- Introdução
- Definições
- TensorFlow/Keras
- Image Recognition (Classification)
- Exploração de características
- Como as redes neurais aprendem a reconhecer imagens
- Extração de características com filtros
- Funções de ativação
- Camadas de Ativação
- Alternância
- Camada totalmente ligada
- O Fluxo de Trabalho de Aprendizagem de Máquina
- Preparação de dados
- Criar o Modelo
- Training the Model
- Avaliação do modelo
- Image Recognition with a CNN
- Preparando os Dados
- Desenhando o Modelo
- Criar o Modelo
- Conclusion
Introdução
Uma das utilizações mais comuns de TensorFlow e Keras é o reconhecimento/classificação de imagens. Se você quiser aprender como usar Keras para classificar ou reconhecer imagens, este artigo irá ensiná-lo como.
Definições
Se você não estiver claro sobre os conceitos básicos por trás do reconhecimento de imagens, será difícil entender completamente o resto deste artigo. Portanto, antes de prosseguirmos, vamos tirar um momento para definir alguns termos.
TensorFlow/Keras

Credit: commons.wikimedia.org
TensorFlow é uma biblioteca de código aberto criada para Python pela equipe do Google Brain. TensorFlow compila muitos algoritmos e modelos diferentes juntos, permitindo ao usuário implementar redes neurais profundas para uso em tarefas como reconhecimento/classificação de imagens e processamento de linguagem natural. TensorFlow é um poderoso framework que funciona implementando uma série de nós de processamento, cada nó representando uma operação matemática, com toda a série de nós sendo chamada de “gráfico”.
Em termos de Keras, é uma API (interface de programação de aplicações) de alto nível que pode usar as funções de TensorFlow abaixo (assim como outras bibliotecas ML como Theano). O Keras foi projetado com a facilidade de uso e modularidade como seus princípios orientadores. Em termos práticos, Keras torna a implementação das muitas funções poderosas mas muitas vezes complexas de TensorFlow o mais simples possível, e está configurado para trabalhar com Python sem grandes modificações ou configurações.
Image Recognition (Classification)
Image recognition refere-se à tarefa de inserir uma imagem em uma rede neural e fazer com que ela produza algum tipo de rótulo para essa imagem. A etiqueta que a rede produz corresponderá a uma classe pré-definida. Pode haver múltiplas classes que a imagem pode ser etiquetada como, ou apenas uma. Se houver uma única classe, o termo “reconhecimento” é frequentemente aplicado, enquanto uma tarefa de reconhecimento de múltiplas classes é frequentemente chamada “classificação”.
Um subconjunto de classificação de imagens é a detecção de objetos, onde instâncias específicas de objetos são identificadas como pertencentes a uma determinada classe como animais, carros ou pessoas.
Exploração de características
Para realizar o reconhecimento/classificação de imagens, a rede neural deve realizar a extração de características. As características são os elementos dos dados que lhe interessam e que serão alimentados através da rede. No caso específico do reconhecimento de imagem, as características são os grupos de pixels, como bordas e pontos, de um objeto que a rede analisará para padrões.
O reconhecimento de característica (ou extração de característica) é o processo de extrair as características relevantes de uma imagem de entrada para que essas características possam ser analisadas. Muitas imagens contêm anotações ou metadados sobre a imagem que ajudam a rede a encontrar os recursos relevantes.
Como as redes neurais aprendem a reconhecer imagens
Conhecendo como uma rede neural reconhece imagens o ajudará quando você estiver implementando um modelo de rede neural, então vamos explorar brevemente o processo de reconhecimento de imagens nas próximas seções.
