El propósito de este tutorial no es convertirte en un experto en la construcción de modelos de sistemas de recomendación. En su lugar, el motivo es iniciarte dándote una visión general del tipo de sistemas de recomendación que existen y cómo puedes construir uno por ti
En este tutorial, aprenderás a construir un modelo básico de sistemas de recomendación simple y basado en el contenido. Aunque estos modelos no se acercarán en absoluto al estándar de la industria en términos de complejidad, calidad o precisión, le ayudará a iniciarse en la construcción de modelos más complejos que produzcan resultados aún mejores.
Los sistemas de recomendación se encuentran entre las aplicaciones más populares de la ciencia de datos hoy en día. Se utilizan para predecir la «calificación» o «preferencia» que un usuario daría a un artículo. Casi todas las grandes empresas tecnológicas los han aplicado de alguna forma. Amazon las utiliza para sugerir productos a los clientes, YouTube las utiliza para decidir qué vídeo es el siguiente en reproducirse automáticamente y Facebook las utiliza para recomendar páginas a las que dar un «me gusta» y personas a las que seguir.
Es más, para algunas empresas como Netflix, Amazon Prime, Hulu y Hotstar, el modelo de negocio y su éxito gira en torno a la potencia de sus recomendaciones. Netflix llegó a ofrecer un millón de dólares en 2009 a quien pudiera mejorar su sistema en un 10%.
También hay sistemas de recomendación populares para dominios como restaurantes, películas y citas en línea. También se han desarrollado sistemas de recomendación para explorar artículos de investigación y expertos, colaboradores y servicios financieros. YouTube utiliza el sistema de recomendación a gran escala para sugerirte vídeos en función de tu historial. Por ejemplo, si ves muchos vídeos educativos, te sugerirá ese tipo de vídeos.
¿Pero qué son estos sistemas de recomendación?
En términos generales, los sistemas de recomendación pueden clasificarse en 3 tipos:
- Recomendadores simples: ofrecen recomendaciones generalizadas a cada usuario, basadas en la popularidad y/o el género de las películas. La idea básica de este sistema es que las películas más populares y aclamadas por la crítica tendrán una mayor probabilidad de gustar al público medio. Un ejemplo podría ser el Top 250 de IMDB.
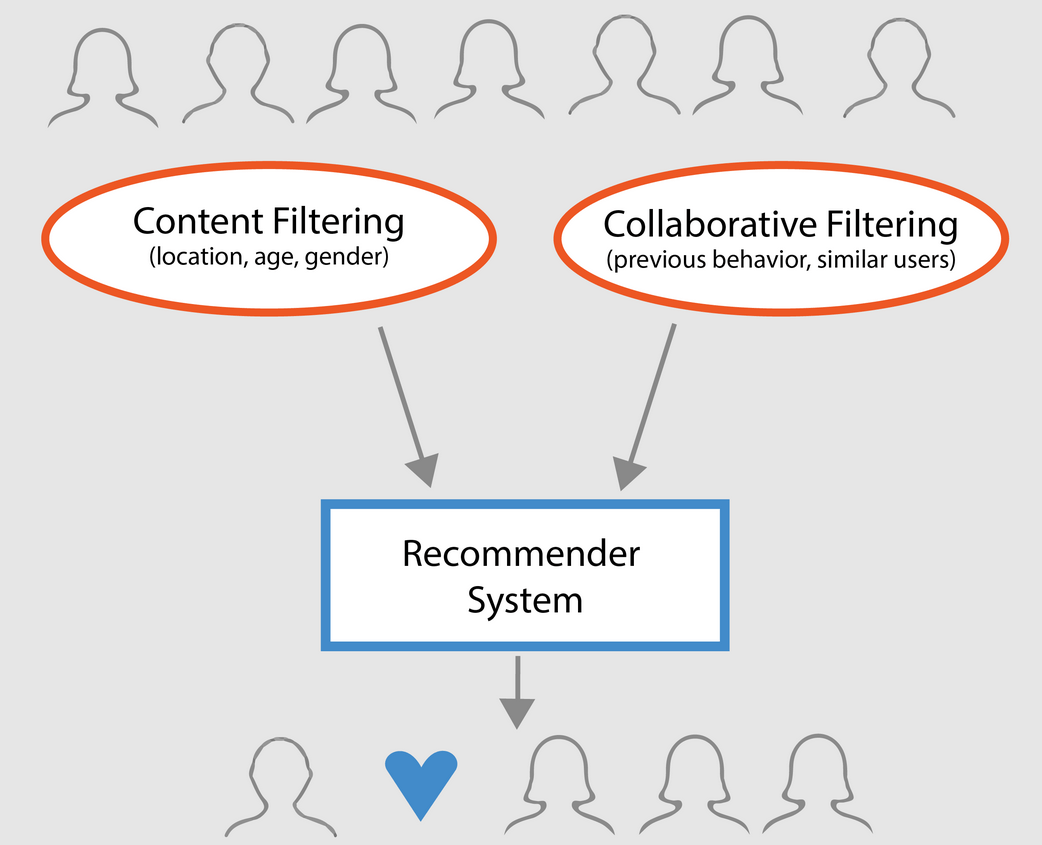
- Recomendadores basados en el contenido: sugieren artículos similares basados en un artículo concreto. Este sistema utiliza los metadatos del artículo, como el género, el director, la descripción, los actores, etc. de las películas, para hacer estas recomendaciones. La idea general de estos sistemas de recomendación es que si a una persona le gusta un artículo concreto, también le gustará otro similar. Y para recomendarlo, se utilizarán los metadatos de artículos anteriores del usuario. Un buen ejemplo podría ser YouTube, donde basándose en tu historial, te sugiere nuevos vídeos que podrías ver.
