Ten artykuł został opublikowany jako część Data Science Blogathon.
- Przegląd
- Wymagania wstępne dla tego artykułu:
- WPROWADZENIE
- Problem z linią liniową:
- Dlaczego nie używamy `Mean Squared Error` jako funkcji kosztu w Regresji Logistycznej?
- What is Log Loss?
- Jakie są poprawione prawdopodobieństwa?
- Korzyści z przyjmowania logarytmu ujawniają się, gdy spojrzymy na wykresy funkcji kosztu dla rzeczywistych klas 1 i 0 :
Przegląd
-
Wyzwania, jeśli używamy modelu Regresji Liniowej do rozwiązania problemu klasyfikacji.
-
Dlaczego MSE nie jest używane jako funkcja kosztu w Regresji Logistycznej?
-
W tym artykule omówiona zostanie matematyka stojąca za funkcją Log Loss na prostym przykładzie.
Wymagania wstępne dla tego artykułu:
-
Regresja liniowa
-
Regresja logistyczna
-
Gradient Descent
WPROWADZENIE
`Zima nadeszła`. Przywitajmy zimy ciepłym problemem data science 😉
Przyjmijmy case study firmy odzieżowej, która produkuje kurtki i kardigany. Chcą mieć model, który będzie w stanie przewidzieć czy klient kupi kurtkę (klasa 1) czy kardigan(klasa 0) na podstawie jego historycznego wzorca zachowań, tak aby móc dawać konkretne oferty zgodne z potrzebami klienta. Jako naukowiec danych musisz pomóc im zbudować model predykcyjny.
Gdy zaczynamy algorytmy uczenia maszynowego, pierwszym algorytmem, o którym się dowiadujemy, jest `regresja liniowa`, w której przewidujemy ciągłą zmienną docelową.
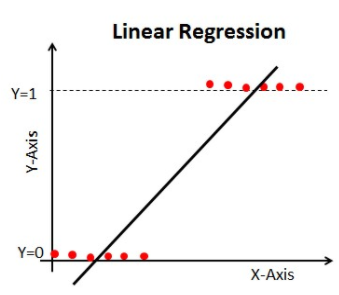
Jeśli użyjemy regresji liniowej w naszym problemie klasyfikacyjnym, otrzymamy najlepiej dopasowaną linię, taką jak ta:
Z = ßX + b
Problem z linią liniową:
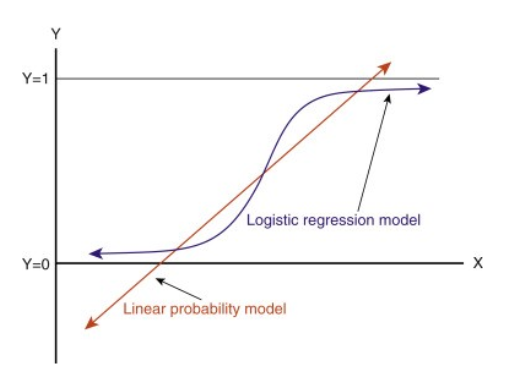
Gdy przedłużymy tę linię, otrzymamy wartości większe niż 1 i mniejsze niż 0, które nie mają większego sensu w naszym problemie klasyfikacyjnym. To sprawi, że interpretacja modelu będzie wyzwaniem. To jest miejsce, gdzie `regresja logistyczna` wchodzi w grę. Jeśli potrzebowalibyśmy przewidzieć sprzedaż dla danego punktu sprzedaży, wtedy ten model mógłby być pomocny. Ale tutaj musimy sklasyfikować klientów.
-Potrzebujemy funkcji do przekształcenia tej linii prostej w taki sposób, aby wartości mieściły się w przedziale od 0 do 1:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (funkcja sigmoidalna)
Ŷ =1/1+ e-z
Po przekształceniu otrzymamy linię, która mieści się w przedziale od 0 do 1. Inną zaletą tej funkcji jest to, że wszystkie wartości ciągłe, które otrzymamy będą pomiędzy 0 a 1, co możemy wykorzystać jako prawdopodobieństwo do tworzenia przewidywań. Na przykład, jeśli przewidywana wartość jest po skrajnej prawej stronie, prawdopodobieństwo będzie bliskie 1, a jeśli przewidywana wartość jest po skrajnej lewej stronie, prawdopodobieństwo będzie bliskie 0.
