Der Zweck dieses Tutorials ist es nicht, Sie zu einem Experten im Aufbau von Empfehlungssystemen zu machen. Vielmehr soll es Ihnen einen Überblick über die verschiedenen Arten von Empfehlungssystemen geben und Ihnen zeigen, wie Sie selbst eines erstellen können
In diesem Tutorial lernen Sie, wie Sie ein grundlegendes Modell für einfache und inhaltsbasierte Empfehlungssysteme erstellen. Auch wenn diese Modelle in Bezug auf Komplexität, Qualität und Genauigkeit nicht an den Industriestandard heranreichen, können Sie damit beginnen, komplexere Modelle zu erstellen, die noch bessere Ergebnisse liefern.
Empfehlungssysteme gehören heute zu den beliebtesten Anwendungen der Datenwissenschaft. Sie werden verwendet, um die „Bewertung“ oder „Präferenz“ vorherzusagen, die ein Benutzer für einen Artikel abgeben würde. Fast jedes große Technologieunternehmen hat sie in irgendeiner Form eingesetzt. Amazon nutzt sie, um seinen Kunden Produkte vorzuschlagen, YouTube verwendet sie, um zu entscheiden, welches Video als nächstes automatisch abgespielt wird, und Facebook nutzt sie, um zu empfehlen, welche Seiten einem gefallen und welchen Personen man folgen sollte.
Für einige Unternehmen wie Netflix, Amazon Prime, Hulu und Hotstar dreht sich das Geschäftsmodell und der Erfolg sogar um die Wirksamkeit ihrer Empfehlungen. Netflix hat 2009 sogar eine Million Dollar für denjenigen ausgelobt, der sein System um 10 % verbessern kann.
Es gibt auch beliebte Empfehlungssysteme für Bereiche wie Restaurants, Filme und Online-Dating. Empfehlungssysteme wurden auch entwickelt, um Forschungsartikel und Experten, Mitarbeiter und Finanzdienstleistungen zu finden. YouTube verwendet das Empfehlungssystem in großem Umfang, um Ihnen Videos auf der Grundlage Ihres Verlaufs vorzuschlagen. Wenn Sie sich beispielsweise viele Lehrvideos ansehen, werden Ihnen diese Art von Videos vorgeschlagen.
Aber was sind diese Empfehlungssysteme?
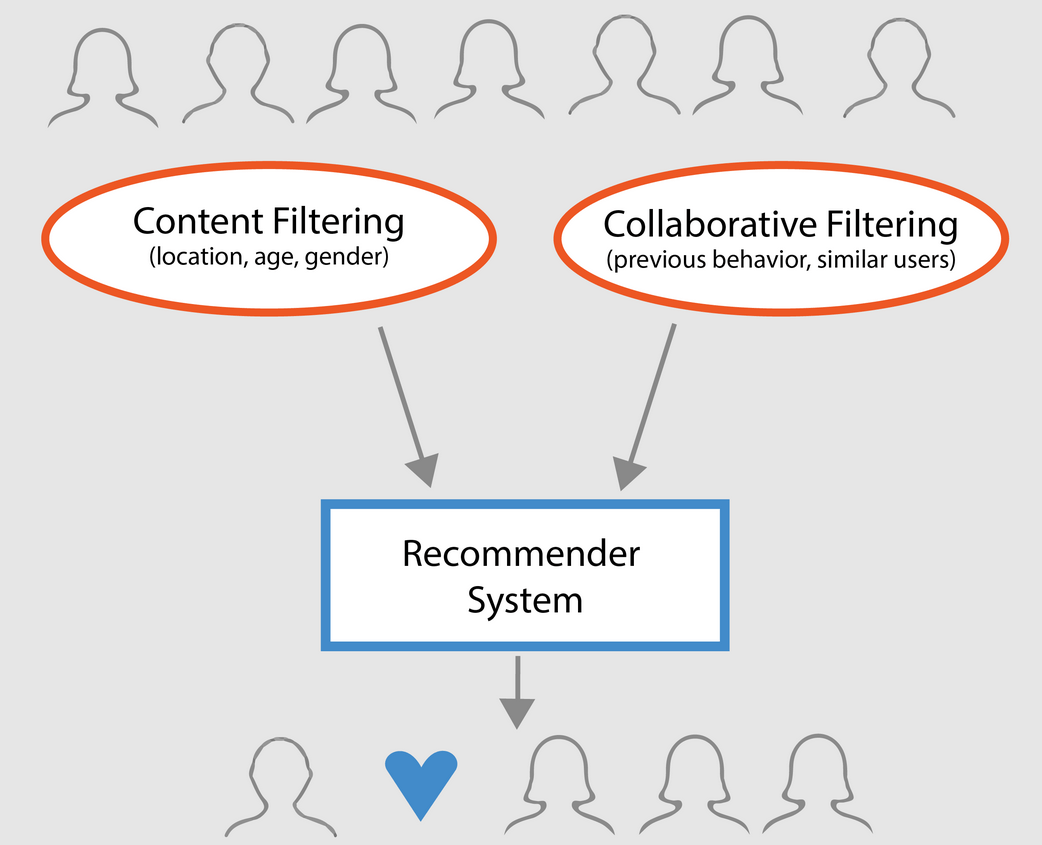
Grundsätzlich können Empfehlungssysteme in drei Typen eingeteilt werden:
- Einfache Empfehlungssysteme: Sie bieten jedem Benutzer allgemeine Empfehlungen auf der Grundlage der Popularität und/oder des Genres eines Films. Die Grundidee hinter diesem System ist, dass Filme, die beliebter sind und von der Kritik gelobt werden, eine höhere Wahrscheinlichkeit haben, vom durchschnittlichen Publikum gemocht zu werden. Ein Beispiel wäre die IMDB Top 250.
