Tento článek byl publikován v rámci Data Science Blogathon.
- Přehled
- Předpoklady pro tento článek:
- ÚVOD
- Problém s lineární přímkou:
- Proč nepoužíváme `Mean Squared Error jako nákladovou funkci v logistické regresi?
- Co je Log Loss?
- Jaké jsou opravené pravděpodobnosti?
- Výhody použití logaritmu se projeví, když se podíváte na grafy nákladových funkcí pro skutečnou třídu 1 a 0 :
Přehled
-
Problémy, pokud k řešení klasifikačního problému použijeme model lineární regrese
-
Proč se MSE nepoužívá jako nákladová funkce v logistické regresi?
-
Tento článek se bude zabývat matematickým pozadím funkce Log Loss na jednoduchém příkladu.
Předpoklady pro tento článek:
-
Lineární regrese
-
Logistická regrese
-
Gradientní sestup
ÚVOD
`Zima je tady`. Přivítejme zimu hřejivým problémem datové vědy 😉
Podívejme se na případovou studii oděvní společnosti, která vyrábí bundy a svetry. Chtějí mít model, který dokáže na základě historického vzorce chování zákazníka předpovědět, zda si koupí bundu (třída 1) nebo svetr(třída 0), aby mu mohli dávat konkrétní nabídky podle jeho potřeb. Jako datový vědec jim musíte pomoci sestavit prediktivní model.
Když začínáme s algoritmy strojového učení, první algoritmus, o kterém se učíme, je `Lineární regrese`, ve které předpovídáme spojitou cílovou proměnnou.
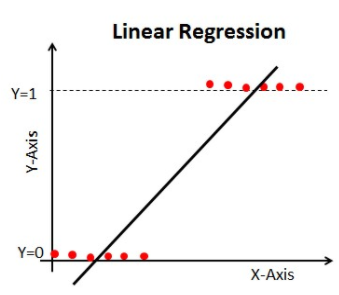
Použijeme-li v našem klasifikačním problému lineární regresi, dostaneme nejlépe vyhovující přímku takto:
Z = ßX + b
Problém s lineární přímkou:
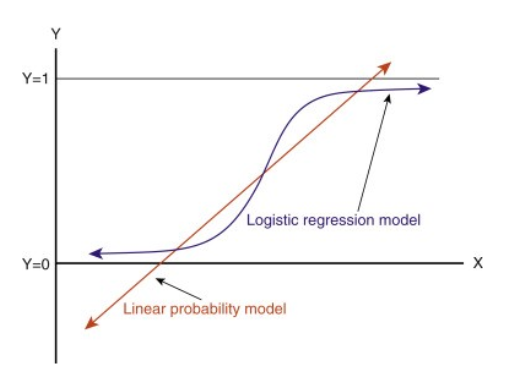
Pokud tuto přímku prodloužíte, budete mít hodnoty větší než 1 a menší než 0, které v našem klasifikačním problému nemají velký smysl. To bude činit problém při interpretaci modelu. Zde přichází na řadu `logistická regrese`. Pokud bychom potřebovali předpovědět tržby pro prodejnu, pak by nám tento model mohl být užitečný. Zde však potřebujeme klasifikovat zákazníky.
-Potřebujeme funkci, která tuto přímku transformuje tak, že hodnoty budou mezi 0 a 1:
Ŷ = Q (Z)
Q (Z) =1/1+ e-z (Sigmoidní funkce)
Ŷ =1/1+ e-z
-Po transformaci získáme přímku, která zůstane mezi 0 a 1.
. Další výhodou této funkce je, že všechny spojité hodnoty, které získáme, budou mezi 0 a 1, což můžeme použít jako pravděpodobnost pro vytváření předpovědí. Například pokud je předpovídaná hodnota na krajní pravé straně, bude pravděpodobnost blízká 1, a pokud je předpovídaná hodnota na krajní levé straně, bude pravděpodobnost blízká 0.
