Denne artikel blev offentliggjort som en del af Data Science Blogathon.
- Overblik
- Forudsætninger for denne artikel:
- INLEDNING
- Problem med den lineære linje:
- Hvorfor bruger vi ikke `Mean Squared Error som en omkostningsfunktion i logistisk regression?
- Hvad er Log Loss?
- Hvad er de korrigerede sandsynligheder?
- Fordelene ved at tage logaritmen afslører sig selv, når man ser på omkostningsfunktionsgraferne for den faktiske klasse 1 og 0 :
Overblik
-
Udfordringer, hvis vi bruger den lineære regressionsmodel til at løse et klassifikationsproblem.
-
Hvorfor bruges MSE ikke som omkostningsfunktion i Logistisk Regression?
-
Denne artikel vil dække matematikken bag Log Loss-funktionen med et simpelt eksempel.
Forudsætninger for denne artikel:
-
Linær regression
-
Logistisk regression
-
Gradient Descent
INLEDNING
`Vinteren er her`. Lad os byde vinteren velkommen med et varmt datavidenskabeligt problem 😉
Lad os tage et casestudie af en tøjvirksomhed, der fremstiller jakker og cardigans. De ønsker at have en model, der kan forudsige, om kunden vil købe en jakke (klasse 1) eller en cardigan(klasse 0) ud fra deres historiske adfærdsmønster, således at de kan give specifikke tilbud i henhold til kundens behov. Som datalog skal du hjælpe dem med at opbygge en forudsigelsesmodel.
Når vi begynder på Machine Learning-algoritmer, er den første algoritme, vi lærer om, `Linear Regression`, hvor vi forudsiger en kontinuerlig målvariabel.
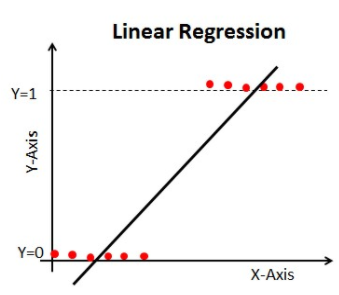
Hvis vi bruger lineær regression i vores klassifikationsproblem, får vi en linje med den bedste tilpasning som denne:
Z = ßX + b
Problem med den lineære linje:
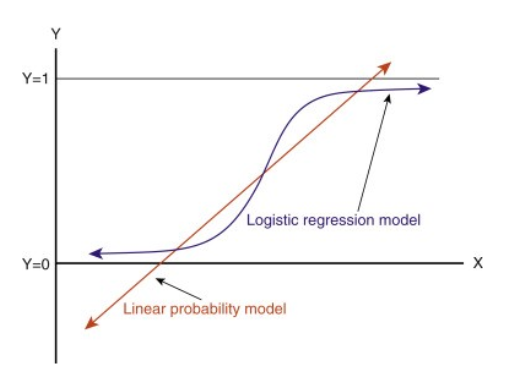
Når du forlænger denne linje, vil du få værdier større end 1 og mindre end 0, hvilket ikke giver meget mening i vores klassifikationsproblem. Det vil gøre en modelfortolkning til en udfordring. Det er her `Logistisk regression` kommer ind i billedet. Hvis vi havde brug for at forudsige salget for en forretning, kunne denne model være nyttig. Men her skal vi klassificere kunder.
-Vi har brug for en funktion til at transformere denne lige linje på en sådan måde, at værdierne vil ligge mellem 0 og 1:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (Sigmoidfunktion)
Ŷ =1/1+ e-z
-Efter transformationen får vi en linje, der forbliver mellem 0 og 1. En anden fordel ved denne funktion er, at alle de kontinuerte værdier, vi får, vil ligge mellem 0 og 1, hvilket vi kan bruge som en sandsynlighed til at lave forudsigelser. Hvis den forudsagte værdi f.eks. ligger yderst til højre, vil sandsynligheden være tæt på 1, og hvis den forudsagte værdi ligger yderst til venstre, vil sandsynligheden være tæt på 0.