Extração de características com filtros
Crédito: commons.wikimedia.org
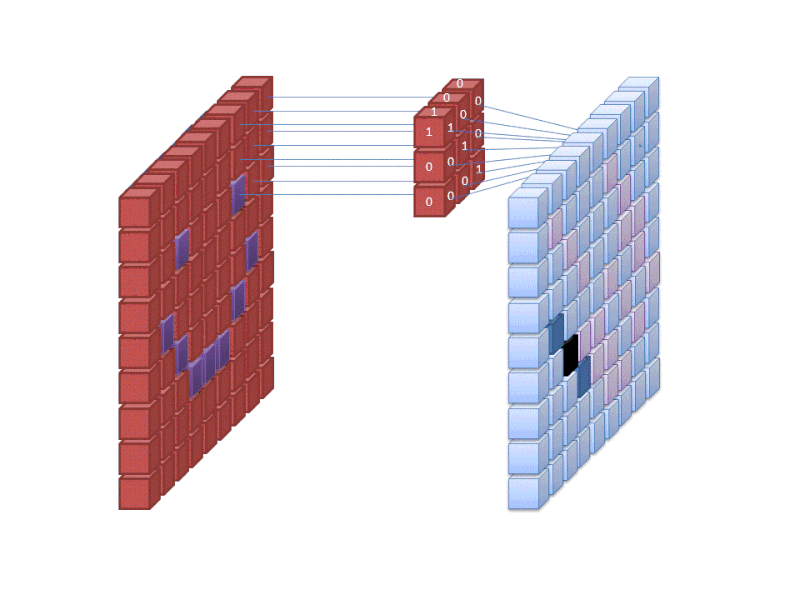
A primeira camada de uma rede neural absorve todos os pixels dentro de uma imagem. Depois de todos os dados terem sido introduzidos na rede, diferentes filtros são aplicados à imagem, que forma representações de diferentes partes da imagem. Este processo de extração de características de uma imagem é realizado com uma “camada convolucional”, e a convolução está simplesmente formando uma representação de parte de uma imagem. É a partir desse conceito de convolução que obtemos o termo Rede Neural Convolucional (CNN), o tipo de rede neural mais usado na classificação/reconhecimento de imagens.
Se você quiser visualizar como funciona a criação de mapas de recursos, pense em iluminar uma lanterna sobre uma imagem em uma sala escura. Ao deslizar o feixe sobre a imagem, você está aprendendo sobre as características da imagem. Um filtro é o que a rede usa para formar uma representação da imagem, e nesta metáfora, a luz da lanterna é o filtro.
A largura do feixe da sua lanterna controla quanto da imagem você examina de uma vez, e as redes neurais têm um parâmetro semelhante, o tamanho do filtro. O tamanho do filtro afeta quanto da imagem, quantos pixels estão sendo examinados de uma só vez. Um tamanho de filtro comum usado em CNNs é 3, e isso cobre tanto a altura quanto a largura, então o filtro examina uma área de 3 x 3 pixels.
Credit: commons.wikimedia.org
Embora o tamanho do filtro cubra a altura e largura do filtro, a profundidade do filtro também deve ser especificada.
Como é que uma imagem 2D tem profundidade?
As imagens digitais são renderizadas como altura, largura e algum valor RGB que define as cores do pixel, portanto a “profundidade” que está a ser rastreada é o número de canais de cor que a imagem tem. Imagens em tons de cinza (não coloridas) têm apenas 1 canal de cor enquanto imagens coloridas têm 3 canais de profundidade.
