- Introducción
- Definiciones
- TensorFlow/Keras
- Reconocimiento de imágenes (clasificación)
- Extracción de características
- Cómo las redes neuronales aprenden a reconocer imágenes
- Extracción de características con filtros
- Funciones de activación
- Capas de agrupación
- Flattening
- Capa totalmente conectada
- El flujo de trabajo del aprendizaje automático
- Preparación de los datos
- Creación del modelo
- Entrenar el modelo
- Evaluación del modelo
- Reconocimiento de imágenes con una CNN
- Preparar los datos
- Diseño del modelo
- Crear el modelo
- Conclusión
Introducción
Una de las utilizaciones más comunes de TensorFlow y Keras es el reconocimiento/clasificación de imágenes. Si quieres aprender a utilizar Keras para clasificar o reconocer imágenes, este artículo te enseñará cómo hacerlo.
Definiciones
Si no tienes claros los conceptos básicos que hay detrás del reconocimiento de imágenes, te será difícil entender completamente el resto de este artículo. Así que antes de seguir adelante, tomemos un momento para definir algunos términos.
TensorFlow/Keras

Credit: commons.wikimedia.org
TensorFlow es una biblioteca de código abierto creada para Python por el equipo de Google Brain. TensorFlow compila muchos algoritmos y modelos diferentes juntos, permitiendo al usuario implementar redes neuronales profundas para su uso en tareas como el reconocimiento/clasificación de imágenes y el procesamiento del lenguaje natural. TensorFlow es un potente marco de trabajo que funciona implementando una serie de nodos de procesamiento, cada nodo representando una operación matemática, siendo la serie completa de nodos llamada «grafo».
En cuanto a Keras, es una API (interfaz de programación de aplicaciones) de alto nivel que puede utilizar las funciones de TensorFlow por debajo (así como otras bibliotecas de ML como Theano). Keras fue diseñado con la facilidad de uso y la modularidad como sus principios rectores. En términos prácticos, Keras hace que la implementación de las muchas funciones poderosas pero a menudo complejas de TensorFlow sea lo más simple posible, y está configurado para trabajar con Python sin ninguna modificación o configuración importante.
Reconocimiento de imágenes (clasificación)
El reconocimiento de imágenes se refiere a la tarea de introducir una imagen en una red neuronal y hacer que esta produzca algún tipo de etiqueta para esa imagen. La etiqueta que la red emite corresponderá a una clase predefinida. Puede haber varias clases a las que la imagen pueda ser etiquetada, o sólo una. Si hay una sola clase, se suele aplicar el término «reconocimiento», mientras que una tarea de reconocimiento de varias clases se suele llamar «clasificación».
Un subconjunto de la clasificación de imágenes es la detección de objetos, en la que se identifican instancias específicas de objetos como pertenecientes a una determinada clase, como animales, coches o personas.
Extracción de características
Para llevar a cabo el reconocimiento/clasificación de imágenes, la red neuronal debe realizar la extracción de características. Las características son los elementos de los datos que le interesan y que serán alimentados por la red. En el caso concreto del reconocimiento de imágenes, las características son los grupos de píxeles, como los bordes y los puntos, de un objeto que la red analizará en busca de patrones.
El reconocimiento de características (o la extracción de características) es el proceso de extraer las características relevantes de una imagen de entrada para poder analizarlas. Muchas imágenes contienen anotaciones o metadatos sobre la imagen que ayudan a la red a encontrar las características relevantes.
Cómo las redes neuronales aprenden a reconocer imágenes
Intuir cómo una red neuronal reconoce las imágenes le ayudará cuando implemente un modelo de red neuronal, así que vamos a explorar brevemente el proceso de reconocimiento de imágenes en las siguientes secciones.
