Sigtet med denne vejledning er ikke at gøre dig til ekspert i at opbygge modeller til recommender-systemer. I stedet er motivet at få dig i gang ved at give dig et overblik over den type anbefalingssystemer, der findes, og hvordan du kan opbygge et ved yo
I denne vejledning lærer du, hvordan du opbygger en grundlæggende model for enkle og indholdsbaserede anbefalingssystemer. Selv om disse modeller ikke vil være i nærheden af industristandarden med hensyn til kompleksitet, kvalitet eller nøjagtighed, vil det hjælpe dig med at komme i gang med at bygge mere komplekse modeller, der giver endnu bedre resultater.
Recommender-systemer er blandt de mest populære anvendelser af datavidenskab i dag. De bruges til at forudsige den “vurdering” eller “præference”, som en bruger vil give en vare. Næsten alle større teknologivirksomheder har anvendt dem i en eller anden form. Amazon bruger dem til at foreslå produkter til kunderne, YouTube bruger dem til at afgøre, hvilken video der skal afspilles næste gang på autoplay, og Facebook bruger dem til at anbefale sider at synes godt om og personer at følge.
For nogle virksomheder som Netflix, Amazon Prime, Hulu og Hotstar drejer forretningsmodellen og deres succes sig desuden om styrken af deres anbefalinger. Netflix tilbød endda i 2009 en million dollars til den, der kunne forbedre sit system med 10 %.
Der findes også populære anbefalingssystemer til domæner som restauranter, film og online dating. Der er også blevet udviklet anbefalingssystemer til at udforske forskningsartikler og eksperter, samarbejdspartnere og finansielle tjenester. YouTube bruger anbefalingssystemet i stor skala til at foreslå dig videoer baseret på din historik. Hvis du f.eks. ser mange uddannelsesvideoer, vil den foreslå den type videoer.
Men hvad er disse anbefalingssystemer?
Overordnet set kan anbefalingssystemer klassificeres i 3 typer:
- Simple recommenders: tilbyder generaliserede anbefalinger til alle brugere, baseret på filmpopularitet og/eller genre. Den grundlæggende idé bag dette system er, at film, der er mere populære og kritikerroste, vil have en større sandsynlighed for at kunne lide dem hos det gennemsnitlige publikum. Et eksempel kunne være IMDB Top 250.
- Indholdsbaserede anbefalinger: foreslår lignende emner på grundlag af et bestemt emne. Dette system bruger metadata om et emne, f.eks. genre, instruktør, beskrivelse, skuespillere osv. for film, til at give disse anbefalinger. Den generelle idé bag disse anbefalingssystemer er, at hvis en person kan lide en bestemt vare, vil han eller hun også kunne lide en vare, der ligner den. Og for at anbefale dette vil systemet gøre brug af brugerens tidligere metadata om varer. Et godt eksempel kunne være YouTube, hvor den på baggrund af din historik foreslår dig nye videoer, som du potentielt kunne se.
- Collaborative filtering engines: Disse systemer er meget udbredte, og de forsøger at forudsige den bedømmelse eller præference, som en bruger vil give et emne, på baggrund af andre brugeres tidligere bedømmelser og præferencer. Kollaborative filtre kræver ikke metadata om emner som deres indholdsbaserede modstykker.
Simple recommenders
Som beskrevet i det foregående afsnit er simple recommenders grundlæggende systemer, der anbefaler de bedste emner baseret på en bestemt metrik eller score. I dette afsnit skal du opbygge en forenklet klon af IMDB Top 250-film ved hjælp af metadata indsamlet fra IMDB.
De følgende trin er de involverede trin:
-
Beslut dig for den metrik eller score, som film skal bedømmes ud fra.
-
Beregn scoren for hver film.
-
Sorter filmene på baggrund af scoren, og output de bedste resultater.
Om datasættet
Datasætfilerne indeholder metadata for alle 45.000 film, der er opført i Full MovieLens Dataset. Datasættet består af film, der er udgivet i eller før juli 2017. Dette datasæt indfanger feature points som cast, crew, plot keywords, budget, indtægter, plakater, udgivelsesdatoer, sprog, produktionsselskaber, lande, TMDB-stemmetal og stemmegennemsnit.