Wybór odpowiedniego modelu to nie wszystko. Potrzebujesz funkcji, która mierzy wydajność modelu uczenia maszynowego dla danych. Funkcja kosztu określa błąd pomiędzy wartościami przewidywanymi a oczekiwanymi.
`Jeśli nie możesz tego zmierzyć, nie możesz tego poprawić.`
Inną rzeczą, która zmieni się wraz z tą transformacją jest funkcja kosztu. W regresji liniowej, używamy `Mean Squared Error` dla funkcji kosztu danej przez:-
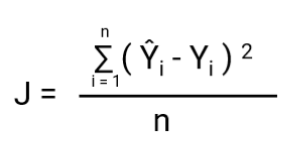
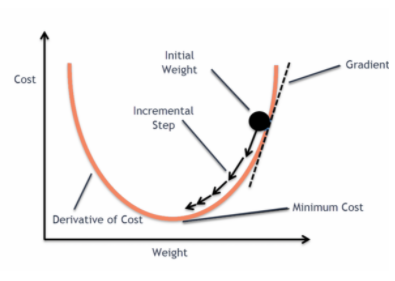
i kiedy ta funkcja błędu jest wykreślona w odniesieniu do parametrów wagowych modelu regresji liniowej, tworzy krzywą wypukłą, która kwalifikuje się do zastosowania algorytmu optymalizacji zstępującej Gradienta w celu minimalizacji błędu poprzez znalezienie minimów globalnych i dostosowanie wag.
Dlaczego nie używamy `Mean Squared Error` jako funkcji kosztu w Regresji Logistycznej?
W regresji logistycznej Ŷi jest funkcją nieliniową (Ŷ=1/1+ e-z), jeśli podstawimy to do powyższego równania MSE, otrzymamy funkcję niewypukłą, jak pokazano na rysunku:
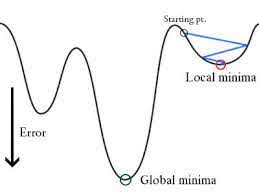
-
Gdy spróbujemy zoptymalizować wartości używając zejścia gradientowego, spowoduje to komplikacje w znalezieniu minimów globalnych.
-
Innym powodem jest to, że w problemach z klasyfikacją mamy wartości docelowe takie jak 0/1, więc (Ŷ-Y)2 zawsze będzie w przedziale 0-1, co może bardzo utrudnić śledzenie błędów i trudno jest przechowywać liczby zmiennoprzecinkowe o wysokiej precyzji.
Funkcją kosztu używaną w regresji logistycznej jest Log Loss.
What is Log Loss?
Log Loss jest najważniejszą metryką klasyfikacyjną opartą na prawdopodobieństwach. Trudno jest zinterpretować surowe wartości log-loss, ale log-loss jest nadal dobrą metryką do porównywania modeli. Dla danego problemu niższa wartość log loss oznacza lepsze przewidywania.
Interpretacja matematyczna:
Log Loss jest ujemną średnią logu skorygowanych przewidywanych prawdopodobieństw dla każdej instancji.
Zrozummy to na przykładzie:
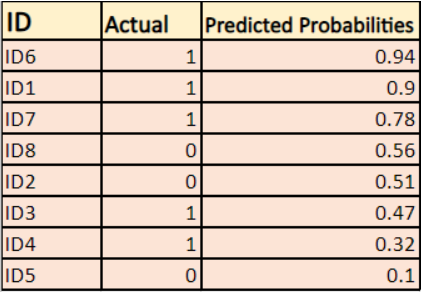
Model daje przewidywane prawdopodobieństwa, jak pokazano powyżej.
Jakie są poprawione prawdopodobieństwa?
-> Domyślnie, wyjście modelu regresji logistycznej jest prawdopodobieństwem, że próbka jest pozytywna (oznaczona przez 1), tzn. jeśli model regresji logistycznej jest szkolony do klasyfikacji na `zestawie danych firmy`, wtedy kolumna przewidywanego prawdopodobieństwa mówi Jakie jest prawdopodobieństwo, że osoba kupiła kurtkę. W powyższym zestawie danych prawdopodobieństwo, że osoba z ID6 kupi kurtkę wynosi 0.94.
