Tämän opetusohjelman tarkoituksena ei ole tehdä sinusta asiantuntijaa suosittelujärjestelmämallien rakentamisessa. Sen sijaan motiivina on saada sinut alkuun antamalla sinulle yleiskatsaus siitä, millaisia suosittelujärjestelmiä on olemassa ja miten voit rakentaa sellaisen itse
Tässä opetusohjelmassa opit rakentamaan yksinkertaisten ja sisältöpohjaisten suosittelujärjestelmien perusmallin. Vaikka nämä mallit eivät tule olemaan lähelläkään alan standardia monimutkaisuuden, laadun tai tarkkuuden suhteen, se auttaa sinua pääsemään alkuun rakentaessasi monimutkaisempia malleja, jotka tuottavat vieläkin parempia tuloksia.
Suosittelujärjestelmät ovat nykyään yksi suosituimmista datatieteen sovelluksista. Niitä käytetään ennustamaan ”arvosanaa” tai ”mieltymystä”, jonka käyttäjä antaisi tuotteelle. Lähes kaikki suuret teknologiayritykset ovat soveltaneet niitä jossakin muodossa. Amazon käyttää sitä ehdottaakseen tuotteita asiakkaille, YouTube käyttää sitä päättääkseen, mikä video toistetaan seuraavaksi automaattisella toistolla, ja Facebook käyttää sitä suositellakseen sivuja, joista kannattaa tykätä, ja henkilöitä, joita kannattaa seurata.
Joidenkin yritysten, kuten Netflixin, Amazon Primen, Hulun ja Hotstarin, liiketoimintamalli ja menestys pyörii suositusten tehon ympärillä. Netflix tarjosi vuonna 2009 jopa miljoona dollaria sille, joka pystyisi parantamaan sen järjestelmää 10 prosenttia.
Suositusjärjestelmiä on suosittu myös sellaisilla aloilla kuin ravintolat, elokuvat ja nettideittailu. Suosittelujärjestelmiä on kehitetty myös tutkimusartikkelien ja asiantuntijoiden, yhteistyökumppaneiden ja rahoituspalvelujen tutkimiseen. YouTube käyttää suosittelujärjestelmää laajamittaisesti ehdottaakseen sinulle videoita historiasi perusteella. Jos esimerkiksi katsot paljon opetusvideoita, se ehdottaa tällaisia videoita.
Mutta mitä nämä suosittelujärjestelmät ovat?
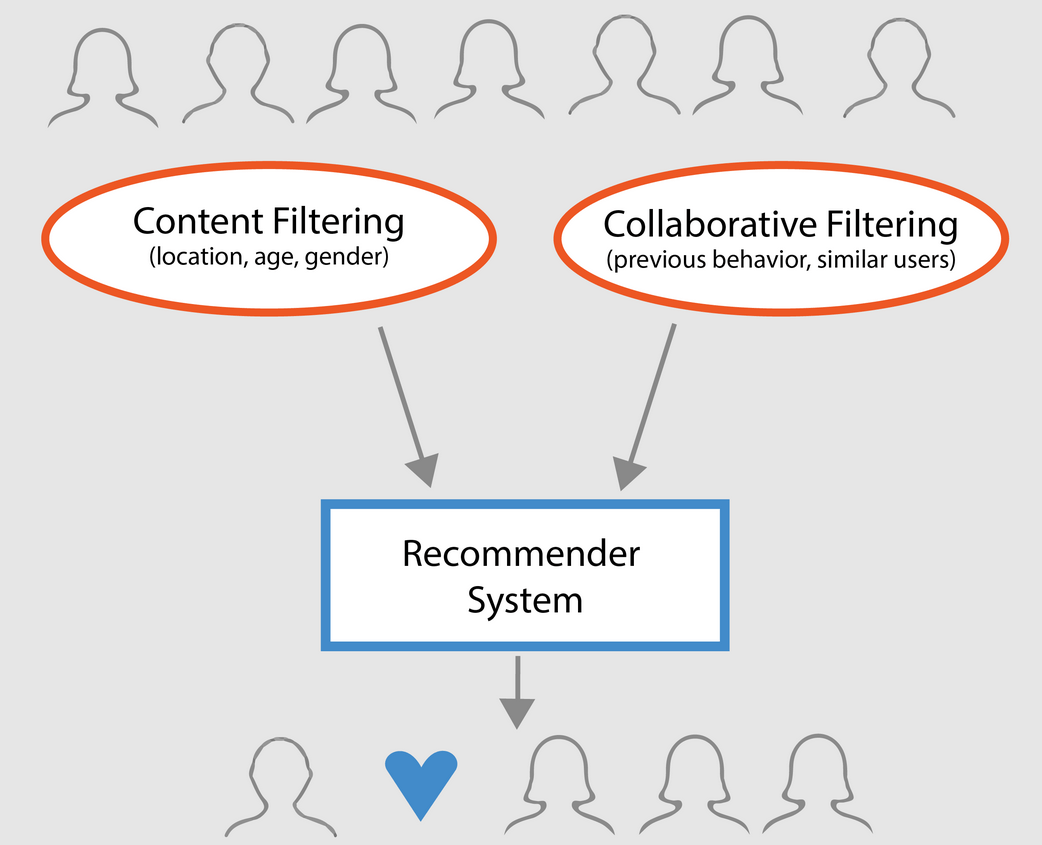
Laaja-alaisesti suosittelujärjestelmät voidaan luokitella kolmeen tyyppiin:
- Yksinkertaiset suosittelijat: Tarjoavat jokaiselle käyttäjälle yleistettyjä suosituksia elokuvan suosion ja/tai genren perusteella. Tämän järjestelmän perusajatuksena on, että elokuvat, jotka ovat suositumpia ja kriitikoiden arvostamia, ovat suuremmalla todennäköisyydellä keskivertoyleisön mieleen. Esimerkkinä voisi olla IMDB Top 250.
