Az oktatóanyag célja nem az, hogy szakértővé tegye Önt az ajánlórendszer-modellek építésében. Ehelyett az az indítéka, hogy elindítsa Önt azáltal, hogy áttekintést ad a létező ajánlórendszerek típusairól, és arról, hogyan építhet egyet saját maga
Ebben az oktatóanyagban megtanulja, hogyan építsen egy egyszerű és tartalomalapú ajánlórendszer alapmodelljét. Bár ezek a modellek összetettség, minőség vagy pontosság tekintetében meg sem közelítik az iparági szabványt, segíteni fog abban, hogy elkezdhesse a még jobb eredményeket produkáló, összetettebb modellek építését.
Az ajánlórendszerek ma az adattudomány legnépszerűbb alkalmazásai közé tartoznak. Arra használják őket, hogy megjósolják azt az “értékelést” vagy “preferenciát”, amelyet egy felhasználó adna egy elemnek. Szinte minden nagyobb technológiai vállalat alkalmazza őket valamilyen formában. Az Amazon arra használja, hogy termékeket javasoljon a vásárlóknak, a YouTube arra, hogy eldöntse, melyik videót játssza le legközelebb automatikus lejátszással, a Facebook pedig arra, hogy oldalakat ajánljon, amelyeket lájkolni és embereket követni lehet.
Mi több, néhány vállalat, például a Netflix, az Amazon Prime, a Hulu és a Hotstar esetében az üzleti modell és annak sikere az ajánlások hatékonysága körül forog. A Netflix 2009-ben még egymillió dollárt is felajánlott annak, aki 10%-kal javítja a rendszerét.
Az olyan területeken is vannak népszerű ajánlórendszerek, mint az éttermek, a filmek és az online társkeresés. Ajánlórendszereket fejlesztettek ki kutatási cikkek és szakértők, munkatársak és pénzügyi szolgáltatások felkutatására is. A YouTube nagymértékben használja az ajánlórendszert, hogy az előzmények alapján videókat javasoljon Önnek. Ha például sok oktatóvideót nézel, akkor ilyen típusú videókat javasolna.
De mik is ezek az ajánlórendszerek?
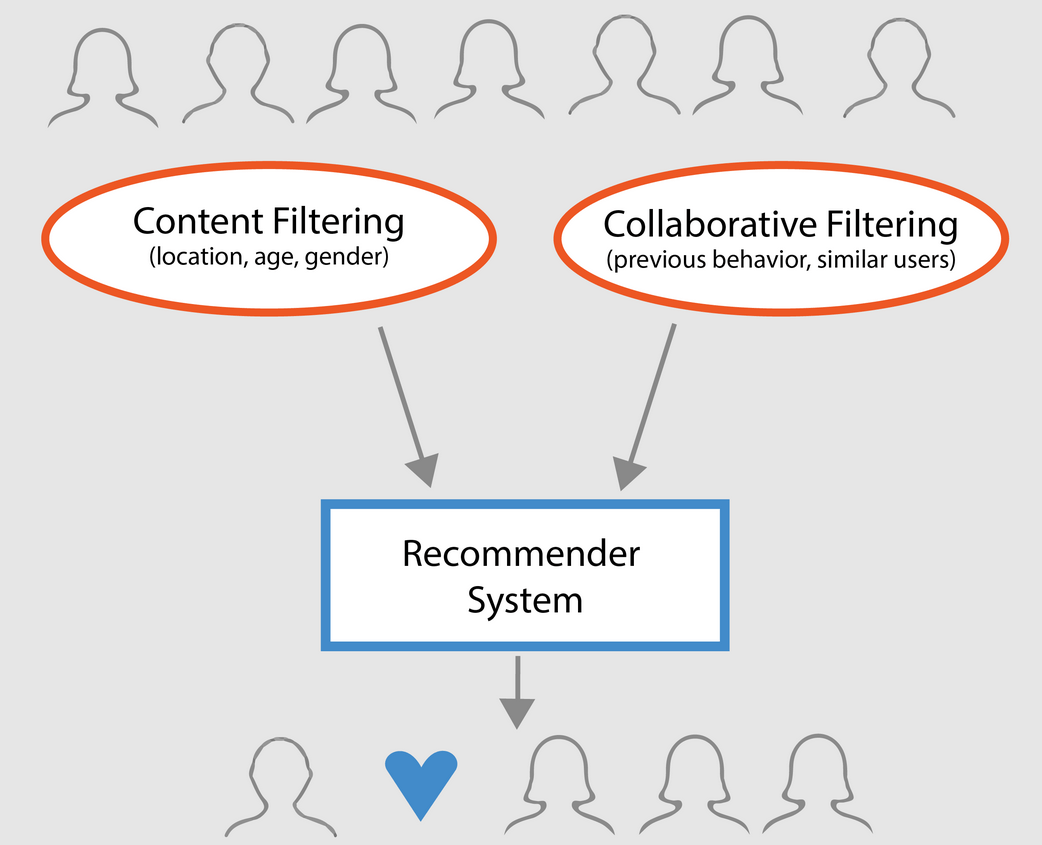
Tágabb értelemben az ajánlórendszerek 3 típusba sorolhatók:
- Egyszerű ajánlók: általánosított ajánlásokat kínálnak minden felhasználónak, a filmek népszerűsége és/vagy műfaja alapján. A rendszer alapgondolata az, hogy a népszerűbb és kritikusok által elismert filmek nagyobb valószínűséggel fognak tetszeni az átlagos közönségnek. Erre példa lehet az IMDB Top 250.