Extracción de características con filtros
Credit: commons.wikimedia.org
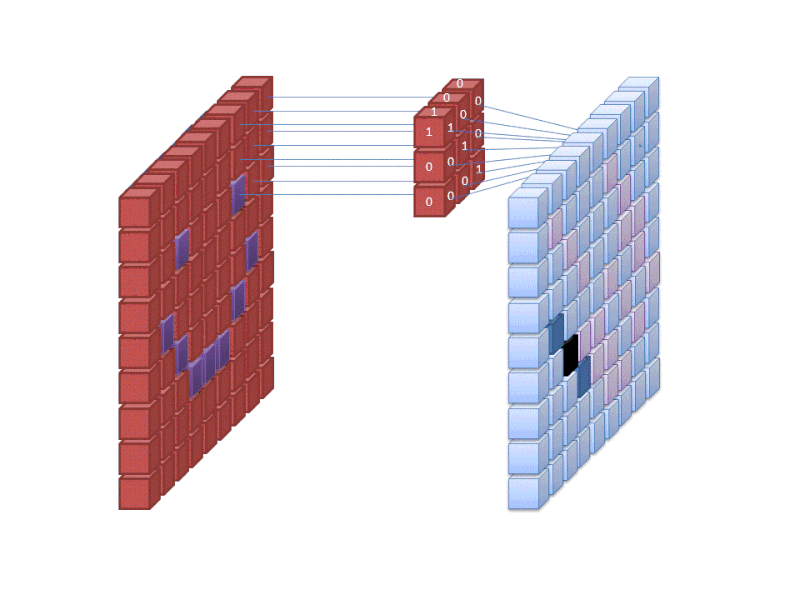
La primera capa de una red neuronal toma todos los píxeles de una imagen. Una vez introducidos todos los datos en la red, se aplican diferentes filtros a la imagen, que forman representaciones de diferentes partes de la misma. Esto es la extracción de características y crea «mapas de características».
Este proceso de extracción de características de una imagen se realiza con una «capa convolucional», y la convolución es simplemente formar una representación de parte de una imagen. De este concepto de convolución se deriva el término Red Neural Convolucional (CNN), el tipo de red neural más utilizado en la clasificación/reconocimiento de imágenes.
Si quiere visualizar cómo funciona la creación de mapas de características, piense en iluminar con una linterna una fotografía en una habitación oscura. A medida que se desliza el rayo sobre la foto, se van aprendiendo las características de la imagen. Un filtro es lo que la red utiliza para formar una representación de la imagen, y en esta metáfora, la luz de la linterna es el filtro.
La anchura del haz de la linterna controla la parte de la imagen que se examina a la vez, y las redes neuronales tienen un parámetro similar, el tamaño del filtro. El tamaño del filtro afecta a la parte de la imagen, el número de píxeles, que se examinan a la vez. Un tamaño de filtro común utilizado en las CNN es 3, y esto cubre tanto la altura como la anchura, por lo que el filtro examina un área de 3 x 3 píxeles.
Credit: commons.wikimedia.org
Mientras que el tamaño del filtro cubre la altura y la anchura del filtro, la profundidad del filtro también debe ser especificada.
¿Cómo tiene profundidad una imagen 2D?
Las imágenes digitales se representan como altura, anchura y algún valor RGB que define los colores del píxel, por lo que la «profundidad» que se rastrea es el número de canales de color que tiene la imagen. Las imágenes en escala de grises (sin color) sólo tienen 1 canal de color mientras que las imágenes en color tienen 3 canales de profundidad.
