Este artículo fue publicado como parte del Blogathon de Ciencia de Datos.
- Overview
- Requisitos para este artículo:
- INTRODUCCIÓN
- Problema con la línea lineal:
- ¿Por qué no usamos el `Error Medio Cuadrado como función de coste en la Regresión Logística?
- ¿Qué es la Pérdida Logística?
- ¿Cuáles son las probabilidades corregidas?
- Las ventajas de tomar el logaritmo se revelan cuando se observan los gráficos de la función de costes para las clases reales 1 y 0 :
Overview
-
Desafíos si utilizamos el modelo de Regresión Lineal para resolver un problema de clasificación.
-
¿Por qué no se utiliza el MSE como función de coste en la Regresión Logística?
-
Este artículo cubrirá las matemáticas detrás de la función de Pérdida Logística con un ejemplo simple.
Requisitos para este artículo:
-
Regresión Lineal
-
Regresión Logística
-
Descendencia Gradiente
INTRODUCCIÓN
`El invierno está aquí`. Demos la bienvenida a los inviernos con un cálido problema de ciencia de datos 😉
Tomemos un caso de estudio de una empresa de ropa que fabrica chaquetas y cardigans. Quieren tener un modelo que pueda predecir si el cliente comprará una chaqueta (clase 1) o una rebeca(clase 0) a partir de su patrón de comportamiento histórico para poder dar ofertas específicas según las necesidades del cliente. Como científico de datos, tienes que ayudarles a construir un modelo predictivo.
Cuando empezamos con los algoritmos de Machine Learning, el primer algoritmo que aprendemos es el de `Regresión lineal` en el que predecimos una variable objetivo continua.
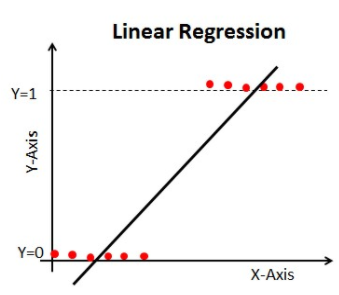
Si utilizamos la Regresión Lineal en nuestro problema de clasificación, obtendremos una línea de mejor ajuste como esta:
Z = ßX + b
Problema con la línea lineal:
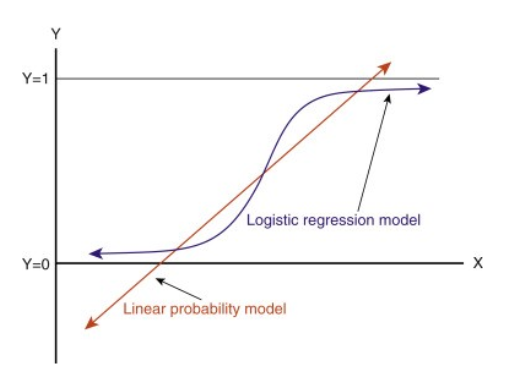
Cuando extiendas esta línea, tendrás valores mayores que 1 y menores que 0, que no tienen mucho sentido en nuestro problema de clasificación. Esto hará que la interpretación del modelo sea un reto. Ahí es donde entra en juego la `Regresión Logística`. Si necesitáramos predecir las ventas de un establecimiento, este modelo podría ser útil. Pero aquí necesitamos clasificar a los clientes.
Necesitamos una función que transforme esta recta de forma que los valores estén entre 0 y 1:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (Función Sigmoide)
Ŷ =1/1+ e-z
-Después de la transformación, obtendremos una recta que queda entre 0 y 1. Otra ventaja de esta función es que todos los valores continuos que obtendremos estarán entre 0 y 1 lo que podemos utilizar como probabilidad para hacer predicciones. Por ejemplo, si el valor predicho está en el extremo derecho, la probabilidad será cercana a 1 y si el valor predicho está en el extremo izquierdo, la probabilidad será cercana a 0.
