Syftet med den här handledningen är inte att göra dig till expert på att bygga modeller för rekommendationssystem. Istället är motivet att få dig igång genom att ge dig en översikt över den typ av rekommendationssystem som finns och hur du kan bygga ett själv
I den här handledningen kommer du att lära dig att bygga en grundläggande modell för enkla och innehållsbaserade rekommendationssystem. Även om dessa modeller inte kommer att vara i närheten av industristandarden när det gäller komplexitet, kvalitet eller noggrannhet, kommer det att hjälpa dig att komma igång med att bygga mer komplexa modeller som ger ännu bättre resultat.
Recommendationssystem är bland de mest populära tillämpningarna av datavetenskap idag. De används för att förutsäga det ”betyg” eller den ”preferens” som en användare skulle ge ett föremål. Nästan alla större teknikföretag har tillämpat dem i någon form. Amazon använder dem för att föreslå produkter till kunderna, YouTube använder dem för att bestämma vilken video som ska spelas upp nästa gång på autoplay och Facebook använder dem för att rekommendera sidor att gilla och personer att följa.
För vissa företag som Netflix, Amazon Prime, Hulu och Hotstar är det till och med så att affärsmodellen och dess framgång kretsar kring hur starka deras rekommendationer är. Netflix erbjöd till och med 2009 en miljon dollar till den som kunde förbättra sitt system med 10 %.
Det finns också populära rekommendationssystem för områden som restauranger, filmer och nätdejting. Rekommenderande system har också utvecklats för att utforska forskningsartiklar och experter, samarbetspartners och finansiella tjänster. YouTube använder rekommendationssystem i stor skala för att föreslå dig videor utifrån din historik. Om du till exempel tittar på många utbildningsvideor skulle det föreslå den typen av videor.
Men vad är dessa rekommendationssystem?
I grova drag kan rekommendationssystem klassificeras i tre typer:
- Enkla rekommendationssystem: erbjuder generaliserade rekommendationer till varje användare, baserade på filmens popularitet och/eller genre. Den grundläggande idén bakom detta system är att filmer som är mer populära och kritikerrosade har en högre sannolikhet att gillas av den genomsnittliga publiken. Ett exempel kan vara IMDB Top 250.
- Innehållsbaserade rekommendationer: föreslår liknande objekt utifrån ett visst objekt. Detta system använder metadata om objektet, t.ex. genre, regissör, beskrivning, skådespelare osv. för filmer, för att göra dessa rekommendationer. Den allmänna idén bakom dessa rekommendationssystem är att om en person gillar en viss artikel kommer han eller hon också att gilla en artikel som liknar den. För att rekommendera detta kommer systemet att använda sig av användarens tidigare metadata om artiklar. Ett bra exempel kan vara YouTube, där systemet utifrån din historik föreslår nya videor som du eventuellt skulle kunna titta på.
- Collaborative filtering engines: Dessa system används i stor utsträckning och försöker förutsäga det betyg eller den preferens som en användare skulle ge ett objekt baserat på andra användares tidigare betyg och preferenser. Samarbetsfilter kräver inte metadata om objektet som dess innehållsbaserade motsvarigheter.
Simple Recommenders
Som beskrivits i föregående avsnitt är enkla recommenders grundläggande system som rekommenderar de bästa objekten baserat på ett visst mått eller poäng. I det här avsnittet ska du bygga en förenklad klon av IMDB Top 250 Movies med hjälp av metadata som samlats in från IMDB.
Sedan följer följande steg:
-
Beslut dig för vilken mätning eller poäng som filmerna ska bedömas utifrån.
-
Beräkna poängen för varje film.
-
Sortera filmerna baserat på poängen och ge ut de bästa resultaten.
Om datamängden
Datasetfilerna innehåller metadata för alla 45 000 filmer som anges i Full MovieLens Dataset. Datasetetet består av filmer som släpptes i eller före juli 2017. Datasetetet fångar funktionspunkter som skådespelare, besättning, nyckelord för handlingen, budget, intäkter, affischer, lanseringsdatum, språk, produktionsbolag, länder, TMDB-röstningssiffror och röstgenomsnitt.