W ten sam sposób prawdopodobieństwo, że osoba z ID5 kupi kurtkę (tj. należy do klasy 1) wynosi 0.1, ale rzeczywista klasa dla ID5 wynosi 0, więc prawdopodobieństwo dla klasy wynosi (1-0.1)=0.9. 0,9 jest poprawnym prawdopodobieństwem dla ID5.
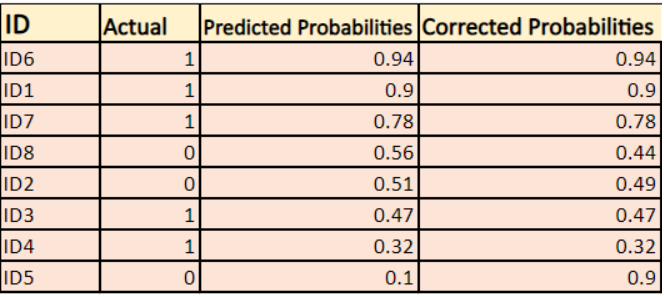
Znajdziemy log poprawionych prawdopodobieństw dla każdej instancji.
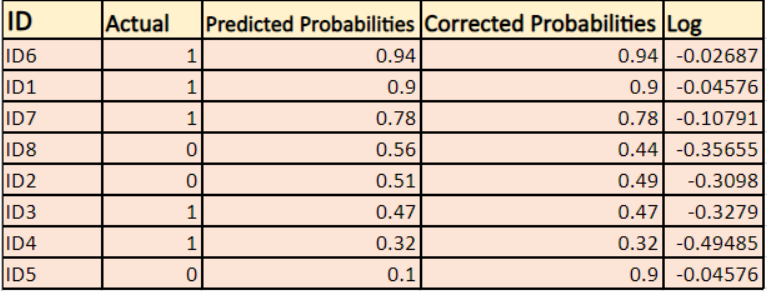
Jak widać te wartości log są ujemne. Aby poradzić sobie z ujemnym znakiem, bierzemy ujemną średnią tych wartości, aby utrzymać wspólną konwencję, że niższe wyniki strat są lepsze.
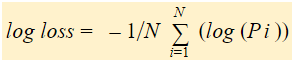
W skrócie, istnieją trzy kroki, aby znaleźć Log Loss:
-
Aby znaleźć skorygowane prawdopodobieństwa.
-
Pobierz log skorygowanych prawdopodobieństw.
-
Pobierz ujemną średnią z wartości, które otrzymaliśmy w drugim kroku.
Jeśli podsumujemy wszystkie powyższe kroki, możemy użyć wzoru:-
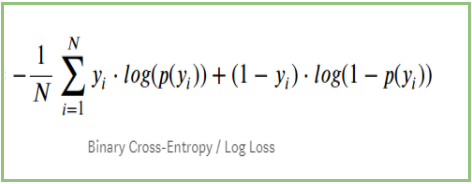
Tutaj Yi reprezentuje rzeczywistą klasę, a log(p(yi)jest prawdopodobieństwem tej klasy.
-
p(yi) jest prawdopodobieństwem równym 1.
-
1-p(yi) jest prawdopodobieństwem równym 0.
Teraz zobaczmy jak powyższy wzór działa w dwóch przypadkach:
-
Gdy klasa rzeczywista jest 1: drugi termin we wzorze będzie 0 i pozostanie nam pierwszy termin tj. yi.log(p(yi)) i (1-1).log(1-p(yi)) to będzie 0.
-
Gdy klasa rzeczywista jest 0: Pierwszy termin wynosiłby 0 i zostanie nam drugi termin tj (1-yi).log(1-p(yi)) i 0.log(p(yi)) to będzie 0.