Seleccionar el modelo correcto no es suficiente. Se necesita una función que mida el rendimiento de un modelo de Machine Learning para unos datos dados. La función de coste cuantifica el error entre los valores predichos y los valores esperados.
Si no puedes medirlo, no puedes mejorarlo.`
Otra cosa que cambiará con esta transformación es la función de coste. En la Regresión Lineal, utilizamos el `Error Medio Cuadrado` para la función de coste dada por:-
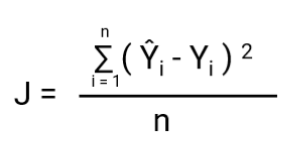
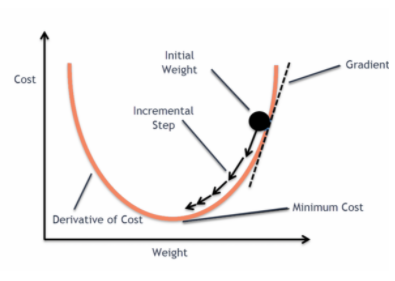
y cuando esta función de error se traza con respecto a los parámetros de peso del Modelo de Regresión Lineal, forma una curva convexa que la hace elegible para aplicar el Algoritmo de Optimización de Descenso Gradiente para minimizar el error encontrando los mínimos globales y ajustando los pesos.
¿Por qué no usamos el `Error Medio Cuadrado como función de coste en la Regresión Logística?
En la Regresión Logística Ŷi es una función no lineal(Ŷ=1/1+ e-z), si ponemos esto en la ecuación MSE anterior dará una función no convexa como se muestra:
-
Cuando tratamos de optimizar los valores utilizando el descenso de gradiente creará complicaciones para encontrar mínimos globales.
-
Otra razón es que en los problemas de clasificación, tenemos valores objetivo como 0/1, por lo que (Ŷ-Y)2 siempre estará entre 0-1 lo que puede hacer muy difícil el seguimiento de los errores y es difícil almacenar números flotantes de alta precisión.
La función de coste utilizada en la Regresión Logística es la Pérdida Logística.
¿Qué es la Pérdida Logística?
La Pérdida Logística es la métrica de clasificación más importante basada en probabilidades. Es difícil interpretar los valores brutos de pérdida logarítmica, pero la pérdida logarítmica sigue siendo una buena métrica para comparar modelos. Para cualquier problema dado, un valor de pérdida logarítmica más bajo significa mejores predicciones.
Interpretación matemática:
La pérdida logarítmica es la media negativa del logaritmo de las probabilidades predichas corregidas para cada instancia.
Entendámoslo con un ejemplo:
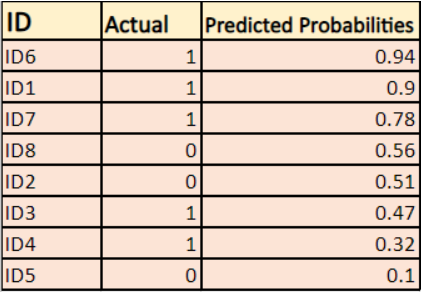
El modelo está dando probabilidades predichas como se muestra arriba.
¿Cuáles son las probabilidades corregidas?
-> Por defecto, la salida del modelo de regresión logística es la probabilidad de que la muestra sea positiva (indicada por 1), es decir, si un modelo de regresión logística se entrena para clasificar en un `conjunto de datos de empresas`, la columna de probabilidad predicha dice Cuál es la probabilidad de que la persona haya comprado una chaqueta. Aquí, en el conjunto de datos anterior, la probabilidad de que una persona con ID6 compre una chaqueta es de 0,94.
Del mismo modo, la probabilidad de que una persona con ID5 compre una chaqueta (es decir, que pertenezca a la clase 1) es de 0,1, pero la clase real para ID5 es 0, por lo que la probabilidad para la clase es (1-0,1)=0,9. 0,9 es la probabilidad correcta para ID5.
