このチュートリアルの目的は、推薦システムモデル構築の専門家にすることではありません。 むしろ、存在するレコメンダーシステムの種類の概要を説明し、どのようにして自分でレコメンダーシステムを構築できるようになるかが目的です。
このチュートリアルでは、シンプルでコンテンツベースのレコメンダーシステムの基本モデルを構築する方法について学びます。 これらのモデルは、複雑さ、品質、または正確さの点で業界標準には遠く及びませんが、より良い結果を生むより複雑なモデルの構築を始めるのに役立ちます。
推薦システムは、今日のデータサイエンスの最も人気のあるアプリケーションの 1 つです。 これは、ユーザーがアイテムに与えるであろう「評価」または「好み」を予測するために使用されます。 ほぼすべての主要なハイテク企業が、何らかの形でこれを適用しています。 Amazon は顧客に商品を提案するために、YouTube は自動再生で次に再生するビデオを決定するために、Facebook は「いいね!」を押すページやフォローする人を推薦するために、それぞれ使用しています。 Netflix は 2009 年に、システムを 10% 改善できた人に 100 万ドルを提供したほどです。
また、レストラン、映画、オンライン デートなどの領域で人気のあるレコメンダー システムもあります。 また、研究論文や専門家、共同研究者、金融サービスなどを探索するための推薦システムも開発されている。 YouTubeでは、大規模にレコメンデーションシステムを使用して、履歴に基づいたビデオを提案しています。 たとえば、教育ビデオをたくさん見ていれば、そのようなタイプのビデオを提案します。
But what are these recommender systems?
Broadly, recommender systems can be classified into 3 types:
- Simple recommers: すべてのユーザーに対して、映画の人気やジャンルに基づいて一般的な推奨作品を提供します。 このシステムの基本的な考え方は、より人気があり批評的に評価されている映画は、平均的な観客に好かれる確率が高くなるということです。 例としては、IMDB トップ 250 が挙げられる。
- Content-based Recommenders: 特定のアイテムに基づき、類似のアイテムを提案する。 このシステムは、映画のジャンル、監督、説明、俳優など、アイテムのメタデータを使用して、これらの推薦を行う。 これらのレコメンダーシステムの一般的な考え方は、ある人が特定のアイテムを好きなら、それに類似したアイテムも好きになるだろうというものである。 そして、それを推薦するために、ユーザーの過去のアイテムのメタデータを利用するのである。
- 協調フィルタリングエンジン:このシステムは広く使われており、他のユーザーの過去の評価や好みに基づいて、ユーザーがアイテムに与えるであろう評価や好みを予測しようとします。
Simple Recommenders
前節で説明したように、シンプル レコメンダーは、特定のメトリックまたはスコアに基づいて上位アイテムを推奨する基本システムです。 このセクションでは、IMDB から収集したメタデータを使用して、IMDB Top 250 Movies の簡易クローンを構築します。
-
映画を評価するメトリックまたはスコアを決定する。
-
すべての映画のスコアを計算する。
-
スコアに基づいて映画をソートし、上位結果を出力する。
データセットについて
データセットファイルには Full MovieLens Dataset に記載した 45,000 作品すべてのメタデータが含まれています。 データセットは、2017年7月以前に公開された映画で構成されています。 このデータセットでは、キャスト、クルー、プロットキーワード、予算、収益、ポスター、リリース日、言語、制作会社、国、TMDB投票数、投票平均などの特徴点が取得されています。
これらの特徴点は、コンテンツと協調フィルタリングのための機械学習モデルを訓練するために使用される可能性があります。
このデータセットは次のファイルで構成されています。 ポスター、背景、予算、ジャンル、収益、公開日、言語、制作国、会社などが含まれます。
- keywords.csv: MovieLens ムービーのプロットキーワードが含まれています。 文字列化された JSON オブジェクトの形式で利用できます。
- credits.csv: すべての映画のキャストとクルー情報で構成されています。 文字列化された JSON オブジェクトの形式で提供されます。
- links.csv: Full MovieLens dataset.
