Lo scopo di questo tutorial non è quello di farti diventare un esperto nella costruzione di modelli di recommender system. Invece, lo scopo è quello di farti iniziare dandoti una panoramica dei tipi di sistemi di raccomandazione che esistono e come puoi costruirne uno da te
In questo tutorial, imparerai come costruire un modello base di sistemi di raccomandazione semplici e basati sul contenuto. Mentre questi modelli non saranno affatto vicini allo standard industriale in termini di complessità, qualità o accuratezza, ti aiuteranno ad iniziare a costruire modelli più complessi che producono risultati ancora migliori.
I sistemi di raccomandazione sono tra le applicazioni più popolari della scienza dei dati oggi. Sono utilizzati per prevedere il “rating” o la “preferenza” che un utente darebbe a un articolo. Quasi ogni grande azienda tecnologica li ha applicati in qualche forma. Amazon li usa per suggerire prodotti ai clienti, YouTube li usa per decidere quale video riprodurre dopo in autoplay, e Facebook li usa per consigliare le pagine che piacciono e le persone da seguire.
Inoltre, per alcune aziende come Netflix, Amazon Prime, Hulu, e Hotstar, il modello di business e il suo successo ruota intorno alla potenza delle loro raccomandazioni. Netflix ha persino offerto un milione di dollari nel 2009 a chiunque potesse migliorare il suo sistema del 10%.
Ci sono anche sistemi di raccomandazione popolari per domini come ristoranti, film e incontri online. I sistemi di raccomandazione sono stati sviluppati anche per esplorare articoli di ricerca ed esperti, collaboratori e servizi finanziari. YouTube utilizza il sistema di raccomandazione su larga scala per suggerirti video basati sulla tua storia. Per esempio, se guardi molti video educativi, ti suggerirebbe quei tipi di video.
Ma cosa sono questi sistemi di raccomandazione?
In generale, i sistemi di raccomandazione possono essere classificati in 3 tipi:
- Raccomandatori semplici: offrono raccomandazioni generalizzate a ogni utente, basate sulla popolarità dei film e/o sul genere. L’idea di base di questo sistema è che i film che sono più popolari e acclamati dalla critica avranno una maggiore probabilità di piacere al pubblico medio. Un esempio potrebbe essere IMDB Top 250.
- Consigliatori basati sul contenuto: suggeriscono articoli simili basati su un particolare articolo. Questo sistema usa i metadati dell’elemento, come il genere, il regista, la descrizione, gli attori, ecc. per i film, per fare queste raccomandazioni. L’idea generale dietro questi sistemi di raccomandazione è che se ad una persona piace un particolare elemento, gli piacerà anche un elemento che è simile ad esso. E per raccomandare ciò, farà uso dei metadati degli articoli passati dell’utente. Un buon esempio potrebbe essere YouTube, dove in base alla tua cronologia, ti suggerisce nuovi video che potresti potenzialmente guardare.
- Motori di filtraggio collaborativo: questi sistemi sono ampiamente utilizzati, e cercano di prevedere la valutazione o la preferenza che un utente darebbe a un elemento in base alle valutazioni e preferenze passate di altri utenti. I filtri collaborativi non richiedono metadati come le loro controparti basate sul contenuto.
Raccomandanti semplici
Come descritto nella sezione precedente, i raccomandatori semplici sono sistemi di base che raccomandano gli elementi migliori sulla base di una certa metrica o punteggio. In questa sezione, costruirete un clone semplificato di IMDB Top 250 Movies usando i metadati raccolti da IMDB.
I seguenti sono i passi coinvolti:
-
Decidere la metrica o il punteggio per valutare i film.
-
Calcolare il punteggio per ogni film.
-
Ordinare i film in base al punteggio e produrre i risultati migliori.
Sul dataset
I file del dataset contengono metadati per tutti i 45.000 film elencati nel Full MovieLens Dataset. Il dataset è composto da film usciti a luglio 2017 o prima. Questo dataset cattura punti caratteristici come cast, equipaggio, parole chiave della trama, budget, entrate, poster, date di uscita, lingue, società di produzione, paesi, conteggi dei voti TMDB e medie dei voti.