Disse funktionspunkter kan potentielt bruges til at træne dine maskinlæringsmodeller til indholds- og kollaborativ filtrering.
Dette datasæt består af følgende filer:
- movies_metadata.csv: Denne fil indeholder oplysninger om ~45.000 film, der er med i det fulde MovieLens-datasæt. Funktioner omfatter plakater, baggrunde, budget, genre, indtægter, udgivelsesdatoer, sprog, produktionslande og selskaber.
- keywords.csv: Indeholder filmplottets nøgleord for vores MovieLens-film. Tilgængelig i form af et stringificeret JSON-objekt.
- credits.csv: Består af oplysninger om cast og besætning for alle film. Tilgængelig i form af et stringificeret JSON Object.
- links.csv: Denne fil indeholder TMDB- og IMDB-id’er for alle de film, der er med i det fulde MovieLens-datasæt.
- links_small.csv: Indeholder TMDB- og IMDB-id’er for en lille delmængde af 9.000 film i det fulde datasæt.
- ratings_small.csv: Delmængden af 100.000 vurderinger fra 700 brugere om 9.000 film.
Det fulde MovieLens-datasæt omfatter 26 millioner vurderinger og 750.000 tag-applikationer fra 270.000 brugere om alle de 45.000 film i dette datasæt. Det kan tilgås fra det officielle GroupLens-websted.
Bemærk: Delmængden af datasættet, der anvendes i dagens tutorial, kan downloades her.
For at indlæse dit datasæt skal du bruge pandas DataFrame-biblioteket. pandas biblioteket bruges hovedsageligt til datamanipulation og analyse. Det repræsenterer dine data i et række- og kolonneformat. Pandas-biblioteket bakkes op af NumPy arrayet til implementering af pandas-dataobjekter. pandas tilbyder færdige datastrukturer og operationer til manipulation af numeriske tabeller, tidsserier, billedmateriale og datasæt til behandling af naturlige sprog. Grundlæggende er pandas nyttigt for de datasæt, der let kan repræsenteres i tabelform.
Hvor du udfører nogen af de ovenstående trin, skal du indlæse dit metadatasæt for film i et pandas DataFrame:
# Import Pandasimport pandas as pd# Load Movies Metadatametadata = pd.read_csv('movies_metadata.csv', low_memory=False)# Print the first three rowsmetadata.head(3)| adult | belongs_to_collection | budget | genres | homepage | id | imdb_id | original_language | original_title | overview | overview | … | release_date | revenue | runtime | spoken_languages | status | tagline | tagline | title | video | vote_average | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | |||||||||||||||
| 1 | Falsk | NaN | 65000000 | Udgivet | Still Yelling. Still Fighting. Still Ready for… | Grumpier Old Men | Falsk | 6,5 | 92,0 |
3 rækker × 24 kolonner
En af de mest grundlæggende målinger, man kan tænke på, er den rangordning, der skal afgøre, hvilke top 250 film der er baseret på deres respektive vurderinger.
Det har dog et par forbehold at bruge en rating som metrik:
-
For det første tager den ikke hensyn til en films popularitet. Derfor vil en film med en vurdering på 9 fra 10 vælgere blive betragtet som “bedre” end en film med en vurdering på 8,9 fra 10.000 vælgere.
For eksempel: Forestil dig, at du ønsker at bestille kinesisk mad, du har et par muligheder, den ene restaurant har en 5-stjernet vurdering af kun 5 personer, mens den anden restaurant har 4,5 vurderinger af 1.000 personer. Hvilken restaurant ville du foretrække? Den anden, ikke sandt?
Der kan selvfølgelig være den undtagelse, at den første restaurant åbnede for få dage siden, og at der derfor er færre, der har stemt på den, mens den anden restaurant tværtimod har været i drift i et år.