- Inhaltsbasierte Empfehlungssysteme: schlagen ähnliche Artikel auf der Grundlage eines bestimmten Artikels vor. Dieses System verwendet Metadaten zu einem Artikel, wie z. B. Genre, Regisseur, Beschreibung, Schauspieler usw. für Filme, um diese Empfehlungen auszusprechen. Die allgemeine Idee hinter diesen Empfehlungssystemen ist, dass eine Person, die einen bestimmten Artikel mag, auch einen ähnlichen Artikel mögen wird. Und um dies zu empfehlen, werden die Metadaten des Nutzers zu früheren Artikeln herangezogen. Ein gutes Beispiel ist YouTube, wo auf der Grundlage des Verlaufs neue Videos vorgeschlagen werden, die man sich möglicherweise ansehen könnte.
- Collaborative Filtering Engines: Diese Systeme sind weit verbreitet und versuchen, die Bewertung oder Präferenz, die ein Benutzer einem Artikel geben würde, auf der Grundlage früherer Bewertungen und Präferenzen anderer Benutzer vorherzusagen. Kollaborative Filter benötigen keine Metadaten zu einem Objekt wie ihre inhaltsbasierten Gegenstücke.
- Einfache Empfehlungssysteme
- Über den Datensatz
- Content-Based Recommender
- Plot Description Based Recommender
- Empfehlungssysteme auf der Grundlage von Credits, Genres und Schlüsselwörtern
- Collaborative Filterung mit Python
- Ein Beispiel für kollaboratives Filtern auf der Grundlage eines Bewertungssystems:
- Abschluss
Einfache Empfehlungssysteme
Wie im vorigen Abschnitt beschrieben, sind einfache Empfehlungssysteme grundlegende Systeme, die die besten Objekte auf der Grundlage einer bestimmten Metrik oder Punktzahl empfehlen. In diesem Abschnitt werden Sie einen vereinfachten Klon der IMDB Top 250 Movies erstellen, indem Sie Metadaten aus IMDB verwenden.
Die folgenden Schritte sind erforderlich:
-
Entscheiden Sie sich für eine Metrik oder Punktzahl, nach der Filme bewertet werden sollen.
-
Berechnen Sie die Punktzahl für jeden Film.
-
Sortieren Sie die Filme anhand der Punktzahl und geben Sie die besten Ergebnisse aus.
Über den Datensatz
Die Dateien des Datensatzes enthalten Metadaten für alle 45.000 Filme, die im Full MovieLens Dataset aufgelistet sind. Der Datensatz besteht aus Filmen, die im Juli 2017 oder früher veröffentlicht wurden. Dieser Datensatz erfasst Merkmale wie Besetzung, Crew, Plot-Schlüsselwörter, Budget, Einnahmen, Plakate, Veröffentlichungsdaten, Sprachen, Produktionsfirmen, Länder, TMDB-Stimmenzahlen und Stimmendurchschnitte.
Diese Merkmalspunkte können potenziell zum Trainieren Ihrer maschinellen Lernmodelle für Inhalte und kollaboratives Filtern verwendet werden.
Dieser Datensatz besteht aus den folgenden Dateien:
- movies_metadata.csv: Diese Datei enthält Informationen zu ~45.000 Filmen, die im vollständigen MovieLens-Datensatz enthalten sind. Zu den Merkmalen gehören Poster, Kulissen, Budget, Genre, Einnahmen, Erscheinungsdaten, Sprachen, Produktionsländer und Unternehmen.