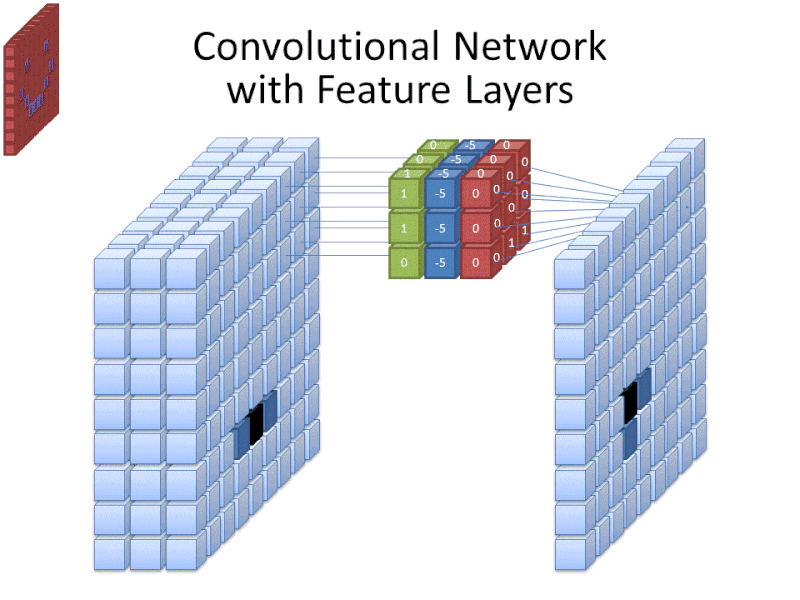
Todo esto significa que para un filtro de tamaño 3 aplicado a una imagen a todo color, las dimensiones de ese filtro serán 3 x 3 x 3. Para cada píxel cubierto por ese filtro, la red multiplica los valores del filtro con los valores de los propios píxeles para obtener una representación numérica de ese píxel. Este proceso se realiza entonces para toda la imagen para conseguir una representación completa. El filtro se desplaza por el resto de la imagen según un parámetro llamado «stride», que define cuántos píxeles debe desplazar el filtro después de calcular el valor en su posición actual. Un tamaño de stride convencional para una CNN es 2.
El resultado final de todo este cálculo es un mapa de características. Este proceso se realiza típicamente con más de un filtro, lo que ayuda a preservar la complejidad de la imagen.
Funciones de activación
Después de crear el mapa de características de la imagen, los valores que la representan pasan por una función de activación o capa de activación. La función de activación toma los valores que representan la imagen, que están en forma lineal (es decir, sólo una lista de números) gracias a la capa convolucional, y aumenta su no linealidad ya que las propias imágenes son no lineales.
La función de activación típica utilizada para lograr esto es una Unidad Lineal Rectificada (ReLU), aunque hay algunas otras funciones de activación que se utilizan ocasionalmente (puede leer sobre ellas aquí).
Capas de agrupación
Después de que los datos se activan, se envían a través de una capa de agrupación. El pooling «reduce la muestra» de una imagen, lo que significa que toma la información que representa la imagen y la comprime, haciéndola más pequeña. El proceso de pooling hace que la red sea más flexible y más hábil a la hora de reconocer objetos/imágenes basándose en las características relevantes.
Cuando miramos una imagen, normalmente no nos preocupa toda la información del fondo de la imagen, sólo las características que nos interesan, como personas o animales.
De manera similar, una capa de agrupación en una CNN abstraerá las partes innecesarias de la imagen, manteniendo sólo las partes de la imagen que considere relevantes, según lo controlado por el tamaño especificado de la capa de agrupación.
Debido a que tiene que tomar decisiones sobre las partes más relevantes de la imagen, la esperanza es que la red aprenda sólo las partes de la imagen que realmente representan el objeto en cuestión. Esto ayuda a evitar el sobreajuste, en el que la red aprende aspectos del caso de entrenamiento demasiado bien y no logra generalizar a los nuevos datos.
Credit: commons.wikimedia.org
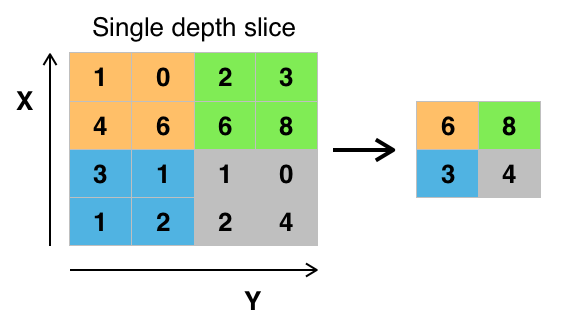
Hay varias formas de agrupar valores, pero la agrupación máxima es la más utilizada. Max pooling obtiene el valor máximo de los píxeles dentro de un solo filtro (dentro de un solo punto de la imagen). Esto deja caer 3/4 partes de la información, suponiendo que se utilizan 2 x 2 filtros.
Los valores máximos de los píxeles se utilizan para tener en cuenta las posibles distorsiones de la imagen, y los parámetros/tamaño de la imagen se reducen para controlar el exceso de ajuste. Existen otros tipos de pooling como el pooling promedio o el pooling de suma, pero no se utilizan con tanta frecuencia porque el pooling máximo tiende a producir una mayor precisión.
