Het doel van deze tutorial is niet om van jou een expert te maken in het bouwen van recommender system modellen. In plaats daarvan is het de bedoeling om je op weg te helpen door je een overzicht te geven van het type aanbevelingssysteem dat bestaat en hoe je er zelf een kunt bouwen
In deze tutorial leer je hoe je een basismodel kunt bouwen van eenvoudige en op inhoud gebaseerde aanbevelingssystemen. Hoewel deze modellen nergens in de buurt van de industriestandaard zullen komen in termen van complexiteit, kwaliteit of nauwkeurigheid, zal het je helpen om aan de slag te gaan met het bouwen van complexere modellen die nog betere resultaten opleveren.
Recommender systemen behoren tot de meest populaire toepassingen van data science vandaag. Ze worden gebruikt om de “waardering” of “voorkeur” te voorspellen die een gebruiker aan een item zou geven. Bijna elk groot techbedrijf heeft ze in een of andere vorm toegepast. Amazon gebruikt het om producten aan klanten voor te stellen, YouTube gebruikt het om te beslissen welke video als volgende moet worden afgespeeld op autoplay, en Facebook gebruikt het om pagina’s aan te bevelen om leuk te vinden en mensen om te volgen.
Wat meer is, voor sommige bedrijven zoals Netflix, Amazon Prime, Hulu en Hotstar, draait het businessmodel en het succes ervan om de potentie van hun aanbevelingen. Netflix bood in 2009 zelfs een miljoen dollar aan iedereen die zijn systeem met 10% kon verbeteren.
Er zijn ook populaire aanbevelingssystemen voor domeinen als restaurants, films, en online dating. Er zijn ook aanbevelingssystemen ontwikkeld voor onderzoeksartikelen en experts, medewerkers en financiële diensten. YouTube gebruikt het aanbevelingssysteem op grote schaal om je video’s voor te stellen op basis van je geschiedenis. Als je bijvoorbeeld veel educatieve video’s bekijkt, zou het dat soort video’s voorstellen.
Maar wat zijn deze aanbevelingssystemen?
In grote lijnen kunnen aanbevelingssystemen worden ingedeeld in 3 typen:
- Eenvoudige aanbevelingssystemen: bieden gegeneraliseerde aanbevelingen aan elke gebruiker, op basis van populariteit van films en/of genre. Het basisidee achter dit systeem is dat films die populairder zijn en door critici worden geprezen, een grotere kans hebben om door het gemiddelde publiek goed te worden gevonden. Een voorbeeld zou de IMDB Top 250 kunnen zijn.
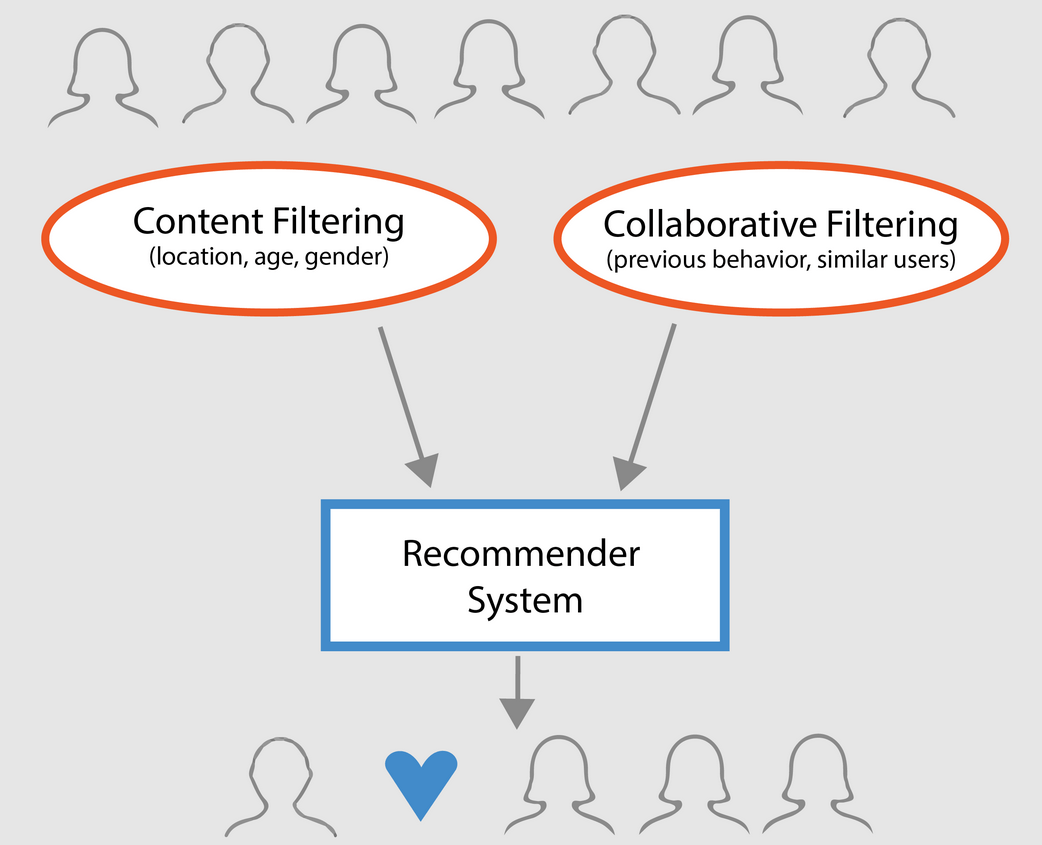