- keywords.csv: Enthält die Schlüsselwörter für die Filmhandlung unserer MovieLens-Filme. Verfügbar in Form eines stringifizierten JSON-Objekts.
- credits.csv: Besteht aus den Informationen zu Besetzung und Crew für alle Filme. Verfügbar in Form eines stringifizierten JSON-Objekts.
- links.csv: Diese Datei enthält die TMDB- und IMDB-IDs aller Filme, die im vollständigen MovieLens-Datensatz enthalten sind.
- links_small.csv: Enthält die TMDB- und IMDB-IDs einer kleinen Teilmenge von 9.000 Filmen des vollständigen Datensatzes.
- ratings_small.csv: Die Teilmenge von 100.000 Bewertungen von 700 Nutzern zu 9.000 Filmen.
Der vollständige MovieLens-Datensatz umfasst 26 Millionen Bewertungen und 750.000 Tag-Anwendungen von 270.000 Nutzern zu allen 45.000 Filmen in diesem Datensatz. Er kann von der offiziellen GroupLens-Website heruntergeladen werden.
Hinweis: Der im heutigen Tutorial verwendete Teilsatz kann von hier heruntergeladen werden.
Um Ihren Datensatz zu laden, verwenden Sie die pandas DataFrame-Bibliothek. Die pandas-Bibliothek wird hauptsächlich für die Datenmanipulation und -analyse verwendet. Sie stellt Ihre Daten in einem Zeilen-/Spaltenformat dar. Die Pandas-Bibliothek wird durch das NumPy-Array für die Implementierung von Pandas-Datenobjekten unterstützt. pandas bietet Standard-Datenstrukturen und -Operationen für die Bearbeitung von numerischen Tabellen, Zeitreihen, Bildern und Datensätzen zur Verarbeitung natürlicher Sprache. Grundsätzlich ist pandas für solche Datensätze nützlich, die sich leicht in Tabellenform darstellen lassen.
Bevor Sie einen der oben genannten Schritte ausführen, laden wir Ihren Film-Metadatensatz in einen pandas DataFrame:
# Import Pandasimport pandas as pd# Load Movies Metadatametadata = pd.read_csv('movies_metadata.csv', low_memory=False)# Print the first three rowsmetadata.head(3)| Erwachsener | gehört_zur_Sammlung | Budget | Genres | homepage | id | imdb_id | original_language | original_title | overview | … | Veröffentlichungsdatum | Umsatz | Laufzeit | gesprochene_Sprachen | Status | Tagline | title | video | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‚id‘: 10194, ’name‘: ‚Toy Story Collection‘, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | ||||||||||||
| 1 | Falsch | NaN | 65000000 | Released | Still Yelling. Immer noch kämpfend. Still Ready for… | Grumpier Old Men | False | 6.5 | 92.0 |
3 Zeilen × 24 Spalten
Eine der grundlegendsten Metriken, die man sich vorstellen kann, ist das Ranking, um zu entscheiden, welche Filme in den Top 250 sind, basierend auf ihren jeweiligen Bewertungen.
Die Verwendung einer Bewertung als Metrik hat jedoch einige Vorbehalte:
-
Zum einen berücksichtigt sie nicht die Popularität eines Films. Daher wird ein Film mit einer Bewertung von 9 von 10 Wählern als „besser“ angesehen als ein Film mit einer Bewertung von 8,9 von 10.000 Wählern.
Stellen Sie sich zum Beispiel vor, Sie möchten chinesisches Essen bestellen und haben mehrere Möglichkeiten. Ein Restaurant hat eine 5-Sterne-Bewertung von nur 5 Personen, während das andere Restaurant 4,5 Bewertungen von 1000 Personen hat. Welches Restaurant würden Sie bevorzugen? Das zweite, richtig?
Natürlich könnte es eine Ausnahme geben, dass das erste Restaurant erst vor ein paar Tagen eröffnet wurde und daher weniger Leute dafür gestimmt haben, während das zweite Restaurant bereits seit einem Jahr in Betrieb ist.
- In diesem Zusammenhang ist zu erwähnen, dass diese Metrik auch dazu neigt, Filme mit einer geringeren Anzahl von Wählern mit verzerrten und/oder extrem hohen Bewertungen zu bevorzugen. Mit zunehmender Anzahl von Wählern wird die Bewertung eines Films gleichmäßiger und nähert sich einem Wert an, der die Qualität des Films widerspiegelt und dem Nutzer eine bessere Vorstellung davon vermittelt, welchen Film er wählen sollte. Da es schwierig ist, die Qualität eines Films mit extrem wenigen Wählern zu erkennen, müssen Sie möglicherweise externe Quellen heranziehen, um zu einem Schluss zu kommen.