Výběr správného modelu nestačí. Potřebujete funkci, která měří výkonnost modelu strojového učení pro daná data. Nákladová funkce vyčísluje chybu mezi předpovídanými a očekávanými hodnotami.
`Jestliže ji nemůžete změřit, nemůžete ji zlepšit.`
-Další věc, která se touto transformací změní, je nákladová funkce. V lineární regresi používáme `Mean Squared Error` pro nákladovou funkci danou vztahem:-
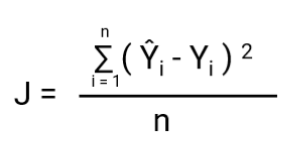
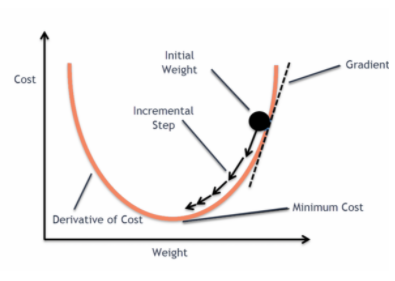
a když tuto chybovou funkci vyneseme do grafu vzhledem k váhovým parametrům lineárního regresního modelu, vytvoří konvexní křivku, která umožňuje použít algoritmus Gradient Descent Optimization k minimalizaci chyby nalezením globálních minim a úpravou vah.
Proč nepoužíváme `Mean Squared Error jako nákladovou funkci v logistické regresi?
V logistické regresi je Ŷi nelineární funkce(Ŷ=1/1+ e-z), pokud ji dosadíme do výše uvedené rovnice MSE, získáme nekonvexní funkci, jak je uvedeno na obrázku:
-
Když se pokusíme optimalizovat hodnoty pomocí gradientního sestupu, způsobí to komplikace při hledání globálních minim.
-
Dalším důvodem je, že v klasifikačních problémech máme cílové hodnoty jako 0/1, Takže (Ŷ-Y)2 bude vždy mezi 0-1, což může velmi ztížit sledování chyb a je obtížné ukládat plovoucí čísla s vysokou přesností.
Nákladovou funkcí používanou v logistické regresi je Log Loss.
Co je Log Loss?
Log Loss je nejdůležitější klasifikační metrika založená na pravděpodobnostech. Je obtížné interpretovat surové hodnoty log-loss, ale přesto je log-loss dobrou metrikou pro porovnávání modelů. Pro daný problém znamená nižší hodnota log loss lepší předpovědi.
Matematická interpretace:
Log loss je záporný průměr logaritmů opravených předpovězených pravděpodobností pro každou instanci.
Pochopíme ji na příkladu:
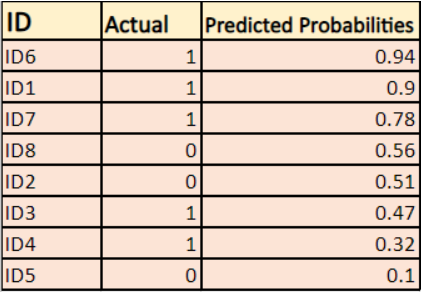
Model dává předpovězené pravděpodobnosti, jak je uvedeno výše.
Jaké jsou opravené pravděpodobnosti?
-> Ve výchozím nastavení je výstupem logistického regresního modelu pravděpodobnost, že vzorek je pozitivní(označená 1), tj. pokud je logistický regresní model natrénován pro klasifikaci na souboru dat `firmy`, pak sloupec predikované pravděpodobnosti říká Jaká je pravděpodobnost, že si osoba koupila bundu. Zde ve výše uvedeném souboru dat je pravděpodobnost, že osoba s ID6 si koupí bundu, 0,94.
Stejně tak pravděpodobnost, že si osoba s ID5 koupí bundu (tj. patří do třídy 1), je 0,1, ale skutečná třída pro ID5 je 0, takže pravděpodobnost pro třídu je (1-0,1)=0,9. 0,9 je správná pravděpodobnost pro ID5.
