Questo articolo è stato pubblicato come parte del Data Science Blogathon.
- Panoramica
- Pre-requisiti per questo articolo:
- INTRODUZIONE
- Problema con la linea lineare:
- Perché non usiamo l’errore quadratico medio come funzione di costo nella regressione logistica?
- Che cos’è Log Loss?
- Quali sono le probabilità corrette?
- I vantaggi di prendere il logaritmo si rivelano quando si guardano i grafici delle funzioni di costo per le classi 1 e 0 attuali :
Panoramica
-
Le sfide se usiamo il modello di Regressione Lineare per risolvere un problema di classificazione.
-
Perché MSE non è usato come funzione di costo nella Regressione Logistica?
-
Questo articolo tratterà la matematica dietro la funzione Log Loss con un semplice esempio.
Pre-requisiti per questo articolo:
-
Regressione lineare
-
Regressione logistica
-
Discesa radiale
INTRODUZIONE
`L’inverno è qui`. Diamo il benvenuto all’inverno con un caldo problema di data science 😉
Prendiamo un caso di studio di un’azienda di abbigliamento che produce giacche e cardigan. Vogliono avere un modello che possa prevedere se il cliente comprerà una giacca (classe 1) o un cardigan (classe 0) dal loro modello comportamentale storico in modo da poter dare offerte specifiche in base alle esigenze del cliente. Come data scientist, devi aiutarli a costruire un modello predittivo.
Quando iniziamo gli algoritmi di Machine Learning, il primo algoritmo che impariamo è la `Regressione lineare` in cui prevediamo una variabile target continua.
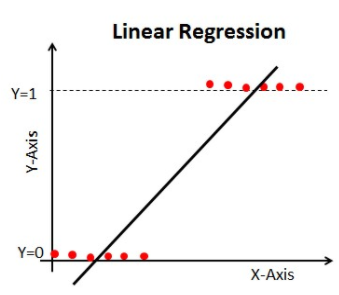
Se usiamo la Regressione Lineare nel nostro problema di classificazione, otterremo una linea best-fit come questa:
Z = ßX + b
Problema con la linea lineare:
Quando si estende questa linea, si avranno valori maggiori di 1 e minori di 0, che non hanno molto senso nel nostro problema di classificazione. Questo renderà l’interpretazione del modello una sfida. È qui che entra in gioco la “regressione logistica”. Se avessimo bisogno di prevedere le vendite di un outlet, allora questo modello potrebbe essere utile. Ma qui abbiamo bisogno di classificare i clienti.
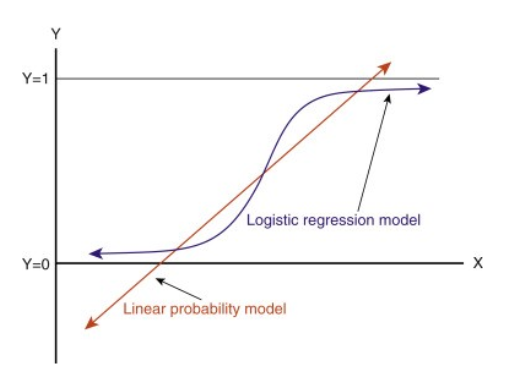
-Abbiamo bisogno di una funzione per trasformare questa linea retta in modo tale che i valori siano tra 0 e 1:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (Funzione Sigmoide)
Ŷ =1/1+ e-z
-Dopo la trasformazione, avremo una linea che rimane tra 0 e 1. Un altro vantaggio di questa funzione è che tutti i valori continui che otterremo saranno compresi tra 0 e 1 che possiamo usare come probabilità per fare previsioni. Per esempio, se il valore previsto è all’estrema destra, la probabilità sarà vicina a 1 e se il valore previsto è all’estrema sinistra, la probabilità sarà vicina a 0.