- Tartalomalapú ajánlók: hasonló elemeket javasolnak egy adott elem alapján. Ez a rendszer a tétel metaadatait, például a filmek esetében a műfajt, a rendezőt, a leírást, a színészeket stb. használja az ajánlásokhoz. Ezen ajánlórendszerek általános alapgondolata az, hogy ha egy személynek tetszik egy adott elem, akkor egy hozzá hasonló elemet is szeretni fog. És ahhoz, hogy ezt ajánlja, a rendszer felhasználja a felhasználó korábbi elemeinek metaadatait. Jó példa lehet erre a YouTube, ahol az előzmények alapján új videókat javasol, amelyeket potenciálisan megnézhetne.
- Együttműködő szűrőmotorok: Ezek a rendszerek széles körben elterjedtek, és más felhasználók korábbi értékelései és preferenciái alapján próbálják megjósolni, hogy egy felhasználó milyen értékelést vagy preferenciát adna egy elemnek. A kollaboratív szűrők nem igényelnek elem-metaadatokat, mint tartalomalapú társaik.
Egyszerű ajánlók
Az előző szakaszban leírtak szerint az egyszerű ajánlók olyan alaprendszerek, amelyek egy bizonyos metrika vagy pontszám alapján ajánlják a legjobb elemeket. Ebben a szakaszban az IMDB Top 250 Filmek egyszerűsített klónját készítjük el az IMDB-ből gyűjtött metaadatok felhasználásával.
Az alábbi lépések a következők:
-
Döntsük el, hogy milyen metrika vagy pontszám alapján értékeljük a filmeket.
-
Kalkulálja ki a pontszámot minden filmhez.
-
Rendezze a filmeket a pontszám alapján, és adja ki a legjobb eredményeket.
Az adatállományról
Az adatállományfájlok a Full MovieLens Dataset-ban felsorolt mind a 45 000 film metaadatait tartalmazzák. Az adatállomány a 2017 júliusában vagy azt megelőzően megjelent filmekből áll. Ez az adatkészlet olyan jellemző pontokat rögzít, mint a szereplők, a stáb, a cselekmény kulcsszavai, a költségvetés, a bevétel, a plakátok, a megjelenési dátumok, a nyelvek, a gyártó cégek, az országok, a TMDB szavazatszámok és a szavazatok átlaga.
Ezek a jellemzőpontok potenciálisan felhasználhatók a tartalom és a kollaboratív szűrés gépi tanulási modelljeinek képzésére.
Ez az adatállomány a következő fájlokból áll:
- movies_metadata.csv: Ez a fájl a Full MovieLens adatállományban szereplő ~45 000 filmre vonatkozó információkat tartalmazza. A jellemzők között szerepelnek plakátok, hátterek, költségvetés, műfaj, bevétel, megjelenési dátum, nyelvek, gyártó országok és cégek.
- keywords.csv: Tartalmazza a MovieLens filmjeink filmtervének kulcsszavait. Egy karakterláncba rendezett JSON objektum formájában érhető el.
