Scopul acestui tutorial nu este de a vă face un expert în construirea de modele de sisteme de recomandare. În schimb, motivul este de a vă ajuta să începeți, oferindu-vă o prezentare generală a tipului de sisteme de recomandare care există și a modului în care puteți construi unul de unul singur
În acest tutorial, veți învăța cum să construiți un model de bază al sistemelor de recomandare simple și bazate pe conținut. Deși aceste modele nu vor fi nici pe departe apropiate de standardul industriei în ceea ce privește complexitatea, calitatea sau acuratețea, vă va ajuta să începeți să construiți modele mai complexe care să producă rezultate și mai bune.
Sistemele de recomandare se numără printre cele mai populare aplicații ale științei datelor din prezent. Ele sunt utilizate pentru a prezice „ratingul” sau „preferința” pe care un utilizator o va acorda unui element. Aproape fiecare companie tehnologică majoră le-a aplicat într-o formă sau alta. Amazon le folosește pentru a sugera produse clienților, YouTube le folosește pentru a decide ce videoclip să ruleze în continuare în redare automată, iar Facebook le folosește pentru a recomanda pagini de apreciat și oameni de urmărit.
Ceea ce este mai mult, pentru unele companii precum Netflix, Amazon Prime, Hulu și Hotstar, modelul de afaceri și succesul său se învârte în jurul potenței recomandărilor lor. Netflix a oferit chiar și un milion de dolari în 2009 oricui ar putea îmbunătăți sistemul său cu 10%.
Există, de asemenea, sisteme de recomandare populare pentru domenii precum restaurantele, filmele și întâlnirile online. De asemenea, au fost dezvoltate sisteme de recomandare pentru a explora articole de cercetare și experți, colaboratori și servicii financiare. YouTube utilizează sistemul de recomandare la scară largă pentru a vă sugera videoclipuri pe baza istoricului dumneavoastră. De exemplu, dacă urmăriți multe videoclipuri educaționale, vă va sugera aceste tipuri de videoclipuri.
Dar ce sunt aceste sisteme de recomandare?
În linii mari, sistemele de recomandare pot fi clasificate în 3 tipuri:
- Recomandatori simpli: oferă recomandări generalizate fiecărui utilizator, pe baza popularității și/sau genului filmului. Ideea de bază din spatele acestui sistem este că filmele care sunt mai populare și mai apreciate de critică vor avea o probabilitate mai mare de a fi apreciate de publicul mediu. Un exemplu ar putea fi IMDB Top 250.
- Recomandatoare bazate pe conținut: sugerează articole similare pe baza unui anumit element. Acest sistem utilizează metadatele articolului, cum ar fi genul, regizorul, descrierea, actorii, etc. pentru filme, pentru a face aceste recomandări. Ideea generală din spatele acestor sisteme de recomandare este că, dacă unei persoane îi place un anumit element, îi va plăcea și un element similar acestuia. Iar pentru a recomanda acest lucru, sistemul va utiliza metadatele anterioare ale utilizatorului. Un bun exemplu ar putea fi YouTube, unde, pe baza istoricului dumneavoastră, vă sugerează videoclipuri noi pe care ați putea să le vizionați.
- Motoare de filtrare colaborativă: aceste sisteme sunt utilizate pe scară largă și încearcă să prezică ratingul sau preferința pe care un utilizator o va acorda unui element pe baza ratingurilor și preferințelor anterioare ale altor utilizatori. Filtrele colaborative nu au nevoie de metadate ale itemului, precum omologii săi bazați pe conținut.
Recomandanți simpli
După cum a fost descris în secțiunea anterioară, recomandatorii simpli sunt sisteme de bază care recomandă elementele de top pe baza unei anumite metrici sau scoruri. În această secțiune, veți construi o clonă simplificată a IMDB Top 250 Movies folosind metadatele colectate de pe IMDB.
Cele mai jos sunt pașii implicați:
-
Decideți metrica sau scorul pe baza căruia să evaluați filmele.
-
Calculează scorul pentru fiecare film.
-
Sortează filmele pe baza scorului și scoate rezultatele de top.
