Celem tego samouczka nie jest uczynienie z użytkownika eksperta w budowaniu modeli systemów rekomendacji. Zamiast tego, motywem przewodnim jest rozpoczęcie pracy z systemem rekomendującym poprzez zapoznanie się z typami systemów rekomendujących, które istnieją i jak można zbudować jeden z nich samodzielnie
W tym poradniku dowiesz się, jak zbudować podstawowy model prostego systemu rekomendującego opartego na treści. Chociaż modele te nie będą w żadnym stopniu zbliżone do standardów branżowych pod względem złożoności, jakości czy dokładności, pomogą Ci zacząć budować bardziej złożone modele, które dają jeszcze lepsze rezultaty.
Systemy rekomendacji są obecnie jednym z najpopularniejszych zastosowań nauki o danych. Służą one do przewidywania „oceny” lub „preferencji”, jakie użytkownik przyzna danemu przedmiotowi. Prawie każda duża firma technologiczna zastosowała je w jakiejś formie. Amazon wykorzystuje je do sugerowania produktów klientom, YouTube wykorzystuje je do decydowania, które wideo odtwarzać dalej na autoplay, a Facebook wykorzystuje je do rekomendowania stron do polubienia i ludzi do naśladowania.
Co więcej, dla niektórych firm, takich jak Netflix, Amazon Prime, Hulu i Hotstar, model biznesowy i jego sukces obraca się wokół potencji ich zaleceń. Netflix nawet zaoferował milion dolarów w 2009 roku każdemu, kto może poprawić swój system o 10%.
Istnieją również popularne systemy rekomendacji dla dziedzin takich jak restauracje, filmy i randki online. Systemy rekomendacji zostały również opracowane w celu wyszukiwania artykułów naukowych i ekspertów, współpracowników i usług finansowych. YouTube wykorzystuje system rekomendacji na dużą skalę, aby sugerować użytkownikowi filmy na podstawie jego historii. Na przykład, jeśli oglądasz dużo filmów edukacyjnych, będzie sugerować te typy filmów.
Ale czym są te systemy rekomendacji?
Ogólnie, systemy rekomendacji mogą być sklasyfikowane w 3 typach:
- Proste rekomendujące: oferują uogólnione rekomendacje dla każdego użytkownika, oparte na popularności filmu i/lub gatunku. Podstawową ideą tego systemu jest to, że filmy, które są bardziej popularne i doceniane przez krytyków, będą miały większe prawdopodobieństwo bycia lubianymi przez przeciętnego widza. Przykładem może być IMDB Top 250.
- Rekomendatory oparte na treści: sugerują podobne elementy na podstawie konkretnego elementu. System ten wykorzystuje metadane pozycji, takie jak gatunek, reżyser, opis, aktorzy, itp. dla filmów, aby dokonać tych rekomendacji. Ogólna idea tych systemów rekomendujących polega na tym, że jeśli dana osoba lubi dany przedmiot, to polubi również przedmiot, który jest do niego podobny. I aby to zarekomendować, wykorzysta metadane użytkownika dotyczące poprzednich pozycji. Dobrym przykładem może być YouTube, gdzie na podstawie historii użytkownika sugeruje on nowe filmy, które mógłby potencjalnie obejrzeć.
- Silniki filtrowania kolaboratywnego: systemy te są szeroko stosowane i próbują przewidzieć ocenę lub preferencje, jakie użytkownik przyzna danemu elementowi na podstawie wcześniejszych ocen i preferencji innych użytkowników. Filtry kolaboracyjne nie wymagają metadanych elementów, jak ich odpowiedniki oparte na zawartości.
Proste rekomendujące
Jak opisano w poprzedniej sekcji, proste rekomendujące są podstawowymi systemami, które rekomendują najlepsze elementy w oparciu o pewną metrykę lub wynik. W tej sekcji zbudujesz uproszczonego klona IMDB Top 250 Movies, używając metadanych zebranych z IMDB.
Następujące kroki:
-
Decyduj o metryce lub wyniku, na podstawie którego będziesz oceniać filmy.
-
Obliczenie wyniku dla każdego filmu.
-
Sortowanie filmów na podstawie wyniku i wyświetlenie najlepszych wyników.