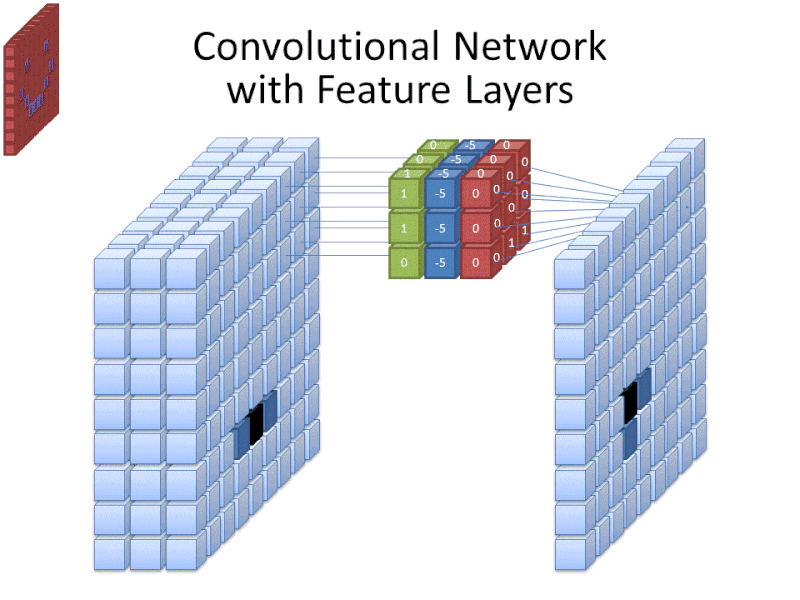
Tudo isto significa que para um filtro de tamanho 3 aplicado a uma imagem colorida, as dimensões desse filtro serão 3 x 3 x 3. Para cada pixel coberto por esse filtro, a rede multiplica os valores do filtro com os valores nos próprios pixels para obter uma representação numérica desse pixel. Este processo é então feito para que toda a imagem obtenha uma representação completa. O filtro é movido através do resto da imagem de acordo com um parâmetro chamado “stride”, que define quantos pixels o filtro deve ser movido depois de calcular o valor em sua posição atual. Um tamanho de stride convencional para uma CNN é 2.
O resultado final de todo este cálculo é um mapa de características. Este processo é normalmente feito com mais de um filtro, o que ajuda a preservar a complexidade da imagem.
Funções de ativação
Após o mapa de características da imagem ter sido criado, os valores que representam a imagem são passados através de uma função de ativação ou camada de ativação. A função de ativação toma valores que representam a imagem, que são de forma linear (ou seja, apenas uma lista de números) graças à camada convolutiva, e aumenta sua não-linearidade, uma vez que as imagens em si são não-lineares.
A típica função de ativação usada para realizar isto é uma Unidade Linear Retificada (ReLU), embora existam algumas outras funções de ativação que são usadas ocasionalmente (você pode ler sobre estas aqui).
Camadas de Ativação
Após os dados serem ativados, eles são enviados através de uma camada de agrupamento. O pooling “downsamples” é uma imagem, ou seja, pega a informação que representa a imagem e comprime-a, tornando-a mais pequena. O processo de pooling torna a rede mais flexível e mais apta a reconhecer objectos/imagens com base nas características relevantes.
Quando olhamos para uma imagem, normalmente não nos preocupamos com toda a informação no fundo da imagem, apenas com as características que nos interessam, tais como pessoas ou animais.
Similiarmente, uma camada de pooling numa CNN irá abstrair as partes desnecessárias da imagem, mantendo apenas as partes da imagem que considera relevantes, como controlada pelo tamanho especificado da camada de pooling.
Porque tem de tomar decisões sobre as partes mais relevantes da imagem, a esperança é que a rede aprenda apenas as partes da imagem que verdadeiramente representam o objecto em questão. Isto ajuda a prevenir o overfitting, onde a rede aprende muito bem aspectos do caso de treinamento e falha em generalizar para novos dados.
Credit: commons.wikimedia.org
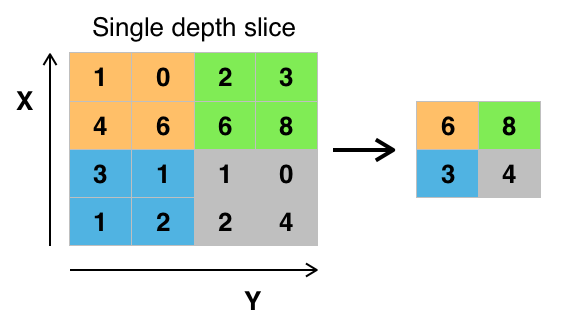
Existem várias maneiras de agrupar valores, mas o máximo de agrupamento é mais comumente usado. O pooling máximo obtém o valor máximo dos pixels dentro de um único filtro (dentro de um único ponto na imagem). Isto diminui 3/4 de informação, assumindo que 2 x 2 filtros estão sendo usados.
Os valores máximos dos pixels são usados a fim de contabilizar possíveis distorções na imagem, e os parâmetros/tamanho da imagem são reduzidos a fim de controlar o sobreajuste. Existem outros tipos de pooling, como o pooling médio ou o pooling de soma, mas estes não são utilizados com tanta frequência porque o pooling máximo tende a produzir uma melhor precisão.