- I den forbindelse vil denne metrik også have en tendens til at favorisere film med et mindre antal vælgere med skæve og/eller ekstremt høje vurderinger. Efterhånden som antallet af vælgere stiger, reguleres vurderingen af en film og nærmer sig en værdi, der afspejler filmens kvalitet og giver brugeren en meget bedre idé om, hvilken film han/hun bør vælge. Selv om det er vanskeligt at skelne kvaliteten af en film med ekstremt få vælgere, kan man være nødt til at overveje eksterne kilder for at konkludere.
I betragtning af disse mangler skal man finde frem til en vægtet bedømmelse, der tager hensyn til den gennemsnitlige bedømmelse og det antal stemmer, den har samlet. Et sådant system vil sikre, at en film med en 9-bedømmelse fra 100.000 vælgere får en (langt) højere score end en film med samme bedømmelse, men med blot nogle få hundrede vælgere.
Da du forsøger at opbygge en klon af IMDB’s Top 250, skal vi bruge dens vægtede bedømmelsesformel som metrik/score. Matematisk er den repræsenteret som følger:
\begin{equation}\text Weighted Rating (\bf WR) = \left({{\bf v} \over {\bf v} + {\bf m}} \cdot R\right) + \left({{\bf m} \over {\bf v} + {\bf m} \over {\bf v} + {\bf m}} \cdot C\right)\end{equation}
I ovenstående ligning,
-
v er antallet af stemmer for filmen;
-
m er det minimum af stemmer, der kræves for at blive opført i diagrammet;
-
R er den gennemsnitlige bedømmelse af filmen;
-
C er den gennemsnitlige stemmeandel i hele rapporten.
Du har allerede værdierne til v (vote_count) og R (vote_average) for hver film i datasættet. Det er også muligt at beregne C direkte ud fra disse data.
Bestemmelse af en passende værdi for m er en hyperparameter, som du kan vælge i overensstemmelse hermed, da der ikke findes en rigtig værdi for m. Du kan betragte det som et foreløbigt negativt filter, der blot fjerner de film, som har et antal stemmer, der er mindre end en vis tærskel m. Selektiviteten af dit filter er op til dit skøn.
I denne vejledning vil du bruge cutoff m som den 90. percentil. Med andre ord skal en film have flere stemmer end mindst 90 % af filmene på listen for at blive vist i hitlisterne. (Hvis du derimod havde valgt den 75. percentil, ville du have taget hensyn til de 25 % af filmene med hensyn til antallet af stemmer, der er opnået. Efterhånden som percentilen falder, vil antallet af film, der tages i betragtning, stige).
Som et første skridt beregner vi værdien af C, den gennemsnitlige bedømmelse på tværs af alle film ved hjælp af pandas .mean()-funktionen:
# Calculate mean of vote average columnC = metadata.mean()print(C)5.618207215133889Fra ovenstående output kan du observere, at den gennemsnitlige bedømmelse af en film på IMDB er omkring 5.6 på en skala på 10.
Næst skal vi beregne antallet af stemmer, m, som en film har modtaget i den 90. percentil. pandas-biblioteket gør denne opgave ekstremt triviel ved hjælp af .quantile()-metoden i pandas:
# Calculate the minimum number of votes required to be in the chart, mm = metadata.quantile(0.90)print(m)160.0Da du nu har m, kan du blot bruge en større end lig med-betingelse til at filtrere film med et antal stemmer større end lig med 160 fra:
Du kan bruge .copy()-metoden til at sikre, at det nye q_movies DataFrame, der oprettes, er uafhængigt af dit oprindelige metadata DataFrame. Med andre ord vil eventuelle ændringer i q_movies DataFrame ikke påvirke den oprindelige metadata-dataramme.
# Filter out all qualified movies into a new DataFrameq_movies = metadata.copy().loc >= m]q_movies.shape(4555, 24)metadata.shape(45466, 24)Fra ovenstående output er det tydeligt, at der er omkring 10 % film med et stemmetal på over 160, som kvalificerer sig til at være på denne liste.