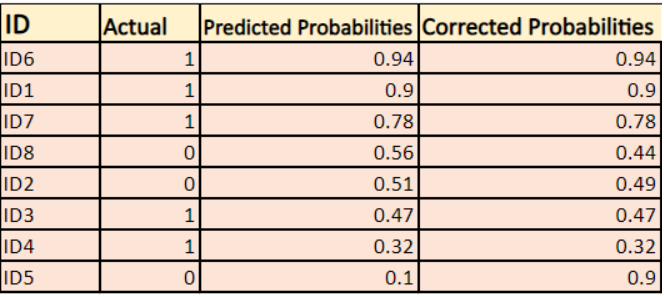
Encontraremos un logaritmo de las probabilidades corregidas para cada instancia.
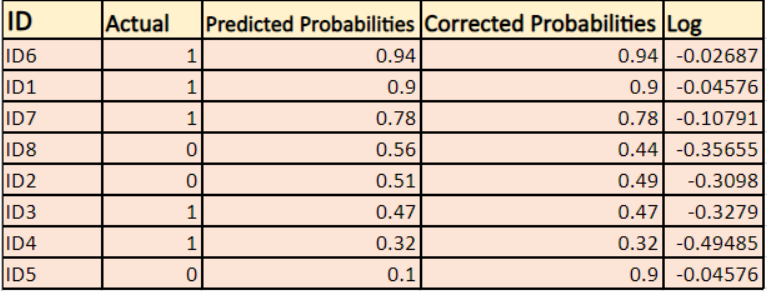
Como puedes ver estos valores del logaritmo son negativos. Para tratar el signo negativo, tomamos la media negativa de estos valores, para mantener una convención común de que las puntuaciones de pérdida más bajas son mejores.
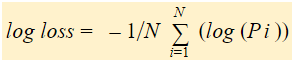
En resumen, hay tres pasos para encontrar la pérdida logarítmica:
-
Para encontrar las probabilidades corregidas.
-
Tomar el logaritmo de las probabilidades corregidas.
-
Tomar la media negativa de los valores que obtenemos en el 2º paso.
Si resumimos todos los pasos anteriores, podemos utilizar la fórmula:-
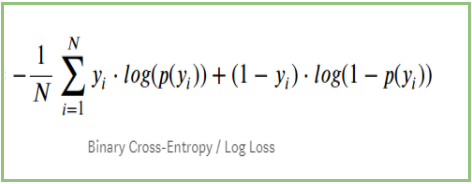
Aquí Yi representa la clase real y log(p(yi)es la probabilidad de esa clase.
-
p(yi) es la probabilidad de 1.
-
1-p(yi) es la probabilidad de 0.
Ahora veamos cómo funciona la fórmula anterior en dos casos:
-
Cuando la clase real es 1: el segundo término de la fórmula sería 0 y nos quedaremos con el primer término es decir yi.log(p(yi)) y (1-1).log(1-p(yi) esto será 0.
-
Cuando la clase real es 0: El primer término sería 0 y quedará el segundo término es decir (1-yi).log(1-p(yi)) y 0.log(p(yi)) será 0.