O zbiorze danych
Pliki zbioru danych zawierają metadane dla wszystkich 45 000 filmów wymienionych w Full MovieLens Dataset. Zbiór danych składa się z filmów wydanych w lipcu 2017 roku lub wcześniej. Ten zbiór danych przechwytuje punkty charakterystyczne, takie jak obsada, załoga, słowa kluczowe fabuły, budżet, przychody, plakaty, daty premiery, języki, firmy produkcyjne, kraje, liczniki głosów TMDB i średnie głosy.
Te punkty charakterystyczne mogą być potencjalnie wykorzystane do szkolenia modeli uczenia maszynowego dla filtrowania treści i filtrowania kolaboracyjnego.
Ten zbiór danych składa się z następujących plików:
- movies_metadata.csv: Ten plik zawiera informacje o ~45,000 filmach znajdujących się w zbiorze danych Full MovieLens. Cechy obejmują plakaty, tła, budżet, gatunek, przychody, daty wydania, języki, kraje produkcji i firmy.
- keywords.csv: Zawiera słowa kluczowe fabuły filmowej dla naszych filmów MovieLens. Dostępne w postaci stringowanego obiektu JSON.
- credits.csv: Zawiera informacje o obsadzie i załodze dla wszystkich filmów. Dostępne w postaci obiektu JSON typu stringified.
- links.csv: Ten plik zawiera identyfikatory TMDB i IMDB wszystkich filmów znajdujących się w zestawie danych Full MovieLens.
- links_small.csv: Zawiera identyfikatory TMDB i IMDB małego podzbioru 9 000 filmów z pełnego zbioru danych.
- ratings_small.csv: Podzbiór 100 000 ocen od 700 użytkowników na temat 9 000 filmów.
Pełny zbiór danych MovieLens zawiera 26 milionów ocen i 750 000 aplikacji tagów, od 270 000 użytkowników na temat wszystkich 45 000 filmów w tym zbiorze danych. Dostęp do niego można uzyskać z oficjalnej strony GroupLens.
Uwaga: Podzbiór danych używany w dzisiejszym tutorialu można pobrać stąd.
Aby załadować swój zbiór danych, należy użyć biblioteki pandas DataFrame. Biblioteka pandas jest używana głównie do manipulacji i analizy danych. Reprezentuje ona twoje dane w formacie wiersz-kolumna. Biblioteka Pandas jest wspierana przez tablicę NumPy do implementacji obiektów danych pandas. pandas oferuje gotowe struktury danych i operacje do manipulowania tablicami numerycznymi, seriami czasowymi, obrazami i zestawami danych do przetwarzania języka naturalnego. Zasadniczo, pandas jest użyteczny dla tych zbiorów danych, które mogą być łatwo reprezentowane w sposób tabelaryczny.
Zanim wykonasz którąkolwiek z powyższych czynności, załadujmy zbiór danych metadanych filmów do pandas DataFrame:
# Import Pandasimport pandas as pd# Load Movies Metadatametadata = pd.read_csv('movies_metadata.csv', low_memory=False)# Print the first three rowsmetadata.head(3)| adult | belongs_to_collection | budget | genres | homepage | id | imdb_id | original_language | original_title | overview | … | release_date | revenue | runtime | spoken_languages | status | tagline | title | video | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {’id’: 10194, 'name’: 'Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | ||||||||||||
| 1 | False | NaN | 650000 | Released | Still Yelling. Wciąż walczący. Still Ready for… | Grumpier Old Men | False | 6.5 | 92.0 |
3 wiersze × 24 kolumny
Jedną z najbardziej podstawowych metryk, jakie można wymyślić, jest ranking, który decyduje o tym, które filmy są w top 250 na podstawie ich odpowiednich ocen.
Jednakże, używając oceny jako metryki ma kilka zastrzeżeń:
-
Dla jednego, nie bierze pod uwagę popularności filmu. Dlatego film z oceną 9 od 10 głosujących będzie uważany za „lepszy” niż film z oceną 8.9 od 10,000 głosujących.
Na przykład, wyobraź sobie, że chcesz zamówić chińskie jedzenie, masz kilka opcji, jedna restauracja ma 5-gwiazdkową ocenę tylko przez 5 osób, podczas gdy druga restauracja ma 4.5 oceny przez 1000 osób. Którą restaurację byś wolał? Drugą, prawda?
Oczywiście, może być wyjątek, że pierwsza restauracja została otwarta zaledwie kilka dni temu; stąd, mniej osób na nią głosowało, podczas gdy, przeciwnie, druga restauracja działa od roku.
