- Introducere
- Definiții
- TensorFlow/Keras
- Recunoașterea imaginilor (clasificare)
- Extragerea caracteristicilor
- Cum învață rețelele neuronale să recunoască imagini
- Extragerea caracteristicilor cu ajutorul filtrelor
- Funcții de activare
- Capacități de centralizare
- Aflatarea
- Clasa complet conectată
- Fluxul de lucru al învățării automate
- Pregătirea datelor
- Crearea modelului
- Învățarea modelului
- Evaluarea modelului
- Recunoașterea imaginilor cu un CNN
- Pregătirea datelor
- Designing the Model
- Crearea modelului
- Concluzie
Introducere
Una dintre cele mai comune utilizări ale TensorFlow și Keras este recunoașterea/clasificarea imaginilor. Dacă doriți să învățați cum să utilizați Keras pentru a clasifica sau recunoaște imagini, acest articol vă va învăța cum.
Definiții
Dacă nu vă sunt clare conceptele de bază din spatele recunoașterii imaginilor, va fi dificil să înțelegeți complet restul acestui articol. Așadar, înainte de a merge mai departe, haideți să luăm un moment pentru a defini câțiva termeni.
TensorFlow/Keras

Credit: commons.wikimedia.org
TensorFlow este o bibliotecă open source creată pentru Python de către echipa Google Brain. TensorFlow compilează mai mulți algoritmi și modele diferite împreună, permițând utilizatorului să implementeze rețele neuronale profunde pentru a le utiliza în sarcini precum recunoașterea/clasificarea imaginilor și procesarea limbajului natural. TensorFlow este un cadru puternic care funcționează prin implementarea unei serii de noduri de procesare, fiecare nod reprezentând o operație matematică, întreaga serie de noduri fiind numită „graf”.
În ceea ce privește Keras, acesta este un API (interfață de programare a aplicațiilor) de nivel înalt care poate utiliza funcțiile TensorFlow dedesubt (precum și alte biblioteci ML, cum ar fi Theano). Keras a fost proiectat având ca principii directoare ușurința de utilizare și modularitatea. În termeni practici, Keras face ca implementarea numeroaselor funcții puternice, dar adesea complexe, ale TensorFlow să fie cât mai simplă posibil și este configurată pentru a funcționa cu Python fără modificări sau configurări majore.
Recunoașterea imaginilor (clasificare)
Recunoașterea imaginilor se referă la sarcina de a introduce o imagine într-o rețea neuronală și de a o face să emită un fel de etichetă pentru acea imagine. Eticheta pe care rețeaua o emite va corespunde unei clase predefinite. Pot exista mai multe clase în care imaginea poate fi etichetată sau doar una singură. Dacă există o singură clasă, se aplică adesea termenul de „recunoaștere”, în timp ce o sarcină de recunoaștere cu mai multe clase se numește adesea „clasificare”.
Un subansamblu al clasificării imaginilor este detectarea obiectelor, în care anumite instanțe specifice ale obiectelor sunt identificate ca aparținând unei anumite clase, cum ar fi animale, mașini sau oameni.
Extragerea caracteristicilor
Pentru a efectua recunoașterea/clasificarea imaginilor, rețeaua neuronală trebuie să efectueze extragerea caracteristicilor. Caracteristicile sunt elementele din datele care vă interesează și care vor fi introduse în rețea. În cazul specific al recunoașterii imaginilor, caracteristicile sunt grupurile de pixeli, cum ar fi marginile și punctele, ale unui obiect pe care rețeaua le va analiza pentru a găsi modele.
Recunoașterea caracteristicilor (sau extragerea caracteristicilor) este procesul de extragere a caracteristicilor relevante dintr-o imagine de intrare, astfel încât aceste caracteristici să poată fi analizate. Multe imagini conțin adnotări sau metadate despre imagine care ajută rețeaua să găsească trăsăturile relevante.
Cum învață rețelele neuronale să recunoască imagini
Obținerea unei intuiții despre modul în care o rețea neuronală recunoaște imaginile vă va ajuta atunci când implementați un model de rețea neuronală, așa că haideți să explorăm pe scurt procesul de recunoaștere a imaginilor în următoarele câteva secțiuni.