- Op inhoud gebaseerde recommandanten: suggereren soortgelijke items op basis van een bepaald item. Dit systeem gebruikt metagegevens over het item, zoals genre, regisseur, beschrijving, acteurs, enz. voor films, om deze aanbevelingen te doen. Het algemene idee achter deze aanbevelingssystemen is dat als een persoon een bepaald item leuk vindt, hij of zij ook een item leuk zal vinden dat erop lijkt. En om dat aan te bevelen, zal het gebruik maken van de metadata van het item uit het verleden van de gebruiker. Een goed voorbeeld is YouTube, waar op basis van je geschiedenis suggesties worden gedaan voor nieuwe video’s die je mogelijk zou kunnen bekijken.
- Motoren voor collaboratief filteren: deze systemen worden veel gebruikt en proberen de waardering of voorkeur te voorspellen die een gebruiker aan een item zou geven op basis van eerdere beoordelingen en voorkeuren van andere gebruikers. Collaboratieve filters vereisen geen metagegevens over het item, zoals de op inhoud gebaseerde tegenhangers.
Eenvoudige aanbevelers
Zoals in de vorige paragraaf is beschreven, zijn eenvoudige aanbevelers basissystemen die de beste items aanbevelen op basis van een bepaalde metriek of score. In dit gedeelte gaat u een vereenvoudigde kloon van IMDB Top 250 Films bouwen met behulp van metagegevens die u van IMDB hebt verzameld.
Het gaat om de volgende stappen:
-
Bepaal de metric of score om films op te beoordelen.
-
Bereken de score voor elke film.
-
Sorteer de films op basis van de score en geef de beste resultaten.
Over de dataset
De bestanden van de dataset bevatten metagegevens voor alle 45.000 films die zijn opgenomen in de Full MovieLens Dataset. De dataset bestaat uit films die op of voor juli 2017 zijn uitgebracht. Deze dataset legt kenmerkpunten vast zoals cast, crew, plot keywords, budget, inkomsten, posters, releasedata, talen, productiemaatschappijen, landen, TMDB stemmentellingen, en stemgemiddelden.
Deze kenmerken kunnen mogelijk worden gebruikt om uw modellen voor machinaal leren te trainen op inhoud en collaboratief filteren.
Deze dataset bestaat uit de volgende bestanden:
- movies_metadata.csv: Dit bestand bevat informatie over ~45.000 films in de volledige MovieLens-dataset. De kenmerken omvatten posters, achtergronden, budget, genre, inkomsten, releasedata, talen, productielanden en bedrijven.
- keywords.csv: Bevat de trefwoorden voor de plot van onze MovieLens-films. Beschikbaar in de vorm van een stringified JSON-object.
- credits.csv: Bevat informatie over de cast en crew van alle films. Beschikbaar in de vorm van een stringified JSON Object.