Questi punti caratteristici potrebbero essere potenzialmente utilizzati per addestrare i modelli di apprendimento automatico per il contenuto e il filtraggio collaborativo.
Questo set di dati è costituito dai seguenti file:
- movies_metadata.csv: Questo file contiene informazioni su ~ 45.000 film presenti nel dataset Full MovieLens. Le caratteristiche includono poster, sfondi, budget, genere, entrate, date di uscita, lingue, paesi di produzione e compagnie.
- keywords.csv: Contiene le parole chiave della trama dei nostri film MovieLens. Disponibile sotto forma di un oggetto JSON stringato.
- credits.csv: Consiste in informazioni sul cast e sulla troupe di tutti i film. Disponibile sotto forma di un oggetto JSON stringato.
- links.csv: Questo file contiene gli ID TMDB e IMDB di tutti i film presenti nel dataset Full MovieLens.
- links_small.csv: Contiene gli ID TMDB e IMDB di un piccolo sottoinsieme di 9.000 film del Full Dataset.
- ratings_small.csv: Il sottoinsieme di 100.000 valutazioni da 700 utenti su 9.000 film.
Il Full MovieLens Dataset comprende 26 milioni di valutazioni e 750.000 applicazioni tag, da 270.000 utenti su tutti i 45.000 film in questo dataset. È possibile accedervi dal sito ufficiale di GroupLens.
Nota: Il sottoinsieme di dati usato nel tutorial di oggi può essere scaricato da qui.
Per caricare il vostro dataset, dovreste usare la libreria pandas DataFrame. La libreria pandas è usata principalmente per la manipolazione e l’analisi dei dati. Rappresenta i tuoi dati in un formato riga-colonna. La libreria Pandas è supportata dall’array NumPy per l’implementazione degli oggetti dati Pandas. pandas offre strutture dati e operazioni per la manipolazione di tabelle numeriche, serie temporali, immagini e set di dati per l’elaborazione del linguaggio naturale. Fondamentalmente, pandas è utile per quei set di dati che possono essere facilmente rappresentati in modo tabellare.
Prima di eseguire uno qualsiasi dei passi di cui sopra, carichiamo il dataset di metadati dei film in un pandas DataFrame:
# Import Pandasimport pandas as pd# Load Movies Metadatametadata = pd.read_csv('movies_metadata.csv', low_memory=False)# Print the first three rowsmetadata.head(3)| adulto | appartiene alla collezione | budget | generi | homepage | id | imdb_id | lingua_originale | titolo_originale | panoramica | sopravvivenza | … | release_date | revenue | runtime | spoken_languages | status | tagline | titolo | video | vote_media | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Falso | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | Falso | 7.7 | 5415.0 | |||||||||||||
| 1 | Falso | NaN | 65000000 | Rilasciato | Ancora grida. Ancora in lotta. Still Ready for… | Grumpier Old Men | Falso | 6.5 | 92.0 |
3 righe × 24 colonne
Una delle metriche più basilari a cui si possa pensare è la classifica per decidere quali sono i primi 250 film in base alle rispettive valutazioni.
Tuttavia, usare un rating come metrica ha alcuni caveat:
-
Per prima cosa, non prende in considerazione la popolarità di un film. Pertanto, un film con una valutazione di 9 da 10 votanti sarà considerato ‘migliore’ di un film con una valutazione di 8,9 da 10.000 votanti.
Per esempio, immaginate di voler ordinare cibo cinese, avete un paio di opzioni, un ristorante ha una valutazione di 5 stelle solo da 5 persone mentre l’altro ristorante ha 4,5 valutazioni da 1000 persone. Quale ristorante preferiresti? Il secondo, giusto?
Ovviamente, ci potrebbe essere un’eccezione che il primo ristorante ha aperto solo pochi giorni fa; quindi, meno persone hanno votato per esso mentre, al contrario, il secondo ristorante è operativo da un anno.
