Dieser Artikel wurde im Rahmen des Data Science Blogathon veröffentlicht.
- Überblick
- Voraussetzungen für diesen Artikel:
- Einleitung
- Problem mit der linearen Linie:
- Warum verwenden wir nicht den „mittleren quadratischen Fehler“ als Kostenfunktion in der logistischen Regression?
- Was ist Log Loss?
- Wie lauten die korrigierten Wahrscheinlichkeiten?
- Die Vorteile der Logarithmierung werden deutlich, wenn man sich die Graphen der Kostenfunktionen für die aktuelle Klasse 1 und 0 ansieht:
Überblick
-
Herausforderungen, wenn wir das Modell der linearen Regression zur Lösung eines Klassifizierungsproblems verwenden.
-
Warum wird MSE nicht als Kostenfunktion in der logistischen Regression verwendet?
-
Dieser Artikel behandelt die Mathematik hinter der Log Loss-Funktion anhand eines einfachen Beispiels.
Voraussetzungen für diesen Artikel:
-
Lineare Regression
-
Logistische Regression
-
Gradientenabstieg
Einleitung
`Winter ist da`. Begrüßen wir den Winter mit einem warmen Data-Science-Problem 😉
Lassen Sie uns ein Fallbeispiel eines Bekleidungsunternehmens nehmen, das Jacken und Strickjacken herstellt. Das Unternehmen möchte ein Modell haben, das anhand der historischen Verhaltensmuster der Kunden vorhersagen kann, ob sie eine Jacke (Klasse 1) oder eine Strickjacke (Klasse 0) kaufen werden, damit es ihnen spezifische Angebote machen kann, die ihren Bedürfnissen entsprechen. Als Datenwissenschaftler müssen Sie ihnen helfen, ein Vorhersagemodell zu erstellen.
Wenn wir mit Algorithmen des maschinellen Lernens beginnen, ist der erste Algorithmus, den wir kennenlernen, die „lineare Regression“, bei der wir eine kontinuierliche Zielvariable vorhersagen.
Wenn wir die Lineare Regression für unser Klassifizierungsproblem verwenden, erhalten wir eine Best-Fit-Linie wie diese:
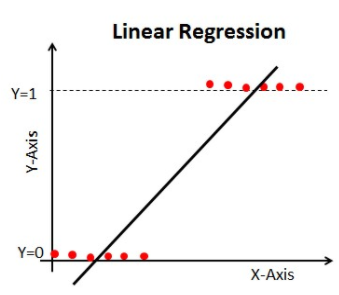
Z = ßX + b
Problem mit der linearen Linie:
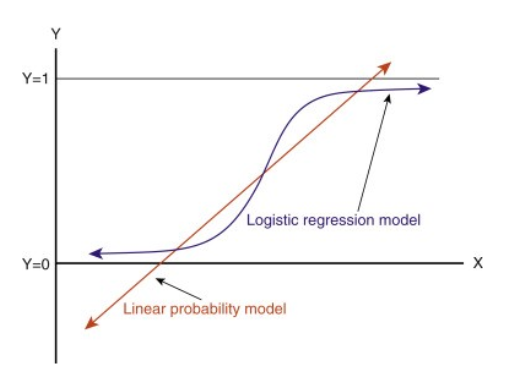
Wenn man diese Linie verlängert, erhält man Werte größer als 1 und kleiner als 0, die für unser Klassifizierungsproblem nicht viel Sinn machen. Das macht eine Modellinterpretation zu einer Herausforderung. Hier kommt die „logistische Regression“ ins Spiel. Wenn wir den Umsatz für eine Verkaufsstelle vorhersagen müssten, könnte dieses Modell hilfreich sein. Aber hier müssen wir Kunden klassifizieren.
-Wir brauchen eine Funktion, um diese Gerade so zu transformieren, dass die Werte zwischen 0 und 1 liegen:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (Sigmoid-Funktion)
Ŷ =1/1+ e-z
-Nach der Transformation erhalten wir eine Gerade, die zwischen 0 und 1 liegt. Ein weiterer Vorteil dieser Funktion ist, dass alle kontinuierlichen Werte, die wir erhalten, zwischen 0 und 1 liegen, was wir als Wahrscheinlichkeit für die Erstellung von Vorhersagen verwenden können. Liegt der vorhergesagte Wert beispielsweise ganz rechts, ist die Wahrscheinlichkeit nahe bei 1, und liegt der vorhergesagte Wert ganz links, ist die Wahrscheinlichkeit nahe bei 0.