- Motores de filtrado colaborativo: estos sistemas son ampliamente utilizados, e intentan predecir la valoración o preferencia que un usuario daría a un elemento basándose en las valoraciones y preferencias anteriores de otros usuarios. Los filtros colaborativos no requieren metadatos de los elementos como sus homólogos basados en el contenido.
- Recomendadores simples
- Acerca del conjunto de datos
- Recomendador basado en el contenido
- Recomendador basado en la descripción de la trama
- Recomendador basado en créditos, géneros y palabras clave
- Filtrado colaborativo con Python
- Un ejemplo de filtrado colaborativo basado en un sistema de calificación:
- Conclusión
Recomendadores simples
Como se describió en la sección anterior, los recomendadores simples son sistemas básicos que recomiendan los mejores elementos en función de una determinada métrica o puntuación. En esta sección, construirá un clon simplificado de las 250 mejores películas de IMDB utilizando los metadatos recogidos de IMDB.
Los siguientes son los pasos a seguir:
-
Decida la métrica o puntuación para calificar las películas.
-
Calcular la puntuación de cada película.
-
Clasificar las películas en función de la puntuación y obtener los mejores resultados.
Acerca del conjunto de datos
Los archivos del conjunto de datos contienen los metadatos de las 45.000 películas que aparecen en el Full MovieLens Dataset. El conjunto de datos consta de películas estrenadas en julio de 2017 o antes. Este conjunto de datos captura puntos de características como el elenco, la tripulación, las palabras clave de la trama, el presupuesto, los ingresos, los carteles, las fechas de lanzamiento, los idiomas, las compañías de producción, los países, los recuentos de votos de TMDB y los promedios de votos.
Estos puntos de características podrían utilizarse para entrenar sus modelos de aprendizaje automático para el contenido y el filtrado colaborativo.
Este conjunto de datos consta de los siguientes archivos:
- movies_metadata.csv: Este archivo contiene información sobre ~45.000 películas que aparecen en el conjunto de datos Full MovieLens. Los datos incluyen carteles, fondos, presupuesto, género, ingresos, fechas de estreno, idiomas, países de producción y empresas.
- keywords.csv: Contiene las palabras clave de la trama de la película para nuestras películas MovieLens. Disponible en forma de un objeto JSON encadenado.
- credits.csv: Consiste en la información del reparto y del equipo de todas las películas. Disponible en forma de objeto JSON encadenado.
- links.csv: Este archivo contiene los ID de TMDB e IMDB de todas las películas que aparecen en el conjunto de datos de Full MovieLens.
- links_small.csv: Contiene los ID de TMDB e IMDB de un pequeño subconjunto de 9.000 películas del conjunto de datos completo.
- ratings_small.csv: El subconjunto de 100.000 valoraciones de 700 usuarios sobre 9.000 películas.
El conjunto de datos completo de MovieLens comprende 26 millones de valoraciones y 750.000 aplicaciones de etiquetas, de 270.000 usuarios sobre todas las 45.000 películas de este conjunto de datos. Se puede acceder desde el sitio web oficial de GroupLens.