Dessa funktionspunkter kan potentiellt användas för att träna dina maskininlärningsmodeller för innehåll och kollaborativ filtrering.
Den här datamängden består av följande filer:
- movies_metadata.csv: Den här filen innehåller information om ~45 000 filmer som ingår i Full MovieLens-dataset. Funktioner inkluderar affischer, bakgrunder, budget, genre, intäkter, releasedatum, språk, produktionsländer och företag.
- keywords.csv: Innehåller nyckelord för filmhandlingar för våra MovieLens-filmer. Finns i form av ett strängifierat JSON-objekt.
- credits.csv: Består av information om skådespelare och besättning för alla filmer. Finns i form av ett stringifierat JSON Object.
- links.csv: Denna fil innehåller TMDB- och IMDB-id för alla filmer som ingår i datasetet Full MovieLens.
- links_small.csv: Innehåller TMDB- och IMDB-id för en liten delmängd av 9 000 filmer i den fullständiga datamängden.
- ratings_small.csv: Delmängden av 100 000 bedömningar från 700 användare av 9 000 filmer.
Den fullständiga MovieLens-datamängden innehåller 26 miljoner bedömningar och 750 000 taggtillämpningar från 270 000 användare av alla de 45 000 filmer som ingår i denna datamängd. Den kan nås från den officiella GroupLens-webbplatsen.
Notera: Den delmängd dataset som används i dagens handledning kan laddas ner härifrån.
För att ladda ditt dataset använder du biblioteket pandas DataFrame. pandas biblioteket används främst för datamanipulering och analys. Det representerar dina data i ett rad-kolumnformat. Pandas-biblioteket stöds av arrayen NumPy för implementering av pandas-dataobjekt. pandas erbjuder färdiga datastrukturer och operationer för hantering av numeriska tabeller, tidsserier, bilder och datamängder för behandling av naturliga språk. I princip är pandas användbart för de dataset som lätt kan representeras i tabellform.
Innan du utför något av ovanstående steg ska vi ladda in ditt dataset med metadata om filmer i en pandas DataFrame:
# Import Pandasimport pandas as pd# Load Movies Metadatametadata = pd.read_csv('movies_metadata.csv', low_memory=False)# Print the first three rowsmetadata.head(3)| adult | belongs_to_collection | budget | genres | homepage | id | imdb_id | original_language | original_title | overview | … | release_date | revenue | runtime | spoken_languages | status | tagline | title | video | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {’id’: 10194, ’name’: ’Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | ||||||||||||
| 1 | Falskt | NaN | 65000000 | Uppsatt | Still Yelling. Kämpar fortfarande. Still Ready for… | Grumpier Old Men | Falsk | 6,5 | 92,0 |
3 rader × 24 kolumner
En av de mest grundläggande mätvärdena som man kan tänka sig är en rangordning för att avgöra vilka de 250 bästa filmerna är baserat på deras respektive betyg.
Att använda ett betyg som mått har dock några invändningar:
-
För det första tar det inte hänsyn till en films popularitet. Därför kommer en film med ett betyg på 9 av 10 röstare att betraktas som ”bättre” än en film med ett betyg på 8,9 av 10 000 röstare.
Föreställ dig till exempel att du vill beställa kinesisk mat, du har ett par alternativ, den ena restaurangen har ett femstjärnigt betyg av endast 5 personer medan den andra restaurangen har ett betyg på 4,5 av 1 000 personer. Vilken restaurang skulle du föredra? Den andra, eller hur?
Det kan naturligtvis finnas ett undantag där den första restaurangen öppnade för bara några dagar sedan, och därför har färre personer röstat på den, medan den andra restaurangen tvärtom har varit i drift i ett år.