Flattening
Las capas finales de nuestra CNN, las capas densamente conectadas, requieren que los datos estén en forma de vector para ser procesados. Por esta razón, los datos deben ser «aplanados». Los valores se comprimen en un vector largo o en una columna de números ordenados secuencialmente.
Capa totalmente conectada
Las capas finales de la CNN son capas densamente conectadas, o una red neuronal artificial (RNA). La función principal de la RNA es analizar las características de entrada y combinarlas en diferentes atributos que ayudarán a la clasificación. Estas capas forman esencialmente colecciones de neuronas que representan diferentes partes del objeto en cuestión, y una colección de neuronas puede representar las orejas caídas de un perro o el color rojo de una manzana. Cuando un número suficiente de estas neuronas se activa en respuesta a una imagen de entrada, la imagen se clasificará como un objeto.

Crédito: commons.wikimedia.org
El error, o la diferencia entre los valores computados y el valor esperado en el conjunto de entrenamiento, es calculado por la RNA. A continuación, la red se somete a la retropropagación, en la que se calcula la influencia de una neurona determinada sobre una neurona de la capa siguiente y se ajusta su influencia. Esto se hace para optimizar el rendimiento del modelo. Este proceso se repite una y otra vez. Así es como la red se entrena en los datos y aprende las asociaciones entre las características de entrada y las clases de salida.
Las neuronas de las capas intermedias totalmente conectadas darán salida a valores binarios relacionados con las posibles clases. Si hay cuatro clases diferentes (digamos un perro, un coche, una casa y una persona), la neurona tendrá un valor «1» para la clase que cree que representa la imagen y un valor «0» para las otras clases.
La última capa totalmente conectada recibirá la salida de la capa anterior y entregará una probabilidad para cada una de las clases, sumando uno. Si hay un valor de 0,75 en la categoría «perro», representa un 75% de certeza de que la imagen es un perro.
El clasificador de imágenes ha sido entrenado, y las imágenes se pueden pasar a la CNN, que ahora emitirá una conjetura sobre el contenido de esa imagen.
El flujo de trabajo del aprendizaje automático
Antes de pasar a un ejemplo de entrenamiento de un clasificador de imágenes, tomemos un momento para entender el flujo de trabajo del aprendizaje automático o pipeline. El proceso para el entrenamiento de un modelo de red neuronal es bastante estándar y se puede dividir en cuatro fases diferentes.
Preparación de los datos
En primer lugar, usted tendrá que recoger sus datos y ponerlos en una forma que la red pueda entrenar. Esto implica recopilar imágenes y etiquetarlas. Incluso si usted ha descargado un conjunto de datos que alguien ha preparado, es probable que haya un preprocesamiento o preparación que debe hacer antes de que pueda utilizarlo para el entrenamiento. La preparación de los datos es un arte en sí mismo, que implica tratar con cosas como los valores perdidos, los datos corruptos, los datos en el formato incorrecto, las etiquetas incorrectas, etc.
En este artículo, vamos a utilizar un conjunto de datos preprocesados.
Creación del modelo
La creación del modelo de red neuronal implica la toma de decisiones sobre varios parámetros e hiperparámetros. Debe tomar decisiones sobre el número de capas a utilizar en su modelo, cuáles serán los tamaños de entrada y salida de las capas, qué tipo de funciones de activación utilizará, si utilizará o no dropout, etc.
Aprender qué parámetros e hiperparámetros utilizar vendrá con el tiempo (y un montón de estudio), pero desde el principio hay algunas heurísticas que puede utilizar para empezar a correr y vamos a cubrir algunos de estos durante el ejemplo de implementación.
Entrenar el modelo
Después de haber creado su modelo, sólo tiene que crear una instancia del modelo y ajustarlo con sus datos de entrenamiento. La mayor consideración cuando se entrena un modelo es la cantidad de tiempo que el modelo toma para entrenar. Puedes especificar la duración del entrenamiento de una red especificando el número de épocas de entrenamiento. Cuanto más tiempo se entrene un modelo, mayor será su rendimiento, pero demasiadas épocas de entrenamiento y se corre el riesgo de sobreajustar.