- credits.csv: Az összes filmhez tartozó szereplőgárda- és stábinformációkból áll. Egy stringifikált JSON objektum formájában érhető el.
- links.csv: Ez a fájl a Full MovieLens adatkészletben szereplő összes film TMDB és IMDB azonosítóját tartalmazza.
- links_small.csv: A teljes adatállomány 9000 filmjének egy kis részhalmazának TMDB és IMDB azonosítóit tartalmazza.
- ratings_small.csv: 700 felhasználó 100 000 értékelésének részhalmaza 9000 filmről.
A teljes MovieLens-adatállomány 26 millió értékelést és 750 000 címkealkalmazást tartalmaz, 270 000 felhasználótól, az ebben az adatállományban szereplő összes 45 000 filmről. Hozzáférhető a GroupLens hivatalos weboldaláról.
Megjegyzés: A mai bemutatóban használt részhalmaz-adatkészlet letölthető innen.
Az adatkészlet betöltéséhez a pandas DataFrame könyvtárat használná. A pandas könyvtárat elsősorban az adatok manipulálására és elemzésére használják. Az adatokat sor-oszlop formátumban ábrázolja. A Pandas könyvtár mögött a NumPy tömb áll a pandas adatobjektumok megvalósításához. A pandas kész adatstruktúrákat és műveleteket kínál numerikus táblázatok, idősorok, képi és természetes nyelvi feldolgozási adathalmazok manipulálásához. Alapvetően a pandas azokhoz az adathalmazokhoz hasznos, amelyek könnyen ábrázolhatók táblázatos formában.
Mielőtt a fenti lépések bármelyikét elvégeznénk, töltsük be a filmek metaadat-adatkészletét egy pandas DataFrame-be:
# Import Pandasimport pandas as pd# Load Movies Metadatametadata = pd.read_csv('movies_metadata.csv', low_memory=False)# Print the first three rowsmetadata.head(3)| felnőtt | belongs_to_collection | budget | genres | homepage | id | imdb_id | original_language | original_title | overview | … | release_date | revenue | runtime | spoken_languages | status | tagline | title | video | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | ||||||||||||
| 1 | False | NaN | 65000000 | Released | Still Yelling. Still Fighting. Still Ready for… | Grumpier Old Men | False | 6.5 | 92.0 |
3 sor × 24 oszlop
Az egyik legalapvetőbb mérőszám, amire gondolhatunk, az a rangsor, amely eldönti, hogy melyik a top 250 film az adott értékelés alapján.
A minősítésnek mint mérőszámnak azonban van néhány fenntartása:
-
Egyrészt nem veszi figyelembe a film népszerűségét. Ezért egy 10 szavazótól 9-es értékelést kapott filmet “jobbnak” tekintünk, mint egy 10 000 szavazótól 8,9-es értékelést kapott filmet.
Elképzeljük például, hogy kínai ételt szeretnénk rendelni, van néhány lehetőségünk, az egyik étterem csak 5 embertől kapott 5 csillagos értékelést, míg a másik étterem 1000 embertől kapott 4,5-ös értékelést. Melyik éttermet választanád inkább? A másodikat, igaz?
Az persze lehet kivétel, hogy az első étterem csak néhány napja nyílt meg; ezért kevesebb ember szavazott rá, míg ezzel szemben a második étterem már egy éve működik.
- Azzal a megjegyzéssel kapcsolatban, hogy ez a mérőszám is hajlamos lesz előnyben részesíteni a kisebb számú szavazóval rendelkező, ferde és/vagy rendkívül magas értékelésű filmeket. A szavazók számának növekedésével a film minősítése rendeződik és közelít egy olyan érték felé, amely tükrözi a film minőségét, és sokkal jobb képet ad a felhasználónak arról, hogy melyik filmet válassza. Míg egy rendkívül kevés szavazóval rendelkező film minőségét nehéz megítélni, a következtetéshez esetleg külső forrásokat kell figyelembe vennie.
Az említett hiányosságokat figyelembe véve olyan súlyozott értékelést kell kialakítania, amely figyelembe veszi az átlagos értékelést és az összegyűjtött szavazatok számát. Egy ilyen rendszer biztosítja, hogy egy 100 000 szavazótól 9-es értékelést kapott film (jóval) magasabb pontszámot kapjon, mint egy ugyanilyen értékelést kapott, de csak néhány száz szavazótól származó film.