Extragerea caracteristicilor cu ajutorul filtrelor
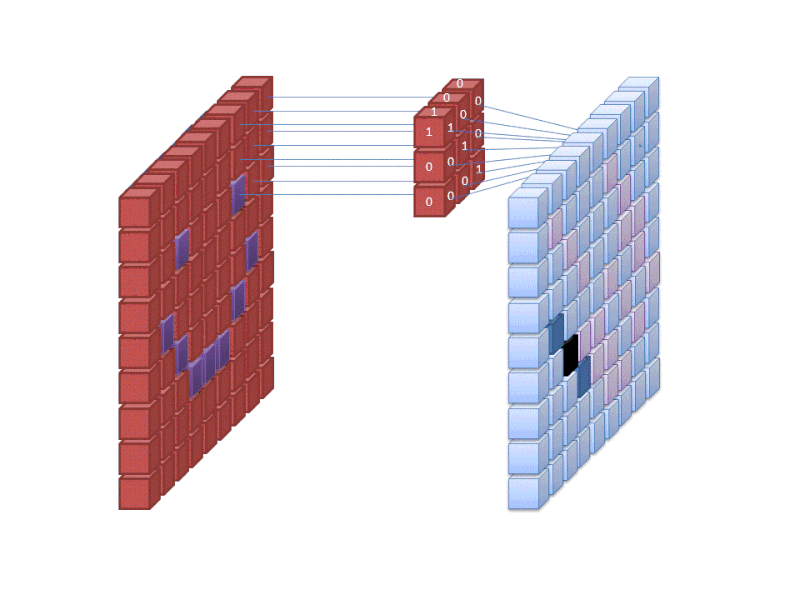
Credit: commons.wikimedia.org
Primul strat al unei rețele neuronale preia toți pixelii din cadrul unei imagini. După ce toate datele au fost introduse în rețea, se aplică diferite filtre pe imagine, care formează reprezentări ale diferitelor părți ale imaginii. Aceasta este extragerea caracteristicilor și creează „hărți ale caracteristicilor”.
Acest proces de extragere a caracteristicilor dintr-o imagine este realizat cu un „strat convoluțional”, iar convoluția este pur și simplu formarea unei reprezentări a unei părți a imaginii. De la acest concept de convoluție provine termenul de rețea neuronală convoluțională (CNN), tipul de rețea neuronală cel mai frecvent utilizat în clasificarea/recunoașterea imaginilor.
Dacă doriți să vizualizați modul în care funcționează crearea hărților de caracteristici, gândiți-vă că luminați o lanternă peste o imagine într-o cameră întunecată. Pe măsură ce glisați fasciculul peste imagine, învățați despre caracteristicile imaginii. Un filtru este ceea ce folosește rețeaua pentru a forma o reprezentare a imaginii, iar în această metaforă, lumina de la lanternă este filtrul.
Lățimea fasciculului lanternei controlează cât de mult din imagine examinați la un moment dat, iar rețelele neuronale au un parametru similar, dimensiunea filtrului. Dimensiunea filtrului afectează cât de mult din imagine, câți pixeli, sunt examinați la un moment dat. O dimensiune obișnuită a filtrului utilizată în CNN-uri este 3, iar aceasta acoperă atât înălțimea, cât și lățimea, astfel încât filtrul examinează o zonă de 3 x 3 pixeli.
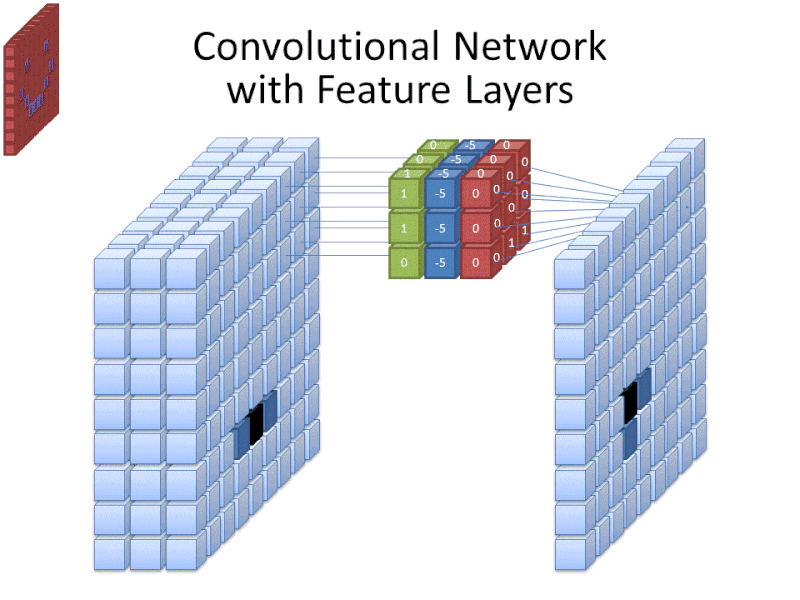
Credit: commons.wikimedia.org
În timp ce dimensiunea filtrului acoperă înălțimea și lățimea filtrului, trebuie specificată și adâncimea filtrului.