- Sisältöön perustuvat suosittelijat: ehdottavat samankaltaisia kohteita tietyn kohteen perusteella. Tämä järjestelmä käyttää suositusten tekemiseen kohteen metatietoja, kuten elokuvien genreä, ohjaajaa, kuvausta, näyttelijöitä jne. Näiden suosittelujärjestelmien yleisenä ajatuksena on, että jos henkilö pitää tietystä kohteesta, hän pitää myös sen kaltaisesta kohteesta. Suosittelussa hyödynnetään käyttäjän aiempien kohteiden metatietoja. Hyvä esimerkki voisi olla YouTube, jossa se ehdottaa sinulle historian perusteella uusia videoita, joita voisit mahdollisesti katsoa.
- Yhteistyösuodatusmoottorit: Nämä järjestelmät ovat laajalti käytettyjä, ja ne pyrkivät ennustamaan arvosanan tai mieltymyksen, jonka käyttäjä antaisi kohteelle, muiden käyttäjien aiempien arvosanojen ja mieltymysten perusteella. Yhteistyösuodattimet eivät vaadi kohteen metatietoja kuten sisältöpohjaiset vastineensa.
Yksinkertaiset suosittelijat
Kuten edellisessä kappaleessa kuvattiin, yksinkertaiset suosittelijat ovat perusjärjestelmiä, jotka suosittelevat parhaita kohteita tietyn mittarin tai pistemäärän perusteella. Tässä osiossa rakennat yksinkertaisen kloonin IMDB:n Top 250 -elokuvista käyttäen IMDB:stä kerättyjä metatietoja.
Vaiheet ovat seuraavat:
-
Päättää metriikka tai pistemäärä, jonka perusteella elokuvia arvioidaan.
-
Lasketaan pistemäärä jokaiselle elokuvalle.
-
Lajitellaan elokuvat pistemäärän perusteella ja tulostetaan parhaat tulokset.
Tietokannasta
Tietokantatiedostot sisältävät metatietoja kaikille 45 000 elokuvalle, jotka on listattu Full MovieLens Dataset. Tietoaineisto koostuu elokuvista, jotka on julkaistu heinäkuussa 2017 tai sitä ennen. Tämä tietokokonaisuus kaappaa ominaisuuspisteitä, kuten näyttelijät, kuvausryhmä, juonen avainsanat, budjetti, tulot, julisteet, julkaisupäivät, kielet, tuotantoyhtiöt, maat, TMDB-äänimäärät ja äänten keskiarvot.
Näitä ominaisuuspisteitä voidaan mahdollisesti käyttää kouluttamaan koneoppimismalleja sisällön ja yhteistoiminnallisen suodatuksen osalta.
Tämä tietokokonaisuus koostuu seuraavista tiedostoista:
- movies_metadata.csv: Tämä tiedosto sisältää tietoja ~45 000 elokuvasta, jotka esiintyvät Full MovieLens -tietokokonaisuudessa. Ominaisuuksiin kuuluvat julisteet, taustakuvat, budjetti, genre, tuotot, julkaisupäivät, kielet, tuotantomaat ja yhtiöt.
- keywords.csv: Sisältää MovieLens-elokuvien elokuvan juonen avainsanat. Saatavilla merkkijonomuotoisena JSON-oliona.
