Denna artikel publicerades som en del av Data Science Blogathon.
- Översikt
- Förutsättningar för denna artikel:
- INLEDNING
- Problem med den linjära linjen:
- Varför använder vi inte `Mean Squared Error som kostnadsfunktion i logistisk regression?
- Vad är logförlust?
- Vad är de korrigerade sannolikheterna?
- Fördelarna med att ta logaritmen avslöjas när man tittar på kostnadsfunktionsgraferna för de faktiska klasserna 1 och 0 :
Översikt
-
Utmaningar om vi använder den linjära regressionsmodellen för att lösa ett klassificeringsproblem.
-
Varför används inte MSE som kostnadsfunktion i logistisk regression?
-
Denna artikel kommer att täcka matematiken bakom Log Loss-funktionen med ett enkelt exempel.
Förutsättningar för denna artikel:
-
Linjär regression
-
Logistisk regression
-
Gradient Descent
INLEDNING
`Vintern är här`. Låt oss välkomna vintern med ett varmt datavetenskapsproblem 😉
Låt oss ta en fallstudie av ett klädföretag som tillverkar jackor och koftor. De vill ha en modell som kan förutsäga om kunden kommer att köpa en jacka (klass 1) eller en kofta (klass 0) utifrån deras historiska beteendemönster så att de kan ge specifika erbjudanden enligt kundens behov. Som datavetare måste du hjälpa dem att bygga en prediktiv modell.
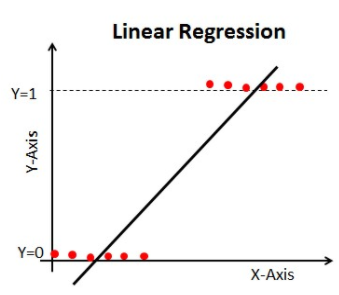
När vi börjar med algoritmer för maskininlärning är den första algoritmen vi lär oss om `linjär regression` där vi förutsäger en kontinuerlig målvariabel.
Om vi använder linjär regression i vårt klassificeringsproblem får vi en linje som passar bäst så här:
Z = ßX + b
Problem med den linjära linjen:
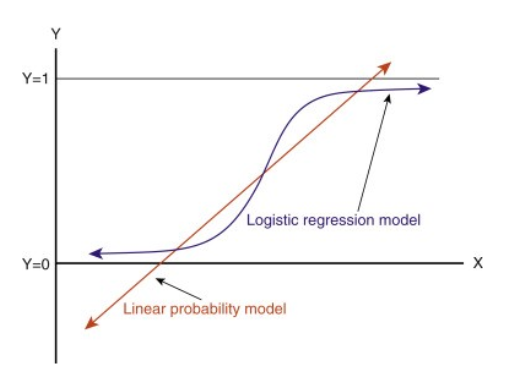
När du förlänger den här linjen får du värden som är större än 1 och mindre än 0, vilket inte ger någon större mening i vårt klassificeringsproblem. Det kommer att göra en modelltolkning till en utmaning. Det är där `Logistisk regression` kommer in i bilden. Om vi skulle behöva förutsäga försäljningen för ett försäljningsställe kan den här modellen vara till hjälp. Men här behöver vi klassificera kunder.
-Vi behöver en funktion för att omvandla denna raka linje på ett sådant sätt att värdena kommer att ligga mellan 0 och 1:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (Sigmoidfunktion)
Ŷ =1/1+ e-z
-Efter omvandlingen får vi en linje som ligger kvar mellan 0 och 1. En annan fördel med denna funktion är att alla kontinuerliga värden vi får kommer att ligga mellan 0 och 1, vilket vi kan använda som en sannolikhet för att göra förutsägelser. Till exempel, om det förutspådda värdet ligger längst till höger kommer sannolikheten att ligga nära 1 och om det förutspådda värdet ligger längst till vänster kommer sannolikheten att ligga nära 0.