- links_small.csv に含まれるすべての映画の TMDB と IMDB ID を含むファイルです。
- ratings_small.csv: 9,000 本の映画に対する 700 人のユーザーによる 10 万件の評価のサブセット
The Full MovieLens Dataset は、このデータセット内の全 45,000 本の映画に対する 27 万のユーザーによる 26 百万の評価および 750,000 のタグ アプリケーションから成ります。 これは、GroupLens の公式 Web サイトからアクセスできます。
注意: 今日のチュートリアルで使用するサブセット データセットは、ここからダウンロードできます。
データセットを読み込むには、pandas DataFrame ライブラリを使用します。 pandas ライブラリは、主にデータ操作と分析に使用されます。 行と列のフォーマットでデータを表現します。 Pandasライブラリは、pandasデータオブジェクトを実装するためのNumPy配列に支えられています。 pandasは、数値表、時系列、画像、自然言語処理のデータセットを操作するための既成のデータ構造と操作を提供します。 基本的に、pandasは表形式で簡単に表現できるデータセットに有用です。
上記の手順を実行する前に、映画のメタデータ データセットを pandas DataFrame にロードしてみましょう。
# Import Pandasimport pandas as pd# Load Movies Metadatametadata = pd.read_csv('movies_metadata.csv', low_memory=False)# Print the first three rowsmetadata.head(3)| adult | belongs_to_collection | budget | genres | ホームページ | id | imdb_id | オリジナル言語 | オリジナルタイトル | 概要 | …続きを読む.. | リリース日 | 収益 | ランタイム | 使用言語 | ステータス | タグライン | title | video | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‘id’. 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | NaN | Toy Story | False | 7.7 | 5415.0 | |||||||||||||
| 1 | False | NaN | 65000000 | Released | Still Yelling. まだ戦っている。 Still Ready for… | Grumpier Old Men | False | 92.0 |
3行×24列
最も基本的に考えられる指標の1つはそれぞれの評価に基づいて上位250作品を決めるランキングであろう。
しかし、指標として評価を使用するには、いくつかの注意点があります:
-
ひとつは、映画の人気度を考慮に入れていないことです。 したがって、10 人の投票者から 9 の評価を得た映画は、10,000 人の投票者から 8.9 の評価を得た映画よりも「良い」とみなされます。
たとえば、中華料理を注文したいとします。あるレストランは 5 人から 5 つ星の評価を得ていますが、別のレストランは 1000 人から 4.5 の評価を得ています。 あなたならどちらのレストランを選びますか? もちろん、最初のレストランは数日前にオープンしたばかりなので、投票した人は少なく、逆に2番目のレストランは1年前から営業しているという例外もありえます。 投票者の数が増えるにつれて、映画の評価は規則的になり、映画の品質を反映する値に向かって近づき、ユーザーがどの映画を選択すべきかについて、より良いアイデアを与えます。 投票者が極端に少ない映画の品質を見極めるのは困難ですが、結論づけるには外部ソースを考慮する必要があるかもしれません。
これらの欠点を考慮し、平均評価と累積投票数を考慮した加重評価を考え出す必要があります。 そのようなシステムは、10 万人の投票者から 9 の評価を得た映画が、同じ評価であってもわずか数百人の投票者の映画よりも (はるかに) 高いスコアを得るようにします。
IMDB のトップ 250 のクローンを構築しようとしているので、メトリック/スコアとしてその加重評価式を使用することにしましょう。 数学的には以下のように表されます。
\begin{equation}text Weighted Rating (\bf WR) = \left({{\bf v} \over {}bf v} + {}bf m}} \cdot Rutable) + \left({{\bf m} \over {}bf v} + {}bf m} \cdot C##right)\end{equation}
上の式において、。
-
v は映画の投票数である。
-
mはチャートに表示されるために必要な最低投票数、