Mivel az IMDB Top 250 klónját próbálod létrehozni, használjuk annak súlyozott értékelési képletét mérőszámként/pontszámként. Matematikailag ez a következőképpen ábrázolható:
\begin{equation}\text Weighted Rating (\bf WR) = \left({{\bf v} \over {\bf v} + {\bf m}} \cdot R\right) + \left({{\bf m} \over {\bf v} + {\bf m}} \cdot C\right)\end{equation}
A fenti egyenletben,
-
v a filmre leadott szavazatok száma;
-
m a táblázatban való szerepléshez szükséges minimális szavazatszám;
-
R a film átlagos értékelése;
-
C a teljes jelentésben szereplő szavazatok átlaga.
Az adathalmazban lévő minden egyes filmhez már megvan a v (vote_count) és R (vote_average) érték. Ezekből az adatokból közvetlenül is ki lehet számítani a C-t.
A m megfelelő értékének meghatározása egy hiperparaméter, amelyet ennek megfelelően választhat, mivel a m-nek nincs megfelelő értéke. Tekinthetjük úgy is, mint egy előzetes negatív szűrőt, amely egyszerűen eltávolítja azokat a filmeket, amelyeknek a szavazatszáma kevesebb, mint egy bizonyos m küszöbérték. A szűrő szelektivitása a saját belátásodra van bízva.
Ebben a bemutatóban a m határértéket fogod használni, mint a 90. percentilt. Más szóval, ahhoz, hogy egy film szerepeljen a grafikonokon, több szavazatot kell kapnia, mint a listán szereplő filmek legalább 90%-ának. (Másrészt, ha a 75. percentilt választotta volna, akkor az összegyűjtött szavazatok száma alapján a filmek legjobb 25%-át vette volna figyelembe. Ahogy csökken a percentilis, úgy nő a figyelembe vett filmek száma).
Első lépésként számítsuk ki a pandas .mean() függvény segítségével a C értékét, az összes film átlagos értékelését:
# Calculate mean of vote average columnC = metadata.mean()print(C)5.618207215133889A fenti kimenetből megfigyelhetjük, hogy egy film átlagos értékelése az IMDB-n 5 körül van.6 a 10-es skálán.
A következőkben számoljuk ki, hogy egy film hány szavazatot, m-t, kapott a 90. percentilisben. A pandas könyvtár rendkívül triviálissá teszi ezt a feladatot a pandas .quantile() metódusának segítségével:
# Calculate the minimum number of votes required to be in the chart, mm = metadata.quantile(0.90)print(m)160.0Mivel már megvan a m, egyszerűen használhatunk egy nagyobb, mint egyenlő feltételt a 160-nál nagyobb szavazatszámú filmek kiszűrésére:
A .copy() metódus segítségével biztosíthatjuk, hogy a létrehozott új q_movies DataFrame független legyen az eredeti metaadat DataFrame-től. Más szóval, a q_movies DataFrame-ben végzett bármilyen változtatás nem befolyásolja az eredeti metaadat adatkeretet.
# Filter out all qualified movies into a new DataFrameq_movies = metadata.copy().loc >= m]q_movies.shape(4555, 24)metadata.shape(45466, 24)A fenti kimenetből egyértelműen kiderül, hogy körülbelül 10% olyan film van, amelynek szavazatszáma meghaladja a 160-at, és felkerülhet a listára.
A következő és legfontosabb lépés az egyes minősített filmek súlyozott értékelésének kiszámítása. Ehhez a következőket kell tennie:
- Meghatároz egy függvényt, a
weighted_rating(); - Mivel már kiszámította a
mésCértékeket, egyszerűen átadja őket argumentumként a függvénynek; - Ezután kiválasztja a
vote_count(v) ésvote_average(R) oszlopot aq_moviesadatkeretből; - Végül kiszámítja a súlyozott átlagot és visszaadja az eredményt.