La elección del número de épocas para entrenar es algo que se va a conseguir, y se acostumbra a guardar los pesos de una red entre las sesiones de entrenamiento para no tener que empezar de nuevo una vez que se ha hecho algún progreso en el entrenamiento de la red.
Evaluación del modelo
Hay varios pasos para evaluar el modelo. El primer paso en la evaluación del modelo es comparar el rendimiento del modelo contra un conjunto de datos de validación, un conjunto de datos que el modelo no ha sido entrenado. Usted comparará el rendimiento del modelo contra este conjunto de validación y analizará su rendimiento a través de diferentes métricas.
Hay varias métricas para determinar el rendimiento de un modelo de red neuronal, pero la métrica más común es la «precisión», la cantidad de imágenes clasificadas correctamente dividida por el número total de imágenes en su conjunto de datos.
Después de haber visto la precisión del rendimiento del modelo en un conjunto de datos de validación, normalmente volverá a entrenar la red utilizando parámetros ligeramente ajustados, porque es poco probable que esté satisfecho con el rendimiento de su red la primera vez que se entrena. Seguirá ajustando los parámetros de su red, reentrenándola y midiendo su rendimiento hasta que esté satisfecho con la precisión de la red.
Por último, probará el rendimiento de la red en un conjunto de pruebas. Este conjunto de pruebas es otro conjunto de datos que su modelo nunca ha visto antes.
Tal vez se pregunte:
¿Por qué molestarse con el conjunto de pruebas? Si está obteniendo una idea de la precisión de su modelo, ¿no es ése el propósito del conjunto de validación?
Es una buena idea mantener un lote de datos que la red nunca ha visto para las pruebas porque todo el ajuste de los parámetros que hace, combinado con la repetición de las pruebas en el conjunto de validación, podría significar que su red ha aprendido algunas idiosincrasias del conjunto de validación que no se generalizarán a los datos fuera de la muestra.
Por lo tanto, el propósito del conjunto de pruebas es comprobar los problemas como el sobreajuste y estar más seguro de que su modelo es realmente apto para funcionar en el mundo real.
Reconocimiento de imágenes con una CNN
Hemos cubierto mucho hasta ahora, y si toda esta información ha sido un poco abrumadora, ver estos conceptos reunidos en un clasificador de ejemplo entrenado en un conjunto de datos debería hacer estos conceptos más concretos. Así que veamos un ejemplo completo de reconocimiento de imágenes con Keras, desde la carga de los datos hasta la evaluación.

Credit: www.cs.toronto.edu
Para empezar, necesitaremos un conjunto de datos sobre el que entrenar. En este ejemplo, utilizaremos el famoso conjunto de datos CIFAR-10. CIFAR-10 es un gran conjunto de datos de imágenes que contiene más de 60.000 imágenes que representan 10 clases diferentes de objetos como gatos, aviones y coches.
Las imágenes son RGB a todo color, pero son bastante pequeñas, sólo 32 x 32. Una gran cosa sobre el conjunto de datos CIFAR-10 es que viene preempaquetado con Keras, por lo que es muy fácil cargar el conjunto de datos y las imágenes necesitan muy poco preprocesamiento.
Lo primero que debemos hacer es importar las bibliotecas necesarias. Mostraré cómo se utilizan estas importaciones a medida que avancemos, pero por ahora sabed que haremos uso de Numpy, y de varios módulos asociados a Keras:
import numpyfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activationfrom keras.layers.convolutional import Conv2D, MaxPooling2Dfrom keras.constraints import maxnormfrom keras.utils import np_utilsAquí vamos a utilizar una semilla aleatoria para que los resultados conseguidos en este artículo puedan ser replicados por vosotros, por lo que necesitamos numpy:
# Set random seed for purposes of reproducibilityseed = 21Preparar los datos
Necesitamos una importación más: el dataset.
from keras.datasets import cifar10Ahora vamos a cargar el conjunto de datos. Podemos hacerlo simplemente especificando en qué variables queremos cargar los datos, y luego usando la función load_data():
# loading in the data (X_train, y_train), (X_test, y_test) = cifar10.load_data()En la mayoría de los casos necesitarás hacer algún preprocesamiento de tus datos para tenerlos listos para su uso, pero como estamos usando un conjunto de datos preempacado, se necesita hacer muy poco preprocesamiento. Una de las cosas que queremos hacer es normalizar los datos de entrada.