Angesichts dieser Unzulänglichkeiten müssen Sie sich eine gewichtete Bewertung ausdenken, die die durchschnittliche Bewertung und die Anzahl der Stimmen berücksichtigt, die sie angesammelt hat. Ein solches System stellt sicher, dass ein Film mit einer Bewertung von 9 von 100.000 Wählern eine (weit) höhere Punktzahl erhält als ein Film mit der gleichen Bewertung, aber nur ein paar hundert Wählern.
Da Sie versuchen, einen Klon der IMDB Top 250 zu erstellen, lassen Sie uns deren gewichtete Bewertungsformel als Metrik/Score verwenden. Mathematisch lässt sie sich wie folgt darstellen:
\begin{equation}\text Weighted Rating (\bf WR) = \left({{\bf v} \over {\bf v} + {\bf m}} \cdot R\right) + \left({\bf m} \over {\bf v} + {\bf m}} \cdot C\right)\end{equation}
In der obigen Gleichung,
-
v ist die Anzahl der Stimmen für den Film;
-
m ist die Mindestanzahl der Stimmen, die erforderlich sind, um in der Tabelle aufgeführt zu werden;
-
R ist die durchschnittliche Bewertung des Films;
-
C ist die durchschnittliche Bewertung für den gesamten Bericht.
Die Werte für v (vote_count) und R (vote_average) liegen bereits für jeden Film im Datensatz vor. Es ist auch möglich, C direkt aus diesen Daten zu berechnen.
Die Bestimmung eines geeigneten Wertes für m ist ein Hyperparameter, den Sie entsprechend wählen können, da es keinen richtigen Wert für m gibt. Sie können ihn als einen vorläufigen Negativfilter betrachten, der einfach die Filme entfernt, deren Stimmenzahl unter einem bestimmten Schwellenwert m liegt. Die Selektivität Ihres Filters liegt in Ihrem Ermessen.
In diesem Tutorial werden Sie den Schwellenwert m als das 90ste Perzentil verwenden. Mit anderen Worten, damit ein Film in den Charts erscheint, muss er mehr Stimmen haben als mindestens 90 % der Filme in der Liste. (Hätten Sie dagegen das 75. Perzentil gewählt, hätten Sie die besten 25 % der Filme in Bezug auf die Anzahl der erhaltenen Stimmen berücksichtigt. Mit abnehmendem Perzentil erhöht sich die Anzahl der berücksichtigten Filme).
Berechnen wir in einem ersten Schritt den Wert von C, die durchschnittliche Bewertung aller Filme mit der Pandas-Funktion .mean():
# Calculate mean of vote average columnC = metadata.mean()print(C)5.618207215133889Aus der obigen Ausgabe können Sie ersehen, dass die durchschnittliche Bewertung eines Films auf IMDB etwa 5.6 auf einer Skala von 10.
Als Nächstes berechnen wir die Anzahl der Stimmen m, die ein Film im 90sten Perzentil erhält. Die pandas-Bibliothek macht diese Aufgabe mit der .quantile()-Methode von Pandas extrem trivial:
# Calculate the minimum number of votes required to be in the chart, mm = metadata.quantile(0.90)print(m)160.0Da Sie nun die m haben, können Sie einfach eine Bedingung „größer gleich“ verwenden, um Filme herauszufiltern, die mehr als 160 Stimmen erhalten haben:
Sie können die .copy()-Methode verwenden, um sicherzustellen, dass der neu erstellte q_movies-DataFrame unabhängig von Ihrem ursprünglichen Metadaten-DataFrame ist. Mit anderen Worten, alle Änderungen, die am q_movies DataFrame vorgenommen werden, wirken sich nicht auf den ursprünglichen Metadaten-DataFrame aus.
# Filter out all qualified movies into a new DataFrameq_movies = metadata.copy().loc >= m]q_movies.shape(4555, 24)metadata.shape(45466, 24)Aus der obigen Ausgabe geht hervor, dass es etwa 10 % Filme mit einer Stimmenzahl von mehr als 160 gibt, die sich für diese Liste qualifizieren.
Der nächste und wichtigste Schritt ist die Berechnung der gewichteten Bewertung für jeden qualifizierten Film. Um dies zu tun, werden Sie:
- Definieren Sie eine Funktion,
weighted_rating(); - Da Sie
mundCbereits berechnet haben, übergeben Sie sie einfach als Argument an die Funktion; - Dann wählen Sie die Spalten
vote_count(v) undvote_average(R) aus dem Datenrahmenq_moviesaus; - Schließlich berechnen Sie den gewichteten Durchschnitt und geben das Ergebnis zurück.