-
Rは映画の平均評価、
-
Cはレポート全体の平均投票数です。
すでにデータセットの各映画のv (vote_count)とR (vote_average)の値を持っています。 このデータから直接Cを計算することも可能です。
mの適切な値を決めるのは、mに正しい値がないので、適宜選択するハイパーパラメータと言えます。 投票数がある閾値mより小さい映画を単純に除去する予備的なネガティブフィルタと考えることができます。
このチュートリアルでは、カットオフ m を 90 パーセンタイルとして使用します。 言い換えれば、映画がチャートで紹介されるためには、リスト上の映画の少なくとも90%より多くの票を獲得する必要があります。 (一方、75パーセンタイルを選択した場合は、獲得した票数の上位25%の映画を考慮することになります。
最初のステップとして、pandas .mean()関数を使用して、すべての映画の平均評価であるCの値を計算してみましょう:
# Calculate mean of vote average columnC = metadata.mean()print(C)5.618207215133889上記の出力から、IMDB上の映画の平均評価は約5であることが観察されます。
次に、90 パーセンタイルの映画が受け取った投票数 m を計算してみましょう。
# Calculate the minimum number of votes required to be in the chart, mm = metadata.quantile(0.90)print(m)160.0m があるので、単純に greater than equal to 条件を使って、160 以上の投票数を持つ映画を除外することができます。
# Filter out all qualified movies into a new DataFrameq_movies = metadata.copy().loc >= m]q_movies.shape(4555, 24)metadata.shape(45466, 24)上記の出力から、投票数が160以上で、このリストに載せるのにふさわしい映画が約10%あることがわかります。 これを行うには、次のようになります。
- 関数
weighted_rating()を定義します。 - すでに
mとCを計算しているので、単にそれらを関数への引数として渡します。 - それから
q_moviesデータフレームからvote_count(v) とvote_average(R) 列を選択し、 - 最後に加重平均値を算出して、結果を返します。
新しい特徴量 score を定義し、この関数を修飾された映画のDataFrameに適用して値を計算します。
# Function that computes the weighted rating of each moviedef weighted_rating(x, m=m, C=C): v = x R = x # Calculation based on the IMDB formula return (v/(v+m) * R) + (m/(m+v) * C)# Define a new feature 'score' and calculate its value with `weighted_rating()`q_movies = q_movies.apply(weighted_rating, axis=1)最後に、score 特徴量列に基づいて DataFrame を降順でソートし、上位20映画のタイトル、投票数、投票平均、重み付け評価(得点)を出力しましょう。
#Sort movies based on score calculated aboveq_movies = q_movies.sort_values('score', ascending=False)#Print the top 15 moviesq_movies].head(20)| title | vote_count | vote_average | スコア | |||||
|---|---|---|---|---|---|---|---|---|
| 314 | The Shawshank Redemption | 8358.B> | The Shawshank Redemption | 8358.0 | 8.5 | 8.445869 | ||
| 834 | The Godfather | 6024.0 | 8.5 | 8.425439 | ||||
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.8.421453 | ||||
| 12481 | The Dark Knight | 12269.0 | 8.3 | 8.265477 | ||||
| 2843 | Fight Club | 9678.0 | 8.3 | 8.256385 | ||||
| 292 | Pulp Fiction | 8670.1 | 8.0 | 8.3 | 8.251406 | |||