- credits.csv: Koostuu kaikkien elokuvien näyttelijä- ja miehistötiedoista. Saatavana merkkijonomuotoisena JSON-objektina.
- links.csv: Tämä tiedosto sisältää kaikkien Full MovieLens -tietokannassa esiintyvien elokuvien TMDB- ja IMDB-tunnukset.
- links_small.csv: Sisältää TMDB- ja IMDB-tunnukset pienestä 9000 elokuvan osajoukosta Full Datasetista.
- ratings_small.csv: Osajoukko 100 000 arviota 700 käyttäjältä 9000 elokuvasta.
Full MovieLens Dataset sisältää 26 miljoonaa arviota ja 750 000 tag-sovellusta, jotka ovat peräisin 270 000 käyttäjältä ja jotka koskevat kaikkia tämän tietokokonaisuuteen sisältyviä 45 000 elokuvaa. Siihen pääsee käsiksi GroupLensin viralliselta verkkosivulta.
Huomautus: Tämänpäiväisessä opetusohjelmassa käytetyn osajoukon datasetin voi ladata täältä.
Tietokannan lataamiseen käytettäisiin pandas DataFrame-kirjastoa. pandas-kirjastoa käytetään pääasiassa datan käsittelyyn ja analysointiin. Se esittää tietosi rivi-sarakemuodossa. Pandas-kirjaston tukena on NumPy-joukko pandas-dataobjektien toteuttamista varten. pandas tarjoaa valmiita tietorakenteita ja operaatioita numeeristen taulukoiden, aikasarjojen, kuvien ja luonnollisen kielen prosessoinnin tietokokonaisuuksien käsittelyyn. Periaatteessa pandas on hyödyllinen niille tietokokonaisuuksille, jotka voidaan helposti esittää taulukkomuodossa.
Ennen kuin suoritat mitään edellä mainituista vaiheista, ladataan elokuvien metatietoaineisto pandas DataFrameen:
# Import Pandasimport pandas as pd# Load Movies Metadatametadata = pd.read_csv('movies_metadata.csv', low_memory=False)# Print the first three rowsmetadata.head(3)| aikuinen | kuuluu_kokoelmaan | budjetti | genres | kotisivu | id | imdb_id | original_language | original_title | overview | … | release_date | revenue | runtime | spoken_languages | status | tagline | title | video | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {’id’: … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | ||||||||||||
| 1 | False | NaN | 65000000 | Vapautettu | Still Yelling. Still Fighting. Still Ready for… | Grumpier Old Men | False | 6.5 | 92.0 |
3 riviä × 24 saraketta
Yksi perustavanlaatuisimmaksi ajateltavaksi mittaristoksi on muodostunut ranking, jonka avulla voidaan päätellä, mitkä elokuvat ovat 250 parhaan elokuvan listalla arvosanojensa perusteella.
Luokituksen käyttämiseen mittarina liittyy kuitenkin muutamia varoituksia:
-
Yksi se ei ota huomioon elokuvan suosiota. Näin ollen elokuvaa, jonka arvosana on 9 kymmeneltä äänestäjältä, pidetään ”parempana” kuin elokuvaa, jonka arvosana on 8,9 kymmeneltätuhannelta äänestäjältä.
Kuvitellaan esimerkiksi, että haluat tilata kiinalaista ruokaa, sinulla on pari vaihtoehtoa, joista yhdellä ravintolalla on viiden tähden arvosana vain viideltä ihmiseltä, kun taas toisella ravintolalla on 4,5 arvosana tuhannelta ihmiseltä. Kumman ravintolan valitsisit mieluummin? Toista, eikö?
Voi tietysti olla poikkeus, että ensimmäinen ravintola avattiin vasta muutama päivä sitten; siksi sitä on äänestänyt vähemmän ihmisiä, kun taas toinen ravintola on päinvastoin ollut toiminnassa jo vuoden.
- Seuraavana huomiona tämä mittari suosii myös elokuvia, joissa on pienempi määrä äänestäjiä, joilla on vinoutuneet ja/tai erittäin korkeat arvosanat. Äänestäjien määrän kasvaessa elokuvan luokitus tasaantuu ja lähestyy arvoa, joka kuvastaa elokuvan laatua ja antaa käyttäjälle paljon paremman käsityksen siitä, mikä elokuva hänen tulisi valita. Vaikka elokuvan, jolla on äärimmäisen vähän äänestäjiä, laatua on vaikea hahmottaa, saatat joutua harkitsemaan ulkopuolisia lähteitä päätelmiä tehdessäsi.