Cum poate o imagine 2D să aibă adâncime?
Imaginile digitale sunt redate ca înălțime, lățime și o anumită valoare RGB care definește culorile pixelului, astfel încât „adâncimea” care este urmărită este numărul de canale de culoare pe care îl are imaginea. Imaginile în tonuri de gri (necolorate) au doar 1 canal de culoare, în timp ce imaginile color au 3 canale de adâncime.
Toate acestea înseamnă că pentru un filtru de mărimea 3 aplicat unei imagini full color, dimensiunile acelui filtru vor fi 3 x 3 x 3. Pentru fiecare pixel acoperit de acel filtru, rețeaua înmulțește valorile filtrului cu valorile din pixelii înșiși pentru a obține o reprezentare numerică a acelui pixel. Acest proces se efectuează apoi pentru întreaga imagine pentru a obține o reprezentare completă. Filtrul este deplasat pe restul imaginii în funcție de un parametru numit „stride”, care definește cu câți pixeli trebuie să fie deplasat filtrul după ce a calculat valoarea din poziția sa curentă. O dimensiune convențională a stride-ului pentru un CNN este de 2.
Rezultatul final al tuturor acestor calcule este o hartă de caracteristici. Acest proces se face de obicei cu mai multe filtre, ceea ce ajută la păstrarea complexității imaginii.
Funcții de activare
După ce a fost creată harta caracteristicilor imaginii, valorile care reprezintă imaginea sunt trecute printr-o funcție de activare sau un strat de activare. Funcția de activare preia valorile care reprezintă imaginea, care sunt într-o formă liniară (adică doar o listă de numere) datorită stratului convoluțional, și le crește neliniaritatea, deoarece imaginile în sine sunt neliniare.
Funcția de activare tipică folosită pentru a realiza acest lucru este o unitate liniară rectificată (ReLU), deși există și alte funcții de activare care sunt folosite ocazional (puteți citi despre acestea aici).
Capacități de centralizare
După ce datele sunt activate, acestea sunt trimise printr-un strat de centralizare. Pooling-ul „downsamplează” o imagine, ceea ce înseamnă că ia informațiile care reprezintă imaginea și le comprimă, făcându-le mai mici. Procesul de pooling face ca rețeaua să fie mai flexibilă și mai pricepută la recunoașterea obiectelor/imaginilor pe baza caracteristicilor relevante.
Când ne uităm la o imagine, de obicei nu suntem preocupați de toate informațiile din fundalul imaginii, ci doar de caracteristicile care ne interesează, cum ar fi oamenii sau animalele.
În mod similar, un strat de grupare într-un CNN va abstractiza părțile inutile ale imaginii, păstrând doar părțile imaginii pe care le consideră relevante, așa cum este controlat de dimensiunea specificată a stratului de grupare.
Pentru că trebuie să ia decizii cu privire la cele mai relevante părți ale imaginii, speranța este că rețeaua va învăța doar părțile imaginii care reprezintă cu adevărat obiectul în cauză. Acest lucru ajută la prevenirea supraadaptării, în cazul în care rețeaua învață prea bine aspecte ale cazului de antrenament și nu reușește să generalizeze la date noi.
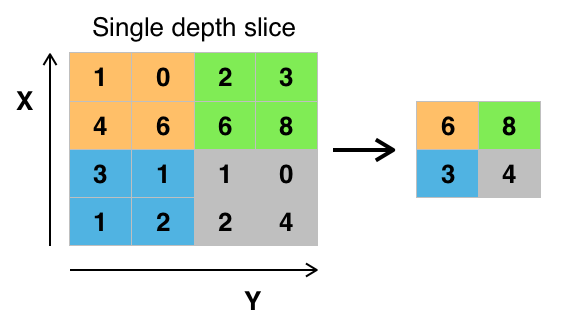
Credit: commons.wikimedia.org
Există diverse moduri de a grupa valorile, dar grupare maximă este cea mai frecvent utilizată. Max pooling obține valoarea maximă a pixelilor din cadrul unui singur filtru (dintr-un singur punct al imaginii). Acest lucru scade 3/4 din informații, presupunând că se folosesc 2 filtre x 2.