Si los valores de los datos de entrada están en un rango demasiado amplio puede afectar negativamente al rendimiento de la red. En este caso, los valores de entrada son los píxeles de la imagen, que tienen un valor entre 0 y 255.
Así que para normalizar los datos podemos simplemente dividir los valores de la imagen entre 255. Para ello primero tenemos que hacer que los datos sean de tipo float, ya que actualmente son enteros. Podemos hacer esto usando el comando astype() Numpy y luego declarando qué tipo de datos queremos:
# normalize the inputs from 0-255 to between 0 and 1 by dividing by 255 X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = X_train / 255.0X_test = X_test / 255.0Otra cosa que tendremos que hacer para tener los datos listos para la red es codificar los valores en un solo paso. No voy a entrar en los detalles de la codificación de una sola vez, pero por ahora sabemos que las imágenes no pueden ser utilizadas por la red tal como son, tienen que ser codificadas primero y la codificación de una sola vez se utiliza mejor cuando se hace la clasificación binaria.
Estamos haciendo efectivamente la clasificación binaria aquí porque una imagen o pertenece a una clase o no, no puede caer en algún punto intermedio. El comando Numpy to_categorical() se utiliza para codificar una sola vez. Por eso importamos la función np_utils de Keras, ya que contiene to_categorical().
También tenemos que especificar el número de clases que hay en el conjunto de datos, para saber a cuántas neuronas hay que comprimir la capa final:
# one hot encode outputsy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)class_num = y_test.shapeDiseño del modelo
Hemos llegado a la fase de diseño del modelo CNN. Lo primero que hay que hacer es definir el formato que queremos utilizar para el modelo, Keras tiene varios formatos o blueprints diferentes para construir modelos, pero Sequential es el más utilizado, y por eso, lo hemos importado de Keras.
Crear el modelo
model = Sequential()La primera capa de nuestro modelo es una capa convolucional. Tomará las entradas y ejecutará filtros convolucionales sobre ellas.
A la hora de implementarlas en Keras, tenemos que especificar el número de canales/filtros que queremos (son los 32 de abajo), el tamaño del filtro que queremos (3 x 3 en este caso), la forma de la entrada (al crear la primera capa) y la activación y el relleno que necesitamos.
Como ya hemos mencionado, relu es la activación más común, y padding='same' sólo significa que no estamos cambiando el tamaño de la imagen en absoluto:
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape, padding='same'))model.add(Activation('relu'))Nota: También puedes encadenar las activaciones y los acolchados, así:
model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), activation='relu', padding='same'))Ahora haremos una capa de abandono para evitar el sobreajuste, que funciona eliminando aleatoriamente algunas de las conexiones entre las capas (0.2 significa que elimina el 20% de las conexiones existentes):
model.add(Dropout(0.2))También podemos querer hacer la normalización por lotes aquí. La normalización por lotes normaliza las entradas que se dirigen a la siguiente capa, asegurando que la red siempre crea activaciones con la misma distribución que deseamos:
model.add(BatchNormalization())Ahora viene otra capa convolucional, pero el tamaño del filtro aumenta para que la red pueda aprender representaciones más complejas:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))Aquí está la capa de agrupación, como se discutió antes esto ayuda a que el clasificador de imágenes sea más robusto para que pueda aprender patrones relevantes. También está el dropout y la normalización de lotes:
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization())Este es el flujo básico de la primera mitad de la implementación de una CNN: Convolucional, activación, dropout, pooling. Ahora puedes ver por qué hemos importado Dropout, BatchNormalization, Activation, Conv2d, y MaxPooling2d.
Puedes variar el número exacto de capas convolucionales que tienes a tu gusto, aunque cada una añade más gastos de computación. Ten en cuenta que a medida que añades capas convolucionales su número de filtros suele aumentar para que el modelo pueda aprender representaciones más complejas. Si los números elegidos para estas capas parecen algo arbitrarios, sólo hay que saber que, en general, se aumentan los filtros a medida que se avanza y se aconseja que sean potencias de 2, lo que puede otorgar un ligero beneficio cuando se entrena en una GPU.