Tämä puutteet huomioon ottaen sinun on keksittävä painotettu luokitus, joka ottaa huomioon keskimääräisen arvosanan ja sille kertyneiden äänien määrän. Tällainen järjestelmä varmistaa, että elokuva, jolla on 9-arvosana 100 000 äänestäjältä, saa (paljon) korkeamman pistemäärän kuin elokuva, jolla on sama arvosana, mutta vain muutama sata äänestäjää.
Koska yrität rakentaa kloonin IMDB:n Top 250:stä, käyttäkäämme metriikkana/pistemääränä sen painotetun arvosanan kaavaa. Matemaattisesti se esitetään seuraavasti:
\begin{equation}\text Weighted Rating (\bf WR) = \left({{\bf v} \over {\bf v} + {\bf m}} \cdot R\right) + \left({{\bf m} \over {\bf v} + {\bf m}} \cdot C\right)\end{equation}
Ylläolevassa yhtälössä,
-
v on elokuvan saama äänimäärä;
-
m on minimiäänimäärä, joka vaaditaan, jotta elokuva voidaan listata taulukkoon;
-
R on elokuvan keskiarvo;
-
C on koko raportin keskiarvo.
Sinulla on jo arvot v (vote_count) ja R (vote_average) jokaiselle elokuvalle aineistossa. Voit myös laskea C:n suoraan näistä tiedoista.
Sopivan arvon määrittäminen arvolle m on hyperparametri, jonka voit valita sen mukaan, koska oikeaa arvoa arvolle m ei ole olemassa. Voit pitää sitä alustavana negatiivisena suodattimena, joka yksinkertaisesti poistaa elokuvat, joiden äänimäärä on pienempi kuin tietty kynnysarvo m. Suodattimesi valikoivuus on harkintasi mukaan.
Tässä opetusohjelmassa käytät rajaarvoa m 90. prosenttipisteenä. Toisin sanoen, jotta elokuva pääsee listalle, sillä on oltava enemmän ääniä kuin vähintään 90 % listalla olevista elokuvista. (Toisaalta, jos olisit valinnut 75. prosenttipisteen, olisit ottanut huomioon 25 prosenttia elokuvista eniten ääniä keränneiden äänien määrän perusteella. Prosenttiilin pienentyessä huomioon otettujen elokuvien määrä kasvaa).
Lasketaan ensin pandas .mean() -funktiolla C:n arvo, eli kaikkien elokuvien keskimääräinen luokitus:
# Calculate mean of vote average columnC = metadata.mean()print(C)5.618207215133889Yllä olevasta tulosteesta voidaan havaita, että elokuvan keskimääräinen luokitus IMDB:ssä on noin 5. Tämän perusteella voidaan todeta, että elokuvan keskimääräinen luokitus IMDB:ssä on noin 5.6 asteikolla 10.
Lasketaan seuraavaksi elokuvan saama äänimäärä, m, 90. persentiilissä. pandas-kirjasto tekee tästä tehtävästä erittäin triviaalin käyttämällä pandasin .quantile()-metodia:
# Calculate the minimum number of votes required to be in the chart, mm = metadata.quantile(0.90)print(m)160.0Sen jälkeen, kun sinulla on nyt m, voit yksinkertaisesti käyttää greater than equal to -ehtoa suodattaaksesi pois elokuvat, joiden äänimäärä on suurempi kuin 160:n äänimäärät:
Voit käyttää .copy()-metodia varmistaaksesi, että luodut uudet q_movies DataFrame-tietokannat (dataFrame) ovat riippumattomissa alkuperäisistä metatietoistasi. Toisin sanoen q_movies DataFrame -tietokehykseen tehdyt muutokset eivät vaikuta alkuperäiseen metadata-tietokehykseen.
# Filter out all qualified movies into a new DataFrameq_movies = metadata.copy().loc >= m]q_movies.shape(4555, 24)metadata.shape(45466, 24)Yllä olevasta tulosteesta käy selväksi, että noin 10 %:lla elokuvista on yli 160 äänimäärää, ja ne kelpuutetaan tälle listalle.
Seuraavana ja tärkeimpänä askeleena on laskea kullekin kelpuutetulle elokuvalle painotettu luokitus. Voit tehdä tämän seuraavasti:
- Määritä funktio
weighted_rating(); - Koska olet jo laskenut
mjaC, annat ne yksinkertaisesti argumenttina funktiolle; - Sitten valitset
vote_count(v) javote_average(R) sarakkeenq_moviestietoruudusta; - Viimeiseksi lasket painotetun keskiarvon ja palautat tuloksen.