Valoarea maximă a pixelilor este folosită pentru a ține cont de posibilele distorsiuni ale imaginii, iar parametrii/dimensiunea imaginii sunt reduși pentru a controla supraajustarea. Există și alte tipuri de pooling, cum ar fi poolingul mediu sau poolingul sumar, dar acestea nu sunt folosite atât de frecvent deoarece poolingul maxim tinde să dea o acuratețe mai bună.
Aflatarea
Cele din urmă straturi ale CNN-ului nostru, straturile dens conectate, necesită ca datele să fie prelucrate sub forma unui vector. Din acest motiv, datele trebuie să fie „aplatizate”. Valorile sunt comprimate într-un vector lung sau într-o coloană de numere ordonate secvențial.
Clasa complet conectată
Cele finale ale CNN sunt straturile dens conectate, sau o rețea neuronală artificială (ANN). Funcția principală a RNA este de a analiza caracteristicile de intrare și de a le combina în diferite atribute care vor ajuta la clasificare. Aceste straturi formează, în esență, colecții de neuroni care reprezintă diferite părți ale obiectului în cauză, iar o colecție de neuroni poate reprezenta urechile flexibile ale unui câine sau roșeața unui măr. Atunci când suficient de mulți dintre acești neuroni sunt activați ca răspuns la o imagine de intrare, imaginea va fi clasificată ca fiind un obiect.

Credit: commons.wikimedia.org
Eroarea, sau diferența dintre valorile calculate și valoarea așteptată în setul de antrenament, este calculată de către RNA. Rețeaua trece apoi prin propagare inversă, unde se calculează influența unui anumit neuron asupra unui neuron din stratul următor și se ajustează influența acestuia. Acest lucru se face pentru a optimiza performanța modelului. Acest proces este apoi repetat la nesfârșit. Acesta este modul în care rețeaua se antrenează pe date și învață asocierile dintre caracteristicile de intrare și clasele de ieșire.
Neuronii din straturile de mijloc complet conectate vor emite valori binare referitoare la clasele posibile. Dacă aveți patru clase diferite (să spunem un câine, o mașină, o casă și o persoană), neuronul va avea o valoare „1” pentru clasa pe care crede că o reprezintă imaginea și o valoare „0” pentru celelalte clase.
Stratul final complet conectat va primi ieșirea stratului dinaintea sa și va furniza o probabilitate pentru fiecare dintre clase, însumând unu. Dacă există o valoare de 0,75 în categoria „câine”, aceasta reprezintă o certitudine de 75% că imaginea este un câine.
Clasificatorul de imagini a fost acum antrenat, iar imaginile pot fi trecute în CNN, care va emite acum o presupunere cu privire la conținutul acelei imagini.
Fluxul de lucru al învățării automate
Înainte de a trece la un exemplu de antrenare a unui clasificator de imagini, să ne oprim un moment pentru a înțelege fluxul de lucru sau conducta de învățare automată. Procesul de antrenare a unui model de rețea neuronală este destul de standard și poate fi împărțit în patru faze diferite.
Pregătirea datelor
În primul rând, va trebui să colectați datele și să le puneți într-o formă pe care rețeaua să se poată antrena. Acest lucru implică colectarea imaginilor și etichetarea lor. Chiar dacă ați descărcat un set de date pe care l-a pregătit altcineva, este posibil să existe o preprocesare sau o pregătire pe care trebuie să o faceți înainte de a le putea folosi pentru antrenare. Pregătirea datelor este o artă de sine stătătoare, implicând tratarea unor lucruri precum valori lipsă, date corupte, date în format greșit, etichete incorecte etc.
În acest articol, vom folosi un set de date preprocesate.
Crearea modelului
Crearea modelului rețelei neuronale implică efectuarea de alegeri cu privire la diverși parametri și hiperparametri. Trebuie să luați decizii cu privire la numărul de straturi pe care le veți folosi în model, care vor fi dimensiunile de intrare și ieșire ale straturilor, ce fel de funcții de activare veți folosi, dacă veți folosi sau nu dropout, etc.
Învățarea parametrilor și hiperparametrilor pe care să îi folosiți va veni cu timpul (și cu mult studiu), dar încă de la început există câteva euristici pe care le puteți folosi pentru a vă pune în mișcare și vom aborda unele dintre acestea în timpul exemplului de implementare.
Învățarea modelului
După ce v-ați creat modelul, pur și simplu creați o instanță a modelului și o potriviți cu datele de instruire. Cel mai mare considerent atunci când se antrenează un model este timpul necesar pentru antrenarea modelului. Puteți specifica durata de instruire pentru o rețea prin specificarea numărului de epoci de instruire. Cu cât antrenați mai mult timp un model, cu atât performanțele sale se vor îmbunătăți mai mult, dar prea multe epoci de antrenament și riscați să vă supraadaptați.