Alternância
As camadas finais da nossa CNN, as camadas densamente conectadas, requerem que os dados estejam na forma de um vector a ser processado. Por este motivo, os dados devem ser “achatados”. Os valores são comprimidos num vector longo ou numa coluna de números ordenados sequencialmente.
Camada totalmente ligada
As camadas finais da CNN são camadas densamente ligadas, ou uma rede neural artificial (ANN). A função principal da ANN é analisar as características de entrada e combiná-las em diferentes atributos que ajudarão na classificação. Essas camadas estão essencialmente formando coleções de neurônios que representam diferentes partes do objeto em questão, e uma coleção de neurônios pode representar as orelhas flexíveis de um cachorro ou a vermelhidão de uma maçã. Quando um número suficiente desses neurônios é ativado em resposta a uma imagem de entrada, a imagem será classificada como um objeto.

Crédito: commons.wikimedia.org
O erro, ou a diferença entre os valores computados e o valor esperado no conjunto de treinamento, é calculado pela ANN. A rede então sofre retropropagação, onde a influência de um determinado neurônio em um neurônio da camada seguinte é calculada e sua influência ajustada. Isto é feito para otimizar o desempenho do modelo. Este processo é então repetido repetidamente. É assim que a rede treina sobre os dados e aprende associações entre as características de entrada e as classes de saída.
Os neurônios nas camadas do meio totalmente conectadas emitirão valores binários relacionados às classes possíveis. Se você tiver quatro classes diferentes (digamos um cão, um carro, uma casa e uma pessoa), o neurônio terá um valor “1” para a classe que ele acredita que a imagem representa e um valor “0” para as outras classes.
A camada final totalmente conectada receberá a saída da camada antes dela e entregará uma probabilidade para cada uma das classes, somando a uma. Se houver um valor 0,75 na categoria “cão”, representa uma certeza de 75% de que a imagem é um cão.
O classificador de imagem foi agora treinado, e as imagens podem ser passadas para a CNN, que agora dará um palpite sobre o conteúdo dessa imagem.
O Fluxo de Trabalho de Aprendizagem de Máquina
Antes de saltarmos para um exemplo de treinamento de um classificador de imagem, vamos tirar um momento para entender o fluxo de trabalho de aprendizagem de máquina ou pipeline. O processo de treinamento de um modelo de rede neural é bastante padrão e pode ser dividido em quatro fases diferentes.
Preparação de dados
Primeiro, você precisará coletar seus dados e colocá-los em uma forma que a rede possa treinar. Isto envolve a coleta de imagens e a etiquetagem das mesmas. Mesmo que você tenha baixado um conjunto de dados que alguém tenha preparado, é provável que haja um pré-processamento ou preparação que você deve fazer antes de poder usá-lo para o treinamento. A preparação de dados é uma arte por si só, envolvendo lidar com coisas como valores ausentes, dados corrompidos, dados no formato errado, etiquetas incorretas, etc.
Neste artigo, estaremos usando um conjunto de dados pré-processados.
Criar o Modelo
Criar o modelo de rede neural envolve fazer escolhas sobre vários parâmetros e hiperparâmetros. Você deve tomar decisões sobre o número de camadas a usar em seu modelo, quais serão os tamanhos de entrada e saída das camadas, que tipo de funções de ativação você usará, se você usará ou não dropout, etc.
Aprender quais parâmetros e hiperparâmetros usar virá com o tempo (e muito estudo), mas logo fora da porta existem algumas heurísticas que você pode usar para colocá-lo em execução e vamos cobrir alguns deles durante o exemplo de implementação.
Training the Model
Depois de ter criado o seu modelo, você simplesmente cria uma instância do modelo e o encaixa com os seus dados de treinamento. A maior consideração ao treinar um modelo é a quantidade de tempo que o modelo leva para treinar. Você pode especificar a duração do treinamento para uma rede especificando o número de épocas a serem treinadas. Quanto mais tempo treinar um modelo, maior será o seu desempenho, mas demasiadas épocas de treino e corre o risco de se sobrepor.