- Det här måttet tenderar också att gynna filmer med färre röstande som har snedvridna och/eller extremt höga betyg. I takt med att antalet röstare ökar regleras bedömningen av en film och närmar sig ett värde som återspeglar filmens kvalitet och ger användaren en mycket bättre uppfattning om vilken film han/hon bör välja. Även om det är svårt att urskilja kvaliteten på en film med extremt få röstare kan du behöva ta hänsyn till externa källor för att dra slutsatser.
Med hänsyn till dessa brister måste du komma fram till ett viktat betyg som tar hänsyn till det genomsnittliga betyget och det antal röster som den har samlat. Ett sådant system kommer att se till att en film med ett 9-betyg från 100 000 röstande får ett (mycket) högre betyg än en film med samma betyg men med bara några hundra röstande.
Då du försöker bygga en klon av IMDB:s Top 250, låt oss använda dess viktade betygsformel som mått/poäng. Matematiskt sett representeras den på följande sätt:
\begin{equation}\text Weighted Rating (\bf WR) = \left({{\bf v} \over {\bf v} + {\bf m}} \cdot R\right) + \left({{\bf m} \over {\bf v} + {\bf m}} \cdot C\right)\end{equation}
I ovanstående ekvation,
-
v är antalet röster för filmen;
-
m är det minsta antal röster som krävs för att visas i diagrammet;
-
R är det genomsnittliga betyget för filmen;
-
C är medelvärdet av rösterna i hela rapporten.
Du har redan värdena till v (vote_count) och R (vote_average) för varje film i datasetet. Det är också möjligt att direkt beräkna C från dessa data.
Bestämningen av ett lämpligt värde för m är en hyperparameter som du kan välja därefter eftersom det inte finns något rätt värde för m. Du kan betrakta det som ett preliminärt negativt filter som helt enkelt tar bort de filmer som har ett antal röster som är lägre än ett visst tröskelvärde m. Selektiviteten hos ditt filter är upp till dig.
I den här handledningen kommer du att använda cutoff m som den 90:e percentilen. Med andra ord måste en film ha fler röster än minst 90 % av filmerna på listan för att visas i listorna. (Om du däremot hade valt den 75:e percentilen skulle du ha beaktat de 25 % bästa filmerna när det gäller antalet röster som samlats in. När percentilen minskar kommer antalet filmer som beaktas att öka).
Som ett första steg beräknar vi värdet av C, det genomsnittliga betyget för alla filmer med hjälp av pandas .mean()-funktionen:
# Calculate mean of vote average columnC = metadata.mean()print(C)5.618207215133889Från ovanstående utdata kan du konstatera att det genomsnittliga betyget för en film på IMDB ligger på cirka 5.6 på en skala på 10.
Nästan, låt oss beräkna antalet röster, m, som en film fått i den 90:e percentilen. Biblioteket pandas gör den här uppgiften extremt trivial med hjälp av .quantile()-metoden i pandas:
# Calculate the minimum number of votes required to be in the chart, mm = metadata.quantile(0.90)print(m)160.0När du nu har m kan du helt enkelt använda ett större än lika med-villkor för att filtrera bort filmer som har ett röstantal som är större än lika med 160:
Du kan använda .copy()-metoden för att se till att det nya q_movies-dataramnet som skapas är oberoende av ditt ursprungliga metadata-dataramnet. Med andra ord kommer alla ändringar som görs i q_movies DataFrame inte att påverka den ursprungliga metadata DataFrame.
# Filter out all qualified movies into a new DataFrameq_movies = metadata.copy().loc >= m]q_movies.shape(4555, 24)metadata.shape(45466, 24)Från ovanstående utdata står det klart att det finns cirka 10 % filmer som har ett röstetal som överstiger 160 och som kvalificerar sig för att finnas med på listan.
Nästa och viktigaste steg är att beräkna det viktade betyget för varje kvalificerad film. För att göra detta måste du:
- Definiera en funktion,
weighted_rating(); - Då du redan har beräknat
mochCkommer du helt enkelt att skicka dem som argument till funktionen; - Därefter kommer du att välja kolumnerna
vote_count(v) ochvote_average(R) frånq_movies-dataramen; - För att slutföra detta kommer du att beräkna det viktade genomsnittet och returnera resultatet.