Määrittelet uuden ominaisuuden score, jonka arvon lasket soveltamalla tätä funktiota kelpuutettujen elokuvien DataFrame:
# Function that computes the weighted rating of each moviedef weighted_rating(x, m=m, C=C): v = x R = x # Calculation based on the IMDB formula return (v/(v+m) * R) + (m/(m+v) * C)# Define a new feature 'score' and calculate its value with `weighted_rating()`q_movies = q_movies.apply(weighted_rating, axis=1)Lajitellaan lopuksi DataFrame alenevaan järjestykseen score ominaisuussarakkeen perusteella ja tulostetaan kahdenkymmenen parhaan elokuvan otsikko, äänimäärät, äänestyskeskiarvo ja painotettu arvosana (score).
#Sort movies based on score calculated aboveq_movies = q_movies.sort_values('score', ascending=False)#Print the top 15 moviesq_movies].head(20)| title | vote_count | vote_average | pisteet | |
|---|---|---|---|---|
| 314 | The Shawshank Redemption | 8358.0 | 8.5 | 8.445869 |
| 834 | Kummisetä | 6024.0 | 8.5 | 8.425439 |
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.421453 |
| 12481 | The Dark Knight | 12269.0 | 8.3 | 8.265477 |
| 2843 | Fight Club | 9678.0 | 8.3 | 8.256385 |
| 292 | Pulp Fiction | 8670.0 | 8.3 | 8.251406 |
| 522 | Schindlerin lista | 4436.0 | 8.3 | 8.206639 |
| 23673 | Whiplash | 4376.0 | 8.3 | 8.205404 |
| 5481 | Spirited Away | 3968.0 | 8.3 | 8.196055 |
| 2211 | Life Is Beautiful | 3643.0 | 8.3 | 8.187171 |
| 1178 | The Godfather: Osa II | 3418.0 | 8.3 | 8.180076 |
| 1152 | Yksi lensi yli käenpesän | 3001.0 | 8.3 | 8.164256 |
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.150272 |
| 1154 | The Empire Strikes Back | 5998.0 | 8.2 | 8.132919 |
| 1176 | Psycho | 2405.0 | 8.3 | 8.132715 |
| 18465 | The Intouchables | 5410.0 | 8.2 | 8.125837 |
| 40251 | Nimesi. | 1030.0 | 8.5 | 8.112532 |
| 289 | Leon: The Professional | 4293.0 | 8.2 | 8.107234 |
| 303030 | The Green Mile | 4166.0 | 8.2 | 8.104511 |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
Ylläolevasta tulosteesta näkee, että simple recommender teki hienoa työtä!
Koska taulukossa on paljon yhteisiä elokuvia IMDB:n Top 250 -taulukon kanssa: esimerkiksi kaksi parasta elokuvaanne, ”Shawshank Redemption” ja ”Kummisetä”, ovat samoja kuin IMDB:ssä, ja me kaikki tiedämme, että ne ovat tosiaankin uskomattomia elokuvia, itse asiassa kaikki top 20 -elokuvat ansaitsevat olla tuolla listalla, eikö totta?
Sisältöön perustuva suosittelija
Kuvakuvaukseen perustuva suosittelija
Tässä opetusohjelman osassa opit rakentamaan järjestelmän, joka suosittelee elokuvia, jotka muistuttavat tiettyä elokuvaa. Tätä varten lasket kaikille elokuville pareittaiset cosine samankaltaisuuspisteet niiden juonikuvausten perusteella ja suosittelet elokuvia tämän samankaltaisuuspistekynnyksen perusteella.
Juonikuvaus on käytettävissäsi overview-ominaisuutena metadata-tietokannassasi. Tarkastellaan muutamien elokuvien juonikuvauksia:
#Print plot overviews of the first 5 movies.metadata.head()0 Led by Woody, Andy's toys live happily in his ...1 When siblings Judy and Peter discover an encha...2 A family wedding reignites the ancient feud be...3 Cheated on, mistreated and stepped on, the wom...4 Just when George Banks has recovered from his ...Name: overview, dtype: objectKäsillä oleva ongelma on luonnollisen kielen käsittelyn ongelma. Näin ollen sinun täytyy poimia jonkinlaisia piirteitä yllä olevasta tekstidatasta, ennen kuin voit laskea niiden välisen samankaltaisuuden ja/tai erilaisuuden. Yksinkertaisesti sanottuna ei ole mahdollista laskea minkään kahden yleiskatsauksen samankaltaisuutta niiden raakamuodossa. Tätä varten on laskettava kunkin yleiskatsauksen tai asiakirjan sanavektorit, kuten sitä jatkossa kutsutaan.