| 522 | シンドラーズ・リスト | 4436.0 | 8.0 | 8.3 | 8.206639 | |||
| 23673 | Whiplash | 4376.0 | 8.3 | 8.206639 | 8.206639 | 8.206639 | 8.206639 | 9.205404 |
| 5481 | Spirited Away | 3968.0 | 8.3 | 8.8.196055 | ||||
| 2211 | Life Is Beautiful | 3643.0 | 8.3 | 8.187171 | ||||
| 1178 | The Godfather: Part II | 3418.0 | 8.3 | |||||
| 1152 | One Flew Over the Cuckoo’s Nest | 3001.0 | 8.3 | |||||
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.8.150272 | ||||
| 1154 | 帝国の逆襲 | 5998.0 | 8.8.2 | 8.132919 | ||||
| 1176 | Psycho | 2405.0 | 8.8.3 | 8.132715 | ||||
| 1846591 | The Intouchables | 5410.0 | 8.2 | 8.125837 | ||||
| 40251 | 「君の名は。 The Professional | 4293.0 | 8.2 | |||||
| 3030 | The Green Mile | 4166.0 | 8.2 | 8.104511 | ||||
| 1170 | GoodFellas | 3211.0 | 8.2 |
以上の出力からsimple recommenderが素晴らしい仕事をしたことが分かりますね!!!。
このチャートは IMDB トップ 250 チャートと多くの映画が共通しているので:たとえば、あなたの上位 2 作品、「ショーシャンクの空に」と「ゴッドファーザー」は IMDB と同じで、それらが確かにすばらしい映画であることを私たちは知っていますが、実際、すべての上位 20 作品はそのリストに値するのではないでしょうか。
Content-Based Recommender
Plot Description Based Recommender
このセクションでは、特定の映画に似ている映画を推薦するシステムを構築する方法を学習します。 これを実現するために、プロットの説明に基づいてすべての映画のペアワイズcosine類似性スコアを計算し、その類似性スコア閾値に基づいて映画を推薦します。
プロットの説明は、metadataデータセットのoverview特徴として利用可能です。
#Print plot overviews of the first 5 movies.metadata.head()0 Led by Woody, Andy's toys live happily in his ...1 When siblings Judy and Peter discover an encha...2 A family wedding reignites the ancient feud be...3 Cheated on, mistreated and stepped on, the wom...4 Just when George Banks has recovered from his ...Name: overview, dtype: object手元の問題は自然言語処理の問題です。 したがって、テキストデータ間の類似度や非類似度を計算する前に、上記のテキストデータからある種の特徴を抽出する必要がある。 簡単に言うと、2つのoverviewsの間の類似度をそのままの形で計算することは不可能である。
その名が示すように、ワードベクトルは文書中の単語をベクトル化したものである。 このベクトルには意味的な意味が含まれている。 例えば、男&王は互いに近いベクトル表現を持ち、男&女は互いに遠い表現を持つ。
各文書についてTerm Frequency-Inverse Document Frequency(TF-IDF)ベクトルを計算することになる。 これは、各列が概要語彙(少なくとも1つの文書に現れるすべての単語)の単語を表し、各列が映画を表す行列を与えます。
その本質において、TF-IDFスコアは、それが現れる文書の数によって重み付けされた、文書内に現れる単語の頻度です。 これは、プロット概要に頻繁に出現する単語の重要度を下げ、したがって最終的な類似度スコアを計算する際の重要度を下げるために行われる。
幸いにも、scikit-learn は、2 行で TF-IDF 行列を生成する組み込み TfIdfVectorizer クラスを提供します。
- Import the Tfidf module using scikit-learn;
- Remove stop words like ‘the’, ‘an’, etc….