Du kommer att definiera en ny funktion score, vars värde du beräknar genom att tillämpa den här funktionen på din DataFrame med kvalificerade filmer:
# Function that computes the weighted rating of each moviedef weighted_rating(x, m=m, C=C): v = x R = x # Calculation based on the IMDB formula return (v/(v+m) * R) + (m/(m+v) * C)# Define a new feature 'score' and calculate its value with `weighted_rating()`q_movies = q_movies.apply(weighted_rating, axis=1)Slutligt ska vi sortera DataFrame i fallande ordning baserat på kolumnen score feature och ge ut titeln, röstantalet, röstgenomsnittet och det viktade betyget (score) för de 20 bästa filmerna.
#Sort movies based on score calculated aboveq_movies = q_movies.sort_values('score', ascending=False)#Print the top 15 moviesq_movies].head(20)| title | vote_count | vote_average | score | ||
|---|---|---|---|---|---|
| 314 | The Shawshank Redemption | 8358.0 | 8.5 | 8.445869 | |
| 834 | The Godfather | 6024.0 | 8.5 | 8.425439 | |
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.421453 | |
| 12481 | The Dark Knight | 12269.0 | 8.3 | 8.265477 | |
| 2843 | Fight Club | 9678.0 | 8.3 | 8.256385 | |
| 292 | Pulp Fiction | 8670.0 | 8.3 | 8.251406 | |
| 522 | Schindlers lista | 4436.0 | 8.3 | 8.206639 | |
| 23673 | Whiplash | 4376.0 | 8.3 | 8.205404 | |
| 5481 | Spirited Away | 3968.0 | 8.3 | 8.196055 | |
| 2211 | Livet är vackert | 3643.0 | 8.3 | 8.187171 | |
| 1178 | The Godfather: Del II | 3418.0 | 8.3 | 8.180076 | |
| 1152 | One Flew Over the Cuckoo’s Nest | 3001.0 | 8.3 | 8.3 | 8.164256 |
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.150272 | |
| 1154 | The Empire Strikes Back | 5998.0 | 8.2 | 8.132919 | |
| 1176 | Psycho | 2405.0 | 8.3 | 8.132715 | |
| 18465 | The Intouchables | 5410.0 | 8.2 | 8.125837 | |
| 40251 | Ditt namn. | 1030.0 | 8.5 | 8.112532 | |
| 289 | Leon: The Professional | 4293.0 | 8.2 | 8.107234 | |
| 3030 | The Green Mile | 4166.0 | 8.2 | 8.104511 | |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
Närmast, från ovanstående utdata, kan du se att simple recommender gjorde ett bra jobb!
Då diagrammet har många filmer gemensamt med IMDB:s topp 250-tabell: till exempel är dina två bästa filmer, ”Shawshank Redemption” och ”Gudfadern”, samma som IMDB och vi vet alla att de verkligen är fantastiska filmer, i själva verket förtjänar alla topp 20-filmer att vara med på den listan, eller hur?
Content-Based Recommender
Plot Description Based Recommender
I det här avsnittet av handledningen kommer du att lära dig att bygga ett system som rekommenderar filmer som liknar en viss film. För att uppnå detta kommer du att beräkna parvisa cosine likhetspoäng för alla filmer baserat på deras handlingsbeskrivningar och rekommendera filmer baserat på detta tröskelvärde för likhetspoäng.
Handlingsbeskrivningen är tillgänglig för dig som overview-funktionen i ditt metadata-dataset. Låt oss inspektera intrigerna för några filmer:
#Print plot overviews of the first 5 movies.metadata.head()0 Led by Woody, Andy's toys live happily in his ...1 When siblings Judy and Peter discover an encha...2 A family wedding reignites the ancient feud be...3 Cheated on, mistreated and stepped on, the wom...4 Just when George Banks has recovered from his ...Name: overview, dtype: objectDet aktuella problemet är ett problem med behandling av naturligt språk. Därför måste du extrahera någon form av egenskaper från ovanstående textdata innan du kan beräkna likheten och/eller olikheten mellan dem. Enkelt uttryckt är det inte möjligt att beräkna likheten mellan två översikter i deras obearbetade form. För att göra detta måste man beräkna ordvektorerna för varje översikt eller dokument, som det kommer att kallas från och med nu.