Nota: El subconjunto de datos utilizado en el tutorial de hoy se puede descargar desde aquí.
Para cargar su conjunto de datos, se utilizaría la biblioteca pandas DataFrame. La biblioteca pandas se utiliza principalmente para la manipulación y el análisis de datos. Representa sus datos en un formato fila-columna. La biblioteca Pandas está respaldada por la matriz NumPy para la implementación de objetos de datos pandas. pandas ofrece estructuras de datos y operaciones para manipular tablas numéricas, series de tiempo, imágenes y conjuntos de datos de procesamiento de lenguaje natural. Básicamente, pandas es útil para aquellos conjuntos de datos que pueden ser fácilmente representados de forma tabular.
Antes de realizar cualquiera de los pasos anteriores, vamos a cargar su conjunto de datos de metadatos de películas en un pandas DataFrame:
# Import Pandasimport pandas as pd# Load Movies Metadatametadata = pd.read_csv('movies_metadata.csv', low_memory=False)# Print the first three rowsmetadata.head(3)| adulto | pertenece_a_la_colección | presupuesto | géneros | página | id | imdb_id | idioma_original | título_original | vista general | … | fecha_de_lanzamiento | ingreso | tiempo de ejecución | idiomas | estado | línea | title | video | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | Lanzamiento | NaN | Toy Story | Falso | 7.7 | 5415.0 | ||||||||||||
| 1 | Falso | NaN | 65000000 | Liberado | Sigue gritando. Todavía luchando. Still Ready for… | Grumpier Old Men | Falso | 6,5 | 92,0 |
3 filas × 24 columnas
Una de las métricas más básicas en las que se puede pensar es el ranking para decidir cuáles son las 250 mejores películas según sus respectivas valoraciones.
Sin embargo, utilizar una calificación como métrica tiene algunas advertencias:
-
Por un lado, no tiene en cuenta la popularidad de una película. Por lo tanto, una película con una calificación de 9 de 10 votantes se considerará «mejor» que una película con una calificación de 8,9 de 10.000 votantes.
Por ejemplo, imagine que quiere pedir comida china, tiene un par de opciones, un restaurante tiene una calificación de 5 estrellas por sólo 5 personas mientras que el otro restaurante tiene 4,5 calificaciones por 1000 personas. ¿Qué restaurante preferirías? El segundo, ¿no?
Por supuesto, podría darse la excepción de que el primer restaurante haya abierto hace sólo unos días; por lo tanto, menos gente lo ha votado mientras que, por el contrario, el segundo restaurante está operativo desde hace un año.
- En una nota relacionada, esta métrica también tenderá a favorecer a las películas con un menor número de votantes con valoraciones sesgadas y/o extremadamente altas. A medida que aumenta el número de votantes, la calificación de una película se regulariza y se aproxima a un valor que refleja la calidad de la película y da al usuario una idea mucho mejor de la película que debe elegir. Si bien es difícil discernir la calidad de una película con muy pocos votantes, es posible que haya que tener en cuenta fuentes externas para llegar a una conclusión.
Teniendo en cuenta estas deficiencias, hay que idear una calificación ponderada que tenga en cuenta la calificación media y el número de votos que ha acumulado. Un sistema de este tipo hará que una película con una calificación de 9 de 100.000 votantes obtenga una puntuación (muy) superior a la de una película con la misma calificación pero con apenas unos cientos de votantes.
Dado que estás intentando construir un clon del Top 250 de IMDB, vamos a utilizar su fórmula de calificación ponderada como métrica/puntuación. Matemáticamente, se representa como sigue:
En la ecuación anterior,
-
v es el número de votos de la película;
-
m es el mínimo de votos necesarios para aparecer en la tabla;
-
R es la valoración media de la película;
-
C es la media de votos de todo el informe.
Ya tiene los valores para v (vote_count) y R (vote_average) para cada película en el conjunto de datos. También es posible calcular directamente C a partir de estos datos.
Determinar un valor apropiado para m es un hiperparámetro que puede elegir en consecuencia ya que no hay un valor correcto para m. Puede considerarlo como un filtro negativo preliminar que simplemente eliminará las películas que tengan un número de votos inferior a un determinado umbral m. La selectividad de su filtro es a su discreción.
En este tutorial, se utilizará el corte m como el percentil 90. En otras palabras, para que una película aparezca en los gráficos, debe tener más votos que al menos el 90% de las películas de la lista. (En cambio, si hubiera elegido el percentil 75, habría considerado el 25% de las películas más votadas. A medida que el percentil disminuye, el número de películas consideradas aumentará).