Selezionare il modello giusto non è sufficiente. Hai bisogno di una funzione che misuri le prestazioni di un modello di Machine Learning per dati dati. La funzione di costo quantifica l’errore tra i valori predetti e i valori attesi.
`Se non puoi misurarlo, non puoi migliorarlo.`
-Un’altra cosa che cambierà con questa trasformazione è la funzione di costo. Nella regressione lineare, usiamo l’errore quadratico medio per la funzione di costo data da:-
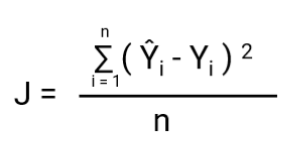
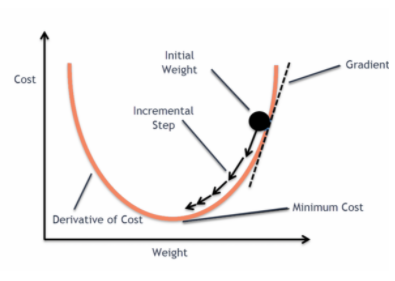
e quando questa funzione di errore è tracciata rispetto ai parametri di peso del modello di regressione lineare, forma una curva convessa che la rende idonea ad applicare l’algoritmo di ottimizzazione Gradient Descent per minimizzare l’errore trovando minimi globali e regolando i pesi.
Perché non usiamo l’errore quadratico medio come funzione di costo nella regressione logistica?
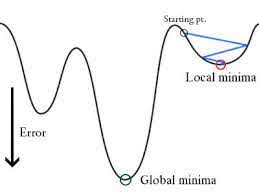
Nella Regressione Logistica Ŷi è una funzione non lineare (Ŷ=1/1+ e-z), se la mettiamo nell’equazione MSE di cui sopra darà una funzione non convessa come mostrato:
-
Quando cerchiamo di ottimizzare i valori usando la discesa a gradiente si creeranno complicazioni per trovare i minimi globali.
-
Un’altra ragione è nei problemi di classificazione, abbiamo valori target come 0/1, quindi (Ŷ-Y)2 sarà sempre tra 0-1 che può rendere molto difficile tenere traccia degli errori ed è difficile memorizzare numeri floating ad alta precisione.
La funzione di costo usata nella regressione logistica è Log Loss.
Che cos’è Log Loss?
Log Loss è la più importante metrica di classificazione basata sulle probabilità. È difficile interpretare i valori grezzi di log-loss, ma il log-loss è comunque una buona metrica per confrontare i modelli. Per ogni dato problema, un valore di log-loss più basso significa previsioni migliori.
Interpretazione matematica:
Log Loss è la media negativa del log delle probabilità previste corrette per ogni istanza.
Comprendiamo con un esempio:
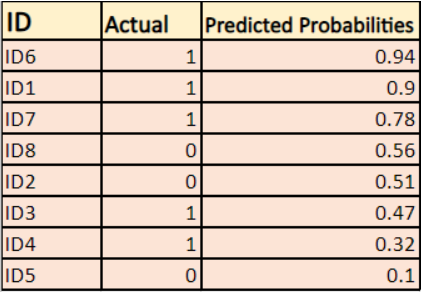
Il modello sta dando probabilità previste come mostrato sopra.
Quali sono le probabilità corrette?
-> Per impostazione predefinita, l’output del modello di regressione logistica è la probabilità che il campione sia positivo (indicato da 1) cioè se un modello di regressione logistica è addestrato a classificare su un `set di dati aziendali` allora la colonna della probabilità prevista dice Qual è la probabilità che la persona abbia comprato una giacca. Qui nel set di dati di cui sopra la probabilità che una persona con ID6 compri una giacca è 0,94.
Allo stesso modo, la probabilità che una persona con ID5 compri una giacca (cioè appartenente alla classe 1) è 0,1 ma la classe effettiva per ID5 è 0, quindi la probabilità per la classe è (1-0,1)=0,9. 0,9 è la probabilità corretta per ID5.