- Na pokrewnej notatce, ta metryka będzie miała również tendencję do faworyzowania filmów z mniejszą liczbą głosujących z przekrzywionymi i/lub ekstremalnie wysokimi ocenami. Wraz ze wzrostem liczby głosujących, ocena filmu reguluje się i zbliża się do wartości, która odzwierciedla jakość filmu i daje użytkownikowi znacznie lepsze pojęcie o tym, który film powinien wybrać. Podczas gdy trudno jest ocenić jakość filmu z bardzo małą liczbą głosujących, możesz być zmuszony do rozważenia zewnętrznych źródeł, aby wyciągnąć wnioski.
Biorąc pod uwagę te niedociągnięcia, musisz wymyślić ważoną ocenę, która bierze pod uwagę średnią ocenę i liczbę głosów, które zgromadziła. Taki system zapewni, że film z oceną 9 od 100,000 głosujących otrzyma (znacznie) wyższą ocenę niż film z taką samą oceną, ale zaledwie kilkuset głosujących.
Ponieważ próbujesz zbudować klon Top 250 IMDB, użyjmy jego formuły ważonej oceny jako metryki/wyniku. Matematycznie, jest to reprezentowane w następujący sposób:
Ważona ocena (WR) = ∗ lewa({{bf v} ∗ nad {{bf v} + {{bf m}} ∗ prawa) + ∗ lewa({{bf m} ∗ nad {{bf v} + {{bf m}} ∗ prawa)∗ ∗ koniec{equation}
W powyższym równaniu,
-
v to liczba głosów oddanych na dany film;
-
m to minimalna liczba głosów wymagana do umieszczenia filmu na wykresie;
-
R to średnia ocena filmu;
-
C to średnia głosów w całym raporcie.
Już masz wartości do v (vote_count) i R (vote_average) dla każdego filmu w zbiorze danych. Możliwe jest również bezpośrednie obliczenie C z tych danych.
Określenie odpowiedniej wartości dla m jest hiperparametrem, który możesz odpowiednio dobrać, ponieważ nie ma właściwej wartości dla m. Możesz to potraktować jako wstępny filtr negatywny, który po prostu usunie filmy, które mają liczbę głosów mniejszą niż pewien próg m. Selektywność twojego filtra zależy od twojego uznania.
W tym poradniku użyjesz wartości m jako 90 percentyla. Innymi słowy, aby film znalazł się na liście przebojów, musi mieć więcej głosów niż co najmniej 90% filmów na liście. (Z drugiej strony, gdybyś wybrał 75 percentyl, wziąłbyś pod uwagę pierwsze 25% filmów pod względem liczby zdobytych głosów. W miarę jak percentyl maleje, liczba rozważanych filmów rośnie).
Pierwszym krokiem jest obliczenie wartości C, średniej oceny wszystkich filmów za pomocą funkcji pandas .mean():
# Calculate mean of vote average columnC = metadata.mean()print(C)5.618207215133889Z powyższego wyniku można zauważyć, że średnia ocena filmu na IMDB wynosi około 5.6 w skali 10.
Następnie obliczmy liczbę głosów, m, otrzymanych przez film w 90. percentylu. Biblioteka pandas czyni to zadanie niezwykle trywialnym przy użyciu metody .quantile() pandas:
# Calculate the minimum number of votes required to be in the chart, mm = metadata.quantile(0.90)print(m)160.0Ponieważ teraz masz już m, możesz po prostu użyć warunku greater than equal to, aby odfiltrować filmy o liczbie głosów większej niż równa 160:
Możesz użyć metody .copy(), aby upewnić się, że nowo utworzona q_movies DataFrame jest niezależna od Twojej oryginalnej metadata DataFrame. Innymi słowy, wszelkie zmiany wprowadzone do q_movies DataFrame nie będą miały wpływu na oryginalną ramkę danych metadanych.
# Filter out all qualified movies into a new DataFrameq_movies = metadata.copy().loc >= m]q_movies.shape(4555, 24)metadata.shape(45466, 24)Z powyższych danych wyjściowych jasno wynika, że istnieje około 10% filmów z liczbą głosów większą niż 160 i kwalifikujących się do znalezienia się na tej liście.