Se escolher o número de épocas para treinar é algo para o qual terá uma ideia, e é costume guardar os pesos de uma rede entre sessões de treino para que não precise de começar de novo depois de ter feito algum progresso no treino da rede.
Avaliação do modelo
Existem vários passos para avaliar o modelo. O primeiro passo para avaliar o modelo é comparar o desempenho do modelo com um conjunto de dados de validação, um conjunto de dados sobre o qual o modelo não foi treinado. Você comparará o desempenho do modelo com esse conjunto de validação e analisará seu desempenho através de diferentes métricas.
Existem várias métricas para determinar o desempenho de um modelo de rede neural, mas a métrica mais comum é “precisão”, a quantidade de imagens corretamente classificadas dividida pelo número total de imagens no seu conjunto de dados.
Após ter visto a precisão do desempenho do modelo em um conjunto de dados de validação, você normalmente voltará e treinará a rede novamente usando parâmetros ligeiramente afinados, pois é improvável que você fique satisfeito com o desempenho da sua rede na primeira vez que treinar. Você continuará ajustando os parâmetros de sua rede, re-treinando-a e medindo seu desempenho até ficar satisfeito com a precisão da rede.
Finalmente, você irá testar o desempenho da rede em um conjunto de testes. Esse conjunto de teste é outro conjunto de dados que seu modelo nunca viu antes.
Talvez você esteja se perguntando:
Por que se preocupar com o conjunto de teste? Se você está tendo uma idéia da precisão do seu modelo, não é esse o propósito do conjunto de validação?
É uma boa idéia manter um lote de dados que a rede nunca viu para testes, pois todos os ajustes dos parâmetros que você faz, combinados com o reteste no conjunto de validação, podem significar que sua rede aprendeu algumas idiossincrasias do conjunto de validação que não irão generalizar para dados fora da amostra.
Por isso, o propósito do conjunto de testes é verificar questões como sobreajustamento e estar mais confiante de que o seu modelo está realmente apto a funcionar no mundo real.
Image Recognition with a CNN
Cobrimos muito até agora, e se toda esta informação tem sido um pouco avassaladora, ver estes conceitos reunidos num classificador de amostra treinado num conjunto de dados deve tornar estes conceitos mais concretos. Então vamos ver um exemplo completo de reconhecimento de imagem com Keras, desde carregar os dados até a avaliação.

Crédito: www.cs.toronto.edu
Para começar, vamos precisar de um conjunto de dados para treinar. Neste exemplo, estaremos usando o famoso conjunto de dados CIFAR-10. O CIFAR-10 é um grande conjunto de imagens contendo mais de 60.000 imagens representando 10 classes diferentes de objetos como gatos, aviões e carros.
As imagens são RGB coloridas, mas são bastante pequenas, apenas 32 x 32. Uma grande coisa sobre o conjunto de dados CIFAR-10 é que ele vem pré-embalado com Keras, então é muito fácil carregar o conjunto de dados e as imagens precisam de muito pouco pré-processamento.
A primeira coisa que devemos fazer é importar as bibliotecas necessárias. Vou mostrar como essas importações são usadas à medida que formos, mas por enquanto saiba que estaremos fazendo uso do Numpy, e vários módulos associados com Keras:
import numpyfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activationfrom keras.layers.convolutional import Conv2D, MaxPooling2Dfrom keras.constraints import maxnormfrom keras.utils import np_utils Vamos usar uma semente aleatória aqui para que os resultados alcançados neste artigo possam ser replicados por você, e é por isso que precisamos numpy:
# Set random seed for purposes of reproducibilityseed = 21Preparando os Dados
Precisamos de mais uma importação: o conjunto de dados.
from keras.datasets import cifar10Agora vamos carregar o conjunto de dados. Podemos fazer isso simplesmente especificando em quais variáveis queremos carregar os dados, e então usando a função load_data()>
# loading in the data (X_train, y_train), (X_test, y_test) = cifar10.load_data()Na maioria dos casos você precisará fazer algum pré-processamento de seus dados para deixá-los prontos para uso, mas como estamos usando um conjunto de dados pré-embalado, muito pouco pré-processamento precisa ser feito. Uma coisa que queremos fazer é normalizar os dados de input.