Die Auswahl des richtigen Modells ist nicht genug. Man braucht eine Funktion, die die Leistung eines Machine Learning Modells für gegebene Daten misst. Die Kostenfunktion quantifiziert den Fehler zwischen den vorhergesagten und den erwarteten Werten.
`Wenn man es nicht messen kann, kann man es nicht verbessern.`
Eine weitere Sache, die sich mit dieser Transformation ändert, ist die Kostenfunktion. Bei der linearen Regression verwenden wir den „mittleren quadratischen Fehler“ für die Kostenfunktion, die wie folgt lautet:
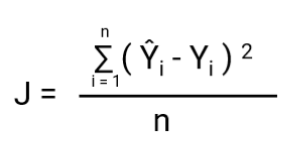
Wenn diese Fehlerfunktion in Bezug auf die Gewichtsparameter des linearen Regressionsmodells aufgetragen wird, bildet sie eine konvexe Kurve, die sich für die Anwendung des Gradientenabstiegs-Optimierungsalgorithmus eignet, um den Fehler zu minimieren, indem globale Minima gefunden und die Gewichte angepasst werden.
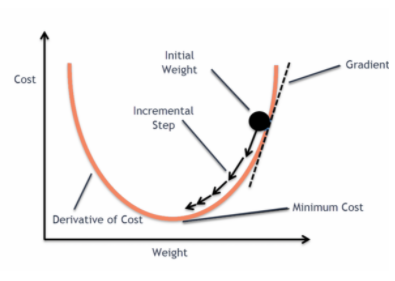
Warum verwenden wir nicht den „mittleren quadratischen Fehler“ als Kostenfunktion in der logistischen Regression?
In der logistischen Regression ist Ŷi eine nichtlineare Funktion (Ŷ=1/1+ e-z), wenn wir dies in die obige MSE-Gleichung einsetzen, ergibt sich eine nicht-konvexe Funktion, wie gezeigt:
-
Wenn wir versuchen, die Werte mithilfe des Gradientenabstiegs zu optimieren, wird es kompliziert, globale Minima zu finden.
-
Ein weiterer Grund ist, dass wir bei Klassifizierungsproblemen Zielwerte wie 0/1 haben, so dass (Ŷ-Y)2 immer zwischen 0-1 liegen wird, was es sehr schwierig machen kann, die Fehler im Auge zu behalten, und es ist schwierig, hochpräzise Gleitkommazahlen zu speichern.
Die in der logistischen Regression verwendete Kostenfunktion ist Log Loss.
Was ist Log Loss?
Log Loss ist die wichtigste auf Wahrscheinlichkeiten basierende Klassifizierungsmetrik. Es ist schwierig, rohe Log-Loss-Werte zu interpretieren, aber Log-Loss ist dennoch eine gute Metrik für den Vergleich von Modellen. Für ein bestimmtes Problem bedeutet ein niedrigerer Log Loss-Wert bessere Vorhersagen.
Mathematische Interpretation:
Log Loss ist der negative Durchschnitt des Logarithmus der korrigierten vorhergesagten Wahrscheinlichkeiten für jede Instanz.
Lassen Sie es uns anhand eines Beispiels verstehen:
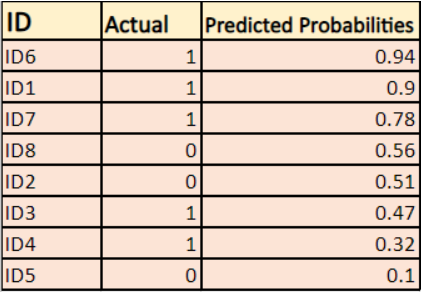
Das Modell liefert vorhergesagte Wahrscheinlichkeiten wie oben gezeigt.
Wie lauten die korrigierten Wahrscheinlichkeiten?
-> Standardmäßig ist die Ausgabe des logistischen Regressionsmodells die Wahrscheinlichkeit, dass die Stichprobe positiv ist (angegeben durch 1), d.h. wenn ein logistisches Regressionsmodell trainiert wird, um einen „Unternehmensdatensatz“ zu klassifizieren, dann steht in der Spalte „Vorhergesagte Wahrscheinlichkeit“: „Wie hoch ist die Wahrscheinlichkeit, dass die Person eine Jacke gekauft hat? Hier im obigen Datensatz ist die Wahrscheinlichkeit, dass eine Person mit ID6 eine Jacke kauft, 0,94.