Następnym i najważniejszym krokiem jest obliczenie oceny ważonej dla każdego zakwalifikowanego filmu. Aby to zrobić, będziesz:
- Zdefiniuj funkcję,
weighted_rating(); - Ponieważ masz już obliczone
miC, po prostu przekażesz je jako argument do funkcji; - Następnie wybierzesz kolumnę
vote_count(v) ivote_average(R) z ramki danychq_movies; - Na koniec obliczysz średnią ważoną i zwrócisz wynik.
Zdefiniujesz nową cechę score, której wartość obliczysz, stosując tę funkcję do ramki DataFrame zawierającej zakwalifikowane filmy:
# Function that computes the weighted rating of each moviedef weighted_rating(x, m=m, C=C): v = x R = x # Calculation based on the IMDB formula return (v/(v+m) * R) + (m/(m+v) * C)# Define a new feature 'score' and calculate its value with `weighted_rating()`q_movies = q_movies.apply(weighted_rating, axis=1)Na koniec posortujmy ramkę DataFrame w porządku malejącym na podstawie kolumny cechy score i wypiszmy tytuł, liczbę głosów, średnią głosów i ocenę ważoną (score) 20 najlepszych filmów.
#Sort movies based on score calculated aboveq_movies = q_movies.sort_values('score', ascending=False)#Print the top 15 moviesq_movies].head(20)| title | vote_count | vote_average | score | |
|---|---|---|---|---|
| 314 | The Shawshank Redemption | 8358.0 | 8.5 | 8.445869 |
| 834 | The Godfather | 6024.0 | 8.5 | 8.425439 |
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.421453 |
| 12481 | The Dark Knight | 12269.0 | 8.3 | 8.265477 |
| 2843 | Fight Club | 9678.0 | 8.3 | 8.256385 |
| 292 | Pulp Fiction | 8670.0 | 8.3 | 8.251406 |
| 522 | Schindler’s List | 4436.0 | 8.3 | 8.206639 |
| 23673 | Whiplash | 4376.0 | 8.3 | 8.205404 |
| 5481 | Spirited Away | 3968.0 | 8.3 | 8.196055 |
| 2211 | Życie jest piękne | 3643.0 | 8.3 | 8.187171 |
| 1178 | Ojciec chrzestny: Część II | 3418.0 | 8.3 | 8.180076 |
| 1152 | One Flew Over the Cuckoo’s Nest | 3001.0 | 8.3 | 8.164256 |
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.150272 |
| 1154 | The Empire Strikes Back | 5998.0 | 8.2 | 8.132919 |
| 1176 | Psycho | 2405.0 | 8.3 | 8.132715 |
| 18465 | The Intouchables | 5410.0 | 8.2 | 8.125837 |
| 40251 | Twoje imię. | 1030.0 | 8.5 | 8.112532 |
| 289 | Leon: The Professional | 4293.0 | 8.2 | 8.107234 |
| 3030 | Zielona Mila | 4166.0 | 8.2 | 8.104511 |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
Więc, z powyższych danych wyjściowych widać, że simple recommender wykonał świetną robotę!
Ponieważ wykres ma wiele filmów wspólnych z wykresem IMDB Top 250: na przykład, twoje dwa najlepsze filmy, „Shawshank Redemption” i „The Godfather”, są takie same jak IMDB i wszyscy wiemy, że są to rzeczywiście niesamowite filmy, w rzeczywistości wszystkie filmy z Top 20 zasługują na to, aby być na tej liście, prawda?
Content-Based Recommender
Plot Description Based Recommender
W tej części kursu dowiesz się jak zbudować system, który poleca filmy, które są podobne do danego filmu. Aby to osiągnąć, obliczymy wynik podobieństwa parami cosine dla wszystkich filmów na podstawie ich opisów fabuły i polecimy filmy na podstawie tego progu wyniku podobieństwa.
Opis fabuły jest dostępny jako cecha overview w zbiorze danych metadata. Przyjrzyjmy się fabułom kilku filmów:
#Print plot overviews of the first 5 movies.metadata.head()0 Led by Woody, Andy's toys live happily in his ...1 When siblings Judy and Peter discover an encha...2 A family wedding reignites the ancient feud be...3 Cheated on, mistreated and stepped on, the wom...4 Just when George Banks has recovered from his ...Name: overview, dtype: objectPrzedmiotowy problem jest problemem związanym z przetwarzaniem języka naturalnego. Dlatego musisz wyodrębnić pewien rodzaj cech z powyższych danych tekstowych, zanim będziesz mógł obliczyć podobieństwo i / lub niepodobieństwo między nimi. Mówiąc wprost, nie jest możliwe obliczenie podobieństwa pomiędzy dwoma dowolnymi przeglądami w ich surowej formie. Aby to zrobić, musisz obliczyć wektory słów dla każdego przeglądu lub dokumentu, jak będziemy je od teraz nazywać.