Es importante no tener demasiadas capas de agrupación, ya que cada agrupación descarta algunos datos. Si se agrupa con demasiada frecuencia, las capas densamente conectadas no tendrán casi nada que aprender cuando los datos lleguen a ellas.
El número exacto de capas de agrupación que se debe utilizar variará en función de la tarea que se esté realizando, y es algo que se irá comprendiendo con el tiempo. Dado que las imágenes son tan pequeñas aquí ya no vamos a la piscina más de dos veces.
Ahora puede repetir estas capas para dar a su red más representaciones para trabajar fuera de:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Después de que hayamos terminado con las capas convolucionales, tenemos que Flatten los datos, por lo que hemos importado la función anterior. También vamos a añadir una capa de abandono de nuevo:
model.add(Flatten())model.add(Dropout(0.2))Ahora hacemos uso de la importación de Dense y creamos la primera capa densamente conectada. Tenemos que especificar el número de neuronas en la capa densa. Obsérvese que el número de neuronas en las capas sucesivas disminuye, acercándose finalmente al mismo número de neuronas que hay en el conjunto de datos (en este caso 10). La restricción del núcleo puede regularizar los datos a medida que aprende, otra cosa que ayuda a evitar el sobreajuste. Por eso importamos antes maxnorm.
model.add(Dense(256, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Dense(128, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())En esta capa final, pasamos el número de clases por el número de neuronas. Cada neurona representa una clase, y la salida de esta capa será un vector de 10 neuronas con cada una de ellas almacenando alguna probabilidad de que la imagen en cuestión pertenezca a la clase que representa.
Por último, la función de activación softmax selecciona como salida la neurona con mayor probabilidad, votando que la imagen pertenece a esa clase:
model.add(Dense(class_num))model.add(Activation('softmax'))Ahora que hemos diseñado el modelo que queremos utilizar, sólo tenemos que compilarlo. Especifiquemos el número de épocas que queremos entrenar, así como el optimizador que queremos utilizar.
El optimizador es el que afinará los pesos de tu red para acercarse al punto de menor pérdida. El algoritmo Adam es uno de los optimizadores más utilizados porque da un gran rendimiento en la mayoría de los problemas:
epochs = 25optimizer = 'adam'Compilemos ahora el modelo con los parámetros que hemos elegido. Especifiquemos también una métrica a utilizar.
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=)Podemos imprimir el resumen del modelo para ver cómo es el modelo completo.
print(model.summary())Imprimir el resumen nos dará bastante información:
Results: Layer (type) Output Shape Param #=================================================================conv2d_1 (Conv2D) (None, 32, 32, 32) 896_________________________________________________________________activation_1 (Activation) (None, 32, 32, 32) 0_________________________________________________________________dropout_1 (Dropout) (None, 32, 32, 32) 0_________________________________________________________________batch_normalization_1 (Batch (None, 32, 32, 32) 128_________________________________________________________________conv2d_2 (Conv2D) (None, 32, 32, 64) 18496_________________________________________________________________activation_2 (Activation) (None, 32, 32, 64) 0_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0_________________________________________________________________dropout_2 (Dropout) (None, 16, 16, 64) 0_________________________________________________________________batch_normalization_2 (Batch (None, 16, 16, 64) 256_________________________________________________________________conv2d_3 (Conv2D) (None, 16, 16, 64) 36928_________________________________________________________________activation_3 (Activation) (None, 16, 16, 64) 0_________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0_________________________________________________________________dropout_3 (Dropout) (None, 8, 8, 64) 0_________________________________________________________________batch_normalization_3 (Batch (None, 8, 8, 64) 256_________________________________________________________________conv2d_4 (Conv2D) (None, 8, 8, 128) 73856_________________________________________________________________activation_4 (Activation) (None, 8, 8, 128) 0_________________________________________________________________dropout_4 (Dropout) (None, 8, 8, 128) 0_________________________________________________________________batch_normalization_4 (Batch (None, 8, 8, 128) 512_________________________________________________________________flatten_1 (Flatten) (None, 8192) 0_________________________________________________________________dropout_5 (Dropout) (None, 8192) 0_________________________________________________________________dense_1 (Dense) (None, 256) 2097408_________________________________________________________________activation_5 (Activation) (None, 256) 0_________________________________________________________________dropout_6 (Dropout) (None, 256) 0_________________________________________________________________batch_normalization_5 (Batch (None, 256) 1024_________________________________________________________________dense_2 (Dense) (None, 128) 32896_________________________________________________________________activation_6 (Activation) (None, 128) 0_________________________________________________________________dropout_7 (Dropout) (None, 128) 0_________________________________________________________________batch_normalization_6 (Batch (None, 128) 512_________________________________________________________________dense_3 (Dense) (None, 10) 1290_________________________________________________________________activation_7 (Activation) (None, 10) 0=================================================================Total params: 2,264,458Trainable params: 2,263,114Non-trainable params: 1,344Ahora vamos a entrenar el modelo. Para ello, todo lo que tenemos que hacer es llamar a la función fit() sobre el modelo y pasar los parámetros elegidos.
