Este artigo foi publicado como parte da Data Science Blogathon.
- Visão geral
- Prrequisitos para este artigo:
- INTRODUÇÃO
- Problema com a linha linear:
- Por que não utilizamos o `Mean Squared Error como função de custo na Regressão Logística?
- O que é Log Loss?
- Quais são as probabilidades corrigidas?
- Os benefícios de tomar logaritmo se revelam quando você olha os gráficos de função de custo para a classe real 1 e 0 :
Visão geral
-
Desafios se usarmos o modelo de Regressão Linear para resolver um problema de classificação.
-
Por que o MSE não é usado como função de custo em Regressão Logística?
-
Este artigo irá cobrir a matemática por detrás da função de Perda de Log com um exemplo simples.
Prrequisitos para este artigo:
-
Regressão Linear
-
Regressão Lógica
-
Descida de Gradiente
INTRODUÇÃO
`Inverno está aqui`. Vamos dar as boas vindas aos Invernos com um problema de dados científicos quentes 😉
Vamos fazer um estudo de caso de uma empresa de vestuário que fabrica casacos e casacos de malha. Eles querem ter um modelo que possa prever se o cliente vai comprar um casaco (classe 1) ou um casaco (classe 0) a partir do seu padrão histórico de comportamento para que eles possam dar ofertas específicas de acordo com as necessidades do cliente. Como cientista de dados, você precisa ajudá-los a construir um modelo preditivo.
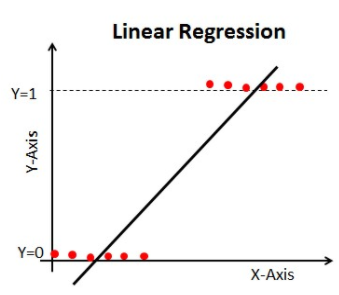
Quando iniciamos os algoritmos de Machine Learning, o primeiro algoritmo que aprendemos é ‘Regressão Linear’, no qual prevemos uma variável alvo contínua.
Se utilizarmos Regressão Linear no nosso problema de classificação, obteremos uma linha de melhor ajuste como esta:
Z = ßX + b
Problema com a linha linear:
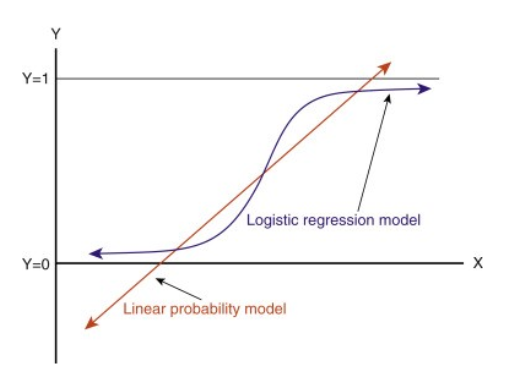
Quando você estender esta linha, você terá valores maiores que 1 e menores que 0, o que não faz muito sentido no nosso problema de classificação. Isto fará da interpretação de um modelo um desafio. É aí que entra a ‘Regressão Lógica’. Se precisarmos de prever as vendas para um ponto de venda, então este modelo pode ser útil. Mas aqui precisamos classificar os clientes.
– Precisamos de uma função para transformar esta linha reta de tal forma que os valores fiquem entre 0 e 1:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (Função Sigmoid)
Ŷ =1/1+ e-z
-Após a transformação, obteremos uma linha que permanecerá entre 0 e 1. Outra vantagem desta função é que todos os valores contínuos que vamos obter estarão entre 0 e 1, o que podemos usar como probabilidade para fazer previsões. Por exemplo, se o valor previsto estiver na extrema direita, a probabilidade será próxima de 1 e se o valor previsto estiver na extrema esquerda, a probabilidade será próxima de 0,
Selecionar o modelo direito não é suficiente. Você precisa de uma função que meça o desempenho de um modelo de Aprendizagem de Máquina para determinados dados. Cost Function quantifica o erro entre valores previstos e valores esperados.
`Se você não pode medi-lo, você não pode melhorá-lo.`
-A outra coisa que vai mudar com esta transformação é Cost Function. Em Regressão Linear, utilizamos `Mean Squared Error` para a função Custo dado por:-
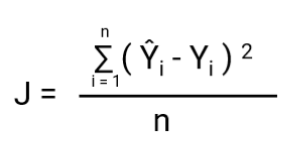
e quando esta função de erro é plotada em relação aos parâmetros de peso do Modelo de Regressão Linear, ela forma uma curva convexa que a torna elegível para aplicar o Algoritmo de Otimização de Descida Gradiente para minimizar o erro, encontrando mínimos globais e ajustando os pesos.
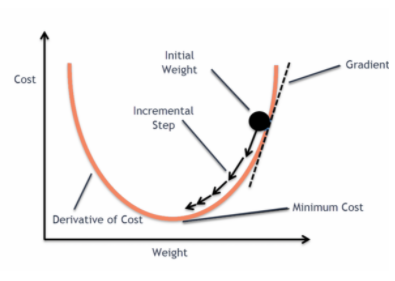
Por que não utilizamos o `Mean Squared Error como função de custo na Regressão Logística?