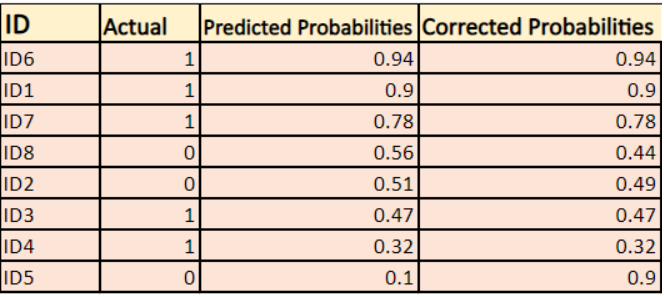
Zjistíme logaritmus opravených pravděpodobností pro každý případ.
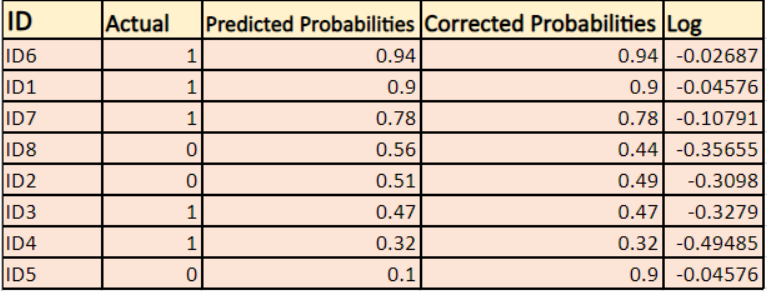
Jak vidíte, tyto logaritmy jsou záporné. Abychom se vypořádali se záporným znaménkem, vezmeme záporný průměr těchto hodnot, abychom zachovali běžnou konvenci, že nižší skóre ztrát je lepší.
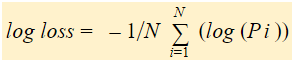
Stručně řečeno, k nalezení logaritmu ztrát jsou tři kroky:
-
Zjistíme opravené pravděpodobnosti.
-
Vzít logaritmus korigovaných pravděpodobností.
-
Vzít záporný průměr hodnot, které jsme získali ve 2. kroku.
Pokud shrneme všechny výše uvedené kroky, můžeme použít vzorec:-
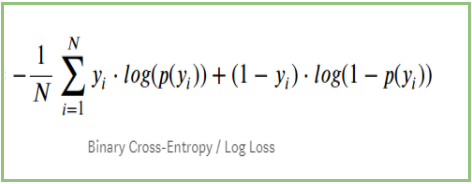
Tady Yi představuje skutečnou třídu a log(p(yi)je pravděpodobnost této třídy.
-
p(yi) je pravděpodobnost 1.
-
1-p(yi) je pravděpodobnost 0.
Nyní se podívejme, jak výše uvedený vzorec funguje ve dvou případech:
-
Když je skutečná třída 1: druhý člen ve vzorci by byl 0 a zůstal by nám první člen, tj. yi.log(p(yi)) a (1-1).log(1-p(yi) to bude 0.
-
Když je skutečná třída 0.
-
Když je skutečná třída 0: První člen by byl 0 a zůstane druhý člen, tj. (1-yi).log(1-p(yi)) a 0.log(p(yi)) bude 0.