Alegerea numărului de epoci pentru care să vă antrenați este un lucru pe care îl veți simți și este obișnuit să salvați greutățile unei rețele între sesiunile de antrenament, astfel încât să nu fie nevoie să o luați de la capăt odată ce ați făcut un anumit progres în antrenarea rețelei.
Evaluarea modelului
Există mai multe etape pentru evaluarea modelului. Primul pas în evaluarea modelului este compararea performanței modelului cu un set de date de validare, un set de date pe care modelul nu a fost antrenat. Veți compara performanța modelului în raport cu acest set de validare și veți analiza performanța sa prin intermediul diferitelor metrici.
Există diferite metrici pentru determinarea performanței unui model de rețea neuronală, dar cea mai comună metrică este „acuratețea”, cantitatea de imagini clasificate corect împărțită la numărul total de imagini din setul de date.
După ce ați văzut acuratețea performanței modelului pe un set de date de validare, de obicei vă veți întoarce și veți antrena din nou rețeaua folosind parametri ușor modificați, deoarece este puțin probabil să fiți mulțumit de performanța rețelei dvs. la prima instruire. Veți continua să modificați parametrii rețelei, să o reantrenați și să îi măsurați performanța până când veți fi mulțumit de acuratețea rețelei.
În cele din urmă, veți testa performanța rețelei pe un set de testare. Acest set de testare este un alt set de date pe care modelul dvs. nu l-a văzut niciodată înainte.
Poate că vă întrebați:
De ce să vă deranjați cu setul de testare? Dacă vă faceți o idee despre acuratețea modelului dumneavoastră, nu acesta este scopul setului de validare?
Este o idee bună să păstrați un lot de date pe care rețeaua nu le-a văzut niciodată pentru testare, deoarece toate ajustările parametrilor pe care le faceți, combinate cu retestarea pe setul de validare, ar putea însemna că rețeaua dumneavoastră a învățat unele particularități ale setului de validare care nu se vor generaliza la datele din afara eșantionului.
Din acest motiv, scopul setului de testare este de a verifica probleme precum supraadaptarea și de a fi mai încrezător că modelul dvs. este cu adevărat potrivit pentru a funcționa în lumea reală.
Recunoașterea imaginilor cu un CNN
Am acoperit multe până acum, iar dacă toate aceste informații au fost puțin copleșitoare, văzând aceste concepte reunite într-un exemplu de clasificator antrenat pe un set de date ar trebui să facă aceste concepte mai concrete. Așa că haideți să analizăm un exemplu complet de recunoaștere a imaginilor cu Keras, de la încărcarea datelor până la evaluare.

Credit: www.cs.toronto.edu
Pentru început, vom avea nevoie de un set de date pe care să ne antrenăm. În acest exemplu, vom folosi celebrul set de date CIFAR-10. CIFAR-10 este un set de date de imagini de mari dimensiuni care conține peste 60.000 de imagini reprezentând 10 clase diferite de obiecte, cum ar fi pisici, avioane și mașini.
Imaginile sunt full-color RGB, dar sunt destul de mici, doar 32 x 32. Un lucru grozav la setul de date CIFAR-10 este că vine preambalat cu Keras, deci este foarte ușor de încărcat setul de date, iar imaginile au nevoie de foarte puțină preprocesare.
Primul lucru pe care ar trebui să-l facem este să importăm bibliotecile necesare. Voi arăta cum sunt folosite aceste importuri pe măsură ce avansăm, dar deocamdată să știți că vom folosi Numpy, și diverse module asociate cu Keras:
import numpyfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activationfrom keras.layers.convolutional import Conv2D, MaxPooling2Dfrom keras.constraints import maxnormfrom keras.utils import np_utilsVom folosi aici o sămânță aleatorie, astfel încât rezultatele obținute în acest articol să poată fi replicate de dumneavoastră, motiv pentru care avem nevoie de numpy:
# Set random seed for purposes of reproducibilityseed = 21Pregătirea datelor
Avem nevoie de încă un import: setul de date.
from keras.datasets import cifar10Acum să încărcăm setul de date. Putem face acest lucru pur și simplu specificând variabilele în care dorim să încărcăm datele și apoi folosind funcția load_data():
# loading in the data (X_train, y_train), (X_test, y_test) = cifar10.load_data()În cele mai multe cazuri va trebui să faceți o preprocesare a datelor pentru a le pregăti pentru utilizare, dar deoarece folosim un set de date preambalat, este nevoie de o preprocesare foarte mică. Un lucru pe care dorim să îl facem este să normalizăm datele de intrare.