Despre setul de date
Filele setului de date conțin metadate pentru toate cele 45.000 de filme listate în Full MovieLens Dataset. Setul de date este format din filme lansate în iulie 2017 sau înainte de această dată. Acest set de date surprinde puncte caracteristice precum distribuția, echipajul, cuvinte cheie ale complotului, bugetul, veniturile, posterele, datele de lansare, limbile, companiile de producție, țările, numărul de voturi TMDB și mediile voturilor.
Aceste puncte caracteristice ar putea fi potențial utilizate pentru a vă antrena modelele de învățare automată pentru filtrarea conținutului și filtrarea colaborativă.
Acest set de date este format din următoarele fișiere:
- movies_metadata.csv: Acest fișier conține informații despre ~45.000 de filme prezentate în setul de date Full MovieLens. Caracteristicile includ afișe, fundaluri, buget, gen, venituri, date de lansare, limbi, țări de producție și companii.
- keywords.csv: Conține cuvintele cheie ale parcelei de film pentru filmele noastre MovieLens. Disponibil sub forma unui obiect JSON stringificat.
- credits.csv: Conține informații despre distribuție și echipaj pentru toate filmele. Disponibil sub forma unui obiect JSON stringificat.
- links.csv: Acest fișier conține ID-urile TMDB și IMDB ale tuturor filmelor prezentate în setul de date Full MovieLens.
- links_small.csv: Conține ID-urile TMDB și IMDB ale unui mic subset de 9.000 de filme din setul complet de date.
- ratings_small.csv: Subsetul de 100.000 de evaluări de la 700 de utilizatori pentru 9.000 de filme.
Setul complet de date MovieLens cuprinde 26 de milioane de evaluări și 750.000 de aplicații de etichete, de la 270.000 de utilizatori pentru toate cele 45.000 de filme din acest set de date. Acesta poate fi accesat de pe site-ul oficial GroupLens.
Nota: Setul de date subset utilizat în tutorialul de astăzi poate fi descărcat de aici.
Pentru a încărca setul de date, veți utiliza biblioteca pandas DataFrame. Biblioteca pandas este utilizată în principal pentru manipularea și analiza datelor. Ea reprezintă datele dvs. într-un format rând-coloană. Biblioteca Pandas este susținută de matricea NumPy pentru implementarea obiectelor de date pandas. pandas oferă structuri de date și operații gata de utilizare pentru manipularea tabelelor numerice, a seriilor temporale, a imaginilor și a seturilor de date de procesare a limbajului natural. Practic, pandas este util pentru acele seturi de date care pot fi reprezentate cu ușurință într-o manieră tabulară.
Înainte de a efectua oricare dintre pașii de mai sus, haideți să încărcăm setul de date de metadate pentru filme într-un pandas DataFrame:
# Import Pandasimport pandas as pd# Load Movies Metadatametadata = pd.read_csv('movies_metadata.csv', low_memory=False)# Print the first three rowsmetadata.head(3)| adult | belongs_to_collection | budget | genres | budget | genres | homepage | id | imdb_id | original_language | original_title | overview | … | release_date | revenue | runtime | spoken_languages | status | tagline | tagline | title | video | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | |||||||||||||||
| 1 | False | NaN | 65000000 | Released | Still Yelling. Încă luptând. Still Ready for… | Grumpier Old Men | Fals | 6.5 | 92.0 |
3 rânduri × 24 coloane
Unul dintre cei mai de bază parametri la care vă puteți gândi este clasamentul pentru a decide care sunt cele mai bune 250 de filme pe baza ratingurilor respective.
Cu toate acestea, utilizarea unui rating ca metrică are câteva avertismente:
-
Pentru început, nu ia în considerare popularitatea unui film. Prin urmare, un film cu un rating de 9 din partea a 10 votanți va fi considerat „mai bun” decât un film cu un rating de 8,9 din partea a 10.000 de votanți.
De exemplu, imaginați-vă că doriți să comandați mâncare chinezească, aveți câteva opțiuni, un restaurant are un rating de 5 stele acordat de doar 5 persoane, în timp ce celălalt restaurant are un rating de 4,5 din partea a 1000 de persoane. Ce restaurant ați prefera? Al doilea, nu-i așa?
Desigur, ar putea exista o excepție în care primul restaurant a fost deschis cu doar câteva zile în urmă; prin urmare, mai puțini oameni au votat pentru el, în timp ce, dimpotrivă, cel de-al doilea restaurant este operațional de un an.