Det er ikke nok at vælge den rigtige model. Du har brug for en funktion, der måler præstationen af en maskinlæringsmodel for givne data. Cost Function kvantificerer fejlen mellem forudsagte værdier og forventede værdier.
`Hvis du ikke kan måle det, kan du ikke forbedre det.`
En anden ting, der vil ændre sig med denne transformation, er Cost Function. I lineær regression bruger vi `Mean Squared Error` til omkostningsfunktion givet ved:-
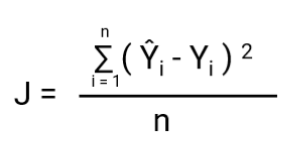
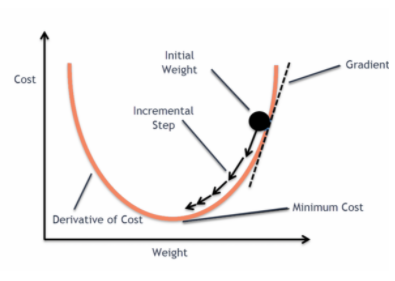
og når denne fejlfunktion plottes med hensyn til vægtparametre i den lineære regressionsmodel, danner den en konveks kurve, hvilket gør den berettiget til at anvende Gradient Descent Optimization Algorithm for at minimere fejlen ved at finde globale minima og justere vægte.
Hvorfor bruger vi ikke `Mean Squared Error som en omkostningsfunktion i logistisk regression?
I logistisk regression er Ŷi en ikke-lineær funktion(Ŷ=1/1+ e-z), hvis vi sætter dette ind i ovenstående MSE-ligning vil det give en ikke-konveks funktion som vist:
-
Når vi forsøger at optimere værdier ved hjælp af gradient descent vil det skabe komplikationer for at finde globale minima.
-
En anden grund er, at vi i klassifikationsproblemer har målværdier som 0/1, så (Ŷ-Y)2 vil altid ligge mellem 0-1, hvilket kan gøre det meget svært at holde styr på fejlene, og det er svært at lagre flydende tal med høj præcision.
Den omkostningsfunktion, der anvendes i logistisk regression, er Log Loss.
Hvad er Log Loss?
Log Loss er den vigtigste klassifikationsmetrikken baseret på sandsynligheder. Det er svært at fortolke rå log-loss-værdier, men log-loss er stadig en god måleenhed til sammenligning af modeller. For et givet problem betyder en lavere log loss-værdi bedre forudsigelser.
Matematisk fortolkning:
Log loss er det negative gennemsnit af logaritmen af de korrigerede forudsagte sandsynligheder for hvert tilfælde.
Lad os forstå det med et eksempel:
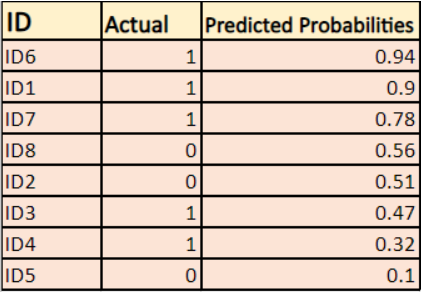
Modellen giver forudsagte sandsynligheder som vist ovenfor.
Hvad er de korrigerede sandsynligheder?
-> Som standard er output af den logistiske regressionsmodel sandsynligheden for, at stikprøven er positiv (angivet med 1), dvs. hvis en logistisk regressionsmodel er trænet til at klassificere på et datasæt for en `virksomhed`, siger den forudsagte sandsynlighedskolonne Hvad er sandsynligheden for, at personen har købt jakke. Her i ovenstående datasæt er sandsynligheden for, at en person med ID6 vil købe en jakke, 0,94.
På samme måde er sandsynligheden for, at en person med ID5 vil købe en jakke (dvs. tilhører klasse 1), 0,1, men den faktiske klasse for ID5 er 0, så sandsynligheden for klassen er (1-0,1)=0,9. 0,9 er den korrekte sandsynlighed for ID5.