Aquí es donde uso la semilla que elegí, a efectos de reproducibilidad.
numpy.random.seed(seed)model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)Estaremos entrenando en 50000 muestras y validando en 10000 muestras.
La ejecución de esta pieza de código dará como resultado:
Epoch 1/2564/50000 - ETA: 16:57 - loss: 3.1479 - acc: 0.0938128/50000 - ETA: 10:12 - loss: 3.0212 - acc: 0.0938192/50000 - ETA: 7:57 - loss: 2.9781 - acc: 0.1250256/50000 - ETA: 6:48 - loss: 2.8830 - acc: 0.1484320/50000 - ETA: 6:07 - loss: 2.8878 - acc: 0.1469384/50000 - ETA: 5:40 - loss: 2.8732 - acc: 0.1458448/50000 - ETA: 5:20 - loss: 2.8842 - acc: 0.1406.........49664/50000 - ETA: 1s - loss: 1.5160 - acc: 0.461149728/50000 - ETA: 1s - loss: 1.5157 - acc: 0.461249792/50000 - ETA: 1s - loss: 1.5153 - acc: 0.461449856/50000 - ETA: 0s - loss: 1.5147 - acc: 0.461549920/50000 - ETA: 0s - loss: 1.5144 - acc: 0.461749984/50000 - ETA: 0s - loss: 1.5141 - acc: 0.461750000/50000 - 262s 5ms/step - loss: 1.5140 - acc: 0.4618 - val_loss: 1.0715 - val_acc: 0.6195End of Epoch 1Nótese que en la mayoría de los casos, usted querrá tener un conjunto de validación que es diferente del conjunto de pruebas, por lo que especificaría un porcentaje de los datos de entrenamiento para utilizar como el conjunto de validación. En este caso, sólo pasaremos los datos de prueba para asegurarnos de que los datos de prueba se apartan y no se entrenan. Sólo tendremos datos de prueba en este ejemplo, con el fin de mantener las cosas simples.
Ahora podemos evaluar el modelo y ver cómo se desempeñó. Basta con llamar a model.evaluate():
# Model evaluationscores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%" % (scores*100))Y nos encontramos con el resultado:
Accuracy: 83.01%¡Y ya está! Ahora tenemos una CNN de reconocimiento de imágenes entrenada. No está mal para la primera ejecución, pero probablemente querrás jugar con la estructura y los parámetros del modelo para ver si puedes obtener un mejor rendimiento.
Conclusión
Ahora que has implementado tu primera red de reconocimiento de imágenes en Keras, sería una buena idea jugar con el modelo y ver cómo el cambio de sus parámetros afecta a su rendimiento.
Esto te dará alguna intuición sobre las mejores opciones para los diferentes parámetros del modelo. También debería leer sobre las diferentes opciones de parámetros e hiperparámetros mientras lo hace. Después de que te sientas cómodo con esto, puedes intentar implementar tu propio clasificador de imágenes en un conjunto de datos diferente.
Si quieres jugar con el código o simplemente estudiarlo un poco más a fondo, el proyecto está subido en GitHub!