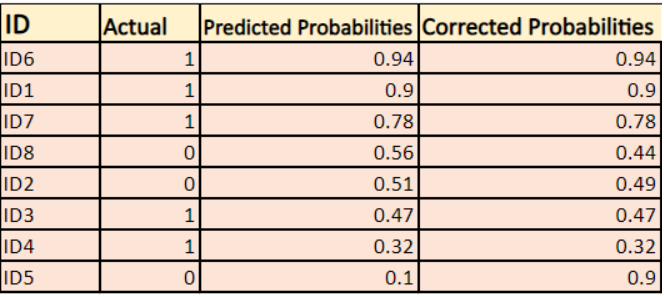
Troveremo un log delle probabilità corrette per ogni istanza.
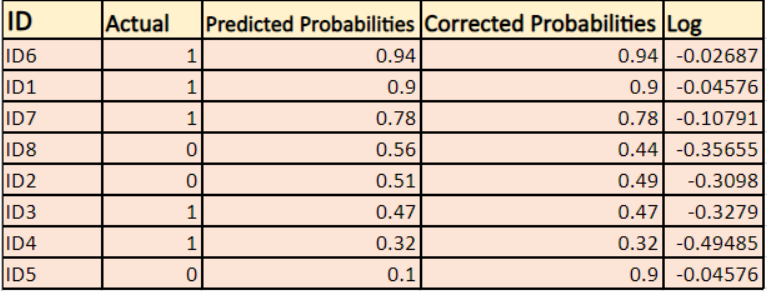
Come potete vedere questi valori log sono negativi. Per trattare il segno negativo, prendiamo la media negativa di questi valori, per mantenere una convenzione comune che i punteggi di perdita più bassi sono migliori.
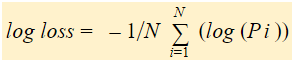
In breve, ci sono tre passi per trovare Log Loss:
-
Per trovare le probabilità corrette.
-
Prendere un log delle probabilità corrette.
-
Prendere la media negativa dei valori che otteniamo nel 2° passo.
Se riassumiamo tutti i passi precedenti, possiamo usare la formula:-
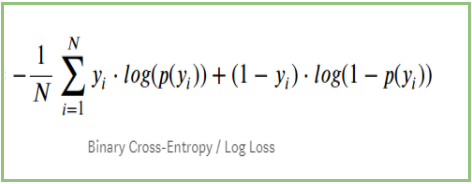
Qui Yi rappresenta la classe attuale e log(p(yi)è la probabilità di quella classe.
-
p(yi) è la probabilità di 1.
-
1-p(yi) è la probabilità di 0.
Ora vediamo come funziona la formula di cui sopra in due casi:
-
Quando la classe effettiva è 1: il secondo termine nella formula sarebbe 0 e ci rimarrà il primo termine cioè yi.log(p(yi)) e (1-1).log(1-p(yi) questo sarà 0.
-
Quando la classe effettiva è 0: Il primo termine sarebbe 0 e rimarrà il secondo termine cioè (1-yi).log(1-p(yi)) e 0.log(p(yi)) sarà 0.
