This article was published as a part of the Data Science Blogathon.
概要
-
分類問題を解くために線形回帰モデルを使用する場合の課題
-
なぜMSEはロジスティック回帰のコスト関数として使用されないのでしょうか。
-
この記事では、Log Loss関数の背後にある数学について、簡単な例を使って説明します。
この記事の前提条件:
-
線形回帰
-
ロジスティック回帰
-
勾配降下
はじめに
<112>冬ですねぇ〜。 暖かいデータサイエンス問題で冬を迎えましょう 😉
ジャケットやカーディガンを製造しているアパレル会社を事例として考えてみましょう。 彼らは、顧客がジャケット(クラス1)とカーディガン(クラス0)のどちらを購入するかを過去の行動パターンから予測できるモデルを持ち、顧客のニーズに合わせて特定のオファーを提供できるようにしたいと考えています。
機械学習アルゴリズムを始めると、最初に学ぶのは「線形回帰」というアルゴリズムで、連続的な対象変数を予測するものです。
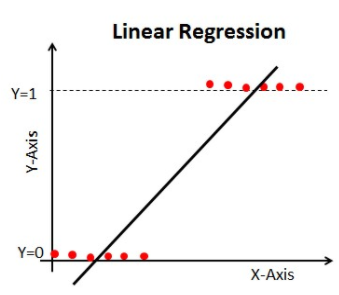
分類問題で線形回帰を使用すると、次のような最適な線が得られます:
Z = ßX + b
線形線の問題:
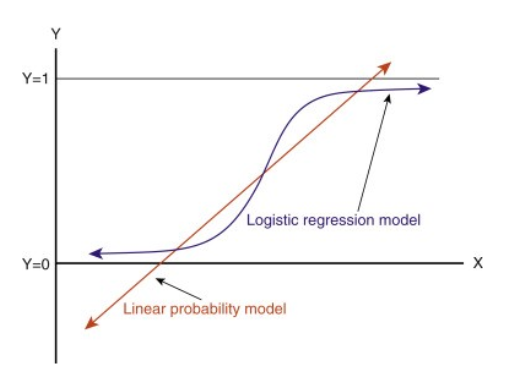
この線を伸ばすと 1 以上 0 以下の値があって、分類問題ではあまり意味のないものになってしまう。 これは、モデルの解釈を難しくします。 そこで登場するのが「ロジスティック回帰」です。 もし、ある店舗の売上を予測する必要があるなら、このモデルは役に立つかもしれません。
Q (Z) =1/1+ e-z (Sigmoid Function)
Ŷ =1/1+ e-z
変換後、0と1の間に残る直線を得られます。 この関数のもう一つの利点は、得られる連続値がすべて0と1の間にあることで、これを確率として予測を立てることができる。 たとえば、予測値が右端の場合、確率は 1 に近くなり、予測値が左端の場合、確率は 0 に近くなります。
正しいモデルの選択だけでは十分ではありません。 与えられたデータに対する機械学習モデルのパフォーマンスを測定する関数が必要である。 コスト関数は、予測値と期待値の誤差を定量化します。
`If you can’t measure it, you can’t improve it.`
この変換で変わるもう1つのことは、コスト関数です。
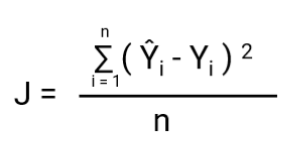
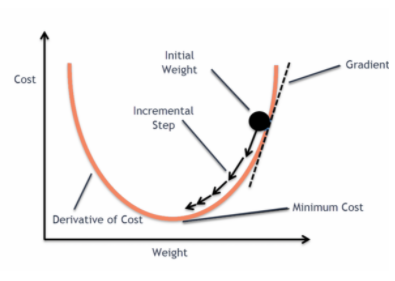
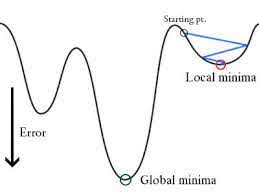
この誤差関数を線形回帰モデルの重みパラメータに対してプロットすると凸曲線になり、Gradient Descent Optimization Algorithm を適用してグローバルミニマムを見つけ、重みを調整することにより誤差を最小化できるようになる。
なぜロジスティック回帰のコスト関数として平均二乗誤差を使用しないのですか?