Dacă valorile datelor de intrare se află într-un interval prea larg, acest lucru poate avea un impact negativ asupra modului în care funcționează rețeaua. În acest caz, valorile de intrare sunt pixelii din imagine, care au o valoare cuprinsă între 0 și 255.
Așa că, pentru a normaliza datele, putem pur și simplu să împărțim valorile imaginii la 255. Pentru a face acest lucru, trebuie mai întâi să transformăm datele într-un tip float, deoarece în prezent acestea sunt numere întregi. Putem face acest lucru folosind comanda astype() Numpy și apoi declarând ce tip de date dorim:
# normalize the inputs from 0-255 to between 0 and 1 by dividing by 255 X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = X_train / 255.0X_test = X_test / 255.0Un alt lucru pe care va trebui să îl facem pentru a pregăti datele pentru rețea este să codificăm valorile într-un singur rând. Nu voi intra aici în specificul codificării one-hot, dar deocamdată să știți că imaginile nu pot fi folosite de rețea așa cum sunt, ele trebuie să fie mai întâi codificate, iar codificarea one-hot este cel mai bine folosită atunci când se face clasificare binară.
Efectiv facem clasificare binară aici, deoarece o imagine fie aparține unei clase, fie nu, nu se poate încadra undeva la mijloc. Comanda Numpy to_categorical() este folosită pentru codificarea one-hot. Acesta este motivul pentru care am importat funcția np_utils din Keras, deoarece conține to_categorical().
De asemenea, trebuie să specificăm numărul de clase care se află în setul de date, astfel încât să știm la câți neuroni să comprimăm stratul final:
# one hot encode outputsy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)class_num = y_test.shapeDesigning the Model
Am ajuns la etapa în care proiectăm modelul CNN. Primul lucru pe care trebuie să îl facem este să definim formatul pe care dorim să îl folosim pentru model, Keras are mai multe formate diferite sau planuri pe care să construim modele, dar Sequential este cel mai des folosit și, din acest motiv, l-am importat din Keras.
Crearea modelului
model = Sequential()Primul strat al modelului nostru este un strat convoluțional. Acesta va prelua intrările și va rula filtre convoluționale pe ele.
Când implementăm acestea în Keras, trebuie să specificăm numărul de canale/filtre pe care îl dorim (este vorba de cele 32 de mai jos), dimensiunea filtrului pe care îl dorim (3 x 3 în acest caz), forma intrării (la crearea primului strat) și activarea și umplutura de care avem nevoie.
După cum am menționat, relu este cea mai obișnuită activare, iar padding='same' înseamnă doar că nu schimbăm deloc dimensiunea imaginii:
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape, padding='same'))model.add(Activation('relu'))Nota: Puteți, de asemenea, să înșiruiți activările și acumulările împreună, astfel:
model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), activation='relu', padding='same'))Acum vom face un strat de eliminare pentru a preveni supraadaptarea, care funcționează prin eliminarea aleatorie a unora dintre conexiunile dintre straturi (0.2 înseamnă că elimină 20% din conexiunile existente):
model.add(Dropout(0.2))De asemenea, este posibil să dorim să facem aici o normalizare pe loturi. Normalizarea lotului normalizează intrările care se îndreaptă spre stratul următor, asigurându-se că rețeaua creează întotdeauna activări cu aceeași distribuție pe care o dorim:
model.add(BatchNormalization())Acum vine un alt strat convoluțional, dar dimensiunea filtrului crește astfel încât rețeaua să poată învăța reprezentări mai complexe:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))Aici este stratul de punere în comun, așa cum am discutat înainte, acesta ajută la a face clasificatorul de imagini mai robust, astfel încât să poată învăța modele relevante. Există, de asemenea, abandonul și normalizarea loturilor:
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization())Acesta este fluxul de bază pentru prima jumătate a unei implementări CNN: Convolutional, activare, droppout, pooling. Acum puteți vedea de ce am importat Dropout, BatchNormalization, Activation, Conv2d și MaxPooling2d.