Næste og vigtigste trin er at beregne den vægtede bedømmelse for hver kvalificeret film. For at gøre dette skal du:
- Definer en funktion,
weighted_rating(); - Da du allerede har beregnet
mogC, skal du blot videregive dem som argument til funktionen; - Dernæst skal du vælge kolonnen
vote_count(v) ogvote_average(R) fraq_movies-datarammen; - Sluttelig skal du beregne det vægtede gennemsnit og returnere resultatet.
Du vil definere en ny funktion score, som du beregner værdien af ved at anvende denne funktion på din DataFrame med kvalificerede film:
# Function that computes the weighted rating of each moviedef weighted_rating(x, m=m, C=C): v = x R = x # Calculation based on the IMDB formula return (v/(v+m) * R) + (m/(m+v) * C)# Define a new feature 'score' and calculate its value with `weighted_rating()`q_movies = q_movies.apply(weighted_rating, axis=1)Sluttelig skal vi sortere DataFrame i faldende rækkefølge baseret på score-funktionskolonnen og udstede titel, stemmetal, stemmegennemsnit og vægtet bedømmelse (score) for de 20 bedste film.
#Sort movies based on score calculated aboveq_movies = q_movies.sort_values('score', ascending=False)#Print the top 15 moviesq_movies].head(20)| title | vote_count | vote_average | vote_average | score | |
|---|---|---|---|---|---|
| 314 | The Shawshank Redemption | 8358.0 | 8.5 | 8.445869 | |
| 834 | The Godfather | 6024.0 | 8.5 | 8.425439 | |
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.421453 | |
| 12481 | The Dark Knight | 12269.0 | 8.3 | 8.265477 | |
| 2843 | Fight Club | 9678.0 | 8.3 | 8.256385 | |
| 292 | Pulp Fiction | 8670.0 | 8.3 | 8.251406 | |
| 522 | Schindlers liste | 4436.0 | 8.251406 | 8.3 | 8.206639 |
| 23673 | Whiplash | 4376.0 | 8.3 | 8.3 | 8.205404 |
| 5481 | Spirited Away | 3968.0 | 8.3 | 8.196055 | |
| 2211 | Livet er smukt | 3643.0 | 8.3 | 8.187171 | |
| 1178 | The Godfather: Part II | 3418.0 | 8.3 | 8.180076 | |
| 1152 | One Flew Over the Cuckoo’s Nest | 3001.0 | 8.3 | 8.3 | 8.164256 |
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.150272 | |
| 1154 | The Empire Strikes Back | 5998.0 | 8.2 | 8.132919 | |
| 1176 | Psycho | 2405.0 | 8.3 | 8.132715 | |
| 18465 | The Intouchables | 5410.0 | 8.2 | 8.125837 | |
| 40251 | Dit navn. | 1030.0 | 8.5 | 8.112532 | |
| 289 | Leon: The Professional | 4293.0 | 8.2 | 8.107234 | |
| 303030 | The Green Mile | 4166.0 | 8.2 | 8.104511 | |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
Nu kan du se af ovenstående output, at simple recommender gjorde et godt stykke arbejde!
Da oversigten har mange film til fælles med IMDB Top 250 oversigten: for eksempel er dine to bedste film, “Shawshank Redemption” og “The Godfather”, de samme som IMDB, og vi ved alle sammen, at de virkelig er fantastiske film, faktisk fortjener alle top 20 film at være på den liste, ikke sandt?
Content-Based Recommender
Plot Description Based Recommender
I dette afsnit af tutorialen lærer du, hvordan du opbygger et system, der anbefaler film, der ligner en bestemt film. For at opnå dette vil du beregne parvise cosine lighedsscorer for alle film baseret på deres plotbeskrivelser og anbefale film baseret på denne tærskel for lighedsscore.
Plotbeskrivelsen er tilgængelig for dig som overview-funktionen i dit metadata-datasæt. Lad os inspicere plotbeskrivelserne for nogle få film:
#Print plot overviews of the first 5 movies.metadata.head()0 Led by Woody, Andy's toys live happily in his ...1 When siblings Judy and Peter discover an encha...2 A family wedding reignites the ancient feud be...3 Cheated on, mistreated and stepped on, the wom...4 Just when George Banks has recovered from his ...Name: overview, dtype: objectDet foreliggende problem er et problem i forbindelse med Natural Language Processing. Derfor skal du udtrække en slags funktioner fra ovenstående tekstdata, før du kan beregne ligheden og/eller uligheden mellem dem. For at sige det enkelt, så er det ikke muligt at beregne ligheden mellem to oversigter i deres rå form. For at gøre dette er man nødt til at beregne ordvektorerne for hver enkelt oversigt eller dokument, som det fremover vil blive kaldt.