Jak sama nazwa wskazuje, wektory słów są wektorową reprezentacją słów w dokumencie. Wektory niosą ze sobą znaczenie semantyczne. Na przykład, człowiek & król będzie miał reprezentacje wektorowe blisko siebie, podczas gdy człowiek & kobieta będzie miał reprezentacje daleko od siebie.
Obliczysz Term Frequency-Inverse Document Frequency (TF-IDF) wektory dla każdego dokumentu. To da ci macierz, gdzie każda kolumna reprezentuje słowo w słownictwie przeglądowym (wszystkie słowa, które pojawiają się w co najmniej jednym dokumencie), a każda kolumna reprezentuje film, jak poprzednio.
W swojej istocie, wynik TF-IDF jest częstością występowania słowa w dokumencie, ważoną w dół przez liczbę dokumentów, w których występuje. Ma to na celu zmniejszenie znaczenia słów, które często występują w przeglądach działek, a tym samym ich znaczenia przy obliczaniu ostatecznego wyniku podobieństwa.
Na szczęście scikit-learn daje Ci wbudowaną TfIdfVectorizer klasę, która produkuje macierz TF-IDF w kilku liniach.
- Importuj moduł Tfidf za pomocą scikit-learn;
- Usuń słowa stop, takie jak 'the’, 'an’, itp. ponieważ nie dają one żadnych użytecznych informacji na temat tematu;
- Zastąp wartości not-a-number pustym ciągiem znaków;
- Na koniec skonstruuj macierz TF-IDF na danych.
#Import TfIdfVectorizer from scikit-learnfrom sklearn.feature_extraction.text import TfidfVectorizer#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'tfidf = TfidfVectorizer(stop_words='english')#Replace NaN with an empty stringmetadata = metadata.fillna('')#Construct the required TF-IDF matrix by fitting and transforming the datatfidf_matrix = tfidf.fit_transform(metadata)#Output the shape of tfidf_matrixtfidf_matrix.shape(45466, 75827)#Array mapping from feature integer indices to feature name.tfidf.get_feature_names()Z powyższych danych wyjściowych wynika, że 75 827 różnych słowników lub słów w zbiorze danych ma 45 000 filmów.
Mając tę macierz w ręku, można teraz obliczyć wynik podobieństwa. Istnieje kilka metryk podobieństwa, których możesz użyć do tego celu, takich jak manhattan, euklidesowy, Pearson i cosinusowy wynik podobieństwa. Ponownie, nie ma dobrej odpowiedzi na to, który wynik jest najlepszy. Różne wyniki działają dobrze w różnych scenariuszach, i często dobrym pomysłem jest eksperymentowanie z różnymi metrykami i obserwowanie wyników.
Będziesz używał cosine similarity do obliczania liczb, które oznaczają podobieństwo między dwoma filmami. Używasz wyniku podobieństwa cosinusowego, ponieważ jest on niezależny od wielkości oraz stosunkowo łatwy i szybki do obliczenia (zwłaszcza w połączeniu z wynikami TF-IDF, które zostaną wyjaśnione później). Matematycznie, jest on zdefiniowany w następujący sposób:
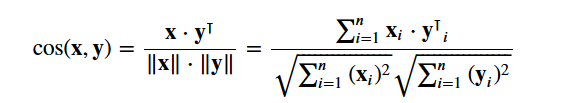
Ponieważ użyłeś wektoryzatora TF-IDF, obliczenie iloczynu kropek pomiędzy każdym wektorem da Ci bezpośrednio wynik podobieństwa cosinusowego. Dlatego użyjesz sklearn's linear_kernel() zamiast cosine_similarities(), ponieważ jest to szybsze.
To zwróciłoby macierz o kształcie 45466×45466, co oznacza, że każdy film overview ma wynik podobieństwa cosinusowego z każdym innym filmem overview. Stąd, każdy film będzie wektorem kolumnowym 1×45466, gdzie każda kolumna będzie wynikiem podobieństwa z każdym filmem.