Na Regressão Logística Ŷi é uma função não linear(Ŷ=1/1+ e-z), se colocarmos isto na equação MSE acima dará uma função não convexa como mostrado:
-
Quando tentamos otimizar valores usando descida de gradiente criará complicações para encontrar mínimos globais.
-
Outra razão está em problemas de classificação, temos valores alvo como 0/1, Então (Ŷ-Y)2 estará sempre entre 0-1 o que pode dificultar muito o acompanhamento dos erros e é difícil armazenar números flutuantes de alta precisão.
A função de custo utilizada na Regressão Logística é Log Loss.
O que é Log Loss?
Log Loss é a métrica de classificação mais importante baseada em probabilidades. É difícil interpretar os valores de perda de log em bruto, mas a perda de log ainda é uma boa métrica para comparar modelos. Para qualquer problema, um valor menor de perda de log significa melhores previsões.
Interpretação matemática:
Perda de log é a média negativa do log das probabilidades previstas corrigidas para cada instância.
Deixe-nos entender com um exemplo:
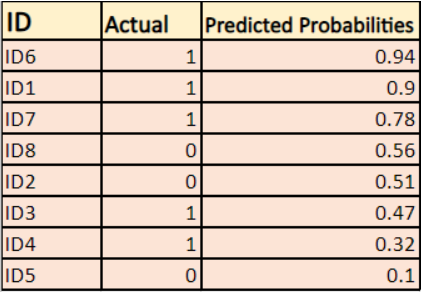
O modelo está dando probabilidades previstas como mostrado acima.
Quais são as probabilidades corrigidas?
-> Por padrão, a saída do modelo de regressão logística é a probabilidade da amostra ser positiva(indicada por 1), ou seja, se um modelo de regressão logística é treinado para classificar em um “conjunto de dados da empresa” então a coluna de probabilidade prevista diz Qual é a probabilidade de a pessoa ter comprado o casaco. Aqui no conjunto de dados acima a probabilidade de uma pessoa com ID6 comprar um casaco é 0.94.
Da mesma forma, a probabilidade de uma pessoa com ID5 comprar um casaco (ou seja, pertencer à classe 1) é 0.1 mas a classe real para ID5 é 0, então a probabilidade para a classe é (1-0.1)=0.9. 0,9 é a probabilidade correta para ID5.
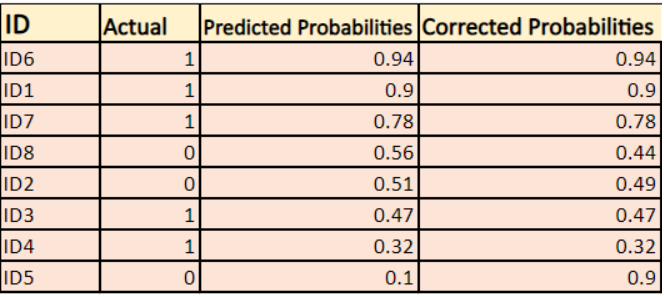
Encontraremos um log de probabilidades corrigidas para cada instância.
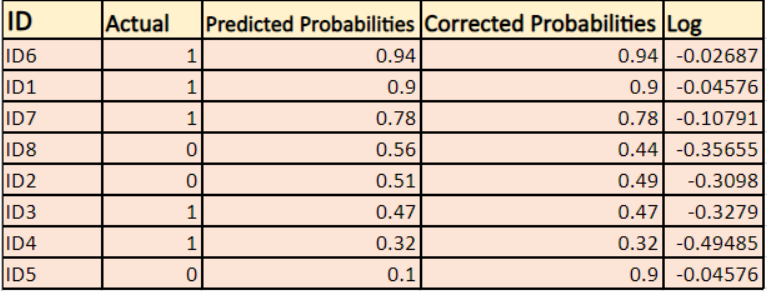
Como você pode ver estes valores de log são negativos. Para lidar com o sinal negativo, tomamos a média negativa desses valores, para manter uma convenção comum de que os valores de perda mais baixos são melhores.
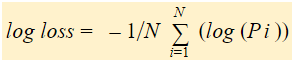
Em resumo, há três passos para encontrar o log de perda:
-
Para encontrar probabilidades corrigidas.
-
Tirar um log das probabilidades corrigidas.
-
Tirar a média negativa dos valores que obtemos no 2º passo.
Se resumirmos todos os passos acima, podemos usar a fórmula:-
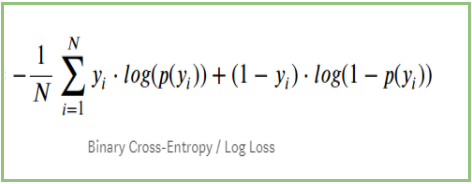
Aqui Yi representa a classe real e log(p(yi)é a probabilidade dessa classe.
-
p(yi) é a probabilidade de 1.
-
1-p(yi) é a probabilidade de 0.
