This article was published as a part of the Data Science Blogathon.
- Áttekintés
- A cikk előfeltételei:
- Előszó
- Probléma a lineáris egyenessel:
- Miért nem használjuk a `Hiba négyzetének középértékét költségfüggvényként a logisztikus regresszióban?
- Mi a Log Loss?
- Melyek a korrigált valószínűségek?
- A logaritmus felvételének előnyei megmutatkoznak, ha megnézzük a költségfüggvény grafikonjait a tényleges 1 és 0 osztályra :
Áttekintés
-
Kihívások, ha a Lineáris regressziós modellt használjuk egy osztályozási probléma megoldására.
-
Miért nem az MSE-t használják költségfüggvényként a Logisztikus regresszióban?
-
Ez a cikk a Log Loss függvény mögötti matematikát mutatja be egy egyszerű példán keresztül.
A cikk előfeltételei:
-
Lineáris regresszió
-
Logisztikus regresszió
-
Gradient Descent
Előszó
`Itt a tél`. Köszöntsük a telet egy meleg adattudományi problémával 😉
Vegyünk egy esettanulmányt egy kabátokat és kardigánokat gyártó ruházati cégről. Szeretnének egy olyan modellt, amely képes megjósolni, hogy a vásárló kabátot (1. osztály) vagy kardigánt(0. osztály) fog-e vásárolni a korábbi viselkedésminták alapján, hogy a vásárló igényeinek megfelelő konkrét ajánlatokat tudjanak adni. Mint adattudósnak, segítenie kell nekik egy előrejelző modell létrehozásában.
Amikor elkezdjük a gépi tanulási algoritmusokat, az első algoritmus, amit megismerünk, a `Lineáris regresszió`, amelyben egy folytonos célváltozót jósolunk meg.
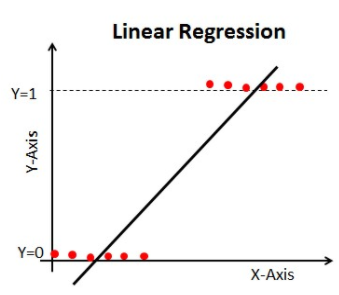
Ha az osztályozási problémánkban Lineáris regressziót használunk, akkor egy ilyen legjobban illeszkedő egyenest kapunk:
Z = ßX + b
Probléma a lineáris egyenessel:
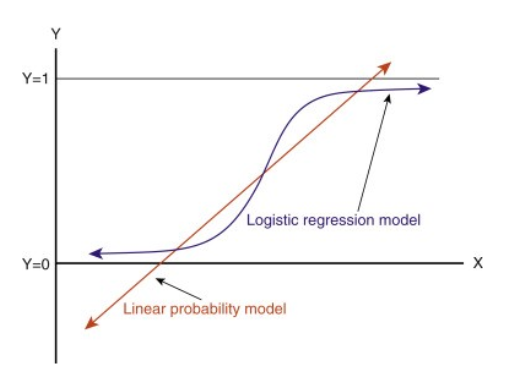
Az egyenes meghosszabbításakor 1-nél nagyobb és 0-nál kisebb értékeket kapunk, amelyeknek nem sok értelme van az osztályozási problémánkban. Ez kihívássá teszi a modell értelmezését. Itt jön a képbe a `Logisztikus regresszió`. Ha egy üzlethelyiség értékesítését kellene megjósolnunk, akkor ez a modell hasznos lehet. Itt azonban a vásárlók osztályozására van szükségünk.
-Szükségünk van egy függvényre, amely ezt az egyenest úgy transzformálja, hogy az értékek 0 és 1 között legyenek:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (Szigmoid függvény)
Ŷ =1/1+ e-z
-A transzformáció után egy olyan egyenest kapunk, amely 0 és 1 között marad. Ennek a függvénynek egy másik előnye, hogy minden folytonos érték, amit kapunk, 0 és 1 között lesz, amit valószínűségként használhatunk előrejelzések készítéséhez. Például, ha az előre jelzett érték a jobb szélső értéken van, a valószínűség közel 1 lesz, ha pedig az előre jelzett érték a bal szélső értéken van, a valószínűség közel 0 lesz.