wow!!! wróciliśmy do oryginalnego wzoru na binarną entropię krzyżową/log loss 🙂
Korzyści z przyjmowania logarytmu ujawniają się, gdy spojrzymy na wykresy funkcji kosztu dla rzeczywistych klas 1 i 0 :
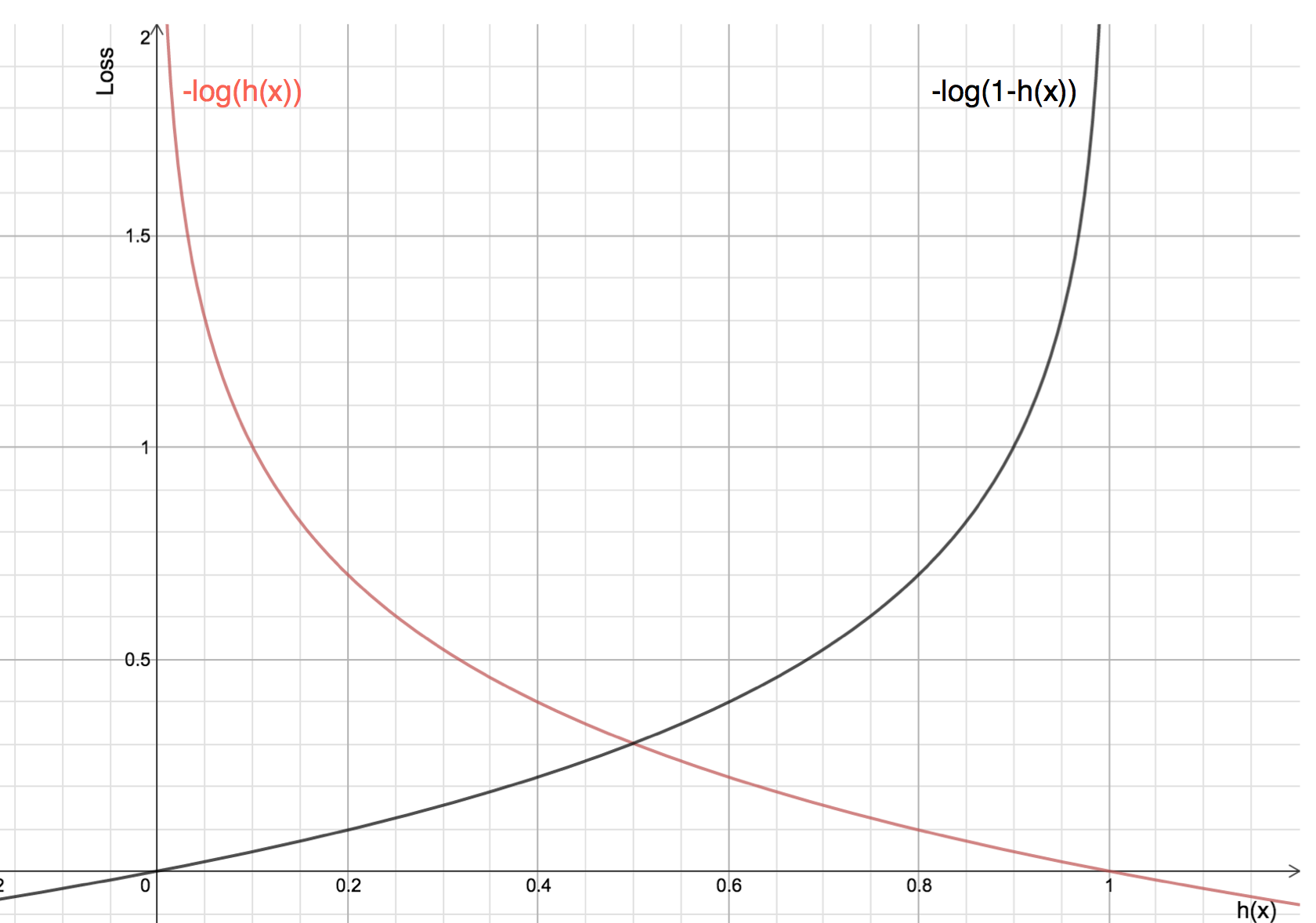
-
Czerwona linia reprezentuje 1 klasę. Jak widzimy, gdy przewidywane prawdopodobieństwo (oś x) jest bliskie 1, strata jest mniejsza, a gdy przewidywane prawdopodobieństwo jest bliskie 0, strata zbliża się do nieskończoności.
-
Czarna linia reprezentuje 0 klas. Jak widzimy, gdy przewidywane prawdopodobieństwo (oś x) jest bliskie 0, strata jest mniejsza, a gdy przewidywane prawdopodobieństwo jest bliskie 1, strata zbliża się do nieskończoności.
.