# Import linear_kernelfrom sklearn.metrics.pairwise import linear_kernel# Compute the cosine similarity matrixcosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)cosine_sim.shape(45466, 45466)cosine_simarray()Zdefiniujesz funkcję, która przyjmie tytuł filmu jako dane wejściowe i wypisze listę 10 najbardziej podobnych filmów. Po pierwsze, potrzebujesz do tego odwrotnego mapowania tytułów filmów i indeksów DataFrame. Innymi słowy, potrzebujesz mechanizmu, który pozwoli Ci zidentyfikować indeks filmu w Twojej metadata DataFrame, biorąc pod uwagę jego tytuł.
#Construct a reverse map of indices and movie titlesindices = pd.Series(metadata.index, index=metadata).drop_duplicates()indicestitleToy Story 0Jumanji 1Grumpier Old Men 2Waiting to Exhale 3Father of the Bride Part II 4Heat 5Sabrina 6Tom and Huck 7Sudden Death 8GoldenEye 9dtype: int64Jesteś teraz w dobrej formie, aby zdefiniować swoją funkcję rekomendacji. Oto kolejne kroki, które wykonasz:
-
Znajdź indeks filmu, biorąc pod uwagę jego tytuł.
-
Znajdź listę wyników podobieństwa cosinusowego dla tego konkretnego filmu z wszystkimi filmami. Przekształć ją w listę krotek, gdzie pierwszy element to pozycja, a drugi to wynik podobieństwa.
-
Sortuj wspomnianą listę krotek na podstawie wyniku podobieństwa, czyli drugiego elementu.
-
Znajdź 10 najlepszych elementów tej listy. Zignoruj pierwszy element, ponieważ odnosi się on do samego siebie (filmem najbardziej podobnym do danego filmu jest sam film).
-
Zwróć tytuły odpowiadające indeksom górnych elementów.
# Function that takes in movie title as input and outputs most similar moviesdef get_recommendations(title, cosine_sim=cosine_sim): # Get the index of the movie that matches the title idx = indices # Get the pairwsie similarity scores of all movies with that movie sim_scores = list(enumerate(cosine_sim)) # Sort the movies based on the similarity scores sim_scores = sorted(sim_scores, key=lambda x: x, reverse=True) # Get the scores of the 10 most similar movies sim_scores = sim_scores # Get the movie indices movie_indices = for i in sim_scores] # Return the top 10 most similar movies return metadata.ilocget_recommendations('The Dark Knight Rises')12481 The Dark Knight150 Batman Forever1328 Batman Returns15511 Batman: Under the Red Hood585 Batman21194 Batman Unmasked: The Psychology of the Dark Kn...9230 Batman Beyond: Return of the Joker18035 Batman: Year One19792 Batman: The Dark Knight Returns, Part 13095 Batman: Mask of the PhantasmName: title, dtype: objectget_recommendations('The Godfather')1178 The Godfather: Part II44030 The Godfather Trilogy: 1972-19901914 The Godfather: Part III23126 Blood Ties11297 Household Saints34717 Start Liquidation10821 Election38030 A Mother Should Be Loved17729 Short Sharp Shock26293 Beck 28 - FamiljenName: title, dtype: objectWidzisz, że chociaż Twój system wykonał przyzwoitą robotę, znajdując filmy o podobnych opisach fabuły, to jakość rekomendacji nie jest aż tak dobra. „The Dark Knight Rises” zwraca wszystkie filmy o Batmanie, podczas gdy jest bardziej prawdopodobne, że ludzie, którym podobał się ten film, są bardziej skłonni do polubienia innych filmów Christophera Nolana. Jest to coś, czego nie może uchwycić Twój obecny system.
Credits, Genres, and Keywords Based Recommender
Jakość Twojego systemu rekomendacji wzrosłaby dzięki zastosowaniu lepszych metadanych i uchwyceniu większej ilości najdrobniejszych szczegółów. To właśnie zamierzasz zrobić w tym rozdziale. Zbudujesz system rekomendacji oparty na następujących metadanych: 3 głównych aktorach, reżyserze, powiązanych gatunkach i słowach kluczowych fabuły filmu.
Słowa kluczowe, obsada i załoga nie są dostępne w twoim obecnym zbiorze danych, więc pierwszym krokiem będzie załadowanie i połączenie ich do twojej głównej DataFrame metadata.