Como primer paso, vamos a calcular el valor de C, la calificación media de todas las películas utilizando la función pandas .mean():
5.618207215133889De la salida anterior, se puede observar que la calificación media de una película en IMDB es alrededor de 5.6 en una escala de 10.
A continuación, vamos a calcular el número de votos, m, recibidos por una película en el percentil 90. La biblioteca pandas hace que esta tarea sea extremadamente trivial utilizando el método .quantile() de pandas:
# Calculate the minimum number of votes required to be in the chart, mm = metadata.quantile(0.90)print(m)160.0Dado que ahora tienes el m puedes simplemente utilizar una condición mayor que igual a para filtrar las películas que tengan un recuento de votos mayor que igual a 160:
Puedes utilizar el método .copy() para asegurarte de que el nuevo q_movies DataFrame creado es independiente de tu DataFrame de metadatos original. En otras palabras, cualquier cambio realizado en el DataFrame q_movies no afectará al DataFrame de metadatos original.
# Filter out all qualified movies into a new DataFrameq_movies = metadata.copy().loc >= m]q_movies.shape(4555, 24)metadata.shape(45466, 24)De la salida anterior, queda claro que hay alrededor de un 10% de películas con un recuento de votos superior a 160 y que cumplen los requisitos para estar en esta lista.
El siguiente paso, y el más importante, es calcular la calificación ponderada de cada película calificada. Para ello:
- Define una función,
weighted_rating(); - Como ya has calculado
myCsimplemente los pasarás como argumento a la función; - Después seleccionarás la columna
vote_count(v) yvote_average(R) del marco de datosq_movies; - Por último, calcularás la media ponderada y devolverás el resultado.
Definirás una nueva característica score, de la que calcularás el valor aplicando esta función a tu DataFrame de películas calificadas:
# Function that computes the weighted rating of each moviedef weighted_rating(x, m=m, C=C): v = x R = x # Calculation based on the IMDB formula return (v/(v+m) * R) + (m/(m+v) * C)# Define a new feature 'score' and calculate its value with `weighted_rating()`q_movies = q_movies.apply(weighted_rating, axis=1)Por último, vamos a ordenar el DataFrame en orden descendente basándonos en la columna de la característica score y a devolver el título, el recuento de votos, la media de votos y la calificación ponderada (puntuación) de las 20 mejores películas.
#Sort movies based on score calculated aboveq_movies = q_movies.sort_values('score', ascending=False)#Print the top 15 moviesq_movies].head(20)| Título | Cuento de votos | Promedio de votos | puntuación | |
|---|---|---|---|---|
| 314 | The Shawshank Redemption | 8358.0 | 8.5 | 8.445869 |
| 834 | El Padrino | 6024,0 | 8,5 | 8.425439 |
| 10309 | Dilwale Dulhania Le Jayenge | 661,0 | 9,1 | 8.421453 |
| 12481 | El caballero oscuro | 12269,0 | 8,3 | 8.265477 |
| 2843 | El club de la lucha | 9678.0 | 8.3 | 8.256385 |
| 292 | Pulp Fiction | 8670.0 | 8,3 | 8,251406 |
| 522 | Lista de Schindler | 4436,0 | 8.3 | 8.206639 |
| 23673 | Whiplash | 4376.0 | 8.3 | 8.205404 |
| 5481 | Spirited Away | 3968,0 | 8,3 | 8.196055 |
| 2211 | La vida es bella | 3643.0 | 8.3 | 8.187171 |
| 1178 | El Padrino: Parte II | 3418.0 | 8.3 | 8.180076 |
| 1152 | Un vuelo sobre el nido del cuco | 3001.0 | 8.3 | 8.164256 |
| 351 | Forrest Gump | 8147,0 | 8,2 | 8.150272 |
| 1154 | El Imperio Contraataca | 5998.0 | 8.2 | 8.132919 |
| 1176 | Psico | 2405.0 | 8.3 | 8.132715 |
| 18465 | Los Intocables | 5410.0 | 8,2 | 8,125837 |
| 40251 | Su nombre. | 1030,0 | 8,5 | 8,112532 |
| 289 | Leon: El profesional | 4293,0 | 8,2 | 8,107234 |
| 30 | La milla verde | 4166,0 | 8,2 | 8.¡104511 |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
Bueno, a partir de la salida anterior, se puede ver que el simple recommender hizo un gran trabajo!