- links.csv: Dit bestand bevat de TMDB- en IMDB-ID’s van alle films die zijn opgenomen in de volledige MovieLens-dataset.
- links_small.csv: Bevat de TMDB- en IMDB-ID’s van een kleine subset van 9.000 films van de volledige dataset.
- ratings_small.csv: De subset van 100.000 ratings van 700 gebruikers over 9.000 films.
De volledige MovieLens-dataset bestaat uit 26 miljoen ratings en 750.000 tag-toepassingen, van 270.000 gebruikers over alle 45.000 films in deze dataset. Deze is toegankelijk via de officiële website van GroupLens.
Note: de subset dataset die in de tutorial van vandaag wordt gebruikt, kan hier worden gedownload.
Om uw dataset te laden, gebruikt u de pandas DataFrame-bibliotheek. pandas De bibliotheek wordt hoofdzakelijk gebruikt voor gegevensmanipulatie en analyse. Het vertegenwoordigt uw gegevens in een rij-kolom formaat. Pandas bibliotheek wordt ondersteund door de NumPy array voor de implementatie van pandas data objecten. pandas biedt kant-en-klare gegevensstructuren en bewerkingen voor het manipuleren van numerieke tabellen, tijdreeksen, beeldmateriaal, en natuurlijke taalverwerking datasets. In principe is pandas nuttig voor die datasets die gemakkelijk in tabelvorm kunnen worden weergegeven.
Voordat u een van de bovenstaande stappen uitvoert, laten we uw films metadata dataset in een pandas DataFrame laden:
# Import Pandasimport pandas as pd# Load Movies Metadatametadata = pd.read_csv('movies_metadata.csv', low_memory=False)# Print the first three rowsmetadata.head(3)| adult | belongs_to_collection | budget | genres | homepage | id | imdb_id | original_language | original_title | overview | … | release_date | revenue | runtime | spoken_languages | status | tagline | title | video | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | ||||||||||||
| 1 | False | NaN | 65000000 | Released | Still Yelling. Nog steeds vechtend. Still Ready for… | Grumpier Old Men | False | 6.5 | 92.0 |
3 rijen × 24 kolommen
Een van de meest elementaire metrieken die je kunt bedenken is de rangschikking om te bepalen welke top 250 films zijn op basis van hun respectieve ratings.
Het gebruik van een rating als meeteenheid heeft echter een paar beperkingen:
-
Zo houdt het geen rekening met de populariteit van een film. Daarom wordt een film met een waardering van 9 van 10 stemmers als ‘beter’ beschouwd dan een film met een waardering van 8,9 van 10.000 stemmers.
Stelt u zich bijvoorbeeld eens voor dat u Chinees wilt eten en u hebt een aantal opties. Het ene restaurant heeft een waardering van 5 sterren van slechts 5 mensen, terwijl het andere restaurant een waardering van 4,5 heeft van 1000 mensen. Aan welk restaurant zou u de voorkeur geven? Het tweede, toch?
Natuurlijk kan er een uitzondering zijn, namelijk dat het eerste restaurant pas een paar dagen geleden is geopend; vandaar dat er minder mensen op hebben gestemd, terwijl het tweede restaurant daarentegen al een jaar operationeel is.
- Op een verwante opmerking, deze metriek zal ook de neiging hebben om films te bevoordelen met een kleiner aantal stemmers met scheve en/of extreem hoge waarderingen. Naarmate het aantal stemmers toeneemt, wordt de waardering van een film regelmatiger en nadert een waarde die de kwaliteit van de film weerspiegelt en de gebruiker een veel beter idee geeft over welke film hij/zij zou moeten kiezen. Hoewel het moeilijk is om de kwaliteit van een film met extreem weinig stemmers te bepalen, moet je misschien externe bronnen raadplegen om tot een conclusie te komen.
Als je deze tekortkomingen in aanmerking neemt, moet je met een gewogen rating komen die rekening houdt met de gemiddelde rating en het aantal stemmen dat de film heeft gekregen. Zo’n systeem zorgt ervoor dat een film met een 9 van 100.000 stemmers een (veel) hogere score krijgt dan een film met dezelfde rating maar slechts een paar honderd stemmers.