Sie definieren ein neues Merkmal score, dessen Wert Sie berechnen, indem Sie diese Funktion auf Ihren DataFrame mit qualifizierten Filmen anwenden:
# Function that computes the weighted rating of each moviedef weighted_rating(x, m=m, C=C): v = x R = x # Calculation based on the IMDB formula return (v/(v+m) * R) + (m/(m+v) * C)# Define a new feature 'score' and calculate its value with `weighted_rating()`q_movies = q_movies.apply(weighted_rating, axis=1)Schließlich sortieren wir den DataFrame in absteigender Reihenfolge auf der Grundlage der Merkmalsspalte score und geben den Titel, die Anzahl der Stimmen, den Stimmendurchschnitt und die gewichtete Bewertung (Score) der 20 besten Filme aus.
#Sort movies based on score calculated aboveq_movies = q_movies.sort_values('score', ascending=False)#Print the top 15 moviesq_movies].head(20)| Titel | Stimmenanzahl | Stimmendurchschnitt | Score | |
|---|---|---|---|---|
| 314 | The Shawshank Redemption | 8358.0 | 8.5 | 8.445869 |
| 834 | Der Pate | 6024.0 | 8.5 | 8.425439 |
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.421453 |
| 12481 | The Dark Knight | 12269.0 | 8.3 | 8.265477 |
| 2843 | Fight Club | 9678.0 | 8.3 | 8.256385 |
| 292 | Pulp Fiction | 8670.0 | 8.3 | 8.251406 |
| 522 | Schindler’s List | 4436.0 | 8.3 | 8.206639 |
| 23673 | Whiplash | 4376.0 | 8.3 | 8.205404 |
| 5481 | Spirited Away | 3968.0 | 8.3 | 8.196055 |
| 2211 | Das Leben ist schön | 3643.0 | 8.3 | 8.187171 |
| 1178 | Der Pate: Teil II | 3418.0 | 8.3 | 8.180076 |
| 1152 | One Flew Over the Cuckoo’s Nest | 3001.0 | 8.3 | 8.164256 |
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.150272 |
| 1154 | Das Imperium schlägt zurück | 5998.0 | 8.2 | 8.132919 |
| 1176 | Psycho | 2405.0 | 8.3 | 8.132715 |
| 18465 | The Intouchables | 5410.0 | 8.2 | 8.125837 |
| 40251 | Dein Name. | 1030.0 | 8.5 | 8.112532 |
| 289 | Leon: The Professional | 4293.0 | 8.2 | 8.107234 |
| 3030 | The Green Mile | 4166.0 | 8.2 | 8.104511 |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
Nun, aus der obigen Ausgabe kann man sehen, dass der simple recommender gute Arbeit geleistet hat!
Da die Tabelle viele Filme mit der IMDB-Top-250-Liste gemeinsam hat: zum Beispiel sind deine beiden Top-Filme, „Shawshank Redemption“ und „Der Pate“, die gleichen wie bei IMDB, und wir alle wissen, dass sie in der Tat erstaunliche Filme sind, in der Tat, alle Top-20-Filme verdienen es, in dieser Liste zu sein, nicht wahr?
Content-Based Recommender
Plot Description Based Recommender
In diesem Abschnitt des Tutorials lernen Sie, wie man ein System erstellt, das Filme empfiehlt, die einem bestimmten Film ähnlich sind. Um dies zu erreichen, werden Sie paarweise cosine Ähnlichkeitsbewertungen für alle Filme auf der Grundlage ihrer Handlungsbeschreibungen berechnen und Filme auf der Grundlage dieses Ähnlichkeitsschwellenwerts empfehlen.
Die Handlungsbeschreibung steht Ihnen als overview Merkmal in Ihrem metadata Datensatz zur Verfügung. Schauen wir uns die Plots einiger Filme an:
#Print plot overviews of the first 5 movies.metadata.head()0 Led by Woody, Andy's toys live happily in his ...1 When siblings Judy and Peter discover an encha...2 A family wedding reignites the ancient feud be...3 Cheated on, mistreated and stepped on, the wom...4 Just when George Banks has recovered from his ...Name: overview, dtype: objectDas vorliegende Problem ist ein Problem der natürlichen Sprachverarbeitung. Daher müssen Sie aus den oben genannten Textdaten eine Art von Merkmalen extrahieren, bevor Sie die Ähnlichkeit und/oder Unähnlichkeit zwischen ihnen berechnen können. Einfach ausgedrückt, ist es nicht möglich, die Ähnlichkeit zwischen zwei Übersichten in ihrer Rohform zu berechnen. Um dies zu tun, müssen Sie die Wortvektoren jeder Übersicht oder jedes Dokuments, wie es von nun an genannt wird, berechnen.