A megfelelő modell kiválasztása nem elég. Szükség van egy olyan függvényre, amely egy gépi tanulási modell teljesítményét méri adott adatokra. A költségfüggvény a megjósolt értékek és a várható értékek közötti hibát számszerűsíti.
`Ha nem tudod mérni, nem tudod javítani.`
-A másik dolog, ami ezzel az átalakítással megváltozik, a költségfüggvény. A lineáris regresszióban a költségfüggvényhez a következő módon megadott `Mean Squared Error` költségfüggvényt használjuk:-
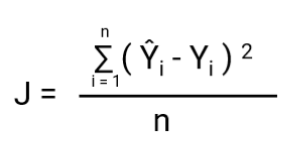
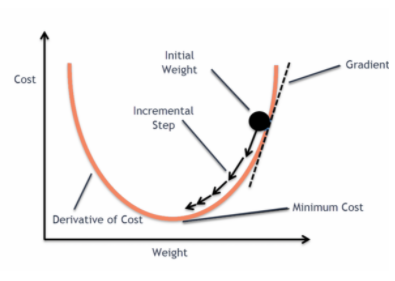
és ha ezt a hibafüggvényt a lineáris regressziós modell súlyparamétereihez viszonyítva ábrázoljuk, akkor egy konvex görbét alkot, ami alkalmassá teszi a Gradient Descent optimalizációs algoritmus alkalmazására a hiba minimalizálására a globális minimumok megtalálása és a súlyok beállítása révén.
Miért nem használjuk a `Hiba négyzetének középértékét költségfüggvényként a logisztikus regresszióban?
A logisztikus regresszióban Ŷi egy nemlineáris függvény(Ŷ=1/1+ e-z), ha ezt beillesztjük a fenti MSE egyenletbe, akkor egy nem konvex függvényt kapunk az alábbiak szerint:
-
Ha az értékeket gradiens ereszkedéssel próbáljuk optimalizálni, akkor komplikációkat okoz a globális minimumok megtalálása.
-
Egy másik ok az osztályozási problémáknál, hogy olyan célértékeink vannak, mint 0/1, Tehát (Ŷ-Y)2 mindig 0-1 között lesz, ami nagyon megnehezítheti a hibák nyomon követését, és nehéz nagy pontosságú lebegőszámokat tárolni.
A logisztikus regresszióban használt költségfüggvény a Log Loss.
Mi a Log Loss?
A Log Loss a legfontosabb valószínűségeken alapuló osztályozási metrika. A nyers log-loss értékeket nehéz értelmezni, de a log-loss mégis jó metrika a modellek összehasonlítására. Egy adott probléma esetén az alacsonyabb log loss érték jobb előrejelzéseket jelent.
Matematikai értelmezés:
A log loss az egyes esetekre korrigált előrejelzett valószínűségek logaritmusának negatív átlaga.
Magyarázzuk meg egy példán keresztül:
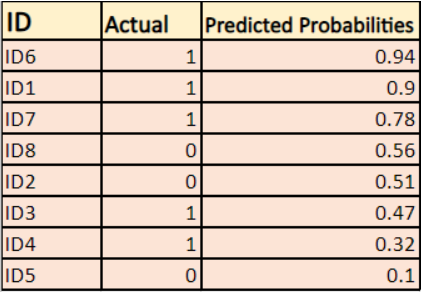
A modell a fent látható módon ad előrejelzett valószínűségeket.
Melyek a korrigált valószínűségek?
-> Alapértelmezés szerint a logisztikus regressziós modell kimenete a minta pozitív valószínűsége(1-gyel jelölve), azaz ha egy logisztikus regressziós modellt betanítunk egy `céges adathalmazon` történő osztályozásra, akkor az előre jelzett valószínűség oszlopban az áll: Mi a valószínűsége annak, hogy az illető kabátot vásárolt. Itt a fenti adathalmazban annak a valószínűsége, hogy az ID6 azonosítóval rendelkező személy kabátot vesz, 0,94.