- In una nota correlata, questa metrica tenderà anche a favorire i film con un numero minore di votanti con valutazioni distorte e/o estremamente elevate. Man mano che il numero di votanti aumenta, la valutazione di un film si regolarizza e si avvicina a un valore che riflette la qualità del film e dà all’utente un’idea molto migliore di quale film dovrebbe scegliere. Mentre è difficile discernere la qualità di un film con pochissimi votanti, potresti dover considerare fonti esterne per concludere.
Prendendo in considerazione queste carenze, è necessario elaborare una valutazione ponderata che tenga conto del voto medio e del numero di voti che ha accumulato. Un tale sistema farà in modo che un film con un voto di 9 da 100.000 votanti ottenga un punteggio (molto) più alto di un film con lo stesso voto ma con poche centinaia di votanti.
Siccome si sta cercando di costruire un clone della Top 250 di IMDB, usiamo la sua formula di valutazione ponderata come metrica/ punteggio. Matematicamente, è rappresentata come segue:
Segin{equazione} \testo Voto Ponderato (\bf WR) = \left({{\bf v} \over {\bf v} + {\bf m}} \cdot R\right) + \left({\bf m} \over {\bf v} + {\bf m} \cdot C\right)\end{equazione}
Nell’equazione di sopra,
-
v è il numero di voti del film;
-
m è il voto minimo richiesto per essere elencati nella classifica;
-
R è il voto medio del film;
-
C è il voto medio dell’intera relazione.
Hai già i valori di v (vote_count) e R (vote_average) per ogni film nel dataset. È anche possibile calcolare direttamente C da questi dati.
Determinare un valore appropriato per m è un iperparametro che puoi scegliere di conseguenza, poiché non esiste un valore giusto per m. Potete considerarlo come un filtro negativo preliminare che rimuoverà semplicemente i film che hanno un numero di voti inferiore a una certa soglia m. La selettività del vostro filtro è a vostra discrezione.
In questo tutorial, userete il cutoff m come il 90° percentile. In altre parole, perché un film sia presente nella classifica, deve avere più voti di almeno il 90% dei film della lista. (D’altra parte, se aveste scelto il 75° percentile, avreste considerato il primo 25% dei film in termini di numero di voti raccolti. Come percentile diminuisce, il numero di film considerati aumenterà).
Come primo passo, calcoliamo il valore di C, la valutazione media di tutti i film utilizzando la funzione pandas .mean():
# Calculate mean of vote average columnC = metadata.mean()print(C)5.618207215133889Dall’output di cui sopra, si può osservare che la valutazione media di un film su IMDB è circa 5.6 su una scala di 10.
In seguito, calcoliamo il numero di voti, m, ricevuti da un film nel 90° percentile. La libreria pandas rende questo compito estremamente banale usando il metodo .quantile() di pandas:
# Calculate the minimum number of votes required to be in the chart, mm = metadata.quantile(0.90)print(m)160.0Siccome ora avete il m potete semplicemente usare una condizione maggiore di uguale a per filtrare i film con un numero di voti maggiore di uguale a 160:
Potete usare il metodo .copy() per assicurarvi che il nuovo DataFrame q_movies creato sia indipendente dal vostro DataFrame di metadati originale. In altre parole, qualsiasi modifica apportata al DataFrame q_movies non influenzerà il DataFrame di metadati originale.
# Filter out all qualified movies into a new DataFrameq_movies = metadata.copy().loc >= m]q_movies.shape(4555, 24)metadata.shape(45466, 24)Dall’output di cui sopra, è chiaro che ci sono circa il 10% di film con un numero di voti superiore a 160 e si qualificano per essere in questa lista.
Il prossimo e più importante passo è quello di calcolare il voto ponderato per ogni film qualificato. Per fare questo, è necessario:
- Definire una funzione,
weighted_rating(); - Siccome avete già calcolato
meCli passerete semplicemente come argomento alla funzione; - Poi selezionerete la colonna
vote_count(v) evote_average(R) dalq_moviesdata frame; - Finalmente, calcolerete la media pesata e restituirete il risultato.