Omdat je een kloon van IMDB’s Top 250 probeert te maken, laten we de formule van de gewogen rating als metriek/score gebruiken. Wiskundig wordt het als volgt voorgesteld:
begin{equation} {\bf WR} = \left({\bf v} \over {\bf v} + {\bf m}} \cdot R\right) + \left({\bf m} \over {\bf v} + {\bf m} \cdot C\right)\end{equation}
In de bovenstaande vergelijking,
-
v is het aantal stemmen voor de film;
-
m het vereiste minimumaantal stemmen om in de grafiek te worden opgenomen;
-
R de gemiddelde waardering van de film;
-
C de gemiddelde waardering over het gehele verslag.
Je hebt al de waarden voor v (vote_count) en R (vote_average) voor elke film in de dataset. Het is ook mogelijk om C rechtstreeks uit deze gegevens te berekenen.
Het bepalen van een geschikte waarde voor m is een hyperparameter die u zelf kunt kiezen, aangezien er geen juiste waarde voor m is. U kunt het als een voorlopig negatief filter beschouwen dat eenvoudig de films zal verwijderen die een aantal stemmen minder dan een bepaalde drempel m hebben. De selectiviteit van je filter is aan jou om te bepalen.
In deze tutorial gebruik je cutoff m als het 90e percentiel. Met andere woorden, een film komt alleen in de hitlijsten als hij meer stemmen heeft dan minstens 90% van de films op de lijst. (Als u daarentegen het 75e percentiel had gekozen, zou u de top 25% van de films in aanmerking hebben genomen wat betreft het aantal stemmen dat deze heeft gekregen. Naarmate het percentiel afneemt, neemt het aantal in aanmerking genomen films toe).
Als eerste stap berekenen we de waarde van C, de gemiddelde waardering over alle films met behulp van de pandas .mean() functie:
# Calculate mean of vote average columnC = metadata.mean()print(C)5.618207215133889Uit de bovenstaande uitvoer kunt u opmaken dat de gemiddelde waardering van een film op IMDB ongeveer 5,6 is op een schaal van 10.
# Calculate mean of vote average columnC = metadata.mean()print(C)5.618207215133889Uit de bovenstaande uitvoer kunt u opmaken dat de gemiddelde waardering van een film op IMDB ongeveer 5,6 is op een schaal van 10.
.6 op een schaal van 10.
Naar aanleiding van dit artikel berekenen we het aantal stemmen, m, dat een film in het 90e percentiel krijgt. De pandas bibliotheek maakt deze taak uiterst triviaal door gebruik te maken van de .quantile() methode van pandas:
# Calculate the minimum number of votes required to be in the chart, mm = metadata.quantile(0.90)print(m)160.0Omdat je nu de m hebt, kun je simpelweg een groter dan gelijk aan voorwaarde gebruiken om films met meer dan gelijk aan 160 stemmen uit te filteren:
U kunt de .copy() methode gebruiken om er zeker van te zijn dat het nieuwe q_movies DataFrame onafhankelijk is van uw originele metadata DataFrame. Met andere woorden, wijzigingen in het q_movies DataFrame hebben geen invloed op het oorspronkelijke metadata data frame.
# Filter out all qualified movies into a new DataFrameq_movies = metadata.copy().loc >= m]q_movies.shape(4555, 24)metadata.shape(45466, 24)Uit de bovenstaande uitvoer blijkt dat er ongeveer 10% films zijn met een stemmenaantal van meer dan 160 die in aanmerking komen om in deze lijst te worden opgenomen.
De volgende en belangrijkste stap is het berekenen van de gewogen rating voor elke gekwalificeerde film. Om dit te doen, zul je:
- Een functie definiëren,
weighted_rating(); - Omdat je
menCal hebt berekend, geef je ze gewoon als argument aan de functie mee; - Dan selecteer je de
vote_count(v) envote_average(R) kolom uit hetq_moviesdata frame; - Tot slot bereken je het gewogen gemiddelde en retourneer je het resultaat.