Meghatározunk egy új score jellemzőt, amelynek értékét úgy számítjuk ki, hogy ezt a függvényt alkalmazzuk a minősített filmeket tartalmazó DataFrame-ünkre:
# Function that computes the weighted rating of each moviedef weighted_rating(x, m=m, C=C): v = x R = x # Calculation based on the IMDB formula return (v/(v+m) * R) + (m/(m+v) * C)# Define a new feature 'score' and calculate its value with `weighted_rating()`q_movies = q_movies.apply(weighted_rating, axis=1)Végül rendezzük az DataFrame-et csökkenő sorrendbe a score jellemző oszlop alapján, és adjuk ki a 20 legjobb film címét, szavazatszámát, szavazatátlagát és súlyozott értékelését (pontszámát).
#Sort movies based on score calculated aboveq_movies = q_movies.sort_values('score', ascending=False)#Print the top 15 moviesq_movies].head(20)| title | vote_count | vote_avage_average | eredmény | |
|---|---|---|---|---|
| 314 | The Shawshank Redemption | 8358.0 | 8.5 | 8.445869 |
| 834 | A Keresztapa | 6024.0 | 8.5 | 8.425439 |
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.421453 |
| 12481 | A sötét lovag | 12269.0 | 8.3 | 8.265477 |
| 2843 | Fight Club | 9678.0 | 8.3 | 8.256385 |
| 292 | Pulp Fiction | 8670.0 | 8.3 | 8.251406 |
| 522 | Schindler listája | 4436.0 | 8.3 | 8.206639 |
| 23673 | Whiplash | 4376.0 | 8.3 | 8.205404 |
| 5481 | Spirited Away | 3968.0 | 8.3 | 8.196055 |
| 2211 | Az élet szép | 3643.0 | 8.3 | 8.187171 |
| 1178 | A Keresztapa: II. rész | 3418.0 | 8.3 | 8.180076 |
| 1152 | One flew Over the Cuckoo’s Nest | 3001.0 | 8.3 | 8.164256 |
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.150272 |
| 1154 | A Birodalom visszavág | 5998.0 | 8.2 | 8.132919 |
| 1176 | Pszicho | 2405.0 | 8.3 | 8.132715 |
| 18465 | Az érinthetetlenek | 5410.0 | 8.2 | 8.125837 |
| 40251 | A neved. | 1030.0 | 8.5 | 8.112532 |
| 289 | Leon: The Professional | 4293.0 | 8.2 | 8.107234 |
| 303030 | The Green Mile | 4166.0 | 8.2 | 8.104511 |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
Nos, a fenti kimenetből látható, hogy a simple recommender remek munkát végzett!
Mivel a táblázat sok közös filmet tartalmaz az IMDB Top 250-es táblázatával: például a két legjobb filmed, a “Shawshank Redemption” és a “Keresztapa”, megegyezik az IMDB-vel, és mindannyian tudjuk, hogy ezek valóban csodálatos filmek, valójában az összes top 20 film megérdemli, hogy szerepeljen ezen a listán, nem igaz?
Content-Based Recommender
Plot Description Based Recommender
A bemutató ezen részében megtanulja, hogyan készíthet egy olyan rendszert, amely olyan filmeket ajánl, amelyek hasonlóak egy adott filmhez. Ennek érdekében páronkénti cosine hasonlósági pontszámokat fogsz kiszámítani az összes filmhez a cselekményleírásuk alapján, és a hasonlósági ponthatár alapján fogsz filmeket ajánlani.
A cselekményleírás overview jellemzőként áll rendelkezésedre a metadata adatállományodban. Vizsgáljuk meg néhány film cselekményét:
#Print plot overviews of the first 5 movies.metadata.head()0 Led by Woody, Andy's toys live happily in his ...1 When siblings Judy and Peter discover an encha...2 A family wedding reignites the ancient feud be...3 Cheated on, mistreated and stepped on, the wom...4 Just when George Banks has recovered from his ...Name: overview, dtype: objectA szóban forgó probléma egy természetes nyelvfeldolgozási probléma. Ezért a fenti szöveges adatokból ki kell vonnunk valamilyen jellemzőt, mielőtt kiszámíthatnánk a hasonlóságot és/vagy a különbözőséget közöttük. Egyszerűen fogalmazva, nyers formában nem lehet kiszámítani a hasonlóságot két áttekintés között. Ehhez ki kell számítani az egyes áttekintések vagy dokumentumok szóvektorait, ahogy a továbbiakban nevezni fogjuk.