Puteți varia numărul exact de straturi convoluționale pe care le aveți după bunul dumneavoastră plac, deși fiecare adaugă mai multe cheltuieli de calcul. Observați că, pe măsură ce adăugați straturi convoluționale, creșteți de obicei numărul de filtre ale acestora, astfel încât modelul să poată învăța reprezentări mai complexe. Dacă numerele alese pentru aceste straturi vi se par oarecum arbitrare, trebuie doar să știți că, în general, creșteți filtrele pe măsură ce avansați și este recomandat să le faceți puteri de 2, ceea ce poate acorda un ușor beneficiu atunci când vă antrenați pe un GPU.
Este important să nu aveți prea multe straturi de punere în comun, deoarece fiecare punere în comun aruncă unele date. Punerea în comun prea des va duce la faptul că straturile dens conectate nu vor avea aproape nimic de învățat atunci când datele ajung la ele.
Numărul exact de straturi de punere în comun pe care ar trebui să le folosiți va varia în funcție de sarcina pe care o realizați și este un lucru pe care îl veți simți în timp. Din moment ce imaginile sunt deja atât de mici aici, nu vom face pooling mai mult de două ori.
Acum puteți repeta aceste straturi pentru a oferi rețelei dvs. mai multe reprezentări pe baza cărora să lucreze:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())După ce am terminat cu straturile convoluționale, trebuie să Flatten datele, motiv pentru care am importat funcția de mai sus. De asemenea, vom adăuga din nou un strat de abandonare:
model.add(Flatten())model.add(Dropout(0.2))Acum ne folosim de importul Dense și creăm primul strat conectat dens. Trebuie să specificăm numărul de neuroni din stratul dens. Observați că numărul de neuroni din straturile succesive scade, apropiindu-se în cele din urmă de același număr de neuroni ca și numărul de clase din setul de date (în acest caz, 10). Constrângerea kernelului poate regulariza datele pe măsură ce învață, un alt lucru care ajută la prevenirea supraadaptării. Acesta este motivul pentru care am importat maxnorm mai devreme.
model.add(Dense(256, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Dense(128, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())În acest strat final, trecem numărul de clase pentru numărul de neuroni. Fiecare neuron reprezintă o clasă, iar ieșirea acestui strat va fi un vector de 10 neuroni, fiecare neuron stocând o anumită probabilitate ca imaginea în cauză să aparțină clasei pe care o reprezintă.
În cele din urmă, funcția de activare softmax selectează neuronul cu cea mai mare probabilitate ca ieșire, votând că imaginea aparține acelei clase:
model.add(Dense(class_num))model.add(Activation('softmax'))Acum că am proiectat modelul pe care dorim să îl folosim, trebuie doar să îl compilăm. Să specificăm numărul de epoci pentru care dorim să ne antrenăm, precum și optimizatorul pe care dorim să îl folosim.
Optimizatorul este cel care va regla greutățile din rețeaua dumneavoastră pentru a se apropia de punctul cu cea mai mică pierdere. Algoritmul Adam este unul dintre cei mai frecvent utilizați optimizatori, deoarece oferă performanțe deosebite în majoritatea problemelor:
epochs = 25optimizer = 'adam'Să compilăm acum modelul cu parametrii aleși de noi. Să specificăm, de asemenea, o metrică de utilizat.
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=)Puteți imprima rezumatul modelului pentru a vedea cum arată întregul model.
print(model.summary())Imprimarea rezumatului ne va oferi destul de multe informații:
Results: Layer (type) Output Shape Param #=================================================================conv2d_1 (Conv2D) (None, 32, 32, 32) 896_________________________________________________________________activation_1 (Activation) (None, 32, 32, 32) 0_________________________________________________________________dropout_1 (Dropout) (None, 32, 32, 32) 0_________________________________________________________________batch_normalization_1 (Batch (None, 32, 32, 32) 128_________________________________________________________________conv2d_2 (Conv2D) (None, 32, 32, 64) 18496_________________________________________________________________activation_2 (Activation) (None, 32, 32, 64) 0_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0_________________________________________________________________dropout_2 (Dropout) (None, 16, 16, 64) 0_________________________________________________________________batch_normalization_2 (Batch (None, 16, 16, 64) 256_________________________________________________________________conv2d_3 (Conv2D) (None, 16, 16, 64) 36928_________________________________________________________________activation_3 (Activation) (None, 16, 16, 64) 0_________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0_________________________________________________________________dropout_3 (Dropout) (None, 8, 8, 64) 0_________________________________________________________________batch_normalization_3 (Batch (None, 8, 8, 64) 256_________________________________________________________________conv2d_4 (Conv2D) (None, 8, 8, 128) 73856_________________________________________________________________activation_4 (Activation) (None, 8, 8, 128) 0_________________________________________________________________dropout_4 (Dropout) (None, 8, 8, 128) 0_________________________________________________________________batch_normalization_4 (Batch (None, 8, 8, 128) 512_________________________________________________________________flatten_1 (Flatten) (None, 8192) 0_________________________________________________________________dropout_5 (Dropout) (None, 8192) 0_________________________________________________________________dense_1 (Dense) (None, 256) 2097408_________________________________________________________________activation_5 (Activation) (None, 256) 0_________________________________________________________________dropout_6 (Dropout) (None, 256) 0_________________________________________________________________batch_normalization_5 (Batch (None, 256) 1024_________________________________________________________________dense_2 (Dense) (None, 128) 32896_________________________________________________________________activation_6 (Activation) (None, 128) 0_________________________________________________________________dropout_7 (Dropout) (None, 128) 0_________________________________________________________________batch_normalization_6 (Batch (None, 128) 512_________________________________________________________________dense_3 (Dense) (None, 10) 1290_________________________________________________________________activation_7 (Activation) (None, 10) 0=================================================================Total params: 2,264,458Trainable params: 2,263,114Non-trainable params: 1,344Acum trecem la antrenarea modelului. Pentru a face acest lucru, tot ce trebuie să facem este să apelăm funcția fit() pe model și să trecem în parametrii aleși.