Logistic Regression では Ŷi は非線形関数 (Ŷ=1/1+ e-z) で、これを上記の MSE 式に当てはめると、次のように非凸関数になります:
-
Gradient Desent で値を最適化しようとするとグローバルミニマムを見つけるのに複雑になってしまうから。
-
もう一つの理由は、分類問題では 0/1 のような目標値があるため、(Ŷ-Y)2 は常に 0-1 の間になり、誤差を追跡するのが非常に難しく、高精度浮動小数点を保存するのが難しいからです。
Logistic Regressionで使用されるコスト関数はLog Lossです。
Log Lossとは?
Log Lossは確率に基づく分類指標の中で最も重要な指標です。 生の Log Loss 値を解釈するのは難しいですが、log-loss はモデルを比較するための良いメトリックであることには変わりありません。
Log Loss は、各インスタンスの補正された予測確率の対数の負の平均です。
例で見てみましょう。
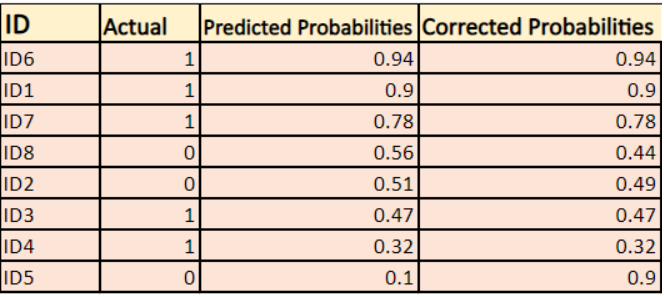
修正された確率は?
-> デフォルトでは、ロジスティック回帰モデルの出力は、サンプルが正である確率(1によって示される)です。 ここで上記のデータセットでは、ID6の人がジャケットを買う確率は0.94です。
同じように、ID5の人がジャケットを買う(つまりクラス1に属する)確率は0.1ですが、ID5の実際のクラスは0なので、クラスの確率は (1-0.1)=0.9 になっています。 0.9はID5の正しい確率です。
各インスタンスの修正確率のログを求めます。
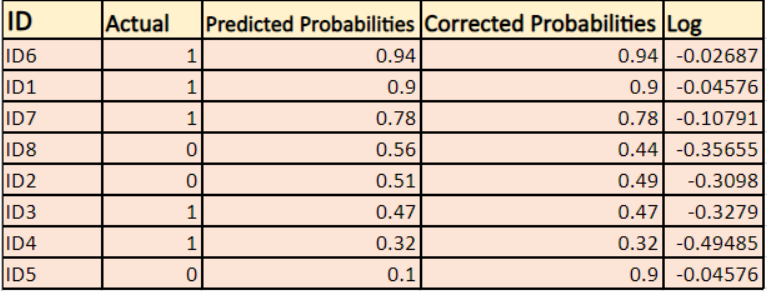
これらのログ値は見てわかるように負の値になっています。
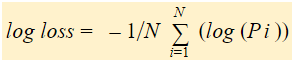
つまり、Log Lossを求めるには3つのステップがある:
-
補正確率を求めるには。
-
補正された確率の対数をとる。
-
第2ステップで得た値の負の平均をとる。
以上のステップをまとめると、以下の式が使える。
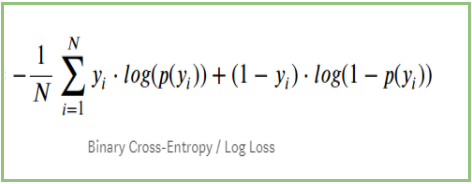
ここでYiは実際のクラス、log(p(yi))はそのクラスの確率を表している。
-
p(yi) は1の確率。
-
1-p(yi) は0の確率である。
さて、上の式が2つのケースでどのように働くか見てみましょう。
-
実際のクラスが1のとき:式の第2項は0となり、第1項、つまりyi.log(p(yi))と (1-1).log(1-p(yi)) は0となる
<6388>
すごい!!!