- În altă ordine de idei, această măsură va tinde, de asemenea, să favorizeze filmele cu un număr mai mic de votanți cu evaluări distorsionate și/sau extrem de ridicate. Pe măsură ce numărul de votanți crește, ratingul unui film se regularizează și se apropie de o valoare care reflectă calitatea filmului și îi oferă utilizatorului o idee mult mai bună despre ce film ar trebui să aleagă. În timp ce este dificil să discerni calitatea unui film cu extrem de puțini votanți, s-ar putea să trebuiască să iei în considerare surse externe pentru a concluziona.
Având în vedere aceste neajunsuri, trebuie să ajungi la un rating ponderat care să ia în considerare ratingul mediu și numărul de voturi pe care acesta le-a acumulat. Un astfel de sistem va face ca un film cu un rating de 9 din partea a 100.000 de votanți să primească un scor (mult) mai mare decât un film cu același rating, dar cu doar câteva sute de votanți.
Din moment ce încercați să construiți o clonă a Top 250 de pe IMDB, haideți să folosim formula sa de rating ponderat ca metrică/punctaj. Din punct de vedere matematic, aceasta este reprezentată după cum urmează:
\begin{equation}\text Weighted Rating (\bf WR) = \left({{\bf v} \over {\bf v} + {\bf m}} \cdot R\right) + \left({{\bf m} \over {\bf v} + {\bf m}} \cdot C\right)\end{equation}
În ecuația de mai sus,
-
v este numărul de voturi pentru film;
-
m este numărul minim de voturi necesare pentru a fi listat în grafic;
-
R este nota medie a filmului;
-
C este media voturilor din întregul raport.
Aveți deja valorile pentru v (vote_count) și R (vote_average) pentru fiecare film din setul de date. De asemenea, este posibil să se calculeze direct C din aceste date.
Determinarea unei valori adecvate pentru m este un hiperparametru pe care îl puteți alege în mod corespunzător, deoarece nu există o valoare corectă pentru m. Îl puteți considera ca un filtru negativ preliminar care va elimina pur și simplu filmele care au un număr de voturi mai mic decât un anumit prag m. Selectivitatea filtrului dvs. este la discreția dvs.
În acest tutorial, veți utiliza cutoff m ca fiind percentila 90. Cu alte cuvinte, pentru ca un film să apară în clasament, acesta trebuie să aibă mai multe voturi decât cel puțin 90% din filmele din listă. (Pe de altă parte, dacă ați fi ales percentila 75, ați fi luat în considerare primele 25% dintre filme în ceea ce privește numărul de voturi obținute. Pe măsură ce percentila scade, numărul de filme luate în considerare va crește).
Ca un prim pas, să calculăm valoarea lui C, ratingul mediu al tuturor filmelor, folosind funcția pandas .mean():
# Calculate mean of vote average columnC = metadata.mean()print(C)5.618207215133889Din rezultatul de mai sus, puteți observa că ratingul mediu al unui film pe IMDB este în jur de 5.6 pe o scală de 10.
În continuare, să calculăm numărul de voturi, m, primit de un film în a 90-a percentila. Biblioteca pandas face această sarcină extrem de trivială folosind metoda .quantile() din pandas:
# Calculate the minimum number of votes required to be in the chart, mm = metadata.quantile(0.90)print(m)160.0Din moment ce acum aveți m puteți folosi pur și simplu o condiție mai mare decât egal cu pentru a filtra filmele care au un număr de voturi mai mare decât egal cu 160:
Puteți folosi metoda .copy() pentru a vă asigura că noul q_movies DataFrame creat este independent de DataFrame-ul de metadate original. Cu alte cuvinte, orice modificări aduse cadrului de date q_movies DataFrame nu vor afecta cadrul de date original de metadate.
# Filter out all qualified movies into a new DataFrameq_movies = metadata.copy().loc >= m]q_movies.shape(4555, 24)metadata.shape(45466, 24)Din rezultatul de mai sus, este clar că există aproximativ 10% filme cu un număr de voturi mai mare de 160 și care se califică pentru a fi pe această listă.
Postul următor și cel mai important este calcularea ratingului ponderat pentru fiecare film calificat. Pentru a face acest lucru, veți:
- Definiți o funcție,
weighted_rating(); - Din moment ce ați calculat deja
mșiC, le veți trece pur și simplu ca argument pentru funcție; - Apoi veți selecta coloana
vote_count(v) șivote_average(R) din cadrul de dateq_movies; - În cele din urmă, veți calcula media ponderată și veți returna rezultatul.