- Not-a-number valuesを空白文字列に置き換える。
- 最後に、データに対してTF-IDF行列を構築する。
#Import TfIdfVectorizer from scikit-learnfrom sklearn.feature_extraction.text import TfidfVectorizer#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'tfidf = TfidfVectorizer(stop_words='english')#Replace NaN with an empty stringmetadata = metadata.fillna('')#Construct the required TF-IDF matrix by fitting and transforming the datatfidf_matrix = tfidf.fit_transform(metadata)#Output the shape of tfidf_matrixtfidf_matrix.shape(45466, 75827)#Array mapping from feature integer indices to feature name.tfidf.get_feature_names()上記の出力から、データセットの75,827の異なる語彙または単語は45,000の映画を持つことがわかります。 これにはマンハッタン、ユークリッド、ピアソン、コサイン類似度など、いくつかの類似度メトリックを使用できます。 繰り返しますが、どのスコアが一番良いかという正解はありません。
2 つの映画の間の類似性を示す数値を計算するために cosine similarity を使用することになります。 大きさに依存せず、比較的簡単かつ高速に計算できるため、余弦類似度スコアを使用します (特に、後で説明する TF-IDF スコアと組み合わせて使用する場合)。 数学的には次のように定義されます:
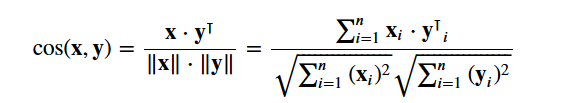
TF-IDFベクタライザーを使用したので、各ベクトル間の内積を計算すると、直接余弦類似度スコアが得られます。
これは45466×45466の行列を返すので、各映画overviewは他の映画overviewとのコサイン類似度スコアを意味します。
# Import linear_kernelfrom sklearn.metrics.pairwise import linear_kernel# Compute the cosine similarity matrixcosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)cosine_sim.shape(45466, 45466)cosine_simarray()映画のタイトルを入力とし、最も似ている映画10本のリストを出力する関数を定義するつもりです。 まず、このためには、映画のタイトルとDataFrameのインデックスの逆マッピングが必要です。
#Construct a reverse map of indices and movie titlesindices = pd.Series(metadata.index, index=metadata).drop_duplicates()indicestitleToy Story 0Jumanji 1Grumpier Old Men 2Waiting to Exhale 3Father of the Bride Part II 4Heat 5Sabrina 6Tom and Huck 7Sudden Death 8GoldenEye 9dtype: int64これで、レコメンデーション関数を定義する準備が整いました。
-
タイトルを指定して映画のインデックスを取得します。
-
その特定の映画とすべての映画の余弦類似度スコアのリストを取得します。 最初の要素がその位置、2番目の要素が類似度スコアであるタプルのリストに変換する。
-
類似度スコアに基づいてタプルの前述のリストをソートする。つまり、2番目の要素。
-
このリストの上位10要素を取得する。 最初の要素は self を参照しているので無視します(特定の映画に最も似ている映画は映画そのものです)。
-
トップ要素のインデックスに対応するタイトルを返します。
# Function that takes in movie title as input and outputs most similar moviesdef get_recommendations(title, cosine_sim=cosine_sim): # Get the index of the movie that matches the title idx = indices # Get the pairwsie similarity scores of all movies with that movie sim_scores = list(enumerate(cosine_sim)) # Sort the movies based on the similarity scores sim_scores = sorted(sim_scores, key=lambda x: x, reverse=True) # Get the scores of the 10 most similar movies sim_scores = sim_scores # Get the movie indices movie_indices = for i in sim_scores] # Return the top 10 most similar movies return metadata.ilocget_recommendations('The Dark Knight Rises')12481 The Dark Knight150 Batman Forever1328 Batman Returns15511 Batman: Under the Red Hood585 Batman21194 Batman Unmasked: The Psychology of the Dark Kn...9230 Batman Beyond: Return of the Joker18035 Batman: Year One19792 Batman: The Dark Knight Returns, Part 13095 Batman: Mask of the PhantasmName: title, dtype: objectget_recommendations('The Godfather')1178 The Godfather: Part II44030 The Godfather Trilogy: 1972-19901914 The Godfather: Part III23126 Blood Ties11297 Household Saints34717 Start Liquidation10821 Election38030 A Mother Should Be Loved17729 Short Sharp Shock26293 Beck 28 - FamiljenName: title, dtype: objectあなたのシステムは類似したプロットの説明を持つ映画を見つけるのにふさわしい仕事をしてきましたが、勧告の質がそれほど高くないことがわかっています。 “The Dark Knight Rises” はすべてのバットマン映画を返しますが、その映画が好きな人は、他のクリストファー・ノーラン映画を楽しむ傾向がある可能性が高くなります。
クレジット、ジャンル、およびキーワードに基づくレコメンダー
レコメンダーの品質は、より良いメタデータを使用し、より詳細な情報を取得することで向上します。 これはまさにこのセクションでやろうとしていることです。
キーワード、キャスト、スタッフのデータは現在のデータセットでは利用できないので、最初のステップはそれらをロードしてメインのDataFrame metadataにマージすることでしょう。
# Load keywords and creditscredits = pd.read_csv('credits.csv')keywords = pd.read_csv('keywords.csv')# Remove rows with bad IDs.metadata = metadata.drop()# Convert IDs to int. Required for mergingkeywords = keywords.astype('int')credits = credits.astype('int')metadata = metadata.astype('int')# Merge keywords and credits into your main metadata dataframemetadata = metadata.merge(credits, on='id')metadata = metadata.merge(keywords, on='id')# Print the first two movies of your newly merged metadatametadata.head(2)| adult | belongs_to_collection | budget | genres | ホームページ | id | imdb_id | オリジナル言語 | オリジナルタイトル | 概要 | …続きを読む.. | spoken_languages | status | tagline | title | video | vote_average | vote_count | cast | crew | keywords | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | NaN | Toy Story | False | 7.7 | 5415.0 | for feature in features: metadata = metadata.False。apply(literal_eval)
次に、各特徴から必要な情報を抽出するための関数を書きます。 最初に、NumPyパッケージをインポートして、その クルーフィーチャーから監督の名前を取得する。 監督が一覧にない場合は 次に、上位3つの要素とリスト全体のどちらか多い方を返す関数を書きます。 ここで、リストとは、
次のステップは、名前とキーワードのインスタンスを小文字に変換し、それらの間のスペースをすべて取り除くことである。 単語間のスペースを取り除くことは、重要な前処理ステップです。 これは、ベクタライザーが “Johnny Depp” と “Johnny Galecki” の Johnny を同じものとしてカウントしないようにするために行われます。 この処理ステップの後、前述の俳優は “johnnydepp” と “johnnygalecki” として表され、ベクトル化器では区別されます。 モデルが同じベクトル表現を出力するもう 1 つの良い例は、「パン詰まり」と「交通渋滞」です。 これで「メタデータスープ」を作成できるようになりました。これは、ベクタライザーに供給したいすべてのメタデータ (俳優、監督、キーワード) を含む文字列です。 これは最後の前処理で、この関数の出力が単語ベクトルモデルに供給されます。
| soup |
0 |
jealousy toy boy tomhanks timallen donrickles … …. 1 |
ボードゲーム消失 basedonchildren’s book …
次のステップは、 上記の出力から、あなたが与えたメタデータには73,881個のボキャブラリがあることがわかります。 次に、 これで、新しい 素晴らしい! レコメンダーはより多くのメタデータによってより多くの情報を取得することに成功し、より良いレコメンデーションを与えるようになったことがわかりますね。 もちろん、レコメンデーションを改善するために、このシステムで実験する方法は数多くあります。
Collaborative Filtering with PythonThe tutorial で、非常に独自のシンプルかつコンテンツ ベースの映画推薦システムの構築方法を学びました。 Collaborative Filter はさらに 2 つのタイプに分類されます:
A an example of collaborative filtering based on a rating system:
 このチュートリアルでは、これらのシステムを構築しませんが、構築するために必要なアイデアのほとんどはすでに知っていることでしょう。 協調フィルタから始めるには、MovieLens データセットを調べるのがよいでしょう。 ConclusionCongratulations on finishing this tutorial! あなたは Python で推奨システムのすべてを学ぶチュートリアルを無事終了しました。 皆さんにとって良い練習は、シンプルでコンテンツベースのレコメンダーを構築するために使用したMovieLensデータセットのサブセットを使用して、Pythonで協調フィルタリングを実装することでしょう。 |