Agora vamos ver como a fórmula acima está funcionando em dois casos:
-
Quando a classe real é 1: o segundo termo na fórmula seria 0 e nós vamos sair com o primeiro termo i.e. yi.log(p(yi)) e (1-1).log(1-p(yi) isto será 0.
-
Quando a classe real é 0: O primeiro termo seria 0 e será deixado com o segundo termo i.e. (1-yi).log(1-p(yi)) e 0.log(p(yi)) será 0.
wow!! voltamos à fórmula original para cross-entropy/log loss 🙂
Os benefícios de tomar logaritmo se revelam quando você olha os gráficos de função de custo para a classe real 1 e 0 :
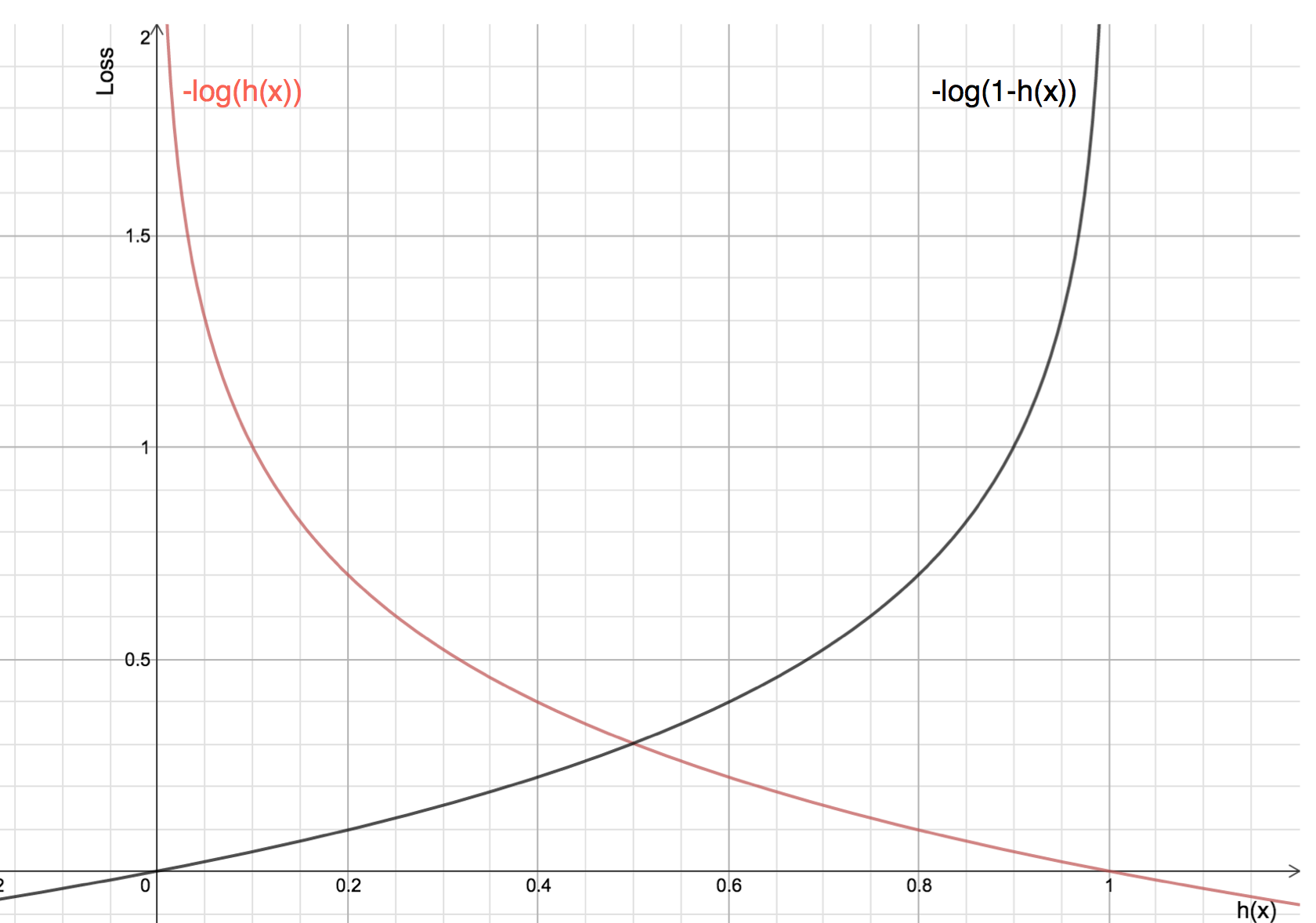
-
A linha Vermelha representa 1 classe. Como podemos ver, quando a probabilidade prevista (eixo x) está próxima de 1, a perda é menor e quando a probabilidade prevista está próxima de 0, a perda aproxima-se do infinito.
-
A linha Preta representa a classe 0. Como podemos ver, quando a probabilidade prevista (eixo x) está próxima de 0, a perda é menor e quando a probabilidade prevista está próxima de 1, a perda se aproxima do infinito.