Amint a neve is mutatja, a szóvektorok a dokumentumban található szavak vektorizált reprezentációi. A vektorok szemantikai jelentést hordoznak magukban. Például a férfi & király egymáshoz közeli vektoros reprezentációkkal fog rendelkezni, míg a férfi & nő egymástól távoli reprezentációkkal.
Az egyes dokumentumokhoz Term Frequency-Inverse Document Frequency (TF-IDF) vektorokat fogunk kiszámítani. Ez egy olyan mátrixot ad, amelyben minden oszlop egy-egy szót képvisel az áttekintő szókincsben (az összes olyan szót, amely legalább egy dokumentumban előfordul), és minden oszlop egy filmet képvisel, ahogy korábban is.
A lényegét tekintve a TF-IDF pontszám a dokumentumban előforduló szó gyakorisága, lefelé súlyozva azon dokumentumok számával, amelyekben előfordul. Ez azért történik, hogy csökkentsük a cselekmény áttekintésében gyakran előforduló szavak fontosságát, és ezáltal jelentőségüket a végső hasonlósági pontszám kiszámításában.
Szerencsére a scikit-learn ad egy beépített TfIdfVectorizer osztályt, amely néhány sorban előállítja a TF-IDF mátrixot.
- Importáljuk a Tfidf modult a scikit-learn segítségével;
- Távolítsuk el az olyan stop szavakat, mint ‘the’, ‘an’ stb. mivel ezek nem adnak hasznos információt a témáról;
- A nem-szám értékeket üres karakterlánccal helyettesítsük;
- Végül építsük fel a TF-IDF mátrixot az adatokra.
#Import TfIdfVectorizer from scikit-learnfrom sklearn.feature_extraction.text import TfidfVectorizer#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'tfidf = TfidfVectorizer(stop_words='english')#Replace NaN with an empty stringmetadata = metadata.fillna('')#Construct the required TF-IDF matrix by fitting and transforming the datatfidf_matrix = tfidf.fit_transform(metadata)#Output the shape of tfidf_matrixtfidf_matrix.shape(45466, 75827)#Array mapping from feature integer indices to feature name.tfidf.get_feature_names()A fenti kimenetből megfigyelheti, hogy az adatállományában 75 827 különböző szókincshez vagy szóhoz 45 000 film tartozik.
Ezzel a mátrixszal a kezében most kiszámíthatja a hasonlósági pontszámot. Ehhez több hasonlósági metrika is használható, például a manhattani, az euklideszi, a Pearson- és a koszinusz-hasonlósági pontszám. Ismétlem, nincs helyes válasz arra, hogy melyik pontszám a legjobb. A különböző pontszámok különböző forgatókönyvekben jól működnek, és gyakran jó ötlet különböző metrikákkal kísérletezni és megfigyelni az eredményeket.
Az cosine similarity segítségével egy numerikus mennyiséget fog kiszámítani, amely két film közötti hasonlóságot jelöl. A koszinusz hasonlósági pontszámot használod, mivel az független a nagyságrendtől, és viszonylag könnyen és gyorsan kiszámítható (különösen, ha a TF-IDF pontszámokkal együtt használod, amelyekről később lesz szó). Matematikailag a következőképpen definiálható:
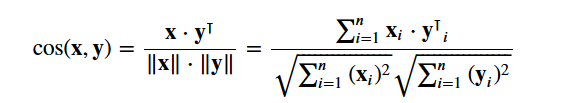
Mivel a TF-IDF vektorizálót használta, az egyes vektorok közötti pontszorzat kiszámításával közvetlenül megkapja a koszinusz hasonlósági pontszámot. Ezért a cosine_similarities() helyett a sklearn's linear_kernel() értéket fogja használni, mivel ez gyorsabb.
Ez egy 45466×45466 alakú mátrixot adna vissza, ami azt jelenti, hogy minden egyes overview film kozinusz hasonlósági pontszáma minden más overview filmmel. Ezért minden film egy 1×45466 oszlopvektor lesz, ahol minden oszlop egy-egy hasonlósági pontszám lesz minden egyes filmmel.