Wie der Name schon sagt, sind Wortvektoren eine vektorisierte Darstellung der Wörter in einem Dokument. Die Vektoren tragen eine semantische Bedeutung mit sich. Zum Beispiel hat Mann & König Vektordarstellungen, die nahe beieinander liegen, während Mann & Frau eine Darstellung hat, die weit voneinander entfernt ist.
Sie werden Term Frequency-Inverse Document Frequency (TF-IDF) Vektoren für jedes Dokument berechnen. So erhalten Sie eine Matrix, in der jede Spalte ein Wort des Übersichtsvokabulars darstellt (alle Wörter, die in mindestens einem Dokument vorkommen), und jede Spalte stellt wie zuvor einen Film dar.
Der TF-IDF-Score ist im Wesentlichen die Häufigkeit, mit der ein Wort in einem Dokument vorkommt, und wird durch die Anzahl der Dokumente, in denen es vorkommt, heruntergewichtet. Dies geschieht, um die Bedeutung von Wörtern, die häufig in Handlungsübersichten vorkommen, und damit ihre Bedeutung bei der Berechnung des endgültigen Ähnlichkeitsscores zu verringern.
Glücklicherweise bietet scikit-learn eine eingebaute TfIdfVectorizer Klasse, die die TF-IDF-Matrix in ein paar Zeilen erzeugt.
- Importieren Sie das Tfidf-Modul mit scikit-learn;
- Entfernen Sie Stoppwörter wie ‚der‘, ‚ein‘, etc. da sie keine nützlichen Informationen über das Thema liefern;
- Ersetzen Sie Nicht-eine-Zahl-Werte durch eine leere Zeichenkette;
- Erstellen Sie schließlich die TF-IDF-Matrix aus den Daten.
#Import TfIdfVectorizer from scikit-learnfrom sklearn.feature_extraction.text import TfidfVectorizer#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'tfidf = TfidfVectorizer(stop_words='english')#Replace NaN with an empty stringmetadata = metadata.fillna('')#Construct the required TF-IDF matrix by fitting and transforming the datatfidf_matrix = tfidf.fit_transform(metadata)#Output the shape of tfidf_matrixtfidf_matrix.shape(45466, 75827)#Array mapping from feature integer indices to feature name.tfidf.get_feature_names()Aus der obigen Ausgabe können Sie ersehen, dass 75.827 verschiedene Vokabulare oder Wörter in Ihrem Datensatz 45.000 Filme haben.
Mit dieser Matrix in der Hand können Sie nun einen Ähnlichkeitswert berechnen. Es gibt mehrere Ähnlichkeitsmetriken, die Sie dafür verwenden können, z. B. die Manhattan-, euklidische, Pearson und Cosinus-Ähnlichkeitsbewertung. Auch hier gibt es keine richtige Antwort auf die Frage, welcher Wert der beste ist. Verschiedene Werte sind in verschiedenen Szenarien gut geeignet, und es ist oft eine gute Idee, mit verschiedenen Metriken zu experimentieren und die Ergebnisse zu beobachten.
Sie werden die cosine similarity verwenden, um eine numerische Größe zu berechnen, die die Ähnlichkeit zwischen zwei Filmen angibt. Sie verwenden den Cosinus-Ähnlichkeitsscore, da er unabhängig von der Größe ist und sich relativ einfach und schnell berechnen lässt (vor allem, wenn er in Verbindung mit TF-IDF-Scores verwendet wird, die später erklärt werden). Mathematisch ist er wie folgt definiert:
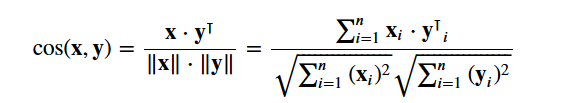
Da Sie den TF-IDF-Vektorizer verwendet haben, ergibt die Berechnung des Punktprodukts zwischen den einzelnen Vektoren direkt den Cosinus-Ähnlichkeitswert. Daher werden Sie sklearn's linear_kernel() anstelle von cosine_similarities() verwenden, da dies schneller ist.
Dies würde eine Matrix der Form 45466×45466 ergeben, was bedeutet, dass jeder Film overview einen Cosinus-Ähnlichkeitswert mit jedem anderen Film overview hat. Jeder Film wird also ein 1×45466-Spaltenvektor sein, bei dem jede Spalte eine Ähnlichkeitsbewertung mit jedem Film darstellt.
# Import linear_kernelfrom sklearn.metrics.pairwise import linear_kernel# Compute the cosine similarity matrixcosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)cosine_sim.shape(45466, 45466)cosine_simarray()Sie werden eine Funktion definieren, die einen Filmtitel als Eingabe annimmt und eine Liste der 10 ähnlichsten Filme ausgibt. Hierfür benötigen Sie zunächst eine umgekehrte Zuordnung von Filmtiteln und DataFrame-Indizes. Mit anderen Worten, Sie brauchen einen Mechanismus, um den Index eines Films in Ihrem metadata DataFrame anhand seines Titels zu identifizieren.