# Load keywords and creditscredits = pd.read_csv('credits.csv')keywords = pd.read_csv('keywords.csv')# Remove rows with bad IDs.metadata = metadata.drop()# Convert IDs to int. Required for mergingkeywords = keywords.astype('int')credits = credits.astype('int')metadata = metadata.astype('int')# Merge keywords and credits into your main metadata dataframemetadata = metadata.merge(credits, on='id')metadata = metadata.merge(keywords, on='id')# Print the first two movies of your newly merged metadatametadata.head(2)| adult | belongs_to_collection | budget | genres | homepage | id | imdb_id | original_language | original_title | overview | … | spoken_languages | status | tagline | title | video | vote_average | vote_count | cast | crew | keywords | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {’id’: 10194, 'name’: 'Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | for feature in features: metadata = metadata.apply(literal_eval)
Następnie napiszesz funkcje, które pomogą Ci wydobyć wymagane informacje z każdej cechy. Po pierwsze, zaimportujesz pakiet NumPy, aby uzyskać dostęp do jego Wyciągnij nazwisko reżysera z funkcji crew. Jeśli reżysera nie ma na liście, zwróć Następnie napiszesz funkcję, która zwróci 3 najlepsze elementy lub całą listę, w zależności od tego, ile jest ich więcej. Tutaj lista odnosi się do
Kolejnym krokiem byłoby przekonwertowanie nazwisk i instancji słów kluczowych na małe litery i usunięcie wszystkich spacji między nimi. Usuwanie spacji między słowami jest ważnym krokiem wstępnego przetwarzania. Robi się to po to, aby wektoryzator nie liczył „Johnny’ego Deppa” i „Johnny’ego Galeckiego” jako to samo. Po tym kroku przetwarzania, wyżej wymienieni aktorzy będą reprezentowani jako „johnnydepp” i „johnnygalecki” i będą odrębne dla twojego wektoryzatora. Innym dobrym przykładem, w którym model może wyprowadzić tę samą reprezentację wektorową jest „dżem chlebowy” i „korek uliczny”. Dlatego lepiej jest usunąć wszelkie spacje, które są obecne. Poniższa funkcja zrobi to dokładnie za Ciebie: Jesteś teraz w stanie stworzyć swoją „zupę metadanych”, która jest łańcuchem zawierającym wszystkie metadane, które chcesz dostarczyć do wektoryzatora (mianowicie aktorzy, reżyser i słowa kluczowe). Funkcja
| soup |
0 |
jealousy toy boy tomhanks timallen donrickles … 1 |
boardgame disappearance basedonchildren’sbook …
Następne kroki są takie same jak w przypadku Główną różnicą między Z powyższych danych wyjściowych widać, że istnieje 73 881 słowników w metadanych, które zostały wprowadzone. Następnie użyjesz funkcji Możesz teraz ponownie użyć funkcji Wspaniale! Widzisz, że Twojemu rekomendującemu udało się przechwycić więcej informacji dzięki większej ilości metadanych i dać Ci lepsze rekomendacje. Istnieje oczywiście wiele sposobów eksperymentowania z tym systemem w celu ulepszenia rekomendacji. Kilka sugestii:
Collaborative Filtering with PythonW tym poradniku dowiedziałeś się, jak zbudować swój własny prosty i oparty na treści system rekomendacji filmów. Istnieje również inny, niezwykle popularny typ systemów rekomendujących, znany jako filtry kolaboracyjne. Filtry kolaboracyjne można dalej podzielić na dwa typy:
Przykład filtrowania kolaboracyjnego opartego na systemie ocen:
 Nie będziesz budował takich systemów w tym podręczniku, ale znasz już większość pomysłów potrzebnych do tego. Dobrym miejscem do rozpoczęcia pracy z filtrami kolaboracyjnymi jest zbadanie zbioru danych MovieLens, który można znaleźć tutaj. PodsumowanieGratulujemy ukończenia tego kursu! Pomyślnie przeszedłeś przez nasz kurs, który nauczył Cię wszystkiego o systemach rekomendujących w Pythonie. Dowiedziałeś się jak budować proste i oparte na treści systemy rekomendujące. Jednym z dobrych ćwiczeń dla Was wszystkich byłoby zaimplementowanie filtrowania kolaboracyjnego w Pythonie przy użyciu podzbioru zbioru danych MovieLens, którego użyłeś do zbudowania prostych i opartych na treści systemów rekomendujących. Jeśli dopiero zaczynasz swoją przygodę z Pythonem i chciałbyś dowiedzieć się więcej, weź udział w kursie DataCamp Wprowadzenie do nauki o danych w Pythonie. |