U definieert een nieuw kenmerk score, waarvan u de waarde berekent door deze functie toe te passen op uw DataFrame van gekwalificeerde films:
# Function that computes the weighted rating of each moviedef weighted_rating(x, m=m, C=C): v = x R = x # Calculation based on the IMDB formula return (v/(v+m) * R) + (m/(m+v) * C)# Define a new feature 'score' and calculate its value with `weighted_rating()`q_movies = q_movies.apply(weighted_rating, axis=1)Sorteer ten slotte het DataFrame in aflopende volgorde op basis van de kolom score van het kenmerk en geef de titel, het aantal stemmen, het stemgemiddelde en de gewogen waardering (score) van de top 20 films.
#Sort movies based on score calculated aboveq_movies = q_movies.sort_values('score', ascending=False)#Print the top 15 moviesq_movies].head(20)| titel | vote_count | vote_average | score | ||
|---|---|---|---|---|---|
| 314 | The Shawshank Redemption | 8358.0 | 8.5 | 8.445869 | |
| 834 | The Godfather | 6024.0 | 8.5 | 8.425439 | |
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.421453 | |
| 12481 | The Dark Knight | 12269.0 | 8.3 | 8.265477 | |
| 2843 | Fight Club | 9678.0 | 8.3 | 8.256385 | |
| 292 | Pulp Fiction | 8670.0 | 8.3 | 8.251406 | |
| 522 | Schindler’s List | 4436.0 | 8.3 | 8.206639 | |
| 23673 | Whiplash | 4376.0 | 8.3 | 8.205404 | |
| 5481 | Spirited Away | 3968.0 | 8.3 | 8.196055 | |
| 2211 | Life Is Beautiful | 3643.0 | 8.3 | 8.187171 | |
| 1178 | The Godfather: Part II | 3418.0 | 8.3 | 8.180076 | |
| 1152 | One Flew Over the Cuckoo’s Nest | 3001.0 | 8.3 | 8.164256 | 8.1.0 |
| 1152 | |||||
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.150272 | |
| 1154 | The Empire Strikes Back | 5998.0 | 8.2 | 8.132919 | |
| 1176 | Psycho | 2405.0 | 8.3 | 8.132715 | |
| 18465 | The Intouchables | 5410.0 | 8.2 | 8.125837 | |
| 40251 | Your Name. | 1030.0 | 8.5 | 8.112532 | |
| 289 | Leon: The Professional | 4293.0 | 8.2 | 8.107234 | |
| 3030 | The Green Mile | 4166.0 | 8.2 | 8.2 | 8.104511 |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
Wel, uit de bovenstaande uitvoer kunt u zien dat de simple recommender goed werk heeft geleverd!
Sinds de grafiek veel films gemeen heeft met de IMDB Top 250 grafiek: bijvoorbeeld, uw top twee films, “Shawshank Redemption” en “The Godfather”, zijn dezelfde als IMDB en we weten allemaal dat ze inderdaad geweldige films zijn, in feite, alle top 20 films verdienen het om in die lijst te staan, is het niet?
Content-Based Recommender
Plot Description Based Recommender
In dit deel van de tutorial leer je hoe je een systeem kunt bouwen dat films aanbeveelt die lijken op een bepaalde film. Om dit te bereiken, berekent u paarsgewijze cosine gelijkenisscores voor alle films op basis van hun plotbeschrijvingen en beveelt u films aan op basis van die gelijkenisscoordrempel.
De plotbeschrijving is voor u beschikbaar als overview kenmerk in uw metadata dataset. Laten we de plots van een paar films bekijken:
#Print plot overviews of the first 5 movies.metadata.head()0 Led by Woody, Andy's toys live happily in his ...1 When siblings Judy and Peter discover an encha...2 A family wedding reignites the ancient feud be...3 Cheated on, mistreated and stepped on, the wom...4 Just when George Banks has recovered from his ...Name: overview, dtype: objectHet probleem waar het hier om gaat is een Natural Language Processing probleem. Daarom moet je een soort kenmerken uit de bovenstaande tekstgegevens halen voordat je de gelijkenis en/of de ongelijkenis tussen hen kunt berekenen. Eenvoudig gezegd, is het niet mogelijk om de gelijkenis tussen twee overzichten in hun ruwe vorm te berekenen. Om dit te doen, moet u de woordvectoren berekenen van elk overzicht of document, zoals het van nu af aan zal worden genoemd.