Som navnet antyder, er ordvektorer en vektoriseret repræsentation af ord i et dokument. Vektorerne bærer en semantisk betydning med sig. For eksempel vil mand & konge have vektorrepræsentationer tæt på hinanden, mens mand & kvinde vil have repræsentation langt fra hinanden.
Du vil beregne Term Frequency-Inverse Document Frequency (TF-IDF) vektorer for hvert dokument. Dette vil give dig en matrix, hvor hver kolonne repræsenterer et ord i oversigtsvokabularet (alle de ord, der forekommer i mindst ét dokument), og hver kolonne repræsenterer en film, som før.
I sin essens er TF-IDF-scoren frekvensen af et ord, der forekommer i et dokument, nedvægtet med antallet af dokumenter, hvori det forekommer. Dette gøres for at reducere betydningen af ord, der hyppigt forekommer i plotoversigter, og dermed deres betydning ved beregning af den endelige lighedsscore.
Glædeligvis giver scikit-learn dig en indbygget TfIdfVectorizer klasse, der producerer TF-IDF-matricen på et par linjer.
- Importér Tfidf-modulet ved hjælp af scikit-learn;
- Fjern stopord som ‘the’, ‘an’ osv. da de ikke giver nogen nyttig information om emnet;
- Erstat ikke-et-nummer-værdier med en tom streng;
- Slutteligt konstrueres TF-IDF-matricen på dataene.
#Import TfIdfVectorizer from scikit-learnfrom sklearn.feature_extraction.text import TfidfVectorizer#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'tfidf = TfidfVectorizer(stop_words='english')#Replace NaN with an empty stringmetadata = metadata.fillna('')#Construct the required TF-IDF matrix by fitting and transforming the datatfidf_matrix = tfidf.fit_transform(metadata)#Output the shape of tfidf_matrixtfidf_matrix.shape(45466, 75827)#Array mapping from feature integer indices to feature name.tfidf.get_feature_names()Fra ovenstående output kan du konstatere, at 75.827 forskellige ordforråd eller ord i dit datasæt har 45.000 film.
Med denne matrix i hånden kan du nu beregne en lighedsscore. Der er flere similaritetsmetrikker, som du kan bruge til dette, f.eks. manhattan-, euklidisk-, Pearson- og cosinus-sammenfaldsscore. Igen er der ikke noget rigtigt svar på, hvilken score der er den bedste. Forskellige scoringer fungerer godt i forskellige scenarier, og det er ofte en god idé at eksperimentere med forskellige metrikker og observere resultaterne.
Du skal bruge cosine similarity til at beregne en numerisk størrelse, der angiver ligheden mellem to film. Du bruger cosinus-sammenfaldsscoren, da den er uafhængig af størrelsen og er relativt nem og hurtig at beregne (især når den bruges sammen med TF-IDF-scoren, som vil blive forklaret senere). Matematisk set er den defineret som følger:
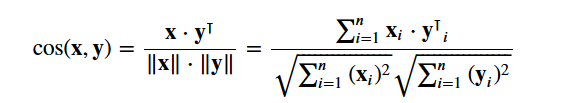
Da du har brugt TF-IDF-vectorizer, vil beregningen af prikproduktet mellem hver vektor direkte give dig cosinus-sammenfaldsscoren. Derfor skal du bruge sklearn's linear_kernel() i stedet for cosine_similarities(), da det er hurtigere.
Dette ville give en matrix af formen 45466×45466, hvilket betyder, at hver film overview cosinuslighedsscore med hver anden film overview. Derfor vil hver film være en 1×45466 kolonnevektor, hvor hver kolonne vil være en lighedsscore med hver film.