Aici folosesc sămânța pe care am ales-o, în scopul reproductibilității.
numpy.random.seed(seed)model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)Ne vom antrena pe 50000 de eșantioane și vom valida pe 10000 de eșantioane.
Executarea acestei bucăți de cod va produce:
Epoch 1/2564/50000 - ETA: 16:57 - loss: 3.1479 - acc: 0.0938128/50000 - ETA: 10:12 - loss: 3.0212 - acc: 0.0938192/50000 - ETA: 7:57 - loss: 2.9781 - acc: 0.1250256/50000 - ETA: 6:48 - loss: 2.8830 - acc: 0.1484320/50000 - ETA: 6:07 - loss: 2.8878 - acc: 0.1469384/50000 - ETA: 5:40 - loss: 2.8732 - acc: 0.1458448/50000 - ETA: 5:20 - loss: 2.8842 - acc: 0.1406.........49664/50000 - ETA: 1s - loss: 1.5160 - acc: 0.461149728/50000 - ETA: 1s - loss: 1.5157 - acc: 0.461249792/50000 - ETA: 1s - loss: 1.5153 - acc: 0.461449856/50000 - ETA: 0s - loss: 1.5147 - acc: 0.461549920/50000 - ETA: 0s - loss: 1.5144 - acc: 0.461749984/50000 - ETA: 0s - loss: 1.5141 - acc: 0.461750000/50000 - 262s 5ms/step - loss: 1.5140 - acc: 0.4618 - val_loss: 1.0715 - val_acc: 0.6195End of Epoch 1Rețineți că, în cele mai multe cazuri, veți dori să aveți un set de validare care este diferit de setul de testare și, prin urmare, veți specifica un procent din datele de instruire care să fie utilizat ca set de validare. În acest caz, vom trece doar datele de testare pentru a ne asigura că datele de testare sunt puse deoparte și nu sunt antrenate. Vom avea doar date de testare în acest exemplu, pentru a păstra lucrurile simple.
Acum putem evalua modelul și să vedem cum a funcționat. Trebuie doar să apelăm model.evaluate():
# Model evaluationscores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%" % (scores*100))Și suntem întâmpinați cu rezultatul:
Accuracy: 83.01%Și asta e tot! Acum avem un CNN antrenat pentru recunoașterea imaginilor. Nu este rău pentru prima execuție, dar probabil că ați dori să vă jucați cu structura și parametrii modelului pentru a vedea dacă nu puteți obține performanțe mai bune.
Concluzie
Acum că ați implementat prima rețea de recunoaștere a imaginilor în Keras, ar fi o idee bună să vă jucați cu modelul și să vedeți cum modificarea parametrilor săi afectează performanța acestuia.
Aceasta vă va da o oarecare intuiție cu privire la cele mai bune alegeri pentru diferiți parametri ai modelului. De asemenea, ar trebui să citiți despre diferitele alegeri de parametri și hiper-parametri în timp ce faceți acest lucru. După ce vă simțiți confortabil cu acestea, puteți încerca să vă implementați propriul clasificator de imagini pe un set de date diferit.
Dacă doriți să vă jucați cu codul sau pur și simplu să-l studiați puțin mai profund, proiectul este încărcat pe GitHub!
.