Det räcker inte att välja rätt modell. Du behöver en funktion som mäter prestandan hos en maskininlärningsmodell för givna data. Kostnadsfunktionen kvantifierar felet mellan förutspådda värden och förväntade värden.
`Om du inte kan mäta det kan du inte förbättra det.`
En annan sak som kommer att förändras i och med denna omvandling är kostnadsfunktionen. I linjär regression använder vi `Mean Squared Error` för kostnadsfunktionen som ges av:-
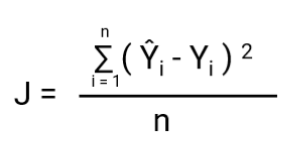
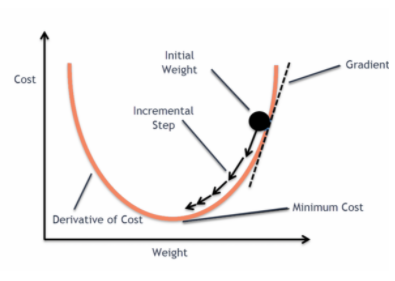
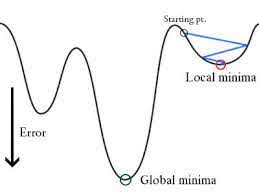
och när denna felfunktion plottas med avseende på viktparametrarna i den linjära regressionsmodellen, bildar den en konvex kurva som gör att den är lämplig för att tillämpa Gradient Descent-optimeringsalgoritmen för att minimera felet genom att hitta globala minima och justera vikterna.
Varför använder vi inte `Mean Squared Error som kostnadsfunktion i logistisk regression?
I logistisk regression är Ŷi en icke-linjär funktion (Ŷ=1/1+ e-z), om vi sätter in detta i ovanstående MSE-ekvation kommer det att ge en icke-konvex funktion enligt följande:
-
När vi försöker optimera värdena med hjälp av gradient descent kommer det att skapa komplikationer för att hitta globala minima.
-
En annan anledning är att vi i klassificeringsproblem har målvärden som 0/1, så (Ŷ-Y)2 kommer alltid att ligga mellan 0-1, vilket kan göra det mycket svårt att hålla reda på felen och det är svårt att lagra flytande tal med hög precision.
Kostnadsfunktionen som används i logistisk regression är logförlust.
Vad är logförlust?
Logförlust är det viktigaste klassificeringsmåttet baserat på sannolikheter. Det är svårt att tolka råa logförlustvärden, men logförlust är ändå ett bra mått för att jämföra modeller. För ett givet problem innebär ett lägre logförlustvärde bättre förutsägelser.
Matematisk tolkning:
Logförlust är det negativa genomsnittet av logvärdet för korrigerade förutsägda sannolikheter för varje instans.
Låt oss förstå det med ett exempel:
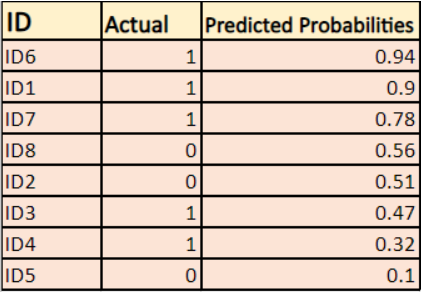
Modellen ger förutsägda sannolikheter som visas ovan.
Vad är de korrigerade sannolikheterna?
-> Som standard är resultatet av den logistiska regressionsmodellen sannolikheten för att provet är positivt (indikerat med 1), dvs. om en logistisk regressionsmodell tränas för att klassificera ett företagsdataset står det i kolumnen för förutsedd sannolikhet: Vad är sannolikheten för att personen har köpt en jacka? I ovanstående dataset är sannolikheten för att en person med ID6 kommer att köpa en jacka 0,94.
På samma sätt är sannolikheten för att en person med ID5 kommer att köpa en jacka (dvs. tillhör klass 1) 0,1, men den faktiska klassen för ID5 är 0, så sannolikheten för klassen är (1-0,1)=0,9. 0,9 är den korrekta sannolikheten för ID5.