Se os valores dos dados de input estiverem em um intervalo muito amplo, isso pode ter um impacto negativo sobre o desempenho da rede. Nesse caso, os valores de input são os pixels da imagem, que têm um valor entre 0 e 255,
Então, para normalizar os dados, podemos simplesmente dividir os valores da imagem por 255. Para fazer isso, precisamos primeiro fazer os dados do tipo float, já que atualmente eles são inteiros. Podemos fazer isso usando o comando astype() Numpy e então declarar que tipo de dados queremos:
# normalize the inputs from 0-255 to between 0 and 1 by dividing by 255 X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = X_train / 255.0X_test = X_test / 255.0Outra coisa que precisamos fazer para ter os dados prontos para a rede é codificar os valores em uma só vez. Eu não vou entrar nas especificidades da codificação de um ponto aqui, mas por enquanto sabemos que as imagens não podem ser usadas pela rede como estão, elas precisam ser codificadas primeiro e a codificação de um ponto é melhor usada ao fazer a classificação binária.
Estamos efetivamente fazendo classificação binária aqui porque uma imagem ou pertence a uma classe ou não pertence, ela não pode cair em algum lugar intermediário. O comando Numpy to_categorical() é usado para codificação de uma imagem. É por isso que importamos a função np_utils de Keras, pois ela contém to_categorical().
Também precisamos especificar o número de classes que estão no conjunto de dados, para que saibamos quantos neurônios comprimir a camada final até:
# one hot encode outputsy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)class_num = y_test.shapeDesenhando o Modelo
Chegamos ao estágio em que desenhamos o modelo CNN. A primeira coisa a fazer é definir o formato que gostaríamos de usar para o modelo, Keras tem vários formatos ou plantas diferentes para construir modelos, mas Sequential é o mais usado, e por essa razão, nós o importamos de Keras.
Criar o Modelo
model = Sequential()A primeira camada do nosso modelo é uma camada convolutiva. Ela vai pegar os inputs e rodar filtros convolucionais neles.
Ao implementá-los em Keras, temos que especificar o número de canais/filtros que queremos (são os 32 abaixo), o tamanho do filtro que queremos (3 x 3 neste caso), a forma do input (ao criar a primeira camada) e a ativação e padding que precisamos.
Como mencionado, relu é a ativação mais comum, e padding='same' apenas significa que não estamos mudando o tamanho da imagem em tudo:
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape, padding='same'))model.add(Activation('relu'))Nota: Você também pode juntar as ativações e os pools, assim:
model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), activation='relu', padding='same'))Agora vamos fazer uma camada dropout para evitar overfitting, que funciona eliminando aleatoriamente algumas das conexões entre as camadas (0.2 significa que ele cai 20% das conexões existentes):
model.add(Dropout(0.2))Pode ser que nós também queiramos fazer a normalização dos lotes aqui. Batch Normalization normaliza as entradas que vão para a próxima camada, assegurando que a rede sempre cria ativações com a mesma distribuição que desejamos:
model.add(BatchNormalization())Agora vem outra camada convolucional, mas o tamanho do filtro aumenta para que a rede possa aprender representações mais complexas:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))Aqui está a camada de agrupamento, como discutido antes, isso ajuda a tornar o classificador de imagens mais robusto para que ele possa aprender padrões relevantes. Há também o dropout e a normalização de lotes:
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization())Esse é o fluxo básico para a primeira metade de uma implementação CNN: Convolucional, activação, desistência, agrupamento. Agora você pode ver porque temos importado Dropout, BatchNormalization, Activation, Conv2d, e MaxPooling2d.
Você pode variar o número exato de camadas convolucionais que você tem a seu gosto, embora cada uma acrescente mais despesas de computação. Note que à medida que você adiciona camadas convolucionais você normalmente aumenta o número de filtros delas para que o modelo possa aprender representações mais complexas. Se os números escolhidos para estas camadas parecem um pouco arbitrários, saiba que em geral, você aumenta o número de filtros à medida que avança e é aconselhado torná-los potentes de 2, o que pode conceder um ligeiro benefício ao treinar em uma GPU.