Definirete una nuova caratteristica score, di cui calcolerete il valore applicando questa funzione al vostro DataFrame di film qualificati:
# Function that computes the weighted rating of each moviedef weighted_rating(x, m=m, C=C): v = x R = x # Calculation based on the IMDB formula return (v/(v+m) * R) + (m/(m+v) * C)# Define a new feature 'score' and calculate its value with `weighted_rating()`q_movies = q_movies.apply(weighted_rating, axis=1)Finalmente, ordiniamo il DataFrame in ordine decrescente in base alla colonna della caratteristica score e restituiamo il titolo, il numero di voti, la media dei voti e la valutazione ponderata (punteggio) dei primi 20 film.
#Sort movies based on score calculated aboveq_movies = q_movies.sort_values('score', ascending=False)#Print the top 15 moviesq_movies].head(20)| titolo | conteggio_voti | media_voti | score | |
|---|---|---|---|---|
| 314 | Le ali della libertà | 8358.0 | 8.5 | 8.445869 |
| 834 | Il Padrino | 6024.0 | 8.5 | 8.425439 |
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.421453 |
| 12481 | The Dark Knight | 12269.0 | 8.3 | 8.265477 |
| 2843 | Fight Club | 9678.0 | 8.3 | 8.256385 |
| 292 | Pulp Fiction | 8670.0 | 8.3 | 8.251406 |
| 522 | Schindler’s List | 4436.0 | 8.3 | 8.206639 |
| 23673 | Whiplash | 4376.0 | 8.3 | 8.205404 |
| 5481 | Spirited Away | 3968.0 | 8.3 | 8.196055 |
| 2211 | La vita è bella | 3643.0 | 8.3 | 8.187171 |
| 1178 | Il padrino: Parte II | 3418.0 | 8.3 | 8.180076 |
| 1152 | One Flew Over the Cuckoo’s Nest | 3001.0 | 8.3 | 8.164256 |
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.150272 |
| 1154 | L’impero colpisce ancora | 5998.0 | 8.2 | 8.132919 |
| 1176 | Psycho | 2405.0 | 8.3 | 8.132715 |
| 18465 | Gli Intoccabili | 5410.0 | 8.2 | 8.125837 |
| 40251 | Your Name. | 1030.0 | 8.5 | 8.112532 |
| 289 | Leon: The Professional | 4293.0 | 8.2 | 8.107234 |
| 30 | The Green Mile | 4166.0 | 8.2 | 8.104511 |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
Bene, dal risultato di cui sopra, puoi vedere che il simple recommender ha fatto un ottimo lavoro!
Siccome la classifica ha molti film in comune con la classifica IMDB Top 250: per esempio, i tuoi due film principali, “Le ali della libertà” e “Il padrino”, sono gli stessi di IMDB e sappiamo tutti che sono davvero film straordinari, infatti, tutti i film top 20 meritano di essere in quella lista, no?
Raccomandante basato sul contenuto
Raccomandante basato sulla descrizione della trama
In questa sezione del tutorial, imparerai come costruire un sistema che raccomanda i film che sono simili a un particolare film. Per raggiungere questo obiettivo, calcolerai i punteggi di somiglianza a coppie cosine per tutti i film basati sulle loro descrizioni della trama e raccomanderai i film in base alla soglia del punteggio di somiglianza.
La descrizione della trama è disponibile come overview caratteristica nel tuo metadata dataset. Ispezioniamo le trame di alcuni film:
#Print plot overviews of the first 5 movies.metadata.head()0 Led by Woody, Andy's toys live happily in his ...1 When siblings Judy and Peter discover an encha...2 A family wedding reignites the ancient feud be...3 Cheated on, mistreated and stepped on, the wom...4 Just when George Banks has recovered from his ...Name: overview, dtype: objectIl problema in questione è un problema di Natural Language Processing. Quindi è necessario estrarre qualche tipo di caratteristiche dai dati di testo di cui sopra prima di poter calcolare la somiglianza e/o la dissimilarità tra loro. Per dirla semplicemente, non è possibile calcolare la somiglianza tra due panorami nella loro forma grezza. Per fare questo, è necessario calcolare i vettori di parole di ogni panoramica o documento, come sarà chiamato d’ora in poi.