Vă veți defini o nouă caracteristică score, a cărei valoare o veți calcula aplicând această funcție la cadrul de date al filmelor calificate:
# Function that computes the weighted rating of each moviedef weighted_rating(x, m=m, C=C): v = x R = x # Calculation based on the IMDB formula return (v/(v+m) * R) + (m/(m+v) * C)# Define a new feature 'score' and calculate its value with `weighted_rating()`q_movies = q_movies.apply(weighted_rating, axis=1)În cele din urmă, să sortăm cadrul de date în ordine descrescătoare pe baza coloanei score a caracteristicii score și să obținem titlul, numărul de voturi, media voturilor și ratingul (scorul) ponderat al primelor 20 de filme.
#Sort movies based on score calculated aboveq_movies = q_movies.sort_values('score', ascending=False)#Print the top 15 moviesq_movies].head(20)| title | vote_count | vote_average | vote_average | score | |
|---|---|---|---|---|---|
| 314 | The Shawshank Redemption | 8358.0 | 8.5 | 8.445869 | |
| 834 | The Godfather | 6024.0 | 8.5 | 8.425439 | |
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.421453 | |
| 12481 | The Dark Knight | 12269.0 | 8.3 | 8.265477 | |
| 2843 | Fight Club | 9678.0 | 8.3 | 8.256385 | |
| 292 | Pulp Fiction | 8670.0 | 8.3 | 8.251406 | |
| 522 | Schindler’s List | 4436.0 | 8.251406 | ||
| 522 | Schindler’s List | 4436.0 | 8.3 | 8.206639 | |
| 23673 | Whiplash | 4376.0 | 8.3 | 8.205404 | |
| 5481 | Spirited Away | 3968.0 | 8.3 | 8.196055 | |
| 2211 | Life Is Beautiful | 3643.0 | 8.3 | 8.187171 | |
| 1178 | The Godfather: Partea a II-a | 3418.0 | 8.3 | 8.180076 | |
| 1152 | One Flew Over the Cuckoo’s Nest | 3001.0 | 8.3 | 8.180076 | |
| 1152 | One Flew Over the Cuckoo’s Nest | 3001.0 | 8.3 | 8.164256 | |
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.150272 | |
| 1154 | The Empire Strikes Back | 5998.0 | 8.2 | 8.132919 | |
| 1176 | Psycho | 2405.0 | 8.3 | 8.132715 | |
| 18465 | The Intouchables | 5410.0 | 8.2 | 8.125837 | |
| 40251 | Your Name. | 1030.0 | 8.5 | 8.112532 | |
| 289 | Leon: The Professional | 4293.0 | 8.2 | 8.107234 | |
| 3030 | The Green Mile | 4166.0 | 8.2 | 8.104511 | |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
Bine, din rezultatul de mai sus, puteți vedea că simple recommender a făcut o treabă excelentă!
Din moment ce clasamentul are o mulțime de filme în comun cu clasamentul IMDB Top 250: de exemplu, primele două filme ale dumneavoastră, „Shawshank Redemption” și „The Godfather”, sunt aceleași ca și IMDB și știm cu toții că sunt într-adevăr filme uimitoare, de fapt, toate filmele din top 20 merită să fie în acea listă, nu-i așa?
Content-Based Recommender
Plot Description Based Recommender
În această secțiune a tutorialului, veți învăța cum să construiți un sistem care să recomande filme care sunt similare cu un anumit film. Pentru a realiza acest lucru, veți calcula scorurile de similaritate pe perechi cosine pentru toate filmele pe baza descrierilor de complot și veți recomanda filme pe baza acestui prag de scoruri de similaritate.