Dado que la tabla tiene muchas películas en común con la tabla de las 250 mejores películas de IMDB: por ejemplo, sus dos primeras películas, «Shawshank Redemption» y «El Padrino», son las mismas que las de IMDB y todos sabemos que son, efectivamente, películas increíbles, de hecho, todas las películas del top 20 merecen estar en esa lista, ¿no?
Recomendador basado en el contenido
Recomendador basado en la descripción de la trama
En esta sección del tutorial, aprenderá a construir un sistema que recomiende películas que sean similares a una película en particular. Para conseguirlo, calculará las puntuaciones de similitud por pares cosine para todas las películas basándose en las descripciones de sus tramas y recomendará películas basándose en ese umbral de puntuación de similitud.
La descripción de la trama está disponible para usted como la característica overview en su conjunto de datos metadata. Inspeccionemos los argumentos de algunas películas:
#Print plot overviews of the first 5 movies.metadata.head()0 Led by Woody, Andy's toys live happily in his ...1 When siblings Judy and Peter discover an encha...2 A family wedding reignites the ancient feud be...3 Cheated on, mistreated and stepped on, the wom...4 Just when George Banks has recovered from his ...Name: overview, dtype: objectEl problema que nos ocupa es un problema de Procesamiento del Lenguaje Natural. Por lo tanto, es necesario extraer algún tipo de características de los datos de texto anteriores antes de poder calcular la similitud y/o disimilitud entre ellos. En pocas palabras, no es posible calcular la similitud entre dos resúmenes en bruto. Para ello, es necesario calcular los vectores de palabras de cada resumen o documento, como se llamará a partir de ahora.
Como su nombre indica, los vectores de palabras son una representación vectorial de las palabras de un documento. Los vectores llevan consigo un significado semántico. Por ejemplo, hombre & rey tendrá representaciones vectoriales cercanas entre sí mientras que hombre & mujer tendría representaciones lejanas entre sí.
Calcularás vectores Term Frequency-Inverse Document Frequency (TF-IDF) para cada documento. Esto le dará una matriz en la que cada columna representa una palabra del vocabulario general (todas las palabras que aparecen en al menos un documento), y cada columna representa una película, como antes.
En su esencia, la puntuación TF-IDF es la frecuencia de una palabra que aparece en un documento, ponderada a la baja por el número de documentos en los que aparece. Esto se hace para reducir la importancia de las palabras que aparecen con frecuencia en los resúmenes de las parcelas y, por lo tanto, su importancia en el cálculo de la puntuación de similitud final.
Afortunadamente, scikit-learn te da una clase incorporada TfIdfVectorizerque produce la matriz TF-IDF en un par de líneas.
- Importa el módulo Tfidf usando scikit-learn;
- Quita las palabras de parada como ‘el’, ‘un’, etc. ya que no aportan ninguna información útil sobre el tema;
- Reemplaza los valores no numéricos por una cadena en blanco;
- Por último, construye la matriz TF-IDF sobre los datos.
#Import TfIdfVectorizer from scikit-learnfrom sklearn.feature_extraction.text import TfidfVectorizer#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'tfidf = TfidfVectorizer(stop_words='english')#Replace NaN with an empty stringmetadata = metadata.fillna('')#Construct the required TF-IDF matrix by fitting and transforming the datatfidf_matrix = tfidf.fit_transform(metadata)#Output the shape of tfidf_matrixtfidf_matrix.shape(45466, 75827)#Array mapping from feature integer indices to feature name.tfidf.get_feature_names()De la salida anterior, se observa que 75.827 vocabularios o palabras diferentes en su conjunto de datos tienen 45.000 películas.
Con esta matriz en la mano, ahora puede calcular una puntuación de similitud. Hay varias métricas de similitud que puede utilizar para esto, como las puntuaciones de similitud manhattan, euclidiana, Pearson y coseno. Una vez más, no hay una respuesta correcta sobre qué puntuación es la mejor. Diferentes puntuaciones funcionan bien en diferentes escenarios, y a menudo es una buena idea experimentar con diferentes métricas y observar los resultados.