Zoals de naam al aangeeft, zijn woordvectoren een gevectoriseerde weergave van woorden in een document. De vectoren dragen een semantische betekenis met zich mee. Bijvoorbeeld, man & koning zal vectorrepresentaties dicht bij elkaar hebben terwijl man & vrouw representatie ver van elkaar zou hebben.
U berekent Term Frequency-Inverse Document Frequency (TF-IDF) vectoren voor elk document. Dit zal u een matrix geven waar elke kolom een woord in het overzichtsvocabulaire vertegenwoordigt (alle woorden die in minstens één document voorkomen), en elke kolom vertegenwoordigt een film, zoals eerder.
In zijn essentie is de TF-IDF-score de frequentie van een woord dat in een document voorkomt, neerwaarts gewogen door het aantal documenten waarin het voorkomt. Dit wordt gedaan om het belang van woorden die vaak voorkomen in plotoverzichten te verminderen, en daarmee ook hun betekenis bij het berekenen van de uiteindelijke similariteitsscore.
Gelukkig geeft scikit-learn u een ingebouwde TfIdfVectorizer klasse die de TF-IDF matrix in een paar regels produceert.
- Importeer de Tfidf module met scikit-learn;
- Verwijder stopwoorden zoals ‘de’, ‘een’, enz. aangezien deze geen nuttige informatie over het onderwerp geven;
- Vervang niet-aantal waarden door een lege tekenreeks;
- Bouw ten slotte de TF-IDF-matrix op de gegevens.
#Import TfIdfVectorizer from scikit-learnfrom sklearn.feature_extraction.text import TfidfVectorizer#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'tfidf = TfidfVectorizer(stop_words='english')#Replace NaN with an empty stringmetadata = metadata.fillna('')#Construct the required TF-IDF matrix by fitting and transforming the datatfidf_matrix = tfidf.fit_transform(metadata)#Output the shape of tfidf_matrixtfidf_matrix.shape(45466, 75827)#Array mapping from feature integer indices to feature name.tfidf.get_feature_names()U kunt uit de bovenstaande uitvoer opmaken dat 75.827 verschillende vocabulaires of woorden in uw dataset 45.000 films hebben.
Met deze matrix in de hand kunt u nu een similariteitsscore berekenen. Er zijn verschillende similariteitsmetrieken die je hiervoor kunt gebruiken, zoals de manhattan, euclidische, de Pearson, en de cosinus similariteitsscores. Nogmaals, er is geen juist antwoord op de vraag welke score de beste is. Verschillende scores werken goed in verschillende scenario’s, en het is vaak een goed idee om met verschillende metrieken te experimenteren en de resultaten te observeren.
U gebruikt de cosine similarity om een numerieke waarde te berekenen die de overeenkomst tussen twee films weergeeft. Je gebruikt de cosinus similariteitsscore omdat die onafhankelijk is van de grootte en relatief eenvoudig en snel te berekenen is (vooral wanneer die wordt gebruikt in combinatie met TF-IDF scores, die later zullen worden uitgelegd). Wiskundig wordt hij als volgt gedefinieerd:
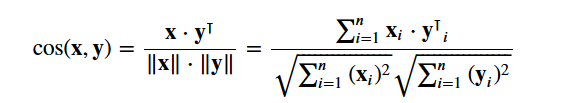
Omdat u de TF-IDF vectorizer hebt gebruikt, zal de berekening van het dot-product tussen elke vector u rechtstreeks de cosinus similariteitsscore opleveren. Daarom gebruikt u sklearn's linear_kernel() in plaats van cosine_similarities(), omdat dat sneller is.
Dit levert een matrix op met de vorm 45466×45466, wat betekent dat elke film overview cosine similarity score heeft met elke andere film overview. Elke film zal dus een kolomvector van 1×45466 zijn, waarbij elke kolom een gelijkenisscore met elke film is.