Descrierea complotului vă este disponibilă ca fiind caracteristica overview din setul de date metadata. Să inspectăm parcelele câtorva filme:
#Print plot overviews of the first 5 movies.metadata.head()0 Led by Woody, Andy's toys live happily in his ...1 When siblings Judy and Peter discover an encha...2 A family wedding reignites the ancient feud be...3 Cheated on, mistreated and stepped on, the wom...4 Just when George Banks has recovered from his ...Name: overview, dtype: objectProblema de față este o problemă de procesare a limbajului natural. Prin urmare, trebuie să extrageți un anumit tip de caracteristici din datele text de mai sus înainte de a putea calcula similaritatea și/sau disimilaritatea dintre ele. Pentru a simplifica, nu este posibil să se calculeze similitudinea între două imagini de ansamblu în forma lor brută. Pentru a face acest lucru, trebuie să calculați vectorii de cuvinte ai fiecărei imagini de ansamblu sau document, așa cum se va numi de acum încolo.
După cum sugerează și numele, vectorii de cuvinte sunt reprezentarea vectorizată a cuvintelor dintr-un document. Vectorii poartă cu ei o semnificație semantică. De exemplu, om & rege va avea reprezentări vectoriale apropiate unul de celălalt, în timp ce om & femeie va avea reprezentări îndepărtate unul de celălalt.
Voi calcula vectorii Term Frequency-Inverse Document Frequency (TF-IDF) pentru fiecare document. Acest lucru vă va da o matrice în care fiecare coloană reprezintă un cuvânt din vocabularul de prezentare generală (toate cuvintele care apar în cel puțin un document), iar fiecare coloană reprezintă un film, ca mai înainte.
În esența sa, scorul TF-IDF este frecvența de apariție a unui cuvânt într-un document, ponderată în minus cu numărul de documente în care acesta apare. Acest lucru se face pentru a reduce importanța cuvintelor care apar frecvent în rezumatele de complot și, prin urmare, importanța lor în calcularea scorului final de similaritate.
Din fericire, scikit-learn vă oferă o clasă încorporată TfIdfVectorizer care produce matricea TF-IDF în câteva rânduri.
- Importați modulul Tfidf folosind scikit-learn;
- Îndepărtați cuvintele de oprire cum ar fi ‘the’, ‘an’, etc. deoarece acestea nu oferă informații utile despre subiect;
- Înlocuiți valorile not-a-number cu un șir de caractere goale;
- În final, construiți matricea TF-IDF pe date.
#Import TfIdfVectorizer from scikit-learnfrom sklearn.feature_extraction.text import TfidfVectorizer#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'tfidf = TfidfVectorizer(stop_words='english')#Replace NaN with an empty stringmetadata = metadata.fillna('')#Construct the required TF-IDF matrix by fitting and transforming the datatfidf_matrix = tfidf.fit_transform(metadata)#Output the shape of tfidf_matrixtfidf_matrix.shape(45466, 75827)#Array mapping from feature integer indices to feature name.tfidf.get_feature_names()Din rezultatul de mai sus, observați că 75.827 de vocabulare sau cuvinte diferite din setul dumneavoastră de date au 45.000 de filme.
Cu această matrice în mână, puteți calcula acum un scor de similaritate. Există mai multe metrici de similaritate pe care le puteți utiliza pentru acest lucru, cum ar fi scorurile de similaritate manhattan, euclidian, Pearson și cosinus. Din nou, nu există un răspuns corect cu privire la care scor este cel mai bun. Scoruri diferite funcționează bine în scenarii diferite și este adesea o idee bună să experimentați cu diferite metrici și să observați rezultatele.
Vă veți utiliza cosine similarity pentru a calcula o cantitate numerică ce denotă similaritatea dintre două filme. Folosiți scorul de similaritate cosinus, deoarece este independent de magnitudine și este relativ ușor și rapid de calculat (în special atunci când este utilizat împreună cu scorurile TF-IDF, care vor fi explicate mai târziu). Din punct de vedere matematic, se definește după cum urmează:
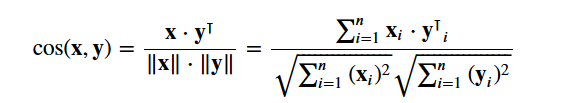
Din moment ce ați utilizat vectorizatorul TF-IDF, calcularea produsului punctat între fiecare vector vă va da direct scorul de similaritate cosinus. Prin urmare, veți folosi sklearn's linear_kernel() în loc de cosine_similarities(), deoarece este mai rapid.
Aceasta ar returna o matrice de forma 45466×45466, ceea ce înseamnă că fiecare film overview scor de similaritate cosinus cu fiecare alt film overview. Prin urmare, fiecare film va fi un vector de coloane 1×45466 în care fiecare coloană va fi un scor de similaritate cu fiecare film.