# Import linear_kernelfrom sklearn.metrics.pairwise import linear_kernel# Compute the cosine similarity matrixcosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)cosine_sim.shape(45466, 45466)cosine_simarray()Du skal definere en funktion, der tager en filmtitel ind som input og udsender en liste over de 10 mest ens film. For det første har du til dette brug for en omvendt mapping af filmtitler og DataFrame-indekser. Med andre ord har du brug for en mekanisme til at identificere indekset for en film i dit metadata DataFrame, givet dens titel.
#Construct a reverse map of indices and movie titlesindices = pd.Series(metadata.index, index=metadata).drop_duplicates()indicestitleToy Story 0Jumanji 1Grumpier Old Men 2Waiting to Exhale 3Father of the Bride Part II 4Heat 5Sabrina 6Tom and Huck 7Sudden Death 8GoldenEye 9dtype: int64Du er nu i god form til at definere din anbefalingsfunktion. Du skal følge følgende trin:
-
Hent filmens indeks givet dens titel.
-
Hent listen over cosinus-sammenfaldsscorer for denne bestemte film med alle film. Konverter den til en liste af tupler, hvor det første element er dens position, og det andet er lighedsscoren.
-
Sorter førnævnte liste af tupler på baggrund af lighedsscorerne; dvs. det andet element.
-
Hent de 10 øverste elementer på denne liste. Ignorer det første element, da det henviser til sig selv (den film, der ligner en bestemt film mest, er filmen selv).
-
Hentér de titler, der svarer til indeksene for de øverste elementer.
# Function that takes in movie title as input and outputs most similar moviesdef get_recommendations(title, cosine_sim=cosine_sim): # Get the index of the movie that matches the title idx = indices # Get the pairwsie similarity scores of all movies with that movie sim_scores = list(enumerate(cosine_sim)) # Sort the movies based on the similarity scores sim_scores = sorted(sim_scores, key=lambda x: x, reverse=True) # Get the scores of the 10 most similar movies sim_scores = sim_scores # Get the movie indices movie_indices = for i in sim_scores] # Return the top 10 most similar movies return metadata.ilocget_recommendations('The Dark Knight Rises')12481 The Dark Knight150 Batman Forever1328 Batman Returns15511 Batman: Under the Red Hood585 Batman21194 Batman Unmasked: The Psychology of the Dark Kn...9230 Batman Beyond: Return of the Joker18035 Batman: Year One19792 Batman: The Dark Knight Returns, Part 13095 Batman: Mask of the PhantasmName: title, dtype: objectget_recommendations('The Godfather')1178 The Godfather: Part II44030 The Godfather Trilogy: 1972-19901914 The Godfather: Part III23126 Blood Ties11297 Household Saints34717 Start Liquidation10821 Election38030 A Mother Should Be Loved17729 Short Sharp Shock26293 Beck 28 - FamiljenName: title, dtype: objectDu kan se, at selv om dit system har gjort et fornuftigt stykke arbejde med at finde film med lignende plotbeskrivelser, er kvaliteten af anbefalingerne ikke så stor. “The Dark Knight Rises” returnerer alle Batman-film, mens det er mere sandsynligt, at de personer, der kunne lide den film, er mere tilbøjelige til at kunne lide andre Christopher Nolan-film. Dette er noget, som dit nuværende system ikke kan indfange.
Credits, Genres, and Keywords Based Recommender
Kvaliteten af din recommender ville blive øget med brug af bedre metadata og ved at indfange flere af de finere detaljer. Det er netop det, du vil gøre i dette afsnit. Du vil opbygge et anbefalingssystem baseret på følgende metadata: de 3 bedste skuespillere, instruktøren, relaterede genrer og nøgleord for filmens plot.
Nøgleordene, skuespillerne og besætningsdataene er ikke tilgængelige i dit nuværende datasæt, så det første skridt vil være at indlæse og sammenføje dem i dit primære DataFrame metadata.