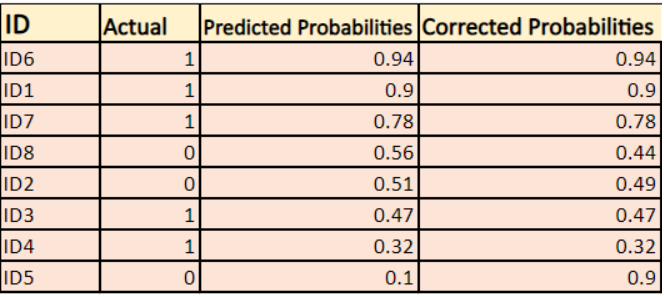
Vi finder en log af de korrigerede sandsynligheder for hvert tilfælde.
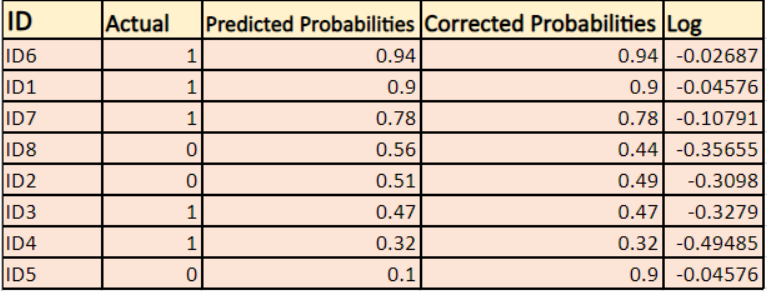
Som du kan se, er disse logværdier negative. For at håndtere det negative fortegn tager vi det negative gennemsnit af disse værdier for at opretholde en almindelig konvention om, at lavere tabsscore er bedre.
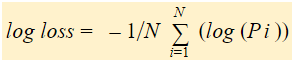
Kort sagt er der tre trin for at finde log tab:
-
For at finde korrigerede sandsynligheder.
-
Tag en log af de korrigerede sandsynligheder.
-
Tag det negative gennemsnit af de værdier, vi får i 2. trin.
Hvis vi opsummerer alle ovenstående trin, kan vi bruge formlen:-
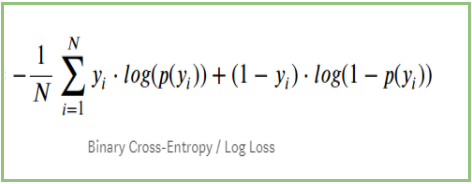
Her repræsenterer Yi den faktiske klasse, og log(p(yi)er sandsynligheden for denne klasse.
-
p(yi) er sandsynligheden for 1.
-
1-p(yi) er sandsynligheden for 0.
Nu skal vi se, hvordan ovenstående formel fungerer i to tilfælde:
-
Når den faktiske klasse er 1: andet udtryk i formlen vil være 0, og vi vil være tilbage med første udtryk, dvs. yi.log(p(yi))) og (1-1).log(1-p(yi)) dette vil være 0.
-
Når den faktiske klasse er 0: Første term vil være 0 og vil være tilbage med anden term dvs. (1-yi).log(1-p(yi)) og 0.log(p(yi)) vil være 0.