# Import linear_kernelfrom sklearn.metrics.pairwise import linear_kernel# Compute the cosine similarity matrixcosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)cosine_sim.shape(45466, 45466)cosine_simarray()Voi defini o funcție care primește ca intrare un titlu de film și produce o listă cu cele mai asemănătoare 10 filme. În primul rând, pentru aceasta, aveți nevoie de o cartografiere inversă a titlurilor de filme și a indicilor DataFrame. Cu alte cuvinte, aveți nevoie de un mecanism care să identifice indicele unui film în DataFrame metadata, având în vedere titlul acestuia.
#Construct a reverse map of indices and movie titlesindices = pd.Series(metadata.index, index=metadata).drop_duplicates()indicestitleToy Story 0Jumanji 1Grumpier Old Men 2Waiting to Exhale 3Father of the Bride Part II 4Heat 5Sabrina 6Tom and Huck 7Sudden Death 8GoldenEye 9dtype: int64Acum sunteți în stare să vă definiți funcția de recomandare. Aceștia sunt următorii pași pe care îi veți urma:
-
Obțineți indexul filmului, dat fiind titlul acestuia.
-
Obțineți lista scorurilor de similaritate cosinus pentru acel film anume cu toate filmele. Convertiți-o într-o listă de tupluri în care primul element este poziția sa, iar al doilea este scorul de similaritate.
-
Tritați lista de tupluri menționată mai sus pe baza scorurilor de similaritate; adică al doilea element.
-
Obțineți primele 10 elemente din această listă. Ignorați primul element deoarece se referă la sine (filmul cel mai asemănător cu un anumit film este filmul însuși).
-
Întoarceți titlurile corespunzătoare indicilor primelor elemente.
# Function that takes in movie title as input and outputs most similar moviesdef get_recommendations(title, cosine_sim=cosine_sim): # Get the index of the movie that matches the title idx = indices # Get the pairwsie similarity scores of all movies with that movie sim_scores = list(enumerate(cosine_sim)) # Sort the movies based on the similarity scores sim_scores = sorted(sim_scores, key=lambda x: x, reverse=True) # Get the scores of the 10 most similar movies sim_scores = sim_scores # Get the movie indices movie_indices = for i in sim_scores] # Return the top 10 most similar movies return metadata.ilocget_recommendations('The Dark Knight Rises')12481 The Dark Knight150 Batman Forever1328 Batman Returns15511 Batman: Under the Red Hood585 Batman21194 Batman Unmasked: The Psychology of the Dark Kn...9230 Batman Beyond: Return of the Joker18035 Batman: Year One19792 Batman: The Dark Knight Returns, Part 13095 Batman: Mask of the PhantasmName: title, dtype: objectget_recommendations('The Godfather')1178 The Godfather: Part II44030 The Godfather Trilogy: 1972-19901914 The Godfather: Part III23126 Blood Ties11297 Household Saints34717 Start Liquidation10821 Election38030 A Mother Should Be Loved17729 Short Sharp Shock26293 Beck 28 - FamiljenName: title, dtype: objectVezi că, deși sistemul tău a făcut o treabă decentă în găsirea filmelor cu descrieri similare ale intrigii, calitatea recomandărilor nu este atât de mare. „The Dark Knight Rises” întoarce toate filmele cu Batman, în timp ce este mai probabil ca persoanele cărora le-a plăcut acest film să fie mai înclinate să se bucure de alte filme ale lui Christopher Nolan. Acesta este un lucru pe care sistemul actual nu îl poate capta.
Credits, Genres, and Keywords Based Recommender
Calitatea recomandării dvs. ar fi crescută prin utilizarea unor metadate mai bune și prin captarea mai multor detalii mai fine. Este exact ceea ce veți face în această secțiune. Veți construi un sistem de recomandare bazat pe următoarele metadate: cei 3 actori de top, regizorul, genurile conexe și cuvintele cheie ale intrigii filmului.
Datele privind cuvintele cheie, distribuția și echipa de filmare nu sunt disponibile în setul dvs. de date actual, astfel încât primul pas ar fi să le încărcați și să le unificați în DataFrame-ul dvs. principal metadata.