Az ID5 azonosítóval rendelkező személy kabátot vesz (azaz az 1. osztályba tartozik) 0,1, de az ID5 tényleges osztálya 0, így az osztályra vonatkozó valószínűség (1-0,1)=0,9 lesz. A 0,9 az ID5 helyes valószínűsége.
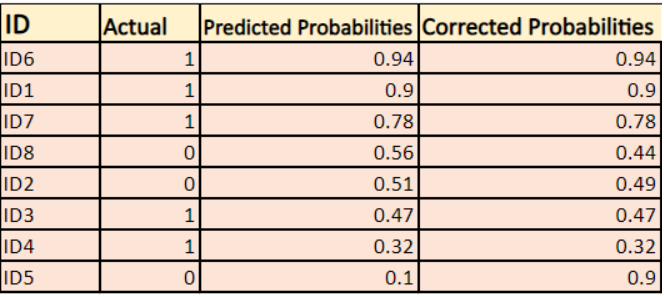
Megkeressük a korrigált valószínűségek logaritmusát minden egyes esetre.
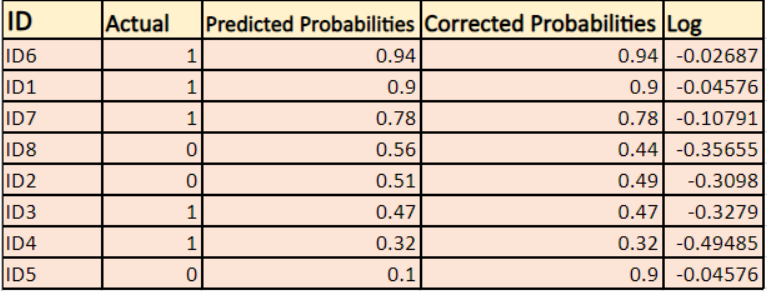
Mint láthatjuk, ezek a logaritmusértékek negatívak. A negatív előjel kezelésére ezen értékek negatív átlagát vesszük, hogy fenntartsuk azt az általános konvenciót, hogy az alacsonyabb veszteségértékek jobbak.
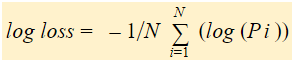
Röviden, három lépésből áll a log veszteség megtalálása:
-
A korrigált valószínűségek megtalálása.
-
Vegyük a korrigált valószínűségek naplóját.
-
Vegyük a 2. lépésben kapott értékek negatív átlagát.
Ha a fenti lépéseket összegezzük, akkor a következő képletet használhatjuk:-
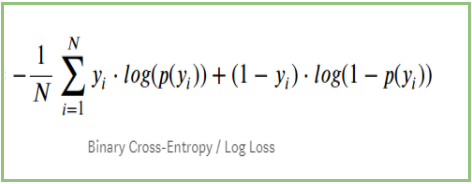
Itt Yi az aktuális osztályt jelenti, és log(p(yi)az adott osztály valószínűsége.
-
p(yi) az 1 valószínűsége.
-
1-p(yi) a 0 valószínűsége.
Most nézzük meg, hogyan működik a fenti képlet két esetben:
-
Ha a tényleges osztály 1: a képlet második tagja 0 lenne, és marad az első tag, azaz yi.log(p(yi)) és (1-1).log(1-p(yi) ez 0 lesz.
-
Ha a tényleges osztály 0 lesz: Az első kifejezés 0 lenne és marad a második kifejezés azaz (1-yi).log(1-p(yi)) és 0.log(p(yi)) lesz 0.