Utilizará el cosine similarity para calcular una cantidad numérica que denote la similitud entre dos películas. Se utiliza la puntuación de similitud del coseno ya que es independiente de la magnitud y es relativamente fácil y rápida de calcular (especialmente cuando se utiliza junto con las puntuaciones TF-IDF, que se explicarán más adelante). Matemáticamente, se define como sigue:
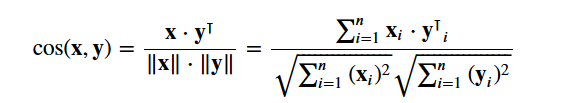
Como ha utilizado el vectorizador TF-IDF, el cálculo del producto punto entre cada vector le dará directamente la puntuación de similitud del coseno. Por lo tanto, se utilizará sklearn's linear_kernel() en lugar de cosine_similarities() ya que es más rápido.
Esto devolvería una matriz de forma 45466×45466, lo que significa que cada película overview puntuación de similitud coseno con cada otra película overview. Por lo tanto, cada película será un vector de columna 1×45466 donde cada columna será una puntuación de similitud con cada película.
# Import linear_kernelfrom sklearn.metrics.pairwise import linear_kernel# Compute the cosine similarity matrixcosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)cosine_sim.shape(45466, 45466)cosine_simarray()Vas a definir una función que toma en un título de la película como una entrada y salidas de una lista de las 10 películas más similares. En primer lugar, para esto, necesitas un mapeo inverso de los títulos de las películas y los índices del DataFrame. En otras palabras, necesitas un mecanismo para identificar el índice de una película en tu metadata DataFrame, dado su título.
#Construct a reverse map of indices and movie titlesindices = pd.Series(metadata.index, index=metadata).drop_duplicates()indicestitleToy Story 0Jumanji 1Grumpier Old Men 2Waiting to Exhale 3Father of the Bride Part II 4Heat 5Sabrina 6Tom and Huck 7Sudden Death 8GoldenEye 9dtype: int64Ahora estás en buena forma para definir tu función de recomendación. Estos son los siguientes pasos que seguirás:
-
Obtén el índice de la película dado su título.
-
Obtén la lista de puntuaciones de similitud del coseno de esa película en particular con todas las películas. Convertirla en una lista de tuplas donde el primer elemento es su posición, y el segundo es la puntuación de similitud.
-
Ordenar la mencionada lista de tuplas en base a las puntuaciones de similitud; es decir, el segundo elemento.
-
Obtener los 10 primeros elementos de esta lista. Ignore el primer elemento ya que se refiere a sí mismo (la película más similar a una película en particular es la propia película).
-
Retorne los títulos correspondientes a los índices de los elementos superiores.
# Function that takes in movie title as input and outputs most similar moviesdef get_recommendations(title, cosine_sim=cosine_sim): # Get the index of the movie that matches the title idx = indices # Get the pairwsie similarity scores of all movies with that movie sim_scores = list(enumerate(cosine_sim)) # Sort the movies based on the similarity scores sim_scores = sorted(sim_scores, key=lambda x: x, reverse=True) # Get the scores of the 10 most similar movies sim_scores = sim_scores # Get the movie indices movie_indices = for i in sim_scores] # Return the top 10 most similar movies return metadata.ilocget_recommendations('The Dark Knight Rises')12481 The Dark Knight150 Batman Forever1328 Batman Returns15511 Batman: Under the Red Hood585 Batman21194 Batman Unmasked: The Psychology of the Dark Kn...9230 Batman Beyond: Return of the Joker18035 Batman: Year One19792 Batman: The Dark Knight Returns, Part 13095 Batman: Mask of the PhantasmName: title, dtype: objectget_recommendations('The Godfather')1178 The Godfather: Part II44030 The Godfather Trilogy: 1972-19901914 The Godfather: Part III23126 Blood Ties11297 Household Saints34717 Start Liquidation10821 Election38030 A Mother Should Be Loved17729 Short Sharp Shock26293 Beck 28 - FamiljenName: title, dtype: objectVe que, aunque su sistema ha hecho un trabajo decente para encontrar películas con descripciones de trama similares, la calidad de las recomendaciones no es tan grande. «The Dark Knight Rises» devuelve todas las películas de Batman mientras que es más probable que las personas a las que les gustó esa película estén más inclinadas a disfrutar de otras películas de Christopher Nolan. Esto es algo que no puede ser capturado por su sistema actual.
Recomendador basado en créditos, géneros y palabras clave
La calidad de su recomendador aumentaría con el uso de mejores metadatos y capturando más detalles. Eso es precisamente lo que va a hacer en esta sección. Construirá un sistema de recomendación basado en los siguientes metadatos: los 3 actores principales, el director, los géneros relacionados y las palabras clave del argumento de la película.