# Import linear_kernelfrom sklearn.metrics.pairwise import linear_kernel# Compute the cosine similarity matrixcosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)cosine_sim.shape(45466, 45466)cosine_simarray()Egy olyan függvényt fog definiálni, amely bemenetként elfogad egy filmcímet, és kiad egy listát a 10 leghasonlóbb filmről. Ehhez először is szükséged van a filmcímek és a DataFrame indexek fordított leképezésére. Más szóval, szükséged van egy olyan mechanizmusra, amellyel azonosítani tudod a metadata DataFrame-ben lévő film indexét a film címe alapján.
#Construct a reverse map of indices and movie titlesindices = pd.Series(metadata.index, index=metadata).drop_duplicates()indicestitleToy Story 0Jumanji 1Grumpier Old Men 2Waiting to Exhale 3Father of the Bride Part II 4Heat 5Sabrina 6Tom and Huck 7Sudden Death 8GoldenEye 9dtype: int64Az ajánlófüggvényed definiálásához már jó formában vagy. A következő lépéseket fogod követni:
-
Kérdezze meg a film indexét a címe alapján.
-
Kérdezze meg az adott film koszinusz hasonlósági pontszámának listáját az összes filmmel. Alakítsuk át egy olyan tuplikból álló listává, ahol az első elem a pozíciója, a második pedig a hasonlósági pontszám.
-
Rendezzük az előbb említett tuplikból álló listát a hasonlósági pontszámok alapján; azaz a második elem alapján.
-
Vegyük ki a lista első 10 elemét. Az első elemet hagyja figyelmen kívül, mivel az önmagára utal (az adott filmhez leginkább hasonló film maga a film).
-
A felső elemek indexeinek megfelelő címeket adja vissza.
# Function that takes in movie title as input and outputs most similar moviesdef get_recommendations(title, cosine_sim=cosine_sim): # Get the index of the movie that matches the title idx = indices # Get the pairwsie similarity scores of all movies with that movie sim_scores = list(enumerate(cosine_sim)) # Sort the movies based on the similarity scores sim_scores = sorted(sim_scores, key=lambda x: x, reverse=True) # Get the scores of the 10 most similar movies sim_scores = sim_scores # Get the movie indices movie_indices = for i in sim_scores] # Return the top 10 most similar movies return metadata.ilocget_recommendations('The Dark Knight Rises')12481 The Dark Knight150 Batman Forever1328 Batman Returns15511 Batman: Under the Red Hood585 Batman21194 Batman Unmasked: The Psychology of the Dark Kn...9230 Batman Beyond: Return of the Joker18035 Batman: Year One19792 Batman: The Dark Knight Returns, Part 13095 Batman: Mask of the PhantasmName: title, dtype: objectget_recommendations('The Godfather')1178 The Godfather: Part II44030 The Godfather Trilogy: 1972-19901914 The Godfather: Part III23126 Blood Ties11297 Household Saints34717 Start Liquidation10821 Election38030 A Mother Should Be Loved17729 Short Sharp Shock26293 Beck 28 - FamiljenName: title, dtype: objectLáthatja, hogy bár a rendszere tisztességes munkát végzett a hasonló cselekményleírású filmek megtalálásában, az ajánlások minősége nem olyan nagyszerű. A “The Dark Knight Rises” visszaadja az összes Batman-filmet, miközben valószínűbb, hogy azok, akiknek tetszett ez a film, inkább más Christopher Nolan-filmeket szeretnek. Ezt a jelenlegi rendszere nem tudja megragadni.
Credits, Genres, and Keywords Based Recommender
A jobb metaadatok használatával és több finomabb részlet megragadásával növelhető lenne az ajánló minősége. Ebben a részben pontosan ezt fogja megtenni. Egy ajánlórendszert fogsz létrehozni a következő metaadatok alapján: a 3 legjobb színész, a rendező, a kapcsolódó műfajok és a film cselekményének kulcsszavai.
A kulcsszavak, a szereplők és a stáb adatai nem állnak rendelkezésre a jelenlegi adatállományodban, ezért az első lépés az lenne, hogy betöltsd és egyesítsd őket a fő DataFrame metadata-ba.