Kuten nimestä voi päätellä, sanavektorit ovat vektorimuotoisia esityksiä asiakirjan sanoista. Vektorit kantavat mukanaan semanttisen merkityksen. Esimerkiksi mies & kuningas on vektoriedustukset lähellä toisiaan, kun taas mies & nainen olisi edustus kaukana toisistaan.
Lasket Term Frequency-Inverse Document Frequency (TF-IDF) vektorit jokaiselle dokumentille. Näin saat matriisin, jossa jokainen sarake edustaa sanaa yleiskatsauksen sanastossa (kaikki sanat, jotka esiintyvät vähintään yhdessä asiakirjassa), ja jokainen sarake edustaa elokuvaa, kuten aiemmin.
TF-IDF-pistemäärä on pohjimmiltaan sanan esiintymisfrekvenssi asiakirjassa vähennettynä niiden asiakirjojen määrällä, joissa se esiintyy. Näin vähennetään juonikatsauksissa usein esiintyvien sanojen merkitystä ja siten niiden merkitystä lopullista samankaltaisuuspistemäärää laskettaessa.
Scikit-learn tarjoaa onneksi sisäänrakennetun TfIdfVectorizer luokan, joka tuottaa TF-IDF-matriisin parilla rivillä.
- Importoi Tfidf-moduuli scikit-learnin avulla;
- Poista stop-sanat, kuten ’the’, ’an’ jne. koska ne eivät anna mitään hyödyllistä tietoa aiheesta;
- Korvaa ei-numeroarvot tyhjällä merkkijonolla;
- Konstruoi lopuksi TF-IDF-matriisi aineistosta.
#Import TfIdfVectorizer from scikit-learnfrom sklearn.feature_extraction.text import TfidfVectorizer#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'tfidf = TfidfVectorizer(stop_words='english')#Replace NaN with an empty stringmetadata = metadata.fillna('')#Construct the required TF-IDF matrix by fitting and transforming the datatfidf_matrix = tfidf.fit_transform(metadata)#Output the shape of tfidf_matrixtfidf_matrix.shape(45466, 75827)#Array mapping from feature integer indices to feature name.tfidf.get_feature_names()Yllä olevasta tulosteesta havaitset, että aineistossasi on 75 827 erilaista sanastoa tai sanaa, joilla on 45 000 elokuvaa.
Tämän matriisin avulla voit nyt laskea samankaltaisuuspisteet. Tähän voit käyttää useita samankaltaisuusmittareita, kuten Manhattanin, euklidisen, Pearsonin ja kosinin samankaltaisuuspisteitä. Jälleen kerran ei ole olemassa oikeaa vastausta siihen, mikä pistemäärä on paras. Eri pisteet toimivat hyvin eri skenaarioissa, ja usein on hyvä idea kokeilla eri mittareita ja tarkkailla tuloksia.
Käytät cosine similarity:aa laskeaksesi numeerisen suureen, joka ilmaisee kahden elokuvan välistä samankaltaisuutta. Käytät kosinin samankaltaisuuspistemäärää, koska se on suuruudesta riippumaton ja suhteellisen helppo ja nopea laskea (varsinkin kun sitä käytetään yhdessä TF-IDF-pisteiden kanssa, jotka selitetään myöhemmin). Matemaattisesti se määritellään seuraavasti:
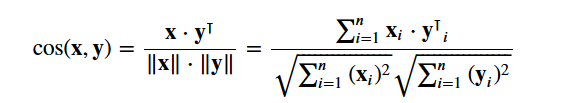
Koska olet käyttänyt TF-IDF-vektorointiainetta, kunkin vektorin välisen pistetuoton laskeminen antaa suoraan kosinin samankaltaisuuspistemäärän. Siksi käytät sklearn's linear_kernel() eikä cosine_similarities(), koska se on nopeampi.
Tämä palauttaisi matriisin, jonka muoto on 45466×45466, mikä tarkoittaa, että jokaisen elokuvan overview kosinin samankaltaisuuspistemäärä jokaisen toisen elokuvan overview kanssa. Näin ollen jokaisesta elokuvasta tulee 1×45466 sarakevektori, jossa jokainen sarake on samankaltaisuuspistemäärä jokaisen elokuvan kanssa.