Come suggerisce il nome, i vettori di parole sono rappresentazioni vettoriali di parole in un documento. I vettori portano con sé un significato semantico. Per esempio, uomo & re avrà rappresentazioni vettoriali vicine tra loro mentre uomo & donna avrà rappresentazioni lontane tra loro.
Computerete Term Frequency-Inverse Document Frequency (TF-IDF) vettori per ogni documento. Questo vi darà una matrice dove ogni colonna rappresenta una parola nel vocabolario generale (tutte le parole che appaiono in almeno un documento), e ogni colonna rappresenta un film, come prima.
Nella sua essenza, il punteggio TF-IDF è la frequenza di una parola che si verifica in un documento, ponderata dal numero di documenti in cui si verifica. Questo viene fatto per ridurre l’importanza delle parole che ricorrono frequentemente nelle panoramiche della trama e, quindi, la loro importanza nel calcolo del punteggio di somiglianza finale.
Fortunatamente, scikit-learn fornisce una classe TfIdfVectorizerintegrata che produce la matrice TF-IDF in un paio di righe.
- Importa il modulo Tfidf usando scikit-learn;
- Rimuovi le parole di stop come ‘the’, ‘an’, ecc. poiché non danno alcuna informazione utile sull’argomento;
- Sostituire i valori non numerici con una stringa vuota;
- Infine, costruire la matrice TF-IDF sui dati.
#Import TfIdfVectorizer from scikit-learnfrom sklearn.feature_extraction.text import TfidfVectorizer#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'tfidf = TfidfVectorizer(stop_words='english')#Replace NaN with an empty stringmetadata = metadata.fillna('')#Construct the required TF-IDF matrix by fitting and transforming the datatfidf_matrix = tfidf.fit_transform(metadata)#Output the shape of tfidf_matrixtfidf_matrix.shape(45466, 75827)#Array mapping from feature integer indices to feature name.tfidf.get_feature_names()Dall’output di cui sopra, si osserva che 75.827 diversi vocabolari o parole nel vostro set di dati hanno 45.000 film.
Con questa matrice in mano, potete ora calcolare un punteggio di similarità. Ci sono diverse metriche di somiglianza che potete usare per questo, come i punteggi di somiglianza manhattan, euclidea, Pearson e coseno. Di nuovo, non c’è una risposta giusta a quale punteggio sia il migliore. Punteggi diversi funzionano bene in scenari diversi, ed è spesso una buona idea sperimentare con diverse metriche e osservare i risultati.
Utilizzerai il cosine similarity per calcolare una quantità numerica che denota la somiglianza tra due film. Si usa il punteggio di somiglianza del coseno perché è indipendente dalla grandezza ed è relativamente facile e veloce da calcolare (specialmente se usato insieme ai punteggi TF-IDF, che saranno spiegati più avanti). Matematicamente, è definito come segue:
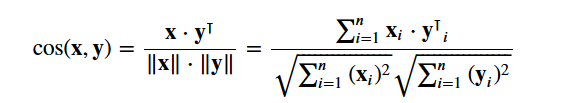
Siccome hai usato il vettorizzatore TF-IDF, calcolando il prodotto di punto tra ogni vettore ti darà direttamente il punteggio di similarità del coseno. Pertanto, userete sklearn's linear_kernel() invece di cosine_similarities() poiché è più veloce.
Questo restituirebbe una matrice di forma 45466×45466, il che significa che ogni film overview ha un punteggio di similarità al coseno con ogni altro film overview. Quindi, ogni film sarà un vettore di colonne 1×45466 dove ogni colonna sarà un punteggio di somiglianza con ogni film.