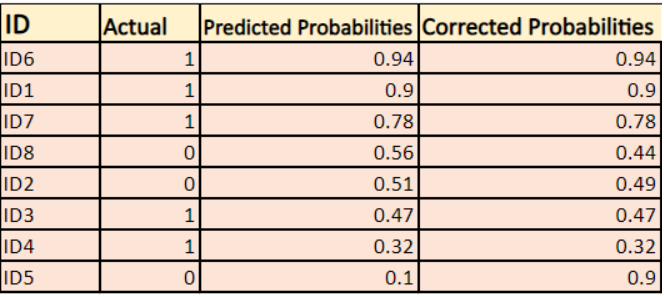
Vi kommer att hitta en log av de korrigerade sannolikheterna för varje instans.
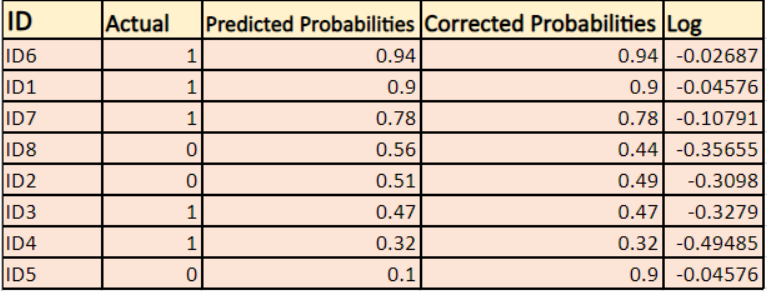
Som ni kan se är dessa logvärden negativa. För att hantera det negativa tecknet tar vi det negativa genomsnittet av dessa värden, för att upprätthålla en vanlig konvention om att lägre förlustvärden är bättre.
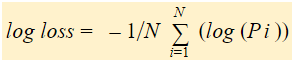
Kort sagt finns det tre steg för att hitta logförlust:
-
För att hitta korrigerade sannolikheter.
-
Ta en log av korrigerade sannolikheter.
-
Ta det negativa medelvärdet av de värden vi får i steg 2.
Om vi sammanfattar alla ovanstående steg kan vi använda formeln:-
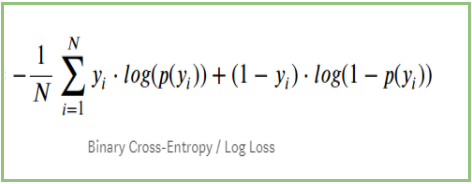
Här representerar Yi den faktiska klassen och log(p(yi)är sannolikheten för denna klass.
-
p(yi) är sannolikheten för 1.
-
1-p(yi) är sannolikheten för 0.
Nu ska vi se hur ovanstående formel fungerar i två fall:
-
När den faktiska klassen är 1: den andra termen i formeln skulle vara 0 och vi kommer att ha kvar den första termen, dvs. yi.log(p(yi)) och (1-1).log(1-p(yi)), vilket kommer att vara 0.
-
När den faktiska klassen är 0: Den första termen skulle vara 0 och kommer att lämnas med den andra termen, dvs. (1-yi).log(1-p(yi)) och 0.log(p(yi)) kommer att vara 0.