É importante não ter muitas camadas de pooling, pois cada pooling descarta alguns dados. O pooling com muita freqüência levará a que não haja quase nada para as camadas densamente conectadas aprenderem sobre quando os dados chegarem a elas.
O número exato de camadas de pooling que você deve usar irá variar dependendo da tarefa que você está fazendo, e é algo que você terá uma sensação ao longo do tempo. Como as imagens já são tão pequenas aqui não vamos fazer pooling mais de duas vezes.
Você pode agora repetir estas camadas para dar à sua rede mais representações para trabalhar fora de:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) Depois de terminarmos com as camadas convolucionais, precisamos de Flatten os dados, e é por isso que importamos a função acima. Também vamos adicionar uma camada de dropout novamente:
model.add(Flatten())model.add(Dropout(0.2))Agora vamos fazer uso da Dense importação e criar a primeira camada densamente ligada. Precisamos especificar o número de neurônios na camada densa. Note que o número de neurônios nas camadas seguintes diminui, eventualmente aproximando-se do mesmo número de neurônios que há classes no conjunto de dados (neste caso 10). A restrição do kernel pode regularizar os dados à medida que eles aprendem, outra coisa que ajuda a evitar o sobreajuste. É por isso que importamos maxnorm anteriormente.
model.add(Dense(256, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Dense(128, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Nesta camada final, passamos no número de classes para o número de neurônios. Cada neurônio representa uma classe, e o output desta camada será um vetor de 10 neurônios com cada neurônio armazenando alguma probabilidade de que a imagem em questão pertence à classe que representa.
Finalmente, a função softmax ativação seleciona o neurônio com a maior probabilidade como output, votando que a imagem pertence a essa classe:
model.add(Dense(class_num))model.add(Activation('softmax'))Agora que desenhamos o modelo que queremos usar, só temos que compilá-lo. Vamos especificar o número de épocas que queremos treinar, assim como o otimizador que queremos usar.
O otimizador é o que vai afinar os pesos na sua rede para se aproximar do ponto de menor perda. O algoritmo Adam é um dos otimizadores mais usados porque dá um ótimo desempenho na maioria dos problemas:
epochs = 25optimizer = 'adam'Vamos agora compilar o modelo com os nossos parâmetros escolhidos. Vamos também especificar uma métrica para usar.
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=)Podemos imprimir o resumo do modelo para ver como o modelo inteiro se parece.
print(model.summary())Imprimir o resumo nos dará um pouco de informação:
Results: Layer (type) Output Shape Param #=================================================================conv2d_1 (Conv2D) (None, 32, 32, 32) 896_________________________________________________________________activation_1 (Activation) (None, 32, 32, 32) 0_________________________________________________________________dropout_1 (Dropout) (None, 32, 32, 32) 0_________________________________________________________________batch_normalization_1 (Batch (None, 32, 32, 32) 128_________________________________________________________________conv2d_2 (Conv2D) (None, 32, 32, 64) 18496_________________________________________________________________activation_2 (Activation) (None, 32, 32, 64) 0_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0_________________________________________________________________dropout_2 (Dropout) (None, 16, 16, 64) 0_________________________________________________________________batch_normalization_2 (Batch (None, 16, 16, 64) 256_________________________________________________________________conv2d_3 (Conv2D) (None, 16, 16, 64) 36928_________________________________________________________________activation_3 (Activation) (None, 16, 16, 64) 0_________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0_________________________________________________________________dropout_3 (Dropout) (None, 8, 8, 64) 0_________________________________________________________________batch_normalization_3 (Batch (None, 8, 8, 64) 256_________________________________________________________________conv2d_4 (Conv2D) (None, 8, 8, 128) 73856_________________________________________________________________activation_4 (Activation) (None, 8, 8, 128) 0_________________________________________________________________dropout_4 (Dropout) (None, 8, 8, 128) 0_________________________________________________________________batch_normalization_4 (Batch (None, 8, 8, 128) 512_________________________________________________________________flatten_1 (Flatten) (None, 8192) 0_________________________________________________________________dropout_5 (Dropout) (None, 8192) 0_________________________________________________________________dense_1 (Dense) (None, 256) 2097408_________________________________________________________________activation_5 (Activation) (None, 256) 0_________________________________________________________________dropout_6 (Dropout) (None, 256) 0_________________________________________________________________batch_normalization_5 (Batch (None, 256) 1024_________________________________________________________________dense_2 (Dense) (None, 128) 32896_________________________________________________________________activation_6 (Activation) (None, 128) 0_________________________________________________________________dropout_7 (Dropout) (None, 128) 0_________________________________________________________________batch_normalization_6 (Batch (None, 128) 512_________________________________________________________________dense_3 (Dense) (None, 10) 1290_________________________________________________________________activation_7 (Activation) (None, 10) 0=================================================================Total params: 2,264,458Trainable params: 2,263,114Non-trainable params: 1,344Agora vamos treinar o modelo. Para isso, basta chamar a função fit() no modelo e passar nos parâmetros escolhidos.