# Import linear_kernelfrom sklearn.metrics.pairwise import linear_kernel# Compute the cosine similarity matrixcosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)cosine_sim.shape(45466, 45466)cosine_simarray()Si sta per definire una funzione che prende un titolo di film come input e produce una lista dei 10 film più simili. In primo luogo, per questo, avete bisogno di una mappatura inversa dei titoli dei film e degli indici DataFrame. In altre parole, hai bisogno di un meccanismo per identificare l’indice di un film nel tuo metadata DataFrame, dato il suo titolo.
#Construct a reverse map of indices and movie titlesindices = pd.Series(metadata.index, index=metadata).drop_duplicates()indicestitleToy Story 0Jumanji 1Grumpier Old Men 2Waiting to Exhale 3Father of the Bride Part II 4Heat 5Sabrina 6Tom and Huck 7Sudden Death 8GoldenEye 9dtype: int64Ora sei in forma per definire la tua funzione di raccomandazione. Questi sono i seguenti passi da seguire:
-
Prendi l’indice del film dato il suo titolo.
-
Prendi la lista dei punteggi di similarità del coseno per quel particolare film con tutti i film. Convertirlo in una lista di tuple dove il primo elemento è la sua posizione, e il secondo è il punteggio di somiglianza.
-
Ordina la suddetta lista di tuple in base ai punteggi di somiglianza; cioè il secondo elemento.
-
Ottieni i primi 10 elementi di questa lista. Ignorate il primo elemento in quanto si riferisce a se stesso (il film più simile a un particolare film è il film stesso).
-
Ritorna i titoli corrispondenti agli indici dei primi elementi.
# Function that takes in movie title as input and outputs most similar moviesdef get_recommendations(title, cosine_sim=cosine_sim): # Get the index of the movie that matches the title idx = indices # Get the pairwsie similarity scores of all movies with that movie sim_scores = list(enumerate(cosine_sim)) # Sort the movies based on the similarity scores sim_scores = sorted(sim_scores, key=lambda x: x, reverse=True) # Get the scores of the 10 most similar movies sim_scores = sim_scores # Get the movie indices movie_indices = for i in sim_scores] # Return the top 10 most similar movies return metadata.ilocget_recommendations('The Dark Knight Rises')12481 The Dark Knight150 Batman Forever1328 Batman Returns15511 Batman: Under the Red Hood585 Batman21194 Batman Unmasked: The Psychology of the Dark Kn...9230 Batman Beyond: Return of the Joker18035 Batman: Year One19792 Batman: The Dark Knight Returns, Part 13095 Batman: Mask of the PhantasmName: title, dtype: objectget_recommendations('The Godfather')1178 The Godfather: Part II44030 The Godfather Trilogy: 1972-19901914 The Godfather: Part III23126 Blood Ties11297 Household Saints34717 Start Liquidation10821 Election38030 A Mother Should Be Loved17729 Short Sharp Shock26293 Beck 28 - FamiljenName: title, dtype: objectVedete che, mentre il vostro sistema ha fatto un lavoro decente nel trovare film con descrizioni di trama simili, la qualità delle raccomandazioni non è così grande. “The Dark Knight Rises” restituisce tutti i film di Batman mentre è più probabile che le persone a cui è piaciuto quel film siano più inclini ad apprezzare altri film di Christopher Nolan. Questo è qualcosa che non può essere catturato dal vostro sistema attuale.
Credits, Genres, and Keywords Based Recommender
La qualità del vostro recommender sarebbe aumentata con l’uso di metadati migliori e catturando più dettagli. Questo è esattamente ciò che farai in questa sezione. Costruirai un sistema di raccomandazione basato sui seguenti metadati: i 3 attori principali, il regista, i generi correlati e le parole chiave della trama del film.
Le parole chiave, il cast e la troupe non sono disponibili nel tuo attuale dataset, quindi il primo passo sarebbe quello di caricarli e unirli nel tuo DataFrame principale metadata.