wow!!! vi er kommet tilbage til den oprindelige formel for binær krydsentropi/log tab 🙂
Fordelene ved at tage logaritmen afslører sig selv, når man ser på omkostningsfunktionsgraferne for den faktiske klasse 1 og 0 :
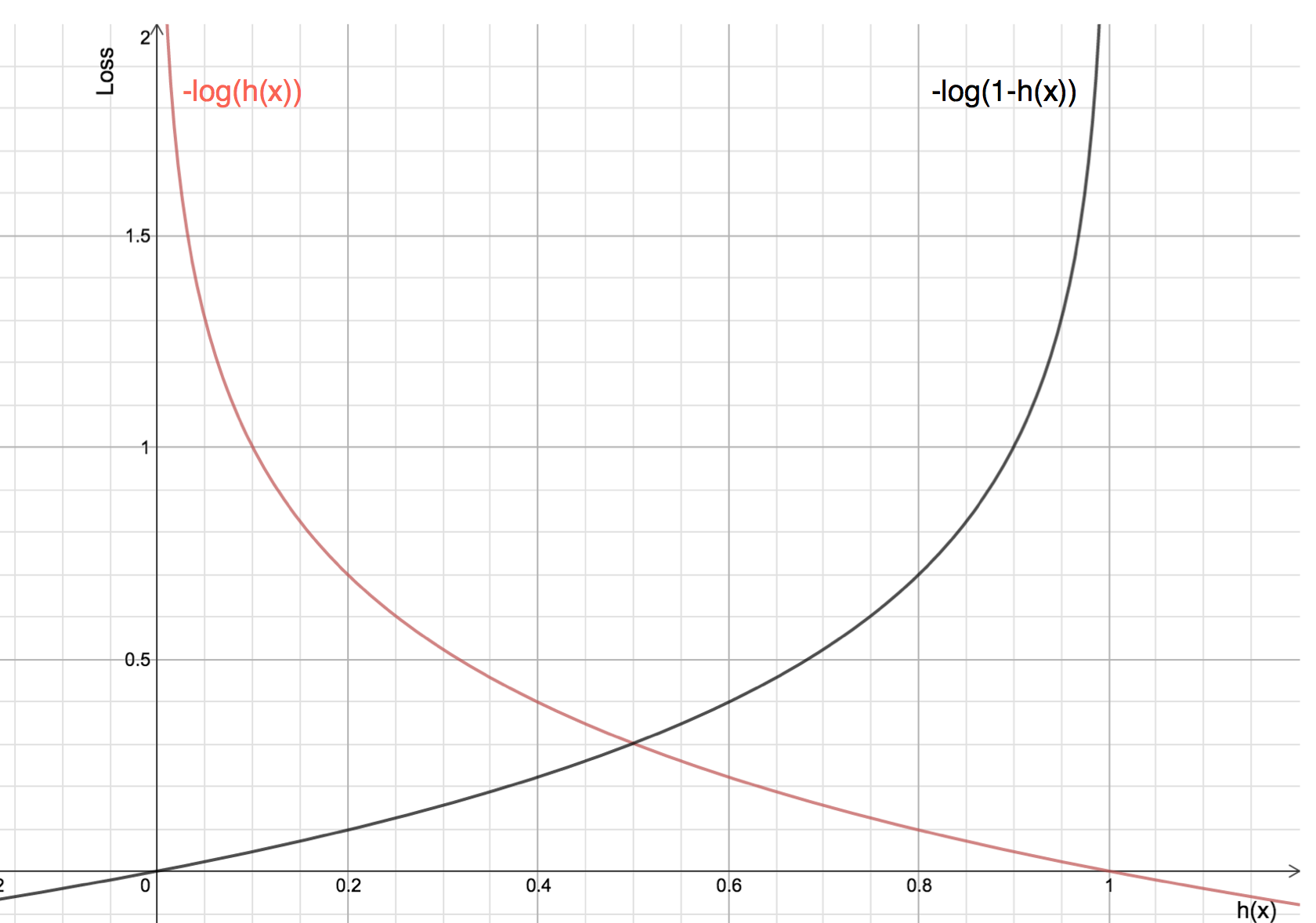
-
Den røde linje repræsenterer 1 klasse. Som vi kan se, er tabet mindre, når den forudsagte sandsynlighed (x-aksen) er tæt på 1, og når den forudsagte sandsynlighed er tæt på 0, nærmer tabet sig uendeligt.
-
Den sorte linje repræsenterer 0 klasse. Som vi kan se, er tabet mindre, når den forudsagte sandsynlighed (x-aksen) er tæt på 0, og når den forudsagte sandsynlighed er tæt på 1, nærmer tabet sig uendeligt.