wow!!!! dostali jsme se zpět k původnímu vzorci pro binární křížovou entropii/logaritmickou ztrátu 🙂
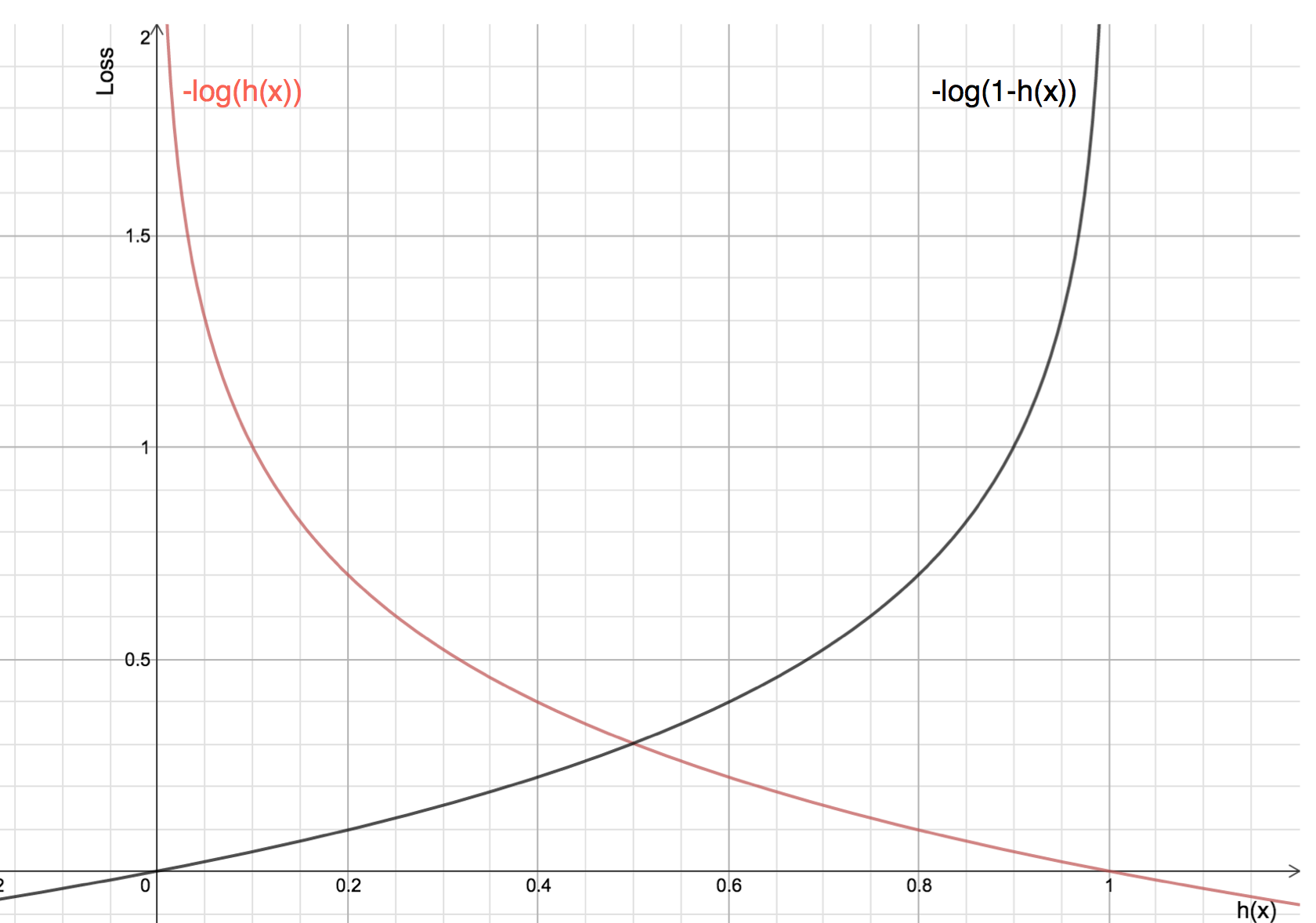
Výhody použití logaritmu se projeví, když se podíváte na grafy nákladových funkcí pro skutečnou třídu 1 a 0 :
-
Červená čára představuje 1 třídu. Jak vidíme, když se předpovídaná pravděpodobnost (osa x) blíží 1, ztráta je menší, a když se předpovídaná pravděpodobnost blíží 0, ztráta se blíží nekonečnu.
-
Černá čára představuje 0 třídu. Jak vidíme, když se předpovídaná pravděpodobnost (osa x) blíží 0, ztráta je menší, a když se předpovídaná pravděpodobnost blíží 1, ztráta se blíží nekonečnu.
.