#Construct a reverse map of indices and movie titlesindices = pd.Series(metadata.index, index=metadata).drop_duplicates()indicestitleToy Story 0Jumanji 1Grumpier Old Men 2Waiting to Exhale 3Father of the Bride Part II 4Heat 5Sabrina 6Tom and Huck 7Sudden Death 8GoldenEye 9dtype: int64Sie sind jetzt in guter Verfassung, um Ihre Empfehlungsfunktion zu definieren. Die folgenden Schritte werden Sie ausführen:
-
Ermitteln Sie den Index des Films anhand seines Titels.
-
Ermitteln Sie die Liste der Cosinus-Ähnlichkeitswerte für diesen bestimmten Film mit allen Filmen. Konvertieren Sie sie in eine Liste von Tupeln, bei denen das erste Element die Position und das zweite die Ähnlichkeitsbewertung ist.
-
Sortieren Sie die oben genannte Liste von Tupeln auf der Grundlage der Ähnlichkeitsbewertungen, d.h. des zweiten Elements.
-
Ermitteln Sie die ersten 10 Elemente dieser Liste. Ignorieren Sie das erste Element, da es sich auf sich selbst bezieht (der Film, der einem bestimmten Film am ähnlichsten ist, ist der Film selbst).
-
Geben Sie die Titel zurück, die den Indizes der obersten Elemente entsprechen.
# Function that takes in movie title as input and outputs most similar moviesdef get_recommendations(title, cosine_sim=cosine_sim): # Get the index of the movie that matches the title idx = indices # Get the pairwsie similarity scores of all movies with that movie sim_scores = list(enumerate(cosine_sim)) # Sort the movies based on the similarity scores sim_scores = sorted(sim_scores, key=lambda x: x, reverse=True) # Get the scores of the 10 most similar movies sim_scores = sim_scores # Get the movie indices movie_indices = for i in sim_scores] # Return the top 10 most similar movies return metadata.ilocget_recommendations('The Dark Knight Rises')12481 The Dark Knight150 Batman Forever1328 Batman Returns15511 Batman: Under the Red Hood585 Batman21194 Batman Unmasked: The Psychology of the Dark Kn...9230 Batman Beyond: Return of the Joker18035 Batman: Year One19792 Batman: The Dark Knight Returns, Part 13095 Batman: Mask of the PhantasmName: title, dtype: objectget_recommendations('The Godfather')1178 The Godfather: Part II44030 The Godfather Trilogy: 1972-19901914 The Godfather: Part III23126 Blood Ties11297 Household Saints34717 Start Liquidation10821 Election38030 A Mother Should Be Loved17729 Short Sharp Shock26293 Beck 28 - FamiljenName: title, dtype: objectSie sehen, dass Ihr System zwar eine gute Arbeit beim Auffinden von Filmen mit ähnlichen Handlungsbeschreibungen geleistet hat, die Qualität der Empfehlungen aber nicht so gut ist. „The Dark Knight Rises“ liefert alle Batman-Filme, während es wahrscheinlicher ist, dass die Leute, die diesen Film mochten, eher geneigt sind, andere Christopher-Nolan-Filme zu mögen. Das ist etwas, das Ihr derzeitiges System nicht erfassen kann.
Empfehlungssysteme auf der Grundlage von Credits, Genres und Schlüsselwörtern
Die Qualität Ihres Empfehlungssystems würde sich durch die Verwendung besserer Metadaten und die Erfassung feinerer Details verbessern. Genau das werden Sie in diesem Abschnitt tun. Sie werden ein Empfehlungssystem erstellen, das auf den folgenden Metadaten basiert: die 3 Top-Schauspieler, der Regisseur, verwandte Genres und die Schlüsselwörter für die Filmhandlung.
Die Schlüsselwörter, die Besetzung und die Crew-Daten sind in Ihrem aktuellen Datensatz nicht verfügbar, so dass der erste Schritt darin besteht, sie in Ihren Haupt-DataFrame metadata zu laden und zusammenzuführen.