Som namnet antyder är ordvektorer en vektoriserad representation av ord i ett dokument. Vektorerna bär en semantisk betydelse med sig. Till exempel kommer man & kung att ha vektorrepresentationer nära varandra medan man & kvinna skulle ha representation långt ifrån varandra.
Du kommer att beräkna Term Frequency-Inverse Document Frequency (TF-IDF) vektorer för varje dokument. Detta kommer att ge dig en matris där varje kolumn representerar ett ord i översiktsvokabulären (alla ord som förekommer i minst ett dokument) och varje kolumn representerar en film, som tidigare.
I sin essens är TF-IDF-poängen frekvensen av ett ord som förekommer i ett dokument, nedviktat med antalet dokument där det förekommer. Detta görs för att minska betydelsen av ord som ofta förekommer i handlingsöversikter och därmed deras betydelse vid beräkningen av den slutliga likhetspoängen.
Troligtvis ger scikit-learn dig en inbyggd TfIdfVectorizer-klass som producerar TF-IDF-matrisen på ett par rader.
- Importera Tfidf-modulen med hjälp av scikit-learn;
- Remsortera stoppord som ”the”, ”an” osv. eftersom de inte ger någon användbar information om ämnet;
- Ersätt not-a-number-värden med en tom sträng;
- Slutligen konstruerar du TF-IDF-matrisen på data.
#Import TfIdfVectorizer from scikit-learnfrom sklearn.feature_extraction.text import TfidfVectorizer#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'tfidf = TfidfVectorizer(stop_words='english')#Replace NaN with an empty stringmetadata = metadata.fillna('')#Construct the required TF-IDF matrix by fitting and transforming the datatfidf_matrix = tfidf.fit_transform(metadata)#Output the shape of tfidf_matrixtfidf_matrix.shape(45466, 75827)#Array mapping from feature integer indices to feature name.tfidf.get_feature_names()Från ovanstående utdata kan du konstatera att 75 827 olika vokabulärer eller ord i ditt dataset har 45 000 filmer.
Med den här matrisen i handen kan du nu beräkna ett likhetsvärde. Det finns flera likhetsmått som du kan använda för detta, t.ex. manhattan-, euklidisk-, Pearson- och cosinuslikhetspoäng. Återigen finns det inget rätt svar på vilken poäng som är bäst. Olika poäng fungerar bra i olika scenarier, och det är ofta en bra idé att experimentera med olika mått och observera resultaten.
Du kommer att använda cosine similarity för att beräkna en numerisk kvantitet som anger likheten mellan två filmer. Du använder cosinus-likhetsvärdet eftersom det är oberoende av storleken och är relativt enkelt och snabbt att beräkna (särskilt när det används tillsammans med TF-IDF-poäng, som kommer att förklaras senare). Matematiskt definieras det på följande sätt:
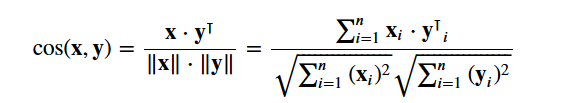
Då du har använt TF-IDF-vektoriseringen ger en beräkning av punktprodukten mellan varje vektor direkt cosinuslikhetspoängen. Därför kommer du att använda sklearn's linear_kernel() i stället för cosine_similarities() eftersom det är snabbare.
Detta skulle ge en matris med formen 45466×45466, vilket innebär att varje film overview har cosinelikhetspoäng med varje annan film overview. Därför kommer varje film att vara en 1×45466 kolumnvektor där varje kolumn kommer att vara en likhetspoäng med varje film.