wow! siamo tornati alla formula originale per la cross-entropia binaria/log loss 🙂
I vantaggi di prendere il logaritmo si rivelano quando si guardano i grafici delle funzioni di costo per le classi 1 e 0 attuali :
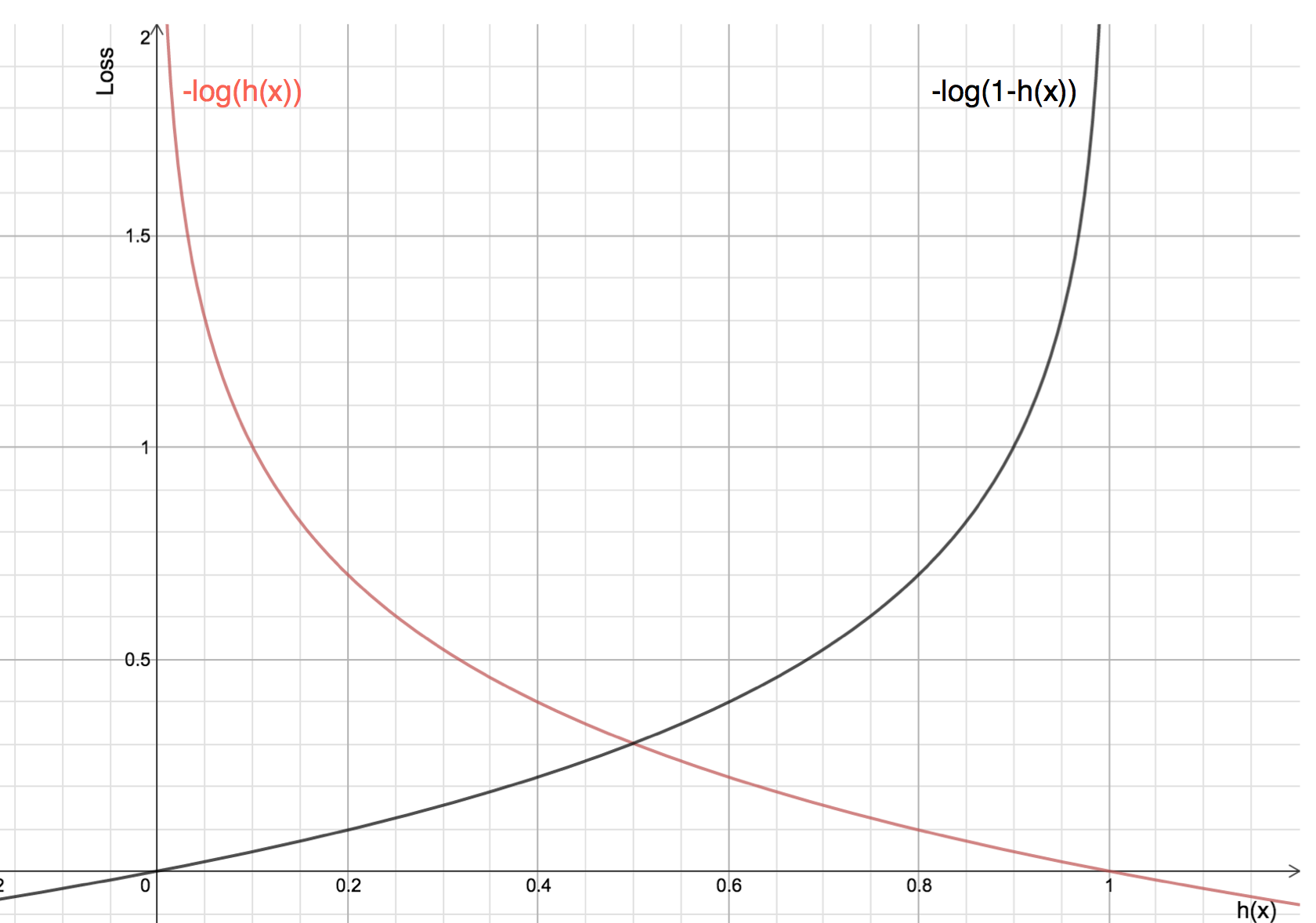
-
La linea rossa rappresenta 1 classe. Come possiamo vedere, quando la probabilità prevista (asse delle x) è vicina a 1, la perdita è minore e quando la probabilità prevista è vicina a 0, la perdita si avvicina all’infinito.
-
La linea nera rappresenta 0 classi. Come possiamo vedere, quando la probabilità prevista (asse delle x) è vicina a 0, la perdita è minore e quando la probabilità prevista è vicina a 1, la perdita si avvicina all’infinito.