# Load keywords and creditscredits = pd.read_csv('credits.csv')keywords = pd.read_csv('keywords.csv')# Remove rows with bad IDs.metadata = metadata.drop()# Convert IDs to int. Required for mergingkeywords = keywords.astype('int')credits = credits.astype('int')metadata = metadata.astype('int')# Merge keywords and credits into your main metadata dataframemetadata = metadata.merge(credits, on='id')metadata = metadata.merge(keywords, on='id')# Print the first two movies of your newly merged metadatametadata.head(2)| Erwachsene | gehört zur Sammlung | Budget | Genres | homepage | id | imdb_id | original_language | original_title | overview | … | gesprochene_Sprachen | Status | Tagline | Titel | Video | Bewertungsdurchschnitt | vote_count | cast | crew | keywords | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‚id‘: 10194, ’name‘: ‚Toy Story Collection‘, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | for feature in features: metadata = metadata.apply(literal_eval)
Als Nächstes schreiben Sie Funktionen, die Ihnen helfen, die benötigten Informationen aus jedem Merkmal zu extrahieren. Zuerst importieren Sie das NumPy-Paket, um Zugriff auf seine Ermittle den Namen des Regisseurs aus dem Crew-Feature. Wenn der Regisseur nicht aufgelistet ist, gib Als Nächstes schreibst du eine Funktion, die die ersten 3 Elemente oder die gesamte Liste zurückgibt, je nachdem, was mehr ist. Hier bezieht sich die Liste auf die
Der nächste Schritt wäre, die Namen und Schlüsselwortinstanzen in Kleinbuchstaben umzuwandeln und alle Leerzeichen zwischen ihnen zu entfernen. Das Entfernen der Leerzeichen zwischen den Wörtern ist ein wichtiger Vorverarbeitungsschritt. Er wird durchgeführt, damit Ihr Vektorisierer den Johnny von „Johnny Depp“ und „Johnny Galecki“ nicht als denselben zählt. Nach diesem Verarbeitungsschritt werden die genannten Schauspieler als „johnnydepp“ und „johnnygalecki“ dargestellt und sind für Ihren Vektorisierer unterscheidbar. Ein weiteres gutes Beispiel, bei dem das Modell die gleiche Vektordarstellung ausgeben könnte, sind „Brotstau“ und „Verkehrsstau“. Daher ist es besser, alle vorhandenen Leerzeichen zu entfernen. Die folgende Funktion wird genau das für Sie tun: Sie sind nun in der Lage, Ihre „Metadatensuppe“ zu erstellen, die eine Zeichenkette ist, die alle Metadaten enthält, die Sie an Ihren Vektorisierer weitergeben möchten (nämlich Schauspieler, Regisseur und Schlüsselwörter). Die Funktion
| soup |
0 |
jealousy toy boy tomhanks timallen donrickles … 1 |
Brettspiel Verschwinden nach Kinderbuch …
Die nächsten Schritte sind die gleichen, wie du sie mit deinem Der Hauptunterschied zwischen Aus der obigen Ausgabe können Sie ersehen, dass es 73.881 Vokabulare in den Metadaten gibt, die Sie eingegeben haben. Als Nächstes verwenden Sie die Sie können nun Ihre Gut! Sie sehen, dass Ihr Empfehlungsprogramm aufgrund von mehr Metadaten mehr Informationen erfassen konnte und Ihnen bessere Empfehlungen gegeben hat. Es gibt natürlich zahlreiche Möglichkeiten, mit diesem System zu experimentieren, um die Empfehlungen zu verbessern. Ein paar Vorschläge:
Collaborative Filterung mit PythonIn diesem Tutorial haben Sie gelernt, wie Sie Ihre eigenen einfachen und inhaltsbasierten Filmempfehlungssysteme erstellen können. Es gibt auch eine andere, sehr beliebte Art von Empfehlungssystemen, die als kollaborative Filter bekannt sind. Kollaborative Filter können in zwei Typen unterteilt werden:
Ein Beispiel für kollaboratives Filtern auf der Grundlage eines Bewertungssystems:
 Sie werden diese Systeme in diesem Tutorium nicht aufbauen, aber Sie sind bereits mit den meisten der dafür erforderlichen Ideen vertraut. Ein guter Ausgangspunkt für kollaborative Filter ist der MovieLens-Datensatz, den Sie hier finden. AbschlussGlückwunsch zum Abschluss dieses Tutoriums! Sie haben unser Tutorium, in dem Sie alles über Empfehlungssysteme in Python gelernt haben, erfolgreich durchlaufen. Sie haben gelernt, wie man einfache und inhaltsbasierte Empfehlungssysteme erstellt. Eine gute Übung für Sie alle wäre es, kollaboratives Filtern in Python zu implementieren, indem Sie die Teilmenge des MovieLens-Datensatzes verwenden, die Sie zum Erstellen einfacher und inhaltsbasierter Empfehlungssysteme verwendet haben. Wenn Sie gerade erst mit Python anfangen und mehr lernen möchten, besuchen Sie den DataCamp-Kurs Einführung in die Datenwissenschaft in Python. |