# Import linear_kernelfrom sklearn.metrics.pairwise import linear_kernel# Compute the cosine similarity matrixcosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)cosine_sim.shape(45466, 45466)cosine_simarray()Du ska definiera en funktion som tar in en filmtitel som indata och ger ut en lista över de 10 mest likartade filmerna. För detta behöver du först och främst en omvänd mappning av filmtitlar och DataFrame-index. Med andra ord behöver du en mekanism för att identifiera indexet för en film i ditt metadata DataFrame, givet dess titel.
#Construct a reverse map of indices and movie titlesindices = pd.Series(metadata.index, index=metadata).drop_duplicates()indicestitleToy Story 0Jumanji 1Grumpier Old Men 2Waiting to Exhale 3Father of the Bride Part II 4Heat 5Sabrina 6Tom and Huck 7Sudden Death 8GoldenEye 9dtype: int64Du är nu i god form för att definiera din rekommendationsfunktion. Du kommer att följa följande steg:
-
Hämta filmens index givet dess titel.
-
Hämta listan över cosinuslikhetspoäng för just den filmen med alla filmer. Konvertera den till en lista med tupler där det första elementet är dess position och det andra är likhetspoängen.
-
Sortera den ovan nämnda listan med tupler baserat på likhetspoängen, det vill säga det andra elementet.
-
Hämta de tio bästa elementen i denna lista. Ignorera det första elementet eftersom det hänvisar till sig själv (den film som är mest lik en viss film är själva filmen).
-
Returnera titlarna som motsvarar indexen för de översta elementen.
# Function that takes in movie title as input and outputs most similar moviesdef get_recommendations(title, cosine_sim=cosine_sim): # Get the index of the movie that matches the title idx = indices # Get the pairwsie similarity scores of all movies with that movie sim_scores = list(enumerate(cosine_sim)) # Sort the movies based on the similarity scores sim_scores = sorted(sim_scores, key=lambda x: x, reverse=True) # Get the scores of the 10 most similar movies sim_scores = sim_scores # Get the movie indices movie_indices = for i in sim_scores] # Return the top 10 most similar movies return metadata.ilocget_recommendations('The Dark Knight Rises')12481 The Dark Knight150 Batman Forever1328 Batman Returns15511 Batman: Under the Red Hood585 Batman21194 Batman Unmasked: The Psychology of the Dark Kn...9230 Batman Beyond: Return of the Joker18035 Batman: Year One19792 Batman: The Dark Knight Returns, Part 13095 Batman: Mask of the PhantasmName: title, dtype: objectget_recommendations('The Godfather')1178 The Godfather: Part II44030 The Godfather Trilogy: 1972-19901914 The Godfather: Part III23126 Blood Ties11297 Household Saints34717 Start Liquidation10821 Election38030 A Mother Should Be Loved17729 Short Sharp Shock26293 Beck 28 - FamiljenName: title, dtype: objectDu ser att även om ditt system har gjort ett hyfsat bra jobb när det gäller att hitta filmer med liknande handlingsbeskrivningar så är kvaliteten på rekommendationerna inte så bra. ”The Dark Knight Rises” returnerar alla Batman-filmer medan det är mer troligt att de personer som gillade den filmen är mer benägna att gilla andra Christopher Nolan-filmer. Detta är något som ditt nuvarande system inte kan fånga upp.
Credits, Genres, and Keywords Based Recommender
Kvaliteten på din recommender skulle höjas med hjälp av bättre metadata och genom att fånga upp fler av de finare detaljerna. Det är precis vad du kommer att göra i det här avsnittet. Du kommer att bygga ett rekommendationssystem baserat på följande metadata: de tre främsta skådespelarna, regissören, relaterade genrer och nyckelord för filmens handling.
Nyckelorden, skådespelarna och besättningsuppgifterna finns inte tillgängliga i ditt nuvarande dataset, så det första steget skulle vara att ladda in och slå samman dem i ditt huvudsakliga DataFrame metadata.