# Import linear_kernelfrom sklearn.metrics.pairwise import linear_kernel# Compute the cosine similarity matrixcosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)cosine_sim.shape(45466, 45466)cosine_simarray()Je gaat een functie definiëren die een filmtitel als invoer neemt en een lijst van de 10 meest gelijkende films als uitvoer geeft. Ten eerste heb je hiervoor een omgekeerde mapping nodig van filmtitels en DataFrame indices. Met andere woorden, je hebt een mechanisme nodig om de index van een film in je metadata DataFrame te identificeren, gegeven zijn titel.
#Construct a reverse map of indices and movie titlesindices = pd.Series(metadata.index, index=metadata).drop_duplicates()indicestitleToy Story 0Jumanji 1Grumpier Old Men 2Waiting to Exhale 3Father of the Bride Part II 4Heat 5Sabrina 6Tom and Huck 7Sudden Death 8GoldenEye 9dtype: int64Je bent nu in goede vorm om je aanbevelingsfunctie te definiëren. Dit zijn de volgende stappen die u zult volgen:
-
Ontdek de index van de film op basis van de titel.
-
Ontdek de lijst met cosinusgelijkenisscores voor die specifieke film met alle films. Zet deze om in een lijst met tupels waarvan het eerste element de positie is en het tweede de similariteitsscore.
-
Sorteer de bovengenoemde lijst met tupels op basis van de similariteitsscores; dat wil zeggen het tweede element.
-
Haal de top 10-elementen van deze lijst op. Negeer het eerste element, omdat dit naar zichzelf verwijst (de film die het meest op een bepaalde film lijkt, is de film zelf).
-
Geef de titels terug die overeenkomen met de indexen van de bovenste elementen.
# Function that takes in movie title as input and outputs most similar moviesdef get_recommendations(title, cosine_sim=cosine_sim): # Get the index of the movie that matches the title idx = indices # Get the pairwsie similarity scores of all movies with that movie sim_scores = list(enumerate(cosine_sim)) # Sort the movies based on the similarity scores sim_scores = sorted(sim_scores, key=lambda x: x, reverse=True) # Get the scores of the 10 most similar movies sim_scores = sim_scores # Get the movie indices movie_indices = for i in sim_scores] # Return the top 10 most similar movies return metadata.ilocget_recommendations('The Dark Knight Rises')12481 The Dark Knight150 Batman Forever1328 Batman Returns15511 Batman: Under the Red Hood585 Batman21194 Batman Unmasked: The Psychology of the Dark Kn...9230 Batman Beyond: Return of the Joker18035 Batman: Year One19792 Batman: The Dark Knight Returns, Part 13095 Batman: Mask of the PhantasmName: title, dtype: objectget_recommendations('The Godfather')1178 The Godfather: Part II44030 The Godfather Trilogy: 1972-19901914 The Godfather: Part III23126 Blood Ties11297 Household Saints34717 Start Liquidation10821 Election38030 A Mother Should Be Loved17729 Short Sharp Shock26293 Beck 28 - FamiljenName: title, dtype: objectJe ziet dat je systeem weliswaar goed werk heeft geleverd met het vinden van films met vergelijkbare plotbeschrijvingen, maar dat de kwaliteit van de aanbevelingen niet zo geweldig is. “The Dark Knight Rises” geeft alle Batman-films weer, terwijl het waarschijnlijker is dat de mensen die die film goed vonden, meer geneigd zijn van andere Christopher Nolan-films te genieten. Dit is iets dat niet kan worden opgevangen door je huidige systeem.
Credits, Genres, and Keywords Based Recommender
De kwaliteit van je recommender zou worden verhoogd met het gebruik van betere metadata en door meer van de fijnere details vast te leggen. Dat is precies wat je gaat doen in deze sectie. Je gaat een aanbevelingssysteem bouwen op basis van de volgende metadata: de 3 topacteurs, de regisseur, gerelateerde genres, en de trefwoorden voor de plot van de film.
De trefwoorden, cast, en crew gegevens zijn niet beschikbaar in je huidige dataset, dus de eerste stap zou zijn om ze te laden en samen te voegen in je hoofd DataFrame metadata.
