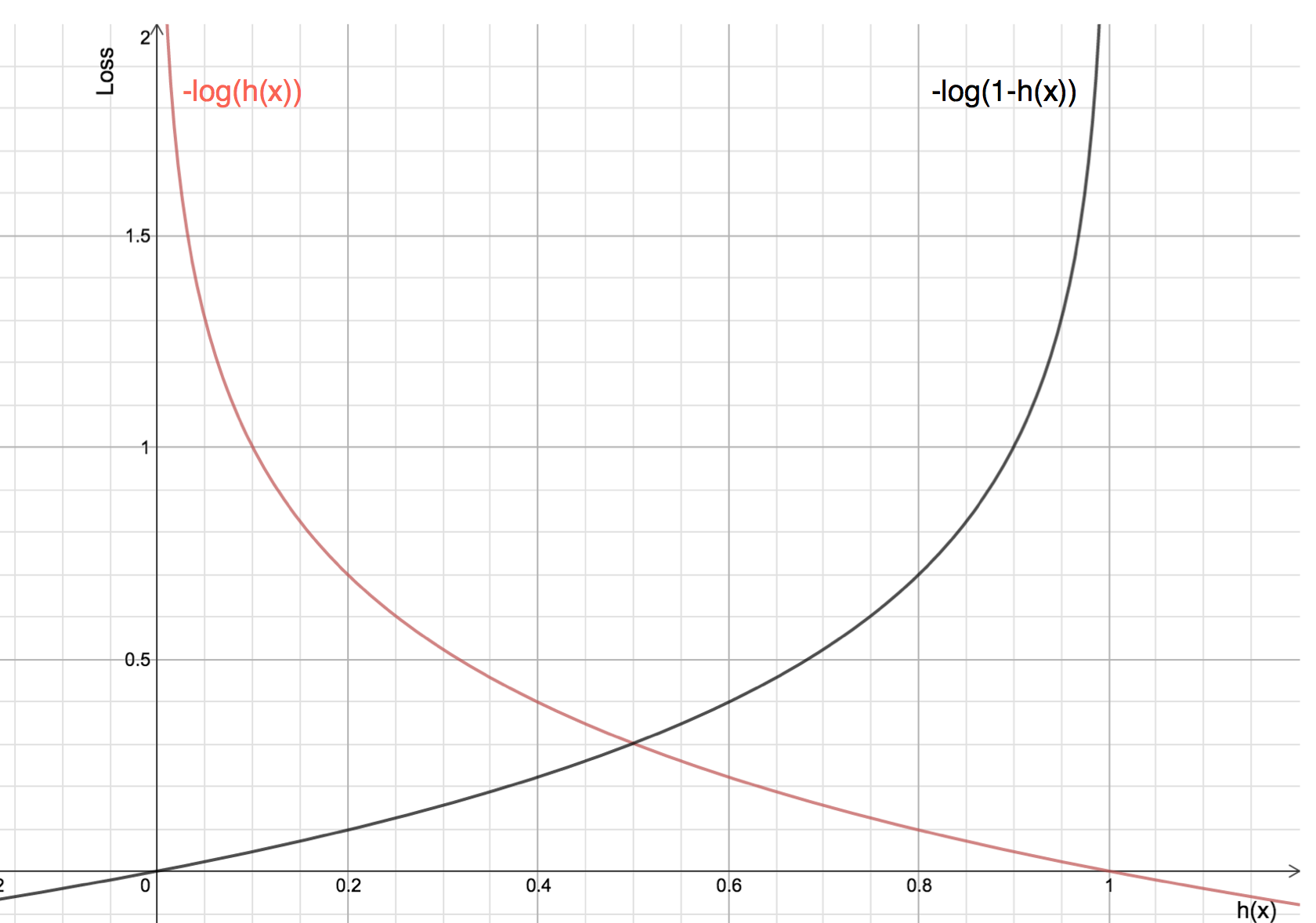
Beneficiile luării logaritmului se dezvăluie atunci când ne uităm la graficele funcției de cost pentru clasa reală 1 și 0 :
-
Linia roșie reprezintă clasa 1. După cum putem observa, atunci când probabilitatea prezisă (axa x) este apropiată de 1, pierderea este mai mică, iar atunci când probabilitatea prezisă este apropiată de 0, pierderea se apropie de infinit.
-
Linia neagră reprezintă clasa 0. După cum se poate observa, atunci când probabilitatea prezisă (axa x) este apropiată de 0, pierderea este mai mică, iar atunci când probabilitatea prezisă este apropiată de 1, pierderea se apropie de infinit.