# Load keywords and creditscredits = pd.read_csv('credits.csv')keywords = pd.read_csv('keywords.csv')# Remove rows with bad IDs.metadata = metadata.drop()# Convert IDs to int. Required for mergingkeywords = keywords.astype('int')credits = credits.astype('int')metadata = metadata.astype('int')# Merge keywords and credits into your main metadata dataframemetadata = metadata.merge(credits, on='id')metadata = metadata.merge(keywords, on='id')# Print the first two movies of your newly merged metadatametadata.head(2)| adult | belongs_to_collection | budget | genres | homepage | id | imdb_id | original_language | original_title | overview | … | spoken_languages | status | tagline | title | video | vote_average | vote_count | cast | crew | keywords | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {’id’: 10194, ’name’: ’Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | för feature i features: metadata = metadata.apply(literal_eval)
Nästan skriver du funktioner som hjälper dig att extrahera den nödvändiga informationen från varje feature. Först importerar du NumPy-paketet för att få tillgång till dess Hämta regissörens namn från crew-funktionen. Om regissören inte finns med i listan, returnera Nästan kommer du att skriva en funktion som returnerar de tre första elementen eller hela listan, beroende på vilket som är flest. Här avser listan
Nästa steg skulle vara att omvandla namnen och nyckelorden till små bokstäver och ta bort alla mellanslag mellan dem. Avlägsnande av mellanslag mellan ord är ett viktigt förbehandlingssteg. Det görs så att din vectorizer inte räknar Johnny av ”Johnny Depp” och ”Johnny Galecki” som samma. Efter detta bearbetningssteg kommer de ovannämnda skådespelarna att representeras som ”johnnydepp” och ”johnnygalecki” och kommer att vara olika för din vectorizer. Ett annat bra exempel där modellen kan ge ut samma vektorrepresentation är ”bread jam” och ”traffic jam”. Därför är det bättre att ta bort eventuella mellanslag. Den nedanstående funktionen kommer att göra exakt det åt dig: Du kan nu skapa din ”metadatasoppa”, som är en sträng som innehåller alla metadata som du vill mata till din vectorizer (nämligen skådespelare, regissör och nyckelord). Funktionen
| soppa |
0 |
jealousy toy boy tomhanks timallen donrickles … 1 |
brädspel försvinnande baserat på barnbok …
Nästa steg är samma som du gjorde med din Den stora skillnaden mellan Från ovanstående utdata kan du se att det finns 73 881 vokabulärer i de metadata som du matade in. Nästan kommer du att använda Du kan nu återanvända din Snyggt! Du ser att din rekommenderare har lyckats fånga in mer information tack vare mer metadata och har gett dig bättre rekommendationer. Det finns naturligtvis många sätt att experimentera med detta system för att förbättra rekommendationerna. Några förslag:
Collaborative Filtering with PythonI den här handledningen har du lärt dig hur du kan bygga ett helt eget enkelt och innehållsbaserat filmrekommendationssystem. Det finns också en annan extremt populär typ av recommender som kallas kollaborativa filter. Collaborativa filter kan vidare klassificeras i två typer:
Ett exempel på kollaborativ filtrering baserad på ett betygssystem:
 Du kommer inte att bygga upp dessa system i den här handledningen, men du är redan bekant med de flesta av de idéer som krävs för att göra det. Ett bra ställe att börja med kollaborativa filter är att undersöka MovieLens-dataset, som finns här. SlutsatsGrattis till att du är klar med den här handledningen! Du har framgångsrikt gått igenom vår handledning som lärde dig allt om rekommendationssystem i Python. Du har lärt dig att bygga enkla och innehållsbaserade rekommendationssystem. En bra övning för er alla skulle vara att implementera kollaborativ filtrering i Python med hjälp av den delmängd av MovieLens-dataset som du använde för att bygga enkla och innehållsbaserade rekommendationssystem. Om du bara har börjat med Python och vill lära dig mer, kan du gå DataCamps kurs Introduktion till datavetenskap i Python. |