Las palabras clave, el reparto y los datos del equipo no están disponibles en su conjunto de datos actual, por lo que el primer paso sería cargarlos y fusionarlos en su DataFrame principal metadata.
# Load keywords and creditscredits = pd.read_csv('credits.csv')keywords = pd.read_csv('keywords.csv')# Remove rows with bad IDs.metadata = metadata.drop()# Convert IDs to int. Required for mergingkeywords = keywords.astype('int')credits = credits.astype('int')metadata = metadata.astype('int')# Merge keywords and credits into your main metadata dataframemetadata = metadata.merge(credits, on='id')metadata = metadata.merge(keywords, on='id')# Print the first two movies of your newly merged metadatametadata.head(2)| adulto | pertenece_a_la_colección | presupuesto | géneros | página | id | imdb_id | idioma_original | título_original | versión | … | idiomas_hablados | estado | línea | título | vídeo | media de votos | cuento_de_votos | cast | tripulación | palabras clave | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Falso | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | Lanzamiento | NaN | Toy Story | Falso | 7.7 | 5415.0 | para feature en features: metadata = metadata.apply(literal_eval)
A continuación, escribe funciones que te ayuden a extraer la información necesaria de cada característica. Primero, importarás el paquete NumPy para acceder a su constante Obtén el nombre del director de la función crew. Si el director no está en la lista, devuelve A continuación, escribirás una función que devuelva los 3 primeros elementos o la lista completa, lo que sea más. Aquí la lista se refiere a los elementos
El siguiente paso sería convertir los nombres y las instancias de las palabras clave en minúsculas y quitar todos los espacios entre ellas. Eliminar los espacios entre las palabras es un importante paso de preprocesamiento. Se hace para que su vectorizador no cuente el Johnny de «Johnny Depp» y «Johnny Galecki» como el mismo. Después de este paso de procesamiento, los actores mencionados se representarán como «johnnydepp» y «johnnygalecki» y serán distintos para su vectorizador. Otro buen ejemplo en el que el modelo podría dar como resultado la misma representación vectorial es «atasco de pan» y «atasco de tráfico». Por lo tanto, es mejor eliminar cualquier espacio que esté presente. La función siguiente hará exactamente eso por usted: Ahora está en condiciones de crear su «sopa de metadatos», que es una cadena que contiene todos los metadatos que desea alimentar a su vectorizador (es decir, actores, director y palabras clave). La función
| sopa |
0 |
jealousy toy boy tomhanks timallen donrickles … 1 |
desaparición de un juego de mesa basado en un libro infantil …
Los siguientes pasos son los mismos que hiciste con tu La principal diferencia entre De la salida anterior, se puede ver que hay 73.881 vocabularios en los metadatos que se alimentaron. A continuación, utilizarás la Ahora puedes reutilizar tu función ¡Genial! Ya ves que tu recomendador ha conseguido captar más información gracias a más metadatos y te ha dado mejores recomendaciones. Hay, por supuesto, numerosas formas de experimentar con este sistema para mejorar las recomendaciones. Algunas sugerencias:
Filtrado colaborativo con PythonEn este tutorial, ha aprendido a construir sus propios sistemas de recomendación de películas simples y basados en el contenido. También existe otro tipo de recomendador extremadamente popular conocido como filtros colaborativos. Los filtros colaborativos pueden clasificarse a su vez en dos tipos:
Un ejemplo de filtrado colaborativo basado en un sistema de calificación:
 No construirás estos sistemas en este tutorial, pero ya estás familiarizado con la mayoría de las ideas necesarias para hacerlo. Un buen lugar para comenzar con los filtros colaborativos es examinando el conjunto de datos MovieLens, que se puede encontrar aquí. Conclusión¡Felicidades por terminar este tutorial! Ha pasado con éxito por nuestro tutorial que le enseñó todo sobre los sistemas de recomendación en Python. Has aprendido a construir recomendadores simples y basados en el contenido. Un buen ejercicio para todos vosotros sería implementar el filtrado colaborativo en Python utilizando el subconjunto de datos de MovieLens que has utilizado para construir recomendadores simples y basados en el contenido. Si te estás iniciando en Python y te gustaría aprender más, toma el curso de Introducción a la Ciencia de Datos en Python de DataCamp. |