Auf die gleiche Weise ist die Wahrscheinlichkeit, dass eine Person mit ID5 eine Jacke kauft (d.h. zu Klasse 1 gehört) 0,1, aber die tatsächliche Klasse für ID5 ist 0, also ist die Wahrscheinlichkeit für die Klasse (1-0,1)=0,9. 0,9 ist die korrekte Wahrscheinlichkeit für ID5.
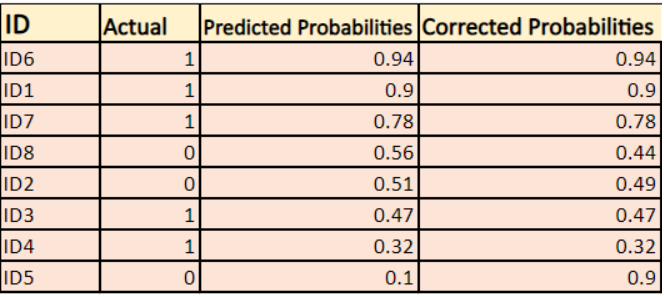
Wir werden einen Logarithmus der korrigierten Wahrscheinlichkeiten für jede Instanz finden.
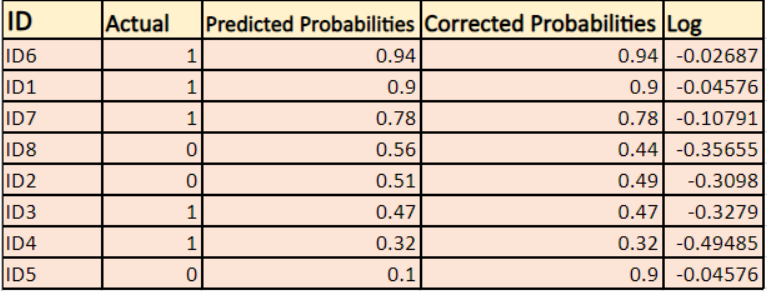
Wie Sie sehen können, sind diese Logarithmuswerte negativ. Um mit dem negativen Vorzeichen umzugehen, nehmen wir den negativen Durchschnitt dieser Werte, um die allgemeine Konvention beizubehalten, dass niedrigere Verlustwerte besser sind.
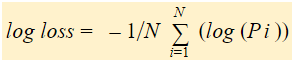
Kurz gesagt, es gibt drei Schritte, um den Log Loss zu finden:
-
Um korrigierte Wahrscheinlichkeiten zu finden.
-
Nimm einen Logarithmus der korrigierten Wahrscheinlichkeiten.
-
Nimm den negativen Durchschnitt der Werte, die wir im zweiten Schritt erhalten.
Wenn wir alle obigen Schritte zusammenfassen, können wir die Formel verwenden:-
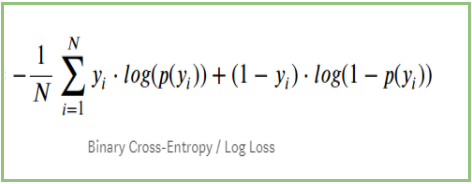
Hier steht Yi für die aktuelle Klasse und log(p(yi)ist die Wahrscheinlichkeit dieser Klasse.
-
p(yi) ist die Wahrscheinlichkeit von 1.
-
1-p(yi) ist die Wahrscheinlichkeit von 0.
Sehen wir uns nun an, wie die obige Formel in zwei Fällen funktioniert:
-
Wenn die tatsächliche Klasse 1 ist: Der zweite Term in der Formel wäre 0 und wir hätten nur noch den ersten Term, d.h. yi.log(p(yi)) und (1-1).log(1-p(yi)), was 0 ist.
-
Wenn die tatsächliche Klasse 0 ist: Der erste Term wäre 0 und es bleibt der zweite Term übrig, d.h. (1-yi).log(1-p(yi)) und 0.log(p(yi)) sind 0.