これは0になります。 となり、元の2値クロスエントロピー/log lossの式に戻る🙂
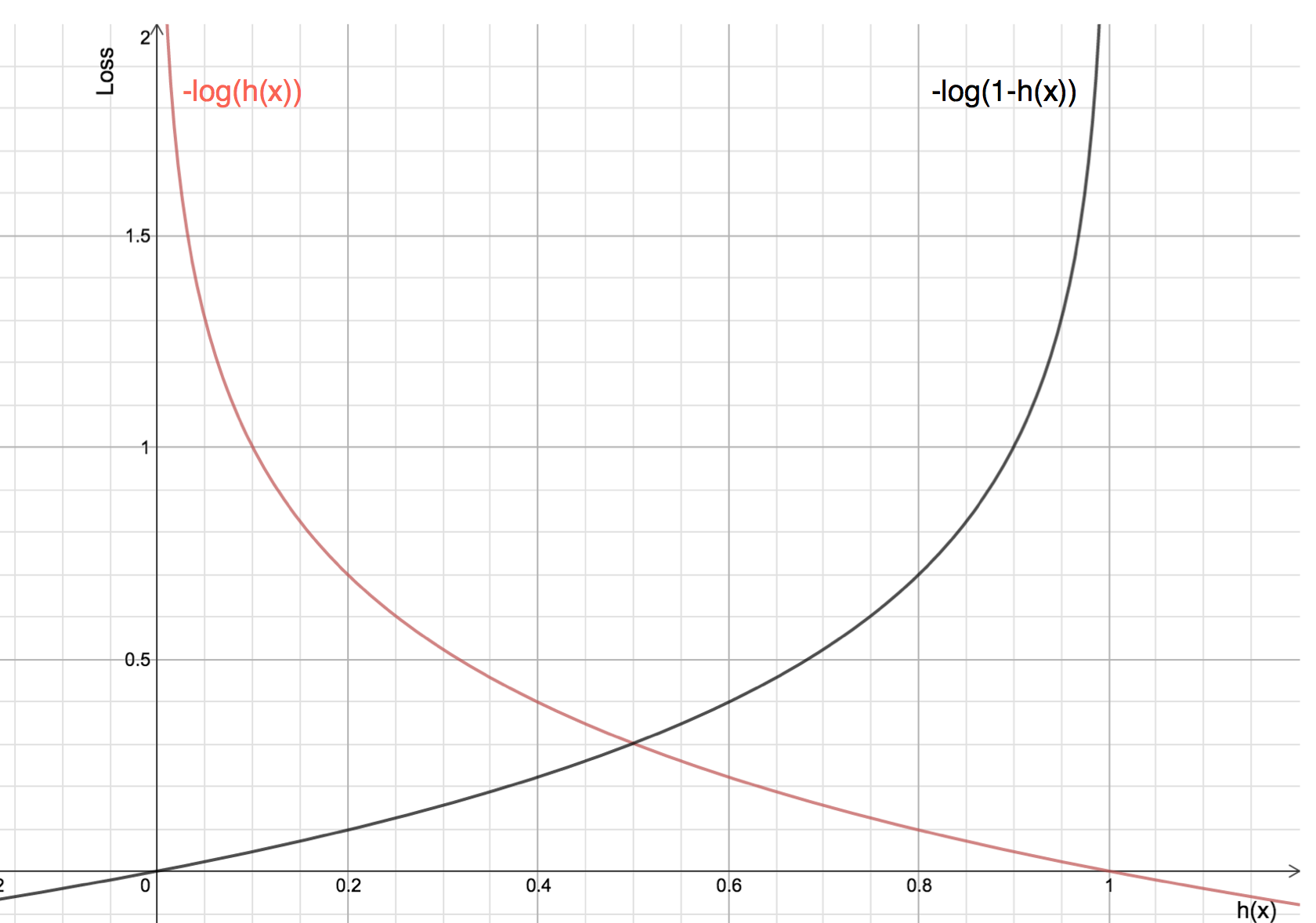
対数を取ることの利点は、実際のクラス1と0のコスト関数のグラフを見るとわかります:
-
赤い線が1クラスを表しています。 このように、予測確率(x軸)が1に近いほど損失は少なく、予測確率が0に近いと損失は無限大に近づく。
-
黒い線は0クラスを表す。 このように、予測確率(x軸)が0に近いと損失が少なく、予測確率が1に近いと損失が無限大に近づくことがわかる。