# Import linear_kernelfrom sklearn.metrics.pairwise import linear_kernel# Compute the cosine similarity matrixcosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)cosine_sim.shape(45466, 45466)cosine_simarray()Määrittelet funktion, joka ottaa syötteenä elokuvan nimen ja antaa tulokseksi luettelon 10 samankaltaisimmasta elokuvasta. Tätä varten tarvitset ensinnäkin elokuvan otsikoiden ja DataFrame-indeksien käänteisen kartoituksen. Toisin sanoen tarvitset mekanismin, jolla voit tunnistaa elokuvan indeksin metadata DataFrame-tietokannassasi sen otsikon perusteella.
#Construct a reverse map of indices and movie titlesindices = pd.Series(metadata.index, index=metadata).drop_duplicates()indicestitleToy Story 0Jumanji 1Grumpier Old Men 2Waiting to Exhale 3Father of the Bride Part II 4Heat 5Sabrina 6Tom and Huck 7Sudden Death 8GoldenEye 9dtype: int64Olet nyt hyvässä kunnossa määrittelemään suosittelufunktion. Seuraavia vaiheita noudatat:
-
Hae elokuvan indeksi sen otsikon perusteella.
-
Hae luettelo kyseisen elokuvan kosinisen samankaltaisuuden pistemääristä kaikkien elokuvien kanssa. Muunna se tupleluetteloksi, jossa ensimmäinen elementti on sen sijainti ja toinen elementti on samankaltaisuuspistemäärä.
-
Lajittele edellä mainittu tupleluettelo samankaltaisuuspistemäärien perusteella; eli toinen elementti.
-
Noutaa tämän luettelon 10 parasta elementtiä. Jätä ensimmäinen elementti huomiotta, koska se viittaa itseensä (elokuva, joka muistuttaa eniten tiettyä elokuvaa, on elokuva itse).
-
Palauta ylimpien elementtien indeksejä vastaavat otsikot.
# Function that takes in movie title as input and outputs most similar moviesdef get_recommendations(title, cosine_sim=cosine_sim): # Get the index of the movie that matches the title idx = indices # Get the pairwsie similarity scores of all movies with that movie sim_scores = list(enumerate(cosine_sim)) # Sort the movies based on the similarity scores sim_scores = sorted(sim_scores, key=lambda x: x, reverse=True) # Get the scores of the 10 most similar movies sim_scores = sim_scores # Get the movie indices movie_indices = for i in sim_scores] # Return the top 10 most similar movies return metadata.ilocget_recommendations('The Dark Knight Rises')12481 The Dark Knight150 Batman Forever1328 Batman Returns15511 Batman: Under the Red Hood585 Batman21194 Batman Unmasked: The Psychology of the Dark Kn...9230 Batman Beyond: Return of the Joker18035 Batman: Year One19792 Batman: The Dark Knight Returns, Part 13095 Batman: Mask of the PhantasmName: title, dtype: objectget_recommendations('The Godfather')1178 The Godfather: Part II44030 The Godfather Trilogy: 1972-19901914 The Godfather: Part III23126 Blood Ties11297 Household Saints34717 Start Liquidation10821 Election38030 A Mother Should Be Loved17729 Short Sharp Shock26293 Beck 28 - FamiljenName: title, dtype: objectNäthän, että vaikka järjestelmäsi on tehnyt kohtuullista työtä löytääkseen elokuvia, joilla on samankaltaiset juonikuvaukset, suositusten laatu ei kuitenkaan ole kovin hyvä. ”The Dark Knight Rises” palauttaa kaikki Batman-elokuvat, kun taas on todennäköisempää, että ihmiset, jotka pitivät kyseisestä elokuvasta, ovat taipuvaisempia pitämään muista Christopher Nolanin elokuvista. Tämä on jotain sellaista, mitä nykyinen järjestelmäsi ei pysty vangitsemaan.
Credits, Genres, and Keywords Based Recommender
Suosituksesi laatua voitaisiin parantaa käyttämällä parempia metatietoja ja vangitsemalla enemmän hienompia yksityiskohtia. Juuri tämän aiot tehdä tässä osiossa. Rakennat suositusjärjestelmän, joka perustuu seuraaviin metatietoihin: kolme parasta näyttelijää, ohjaaja, aiheeseen liittyvät genret ja elokuvan juonen avainsanat.
Avainsanat, näyttelijät ja kuvausryhmätiedot eivät ole saatavilla nykyisessä tietokokonaisuudessasi, joten ensimmäinen askel olisi ladata ja yhdistää ne päätietokantaasi metadata.