Wow!!! Damit sind wir wieder bei der ursprünglichen Formel für binäre Kreuzentropie/log Verlust 🙂
Die Vorteile der Logarithmierung werden deutlich, wenn man sich die Graphen der Kostenfunktionen für die aktuelle Klasse 1 und 0 ansieht:
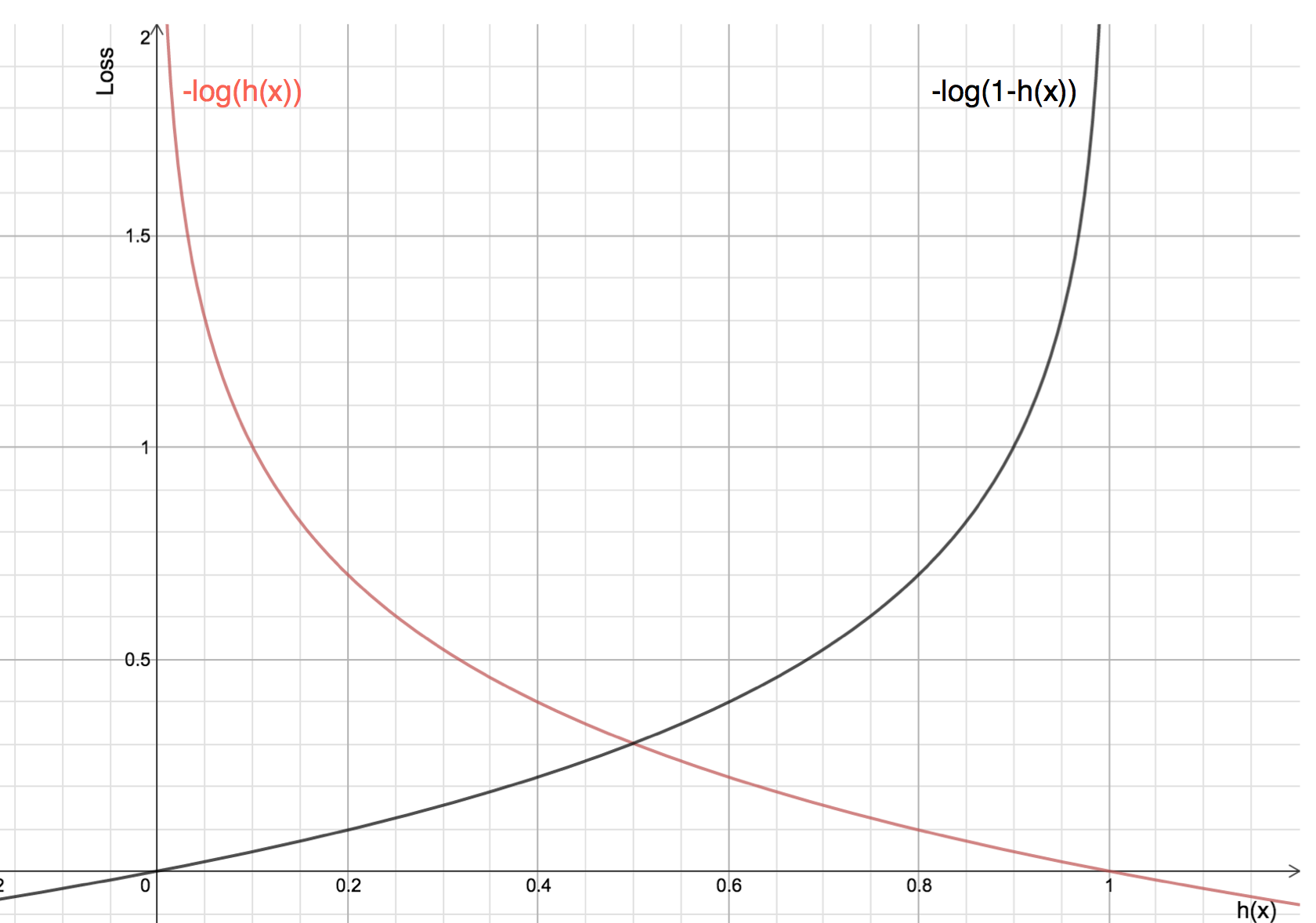
-
Die rote Linie steht für die Klasse 1. Wie wir sehen können, ist der Verlust geringer, wenn die vorhergesagte Wahrscheinlichkeit (x-Achse) nahe bei 1 liegt, und wenn die vorhergesagte Wahrscheinlichkeit nahe bei 0 liegt, nähert sich der Verlust unendlich.
-
Die schwarze Linie stellt die Klasse 0 dar. Wie wir sehen können, ist der Verlust geringer, wenn die vorhergesagte Wahrscheinlichkeit (x-Achse) nahe bei 0 liegt, und wenn die vorhergesagte Wahrscheinlichkeit nahe bei 1 liegt, nähert sich der Verlust dem Unendlichen.