¡Vaya! volvemos a la fórmula original de la entropía cruzada binaria/pérdida logarítmica 🙂
Las ventajas de tomar el logaritmo se revelan cuando se observan los gráficos de la función de costes para las clases reales 1 y 0 :
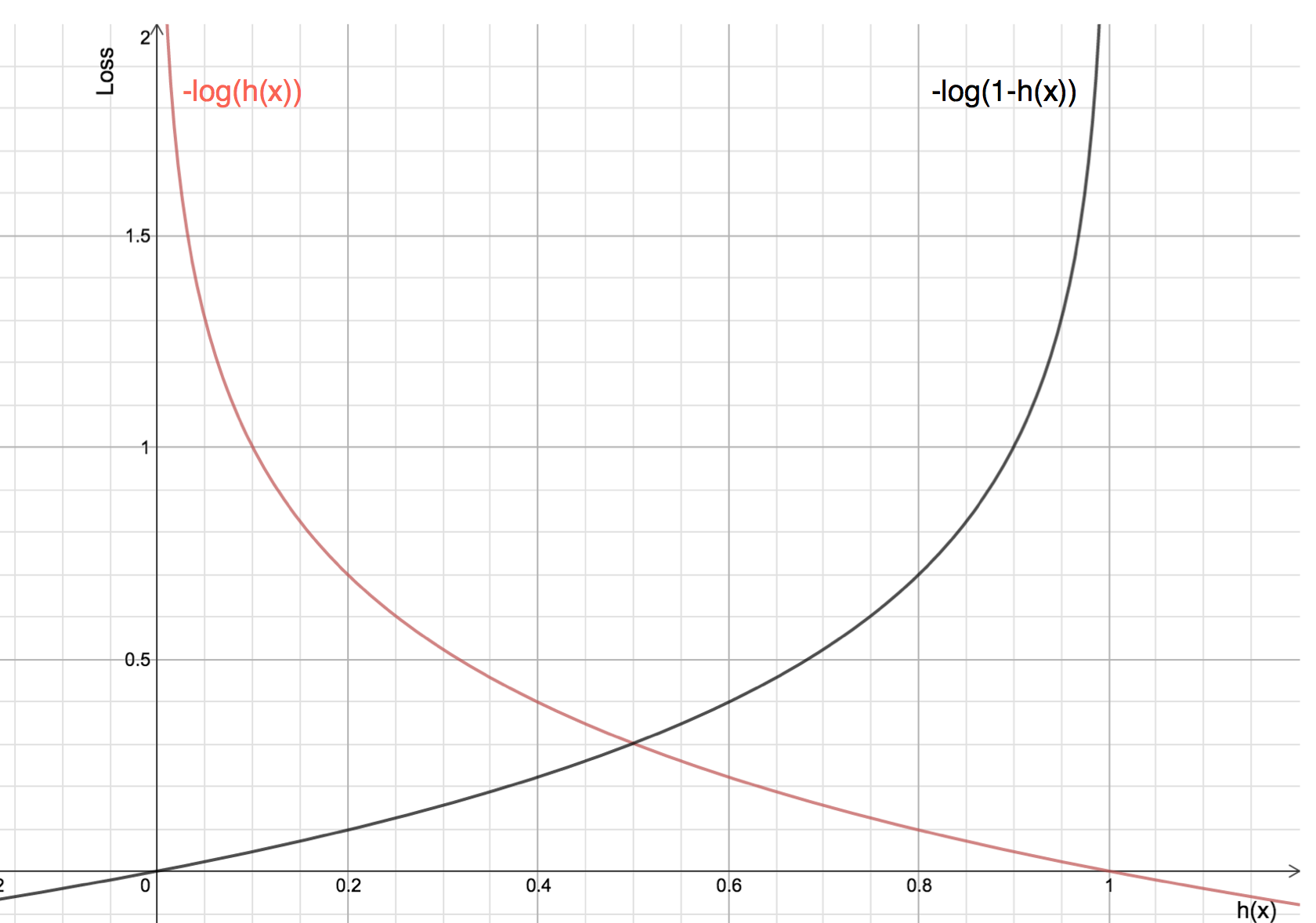
-
La línea roja representa la clase 1. Como podemos ver, cuando la probabilidad predicha (eje x) se acerca a 1, la pérdida es menor y cuando la probabilidad predicha se acerca a 0, la pérdida se aproxima al infinito.
-
La línea negra representa la clase 0. Como podemos ver, cuando la probabilidad predicha (eje x) está cerca de 0, la pérdida es menor y cuando la probabilidad predicha está cerca de 1, la pérdida se acerca al infinito.