# Load keywords and creditscredits = pd.read_csv('credits.csv')keywords = pd.read_csv('keywords.csv')# Remove rows with bad IDs.metadata = metadata.drop()# Convert IDs to int. Required for mergingkeywords = keywords.astype('int')credits = credits.astype('int')metadata = metadata.astype('int')# Merge keywords and credits into your main metadata dataframemetadata = metadata.merge(credits, on='id')metadata = metadata.merge(keywords, on='id')# Print the first two movies of your newly merged metadatametadata.head(2)| adulto | appartiene alla collezione | budget | generi | homepage | id | imdb_id | lingua_originale | titolo_originale | panoramica | sopravvivenza | … | lingue_parlate | status | tagline | titolo | video | voto_medio | vote_count | cast | crew | keywords | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Falso | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | Falso | 7.7 | 5415.0 | for feature in features: metadata = metadata.apply(literal_eval)
Poi, scrivete le funzioni che vi aiuteranno ad estrarre le informazioni richieste da ogni caratteristica. Prima di tutto, importerete il pacchetto NumPy per avere accesso alla sua Prendi il nome del regista dalla funzione crew. Se il regista non è elencato, restituisci Poi scriverai una funzione che restituirà i primi 3 elementi o l’intera lista, se è di più. Qui la lista si riferisce a
Il prossimo passo sarebbe quello di convertire i nomi e le istanze delle parole chiave in minuscolo e togliere tutti gli spazi tra loro. Rimuovere gli spazi tra le parole è un importante passo di pre-elaborazione. Viene fatto in modo che il vettorizzatore non conti i Johnny di “Johnny Depp” e “Johnny Galecki” come la stessa cosa. Dopo questo passo di elaborazione, i suddetti attori saranno rappresentati come “johnnydepp” e “johnnygalecki” e saranno distinti dal vostro vettorizzatore. Un altro buon esempio in cui il modello potrebbe produrre la stessa rappresentazione vettoriale è “marmellata di pane” e “ingorgo”. Quindi, è meglio eliminare qualsiasi spazio presente. La funzione seguente lo farà esattamente per te: Sei ora in grado di creare la tua “zuppa di metadati”, che è una stringa che contiene tutti i metadati che vuoi fornire al tuo vettorizzatore (cioè attori, regista e parole chiave). La funzione
| soup |
0 |
jealousy toy boy tomhanks timallen donrickles … 1 |
scomparsa del gioco da tavolo basato sul libro dei bambini …
I prossimi passi sono gli stessi che hai fatto con il tuo La differenza principale tra Dall’output di cui sopra, si può vedere che ci sono 73.881 vocabolari nei metadati che hai inserito. Prossimo, userai il Puoi ora riutilizzare la tua funzione Grande! Vedete che il vostro recommender ha avuto successo nel catturare più informazioni grazie a più metadati e vi ha dato migliori raccomandazioni. Ci sono, naturalmente, numerosi modi di sperimentare questo sistema per migliorare le raccomandazioni. Alcuni suggerimenti:
Filtraggio collaborativo con PythonIn questo tutorial, hai imparato come costruire i tuoi sistemi di raccomandazione di film semplici e basati sul contenuto. C’è anche un altro tipo estremamente popolare di recommender conosciuto come filtri collaborativi. I filtri collaborativi possono essere ulteriormente classificati in due tipi:
Un esempio di filtraggio collaborativo basato su un sistema di valutazione:
 Non costruirete questi sistemi in questo tutorial, ma avete già familiarità con la maggior parte delle idee necessarie per farlo. Un buon punto di partenza per i filtri collaborativi è l’esame del dataset MovieLens, che può essere trovato qui. ConclusioneCongratulazioni per aver finito questo tutorial! Hai superato con successo il nostro tutorial che ti ha insegnato tutto sui recommender systems in Python. Hai imparato a costruire raccomandatori semplici e basati sul contenuto. Un buon esercizio per tutti voi sarebbe quello di implementare il filtraggio collaborativo in Python usando il sottoinsieme di dati MovieLens che hai usato per costruire raccomandatori semplici e basati sul contenuto. Se hai appena iniziato con Python e vuoi saperne di più, segui il corso di DataCamp “Introduzione alla scienza dei dati in Python”. |