wow!!! visszatértünk a bináris kereszt-entrópia/log veszteség 🙂
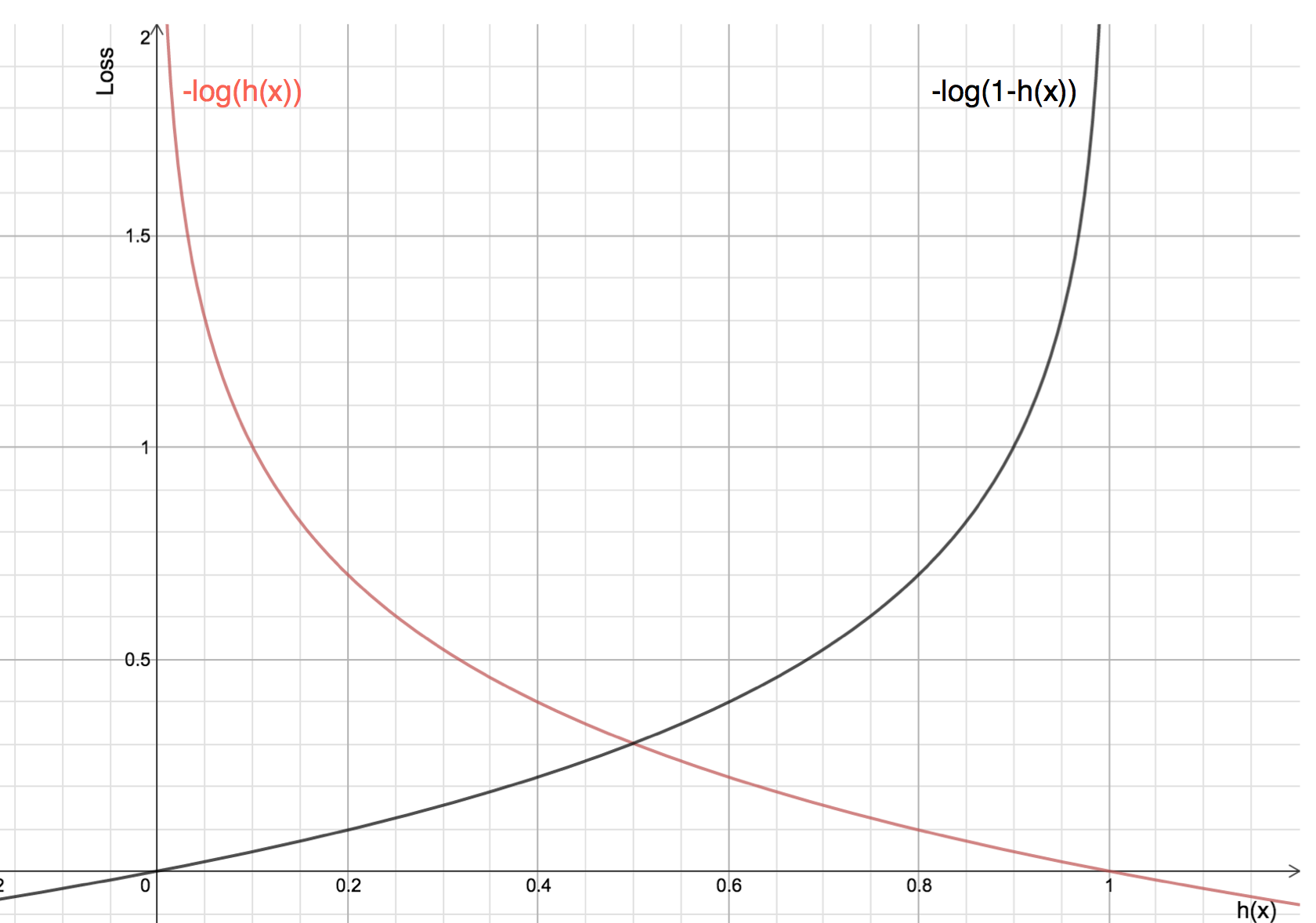
A logaritmus felvételének előnyei megmutatkoznak, ha megnézzük a költségfüggvény grafikonjait a tényleges 1 és 0 osztályra :
-
A piros vonal az 1 osztályt képviseli. Mint látható, amikor az előre jelzett valószínűség (x-tengely) közel 1, a veszteség kisebb, és amikor az előre jelzett valószínűség közel 0, a veszteség megközelíti a végtelent.
-
A fekete vonal 0 osztályt jelöl. Mint látható, amikor az előre jelzett valószínűség (x-tengely) közel van a 0-hoz, a veszteség kisebb, és amikor az előre jelzett valószínűség közel van az 1-hez, a veszteség megközelíti a végtelent.