# Load keywords and creditscredits = pd.read_csv('credits.csv')keywords = pd.read_csv('keywords.csv')# Remove rows with bad IDs.metadata = metadata.drop()# Convert IDs to int. Required for mergingkeywords = keywords.astype('int')credits = credits.astype('int')metadata = metadata.astype('int')# Merge keywords and credits into your main metadata dataframemetadata = metadata.merge(credits, on='id')metadata = metadata.merge(keywords, on='id')# Print the first two movies of your newly merged metadatametadata.head(2)| adult | belongs_to_collection | budget | genres | homepage | id | imdb_id | original_language | original_title | overview | … | spoken_talen | status | tagline | title | video | vote_average | vote_count | cast | crew | keywords | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | for feature in features: metadata = metadata.apply(literal_eval)
Volgende stap is het schrijven van functies die u helpen om de benodigde informatie uit elk kenmerk te halen. Eerst importeert u het NumPy-pakket om toegang te krijgen tot de Ontdek de naam van de regisseur uit de crew-functie. Als de regisseur niet in de lijst voorkomt, retourneert u Naar aanleiding hiervan schrijft u een functie die de bovenste 3 elementen of de hele lijst retourneert, afhankelijk van wat meer is. Hier verwijst de lijst naar de
De volgende stap zou zijn om de namen en trefwoordinstanties om te zetten in kleine letters en alle spaties ertussen te verwijderen. Het verwijderen van de spaties tussen de woorden is een belangrijke voorbewerkingsstap. Dit wordt gedaan om te voorkomen dat de vectorizer de Johnny van “Johnny Depp” en “Johnny Galecki” als hetzelfde beschouwt. Na deze bewerkingsstap zullen de bovengenoemde acteurs worden weergegeven als “johnnydepp” en “johnnygalecki” en zullen zij voor uw vectorizer verschillend zijn. Een ander goed voorbeeld waarbij het model dezelfde vectorrepresentatie zou kunnen opleveren is “bread jam” en “traffic jam”. Daarom is het beter om alle aanwezige spaties weg te strepen. De onderstaande functie zal dat precies voor u doen: U bent nu in een positie om uw “metadatasoep” te maken, wat een string is die alle metadata bevat die u aan uw vectorizer wilt toevoeren (namelijk acteurs, regisseur en trefwoorden). De
| soup |
0 |
jealousy toy boy tomhanks timallen donrickles …. 1 |
bordspelverdwijninggebaseerdopkinderboek …
De volgende stappen zijn hetzelfde als wat u deed met uw Het grote verschil tussen U ziet in de bovenstaande uitvoer dat er 73.881 vocabulaires zijn in de metadata die u eraan hebt toegevoerd. Daarna gebruikt u de U kunt nu uw Geweldig! Je ziet dat je aanbeveler er in geslaagd is om meer informatie vast te leggen door meer metadata en je betere aanbevelingen heeft gegeven. Er zijn natuurlijk talloze manieren om met dit systeem te experimenteren om de aanbevelingen te verbeteren. Enkele suggesties:
Collaborative Filtering with PythonIn deze tutorial heb je geleerd hoe je je eigen eenvoudige en inhoudsgebaseerde filmrecommender-systemen kunt bouwen. Er is ook een ander zeer populair type recommender dat bekend staat als collaboratieve filters. Collaboratieve filters kunnen verder worden geclassificeerd in twee typen:
Een voorbeeld van collaboratief filteren op basis van een beoordelingssysteem:
 U zult deze systemen niet bouwen in deze tutorial, maar u bent al bekend met de meeste ideeën die nodig zijn om dit te doen. Een goede plek om te beginnen met collaboratieve filters is door de MovieLens-dataset te bestuderen, die hier kan worden gevonden. ConclusieGefeliciteerd met het voltooien van deze tutorial! Je hebt met succes onze tutorial doorlopen waarin je alles hebt geleerd over aanbevelingssystemen in Python. Je hebt geleerd hoe je eenvoudige en op inhoud gebaseerde aanbevelingssystemen kunt bouwen. Een goede oefening voor jullie allemaal zou zijn om collaboratieve filtering in Python te implementeren met behulp van de subset van MovieLens dataset die je hebt gebruikt om eenvoudige en op inhoud gebaseerde aanbevelingssystemen te bouwen. Als je net begint met Python en meer wilt leren, volg dan DataCamp’s Introduction to Data Science in Python cursus. |