Wow!!! Vi har återgått till den ursprungliga formeln för binär korsentropi/logförlust 🙂
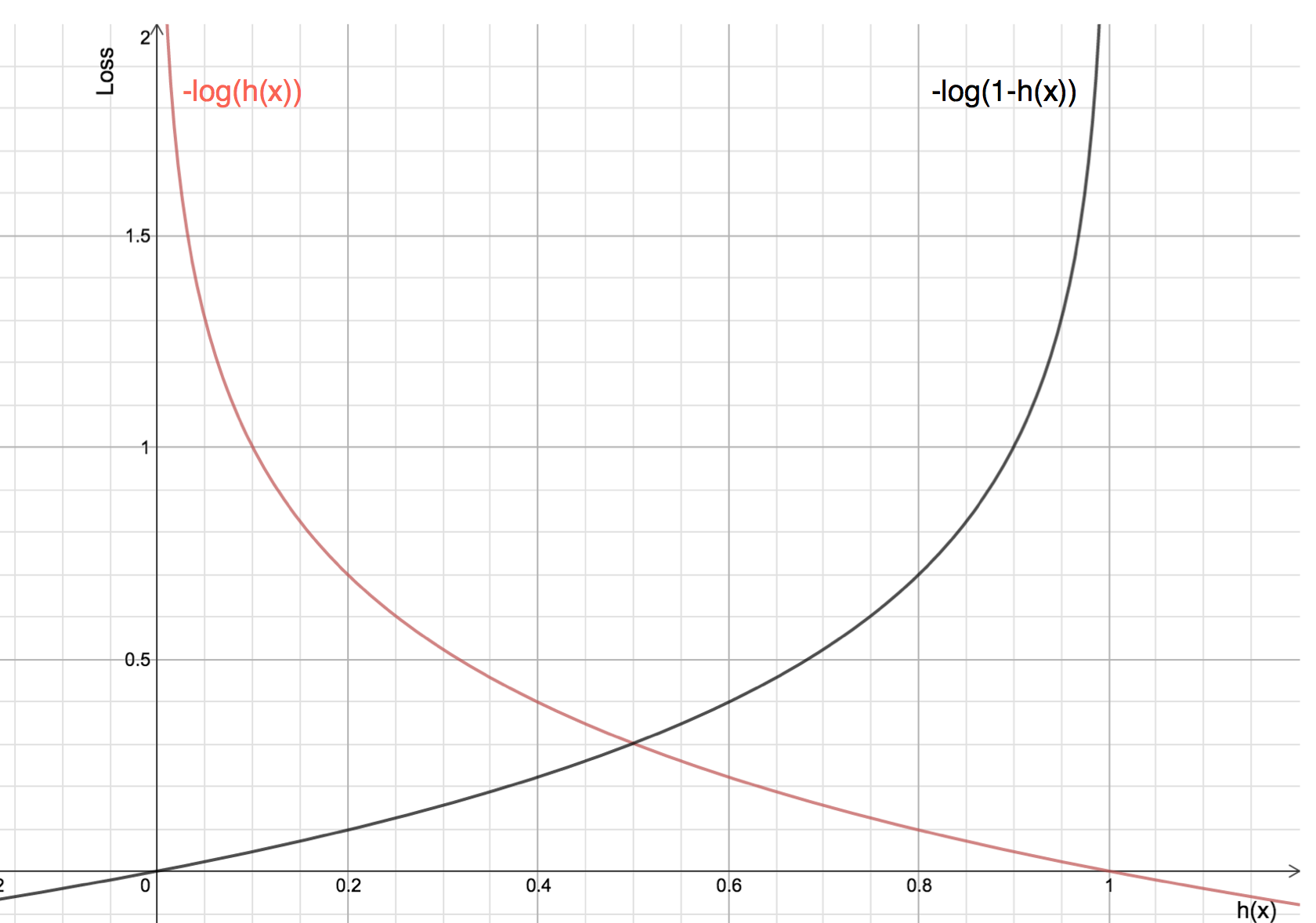
Fördelarna med att ta logaritmen avslöjas när man tittar på kostnadsfunktionsgraferna för de faktiska klasserna 1 och 0 :
-
Den röda linjen representerar 1 klass. Som vi kan se är förlusten mindre när den förutspådda sannolikheten (x-axeln) ligger nära 1, och när den förutspådda sannolikheten ligger nära 0 närmar sig förlusten oändligheten.
-
Den svarta linjen representerar 0 klass. Som vi kan se är förlusten mindre när den förutspådda sannolikheten (x-axeln) ligger nära 0, och när den förutspådda sannolikheten ligger nära 1, närmar sig förlusten oändligheten.