# Load keywords and creditscredits = pd.read_csv('credits.csv')keywords = pd.read_csv('keywords.csv')# Remove rows with bad IDs.metadata = metadata.drop()# Convert IDs to int. Required for mergingkeywords = keywords.astype('int')credits = credits.astype('int')metadata = metadata.astype('int')# Merge keywords and credits into your main metadata dataframemetadata = metadata.merge(credits, on='id')metadata = metadata.merge(keywords, on='id')# Print the first two movies of your newly merged metadatametadata.head(2)| aikuinen | kuuluu_kokoelmaan | budjetti | genres | kotisivu | id | imdb_id | original_language | original_title | overview | … | spoken_languages | status | tagline | title | video | vote_average | vote_count | cast | crew | keywords | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {’id’: … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | for feature in features: metadata = metadata.apply(literal_eval)
Seuraavaksi kirjoitat funktioita, joiden avulla saat poimittua tarvittavat tiedot kustakin piirteestä. Aluksi tuodaan NumPy-paketti, jotta saat käyttöösi sen Hae ohjaajan nimi crew-ominaisuudesta. Jos ohjaajaa ei ole luettelossa, palauta Seuraavaksi kirjoitat funktion, joka palauttaa 3 ensimmäistä elementtiä tai koko luettelon, sen mukaan, kumpi on enemmän. Tässä luettelolla tarkoitetaan
Seuraavaksi nimet ja avainsanainstanssit muutettaisiin pieniksi ja niiden väliltä poistettaisiin kaikki välilyönnit. Sanojen välejen poistaminen on tärkeä esikäsittelyvaihe. Se tehdään, jotta vektorisaattorisi ei laske ”Johnny Deppin” ja ”Johnny Galeckin” Johnnya samaksi. Tämän käsittelyvaiheen jälkeen edellä mainitut näyttelijät esitetään nimillä ”johnnydepp” ja ”johnnygalecki”, ja ne ovat vektorisaattorillesi erillisiä. Toinen hyvä esimerkki, jossa malli saattaa tuottaa saman vektoriesityksen, on ”leipäruuhka” ja ”liikenneruuhka”. Näin ollen on parempi poistaa kaikki välilyönnit. Alhaalla oleva funktio tekee juuri tämän puolestasi: Voit nyt luoda ”metadatakeittosi”, joka on merkkijono, joka sisältää kaikki metatiedot, jotka haluat syöttää vektorisaattorillesi (nimittäin näyttelijät, ohjaaja ja avainsanat). Funktio
| soppaa |
0 |
kateellinen lelupoika tomhanks timallen donrickles … 1 |
lastenkirjaan perustuva lautapeli katoaminen … 1 |
Seuraavat vaiheet ovat samat kuin mitä teit Merkittävin ero Yllä olevasta tulosteesta näet, että syöttämässäsi metatiedossa on 73 881 sanastoa. Seuraavaksi mittaat Voit nyt käyttää uudelleen Hienoa! Näet, että suosittelijasi on onnistunut vangitsemaan enemmän tietoa suuremman metatiedon ansiosta ja on antanut sinulle parempia suosituksia. On tietysti lukuisia tapoja kokeilla tätä järjestelmää suositusten parantamiseksi. Joitakin ehdotuksia:
Yhteistyösuodatus PythonillaTässä opetusohjelmassa olet oppinut rakentamaan ikiomia yksinkertaisia ja sisällöllisiä elokuvasuosituksia. On olemassa myös toinen erittäin suosittu suosittelutyyppi, joka tunnetaan nimellä kollaboratiiviset suodattimet. Kollaboratiiviset suodattimet voidaan edelleen luokitella kahteen tyyppiin:
Esimerkki arvostelujärjestelmään perustuvasta yhteissuodatuksesta:
 Et rakenna näitä järjestelmiä tässä opetusohjelmassa, mutta tunnet jo suurimman osan siihen tarvittavista ideoista. Hyvä paikka aloittaa yhteistoiminnallisista suodattimista on tutkia MovieLens-tietokokonaisuutta, joka löytyy täältä. LoppupäätelmäOnnittelut tämän tutoriaalin loppuunsaattamisesta! Olet menestyksekkäästi käynyt läpi tutoriaalimme, jossa opit kaiken suosittelujärjestelmistä Pythonissa. Opitte rakentamaan yksinkertaisia ja sisältöpohjaisia suosittelijoita. Yksi hyvä harjoitus teille kaikille olisi toteuttaa yhteistoiminnallinen suodatus Pythonissa käyttäen MovieLens-tietokannan osajoukkoa, jota käytitte yksinkertaisten ja sisältöpohjaisten suosittelijoiden rakentamiseen. Jos olet vasta aloittamassa Python-ohjelmia ja haluat oppia lisää, osallistu DataCampin Johdatus tietojenkäsittelytieteeseen Pythonilla -kurssille. Mitä? |