# Load keywords and creditscredits = pd.read_csv('credits.csv')keywords = pd.read_csv('keywords.csv')# Remove rows with bad IDs.metadata = metadata.drop()# Convert IDs to int. Required for mergingkeywords = keywords.astype('int')credits = credits.astype('int')metadata = metadata.astype('int')# Merge keywords and credits into your main metadata dataframemetadata = metadata.merge(credits, on='id')metadata = metadata.merge(keywords, on='id')# Print the first two movies of your newly merged metadatametadata.head(2)| felnőtt | belongs_to_collection | budget | genres | homepage | id | imdb_id | original_language | original_title | overview | … | spoken_languages | status | tagline | title | video | vote_average | vote_count | cast | crew | keywords | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | for feature in features: metadata = metadata.apply(literal_eval)
A következőkben olyan függvényeket írunk, amelyek segítségével minden egyes feature-ből kinyerhetjük a szükséges információkat. Először is importáljuk a NumPy csomagot, hogy hozzáférjünk annak A rendező nevét kapod meg a stáb funkcióból. Ha a rendező nem szerepel a listában, akkor adja vissza A következőkben írjon egy olyan függvényt, amely visszaadja az első 3 elemet vagy a teljes listát, attól függően, hogy melyik a több. Itt a lista a
A következő lépés az lenne, hogy a neveket és a kulcsszópéldányokat kisbetűvé alakítjuk, és eltávolítjuk a köztük lévő szóközöket. A szavak közötti szóközök eltávolítása fontos előfeldolgozási lépés. Ez azért történik, hogy a vektorizáló ne számolja azonosnak a “Johnny Depp” és a “Johnny Galecki” Johnnyját. E feldolgozási lépés után a fent említett szereplők “johnnydepp”-ként és “johnnygalecki”-ként lesznek reprezentálva, és a vektorizálója számára különbözőek lesznek. Egy másik jó példa, ahol a modell ugyanazt a vektorreprezentációt adhatja ki, a “kenyérdugó” és a “közlekedési dugó”. Ezért jobb, ha minden jelenlévő szóközt eltávolítunk. Az alábbi függvény pontosan ezt fogja megtenni neked: Most abban a helyzetben vagy, hogy létrehozd a “metaadatlevesedet”, ami egy olyan karakterlánc, amely tartalmazza az összes metaadatot, amelyet a vektorizátorodba akarsz táplálni (nevezetesen a szereplőket, a rendezőt és a kulcsszavakat). A
| soup |
0 |
jealousy toy boy tomhanks timallen donrickles … 1 |
boardgame disappearance basedonchildren’sbook …
A következő lépések ugyanazok, mint amit a A A fenti kimenetből láthatja, hogy 73 881 szókapcsolat van a metaadatokban, amelyeket betáplált. A következőkben a Most újra felhasználhatod a Nagyszerű! Látod, hogy az ajánlóidnak sikerült több információt rögzíteniük a több metaadat miatt, és jobb ajánlásokat adtak neked. Természetesen számos lehetőség van arra, hogy kísérletezzünk ezzel a rendszerrel az ajánlások javítása érdekében. Néhány javaslat:
Collaborative Filtering with PythonEzzel a bemutatóval megtanultuk, hogyan készíthetünk saját egyszerű és tartalomalapú filmajánló rendszert. Létezik egy másik rendkívül népszerű ajánlástípus is, az úgynevezett kollaboratív szűrők. A kollaboratív szűrőket továbbá két típusba sorolhatjuk:
Egy példa az értékelési rendszeren alapuló kollaboratív szűrésre:
 Egy ilyen rendszert nem ebben a tananyagban fog építeni, de az ehhez szükséges ötletek nagy részét már ismeri. A kollaboratív szűrőkkel való ismerkedéshez jó kiindulópont lehet a MovieLens adathalmaz vizsgálata, amely itt található. KövetkeztetésGratulálunk, hogy befejezted ezt a bemutatót! Sikeresen végigjártad a bemutatót, amely mindent megtanított neked az ajánlórendszerekről Pythonban. Megtanultátok, hogyan építsetek egyszerű és tartalomalapú ajánlórendszereket. Egy jó gyakorlat lenne mindannyiótok számára, ha kollaboratív szűrést valósítanátok meg Pythonban a MovieLens adathalmaz részhalmazának felhasználásával, amelyet az egyszerű és tartalomalapú ajánlórendszerek építéséhez használtatok. Ha még csak most kezditek a Python használatát, és többet szeretnétek tanulni, vegyétek fel a DataCamp Bevezetés az adattudományba Pythonban kurzusát. |