Aqui onde eu uso a semente que escolhi, para fins de reprodutibilidade.
numpy.random.seed(seed)model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)Estaremos treinando em 50000 amostras e validando em 10000 amostras.
Executar este código renderá:
Epoch 1/2564/50000 - ETA: 16:57 - loss: 3.1479 - acc: 0.0938128/50000 - ETA: 10:12 - loss: 3.0212 - acc: 0.0938192/50000 - ETA: 7:57 - loss: 2.9781 - acc: 0.1250256/50000 - ETA: 6:48 - loss: 2.8830 - acc: 0.1484320/50000 - ETA: 6:07 - loss: 2.8878 - acc: 0.1469384/50000 - ETA: 5:40 - loss: 2.8732 - acc: 0.1458448/50000 - ETA: 5:20 - loss: 2.8842 - acc: 0.1406.........49664/50000 - ETA: 1s - loss: 1.5160 - acc: 0.461149728/50000 - ETA: 1s - loss: 1.5157 - acc: 0.461249792/50000 - ETA: 1s - loss: 1.5153 - acc: 0.461449856/50000 - ETA: 0s - loss: 1.5147 - acc: 0.461549920/50000 - ETA: 0s - loss: 1.5144 - acc: 0.461749984/50000 - ETA: 0s - loss: 1.5141 - acc: 0.461750000/50000 - 262s 5ms/step - loss: 1.5140 - acc: 0.4618 - val_loss: 1.0715 - val_acc: 0.6195End of Epoch 1Note que na maioria dos casos, você gostaria de ter um conjunto de validação diferente do conjunto de teste, e assim você especificaria uma porcentagem dos dados de treinamento para usar como o conjunto de validação. Neste caso, vamos apenas passar nos dados do teste para nos certificarmos que os dados do teste são colocados de lado e não treinados. Só teremos dados de teste neste exemplo, a fim de manter as coisas simples.
Agora podemos avaliar o modelo e ver como ele foi executado. Basta ligar para model.evaluate():
# Model evaluationscores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%" % (scores*100))E somos saudados com o resultado:
Accuracy: 83.01%E é isso! Agora temos uma CNN de reconhecimento de imagem treinada. Nada mal para a primeira execução, mas você provavelmente gostaria de brincar com a estrutura e parâmetros do modelo para ver se você não consegue obter melhor performance.
Conclusion
Agora que você implementou sua primeira rede de reconhecimento de imagens no Keras, seria uma boa idéia brincar com o modelo e ver como a mudança de seus parâmetros afeta sua performance.
Isso lhe dará alguma intuição sobre as melhores escolhas para diferentes parâmetros do modelo. Você também deve ler sobre as diferentes escolhas de parâmetros e hiper-parametros enquanto o faz. Depois que você estiver confortável com eles, você pode tentar implementar seu próprio classificador de imagens em um conjunto de dados diferente.
Se você quiser brincar com o código ou simplesmente estudá-lo um pouco mais profundamente, o projeto é carregado no GitHub!