
Jag gör en hel del Twitchrelaterade projekt här och där, och försöker se vilka möjligheter som finns. Ett av mina senaste projekt var att skapa ett Twitch Emote Extension för Chrome där jag visade hur man gratis kan få extra emote ”slots”. Det fick mig att börja med webbläsartillägg, så jag tänkte att vi kan visa hur man gör ett från grunden genom att bygga ett profanitetsfilter för Twitch-chatten.
I slutet av detta vill vi ha ett tillägg som, när det är installerat, kontrollerar om det finns en uppsättning flaggade ord i chatten och ersätter dem med mer vänliga versioner. Detta kan till exempel vara användbart för barn som tittar på streams.
Om du bara vill ha koden för det här tillägget finns det en länk till slutresultatet längst ner i den här artikeln.
Okej, så låt oss gå in i det med huvudet först. Skapa en mapp någonstans där du vill och kalla den profanity-filter. Jag skapade min på en plats där jag synkroniserar med GitHub.

Nu skapar du inom den här mappen två nya filer: manifest.json och content.js. Du kommer att se hur vi kommer att använda dem när vi börjar bygga tillägget.
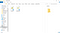
Öppna manifest.json, som är den fil som Google tittar på för metadata om ditt tillägg, och klistra in följande i den:
{ "manifest_version": 2, "name": "Twitch Profanity Filter Extension", "version": "0.1", "content_scripts": , "js": } ]}
Som du kan se talar vi om för Google att det här tillägget ska fungera på vilken sida som helst från Twitch, och vi säger också att logiken som ska köras på de här sidorna finns i filen som heter content.js. Observera att jag har angett versionen som 0.1, eftersom detta är mitt första försök.
För att få in logiken
Öppna nu content.js i en valfri textredigerare. Jag skulle starkt rekommendera Visual Studio Code, det är min favorittextredigerare för allt kodningsrelaterat och den är gratis.
Nu kommer vi att ställa in detta i några få steg. Vad vill vi uppnå och hur ska vi åstadkomma det? Vi vet att vi vill ändra vissa ord till andra, vilket innebär att vi läser chattmeddelandena, skannar dem efter markerade ord och sedan uppdaterar dessa ord till mer vänliga ord. Så när sidan laddas vill vi att vår logik ska kunna göra följande:
- Hitta chattboxen
- Varje gång ett nytt chattmeddelande dyker upp, hämta meddelandet eller meddelandebehållaren
- Ändra markerade ord till deras vänliga motsvarigheter
Så låt oss sätta igång. Den första delen är faktiskt att aktivera skriptet när sidan, eller mer specifikt fönstret, har laddats. I javascript kan du koppla in dig på denna laddningshändelse och vi kommer att göra just det. Uppdatera din content.js så att den innehåller följande:
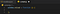
Detta kommer att se till att vad vi än lägger in i den funktionen, så kommer den att anropas när sidan har laddats.
Finn chattboxen
Hur hittar vi då chattboxen? Jo, i Chrome-versionen av Twitch-webbplatsen finns chattboxen i ett <div>-element som har en klass som heter chat-scrollable-area__message-container. Vi kommer att hämta det elementet, eller noden, med hjälp av javascript. Uppdatera filen så att den ser ut så här:

Förklaringen till att vi lägger till .item(0) bakom, är att getElementsByClassName() returnerar en array av element. Eftersom vi vet att endast ett element har den här klassen, tar vi det från arrayen genom att ange att vi vill ha den första saken (de flesta programmeringsspråk börjar räkna vid 0).
Hämta varje nytt meddelande i chatten
Det här är lite svårare att förstå om du inte är van vid programmering eller inte är van vid observatörsmönster. Sättet vi kommer att få varje nytt meddelande på är genom att använda en MutationObserver på chattbox-noden som vi just plockade upp. Uppdatera filen så att den matchar följande och sedan går vi igenom vad som händer:
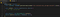
Först, på rad 4, definierar vi en callback-funktion som tar emot en lista med mutationer och observatören som vi kommer att skapa på rad 8. Logiken i den här funktionen är vad som anropas när något ändras, eller muteras, i noden vi observerar.
På rad 8 skapar vi observatören och skickar över vår callback-funktion till den. På rad 9 säger vi sedan till observatören att börja observera vår målnod och vi skickar en konfiguration som säger att vi bara är intresserade av mutationer i childList. Meddelanden visas som underordnade noder i chattbox-noden som vi observerar, så vår callback-funktion kommer att utlösas varje gång ett nytt chattmeddelande visas. Det är precis vad vi vill ha!
Men nu behöver vi fortfarande hämta de faktiska meddelandeelementen och för det lägger vi till ytterligare en kodrad i vår callback:
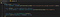
Namnet kan tyckas lite konstigt, men alla textdelar i ett meddelande (vi skannar inte av emotes, utan bara de faktiska texterna) placeras i <span> HTML-element som har klassen text-fragment. Eftersom den här funktionen utlöses vid varje nytt meddelande vet vi också att det meddelande vi vill ha måste vara det sista elementet i chattbox-noden, så det är därför vi tar tag i lastElementChild.
Ändra flaggade ord till deras vänliga motsvarigheter
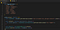
Nu kommer vi till den saftiga biten. Om vi vill ändra flaggade ord behöver vi först något som talar om för oss vad flaggade ord och deras motsvarigheter är. Vi gör detta genom att använda en enkel ordbok. Uppdatera filen så att den ser ut så här:
Nu ska vi läsa själva texten i alla textfragmentelement, slinga oss fram till alla förbjudna ord och byta ut dem om det behövs. Låt oss få igång denna loop, så uppdatera din callback-funktion med följande:

Vad som händer här är att vi loopar genom alla dessa element som innehåller text. På rad 18 tar vi ett specifikt element i taget och på rad 19 hämtar vi den faktiska texten från det i små bokstäver, eftersom alla våra markerade ord också är i små bokstäver. Det gör det lättare att jämföra, men i en mer avancerad version skulle vi ta hand om att snyggt upprätthålla kasetteringen. Nu när vi har vår text vill vi gå över våra markerade ord och kontrollera om de finns med. Om så är fallet raderar vi dem. Uppdatera funktionen:

Det lexikon som vi gjorde fungerar med nyckel-värdepar, där nycklarna är de flaggade orden och värdena är de vänliga orden, så på rad 21 hämtar vi helt enkelt en matris med alla nycklar, vilket är matrisen av flaggade ord vi vill slinga över. I slingan tar vi det flaggade ordet som vi för närvarande tittar på och om vår text innehåller ett eller flera av dem, tar vi det vänliga ordet och uppdaterar vår text genom att ersätta de flaggade orden. Det är nästan allt, nu behöver vi bara ta vår nya och förbättrade text och placera den tillbaka i elementet vi tog den från:

På rad 31 har vi nu placerat texten tillbaka i elementet och det är det! Låt oss börja testa detta i Chrome.
Testet
Öppna Chrome och bläddra till chrome://extensions. Du bör se dina tillägg och uppe till höger ser du Utvecklingsläge. Slå på det om det inte är det ännu. Därefter ser du i det övre högra hörnet alternativet Ladda upp uppackat. Vi ska använda det för att ladda in vårt lokala tillägg utan att behöva gå via Chrome Web Store-rutten ännu. Klicka på den och välj mappen där filerna finns:
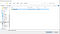
Det borde göra att det visas omedelbart i vår tilläggslista:
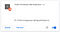
Bra! Nu går vi över till någon kanal där vi kan chatta. Jag går till min vän Bjarkes kanal, en rolig dansk streamer, och provar det:

Där har vi det, det fungerar! Vårt eget filter för svordomar. Det var väl inte så svårt, eller hur? Allt som återstår är att släppa det till Chrome Web Store om du vill. Jag kommer att utöka den här listan med ord och släppa detta, så om du inte behöver mer än så här behöver du inte släppa det, eftersom det kräver en avgift för att komma in i programmet. Jag kommer inte att gå in på hur releasen fungerar, men om du är intresserad har jag gjort en Twitch Emote Extension för att få dina egna gränslösa emote slots och den här artikeln förklarar hur man släpper tillägg i slutet.
Om du vill se all kod för det här tillägget kan du kolla in GitHub repo här. Glad kodning!