# Load keywords and creditscredits = pd.read_csv('credits.csv')keywords = pd.read_csv('keywords.csv')# Remove rows with bad IDs.metadata = metadata.drop()# Convert IDs to int. Required for mergingkeywords = keywords.astype('int')credits = credits.astype('int')metadata = metadata.astype('int')# Merge keywords and credits into your main metadata dataframemetadata = metadata.merge(credits, on='id')metadata = metadata.merge(keywords, on='id')# Print the first two movies of your newly merged metadatametadata.head(2)| adult | belongs_to_collection | budget | genres | homepage | id | imdb_id | original_language | original_title | overview | overview | … | spoken_languages | status | tagline | title | video | vote_average | vote_count | cast | crew | crew | keywords | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | {‘id’: 10194, ‘name’: ‘Toy Story Collection’, … | 30000000 | Released | NaN | Toy Story | False | 7.7 | 5415.0 | for feature in features: metadata = metadata.apply(literal_eval)
Næst skriver du funktioner, der hjælper dig med at udtrække de nødvendige oplysninger fra hver feature. Først importerer du NumPy-pakken for at få adgang til dens Hent instruktørens navn fra crew-funktionen. Hvis instruktøren ikke er opført, returnerer du Næst skal du skrive en funktion, der returnerer de 3 øverste elementer eller hele listen, alt efter hvad der er flest. Her henviser listen til
Det næste skridt ville være at konvertere navnene og nøgleordsinstanserne til små bogstaver og fjerne alle mellemrum mellem dem. Fjernelse af mellemrum mellem ord er et vigtigt forbehandlingstrin. Det gøres, så din vectorizer ikke tæller Johnny af “Johnny Depp” og “Johnny Galecki” som det samme. Efter dette behandlingstrin vil de førnævnte skuespillere blive repræsenteret som “johnnydepp” og “johnnygalecki” og vil være forskellige for din vectorizer. Et andet godt eksempel, hvor modellen kan outputte den samme vektorrepræsentation, er “bread jam” og “traffic jam”. Derfor er det bedre at fjerne ethvert mellemrum, der er til stede. Nedenstående funktion vil præcis gøre det for dig: Du er nu i stand til at oprette din “metadatasuppe”, som er en streng, der indeholder alle de metadata, som du ønsker at fodre din vectorizer med (nemlig skuespillere, instruktør og nøgleord). Funktionen
| suppe |
0 |
jealousy toy boy tomhanks timallen donrickles … 1 |
brætspil forsvinden baseretpåbørnebog …
De næste trin er de samme som dem, du gjorde med din Den store forskel mellem og Fra ovenstående output kan du se, at der er 73.881 vokabularer i de metadata, som du har fodret den med. Næst bruger du Du kan nu genbruge din Godt! Du kan se, at din anbefalingssøger har haft succes med at indfange flere oplysninger på grund af flere metadata og har givet dig bedre anbefalinger. Der er naturligvis mange måder at eksperimentere med dette system på for at forbedre anbefalingerne. Nogle forslag:
Collaborative Filtering med PythonI denne vejledning har du lært, hvordan du kan opbygge dit helt eget enkle og indholdsbaserede filmanbefalingssystem. Der findes også en anden yderst populær type recommender, der er kendt som kollaborative filtre. Samarbejdsfiltre kan yderligere inddeles i to typer:
Et eksempel på kollaborativ filtrering baseret på et vurderingssystem:
 Du skal ikke opbygge disse systemer i denne vejledning, men du er allerede bekendt med de fleste af de idéer, der kræves for at gøre det. Et godt sted at starte med kollaborative filtre er ved at undersøge MovieLens-datasættet, som findes her. KonklusionGodt tillykke med afslutningen af denne tutorial! Du har med succes gennemgået vores tutorial, der lærte dig alt om recommender-systemer i Python. Du har lært at opbygge enkle og indholdsbaserede anbefalingssystemer. En god øvelse for jer alle ville være at implementere kollaborativ filtrering i Python ved hjælp af den delmængde af MovieLens-datasættet, som du brugte til at opbygge enkle og indholdsbaserede anbefalingssystemer. Hvis du lige er begyndt i Python og gerne vil lære mere, kan du tage DataCamps kursus Introduktion til datalogi i Python. |