# Load keywords and creditscredits = pd.read_csv('credits.csv')keywords = pd.read_csv('keywords.csv')# Remove rows with bad IDs.metadata = metadata.drop()# Convert IDs to int. Required for mergingkeywords = keywords.astype('int')credits = credits.astype('int')metadata = metadata.astype('int')# Merge keywords and credits into your main metadata dataframemetadata = metadata.merge(credits, on='id')metadata = metadata.merge(keywords, on='id')# Print the first two movies of your newly merged metadatametadata.head(2)| adult | aparține_colecției | buget | gene | genuri | homepage | id | imdb_id | original_language | original_title | overview | … | spoken_languages | status | tagline | title | video | spoken_average | vote_average | vote_count | cast | crew | keywords | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | for feature in features: metadata = metadata.apply(literal_eval)
În continuare, veți scrie funcții care vă vor ajuta să extrageți informațiile necesare din fiecare caracteristică. În primul rând, veți importa pachetul NumPy pentru a avea acces la constanta sa Obțineți numele regizorului din caracteristica echipajului. Dacă regizorul nu este listat, returnează În continuare, veți scrie o funcție care va returna primele 3 elemente sau întreaga listă, oricare dintre acestea este mai mare. Aici, lista se referă la
Postul următor ar fi să convertim numele și instanțele cuvintelor cheie în minuscule și să eliminăm toate spațiile dintre ele. Îndepărtarea spațiilor dintre cuvinte este un pas important de preprocesare. Se face astfel încât vectorizatorul dvs. să nu socotească Johnny de „Johnny Depp” și „Johnny Galecki” ca fiind același lucru. După acest pas de procesare, actorii menționați mai sus vor fi reprezentați ca „johnnydepp” și „johnnygalecki” și vor fi distincți pentru vectorizatorul dumneavoastră. Un alt exemplu bun în care modelul ar putea emite aceeași reprezentare vectorială este „blocaj de pâine” și „blocaj de trafic”. Prin urmare, este mai bine să eliminați orice spațiu care este prezent. Funcția de mai jos va face exact acest lucru pentru dumneavoastră: Sunteți acum în măsură să vă creați „supa de metadate”, care este un șir care conține toate metadatele pe care doriți să le furnizați vectorizatorului dumneavoastră (și anume actori, regizor și cuvinte cheie). Funcția
| soup |
0 |
jealousy toy boy tomhanks timallen donrickles …. 1 |
dispariția unui joc de tablă bazat pe o carte pentru copii …
Pasii următori sunt aceiași cu cei pe care i-ați făcut cu Diferența majoră dintre Din rezultatul de mai sus, puteți vedea că există 73 881 de vocabulare în metadatele pe care le-ați introdus. În continuare, veți folosi Acum puteți refolosi funcția Genial! Vedeți că recomandatorul dvs. a reușit să capteze mai multe informații datorită mai multor metadate și v-a oferit recomandări mai bune. Există, bineînțeles, numeroase modalități de a experimenta acest sistem pentru a îmbunătăți recomandările. Câteva sugestii:
Collaborative Filtering with PythonÎn acest tutorial, ați învățat cum să vă construiți propriile sisteme de recomandare de filme simple și bazate pe conținut. Există, de asemenea, un alt tip de recomandare extrem de popular, cunoscut sub numele de filtre colaborative. Filtrele colaborative pot fi clasificate în continuare în două tipuri:
Un exemplu de filtrare colaborativă bazată pe un sistem de evaluare:
 Nu veți construi aceste sisteme în acest tutorial, dar sunteți deja familiarizați cu majoritatea ideilor necesare pentru a face acest lucru. Un loc bun pentru a începe cu filtrele colaborative este examinarea setului de date MovieLens, care poate fi găsit aici. ConcluzieFelicitări pentru că ați terminat acest tutorial! Ați parcurs cu succes tutorialul nostru care v-a învățat totul despre sistemele de recomandare în Python. Ați învățat cum să construiți sisteme de recomandare simple și bazate pe conținut. Un exercițiu bun pentru voi toți ar fi să implementați filtrarea colaborativă în Python folosind subsetul de date MovieLens pe care l-ați folosit pentru a construi sisteme de recomandare simple și bazate pe conținut. Dacă sunteți la început în Python și doriți să învățați mai multe, urmați cursul Introducere în știința datelor în Python de la DataCamp. . |