 Arwin Lashawn em 04 de dezembro de 2020
Arwin Lashawn em 04 de dezembro de 2020 
- Background
- How is Memory Managed in Python?
- Python Memory Allocation
- Static vs. Alocação Dinâmica de Memória
- Stack memory
- Memória heap
- Arenas
- Piscinas
- Blocks
- Python Garbage Collection
- Monitoring Python Memory Issues
- Ferramentas de Monitoramento de Desempenho de Aplicações (APM)
- Profile Modules
- tracemalloc
- memory_profiler
- Best Practices for Improving Python Code Performance
- Tirar vantagem das bibliotecas Python e funções incorporadas
- Não usar “+” para concatenação de strings
- Usar itertools para looping eficiente
- Recap and Closing Thoughts
Background
Python não é conhecido por ser uma linguagem de programação “rápida”. No entanto, de acordo com os resultados do 2020 Stack Overflow Developer Survey, Python é a 2ª linguagem de programação mais popular por trás do JavaScript (como você deve ter adivinhado). Isto é em grande parte devido à sua sintaxe super amigável e sua aplicabilidade para praticamente qualquer propósito. Embora o Python não seja a linguagem mais rápida por aí, sua grande legibilidade aliada ao incomparável suporte à comunidade e disponibilidade de bibliotecas o tornou extremamente atraente para se fazer coisas com o code.
O gerenciamento de memória do Python também desempenha um papel em sua popularidade. Como assim? O gerenciamento de memória Python é implementado de uma forma que facilita a nossa vida. Já ouviu falar do gerenciador de memória Python? É o gerenciador que mantém a memória Python sob controle, permitindo assim que você se concentre no seu código ao invés de ter que se preocupar com o gerenciamento de memória. Devido à sua simplicidade, no entanto, Python não lhe oferece muita liberdade no gerenciamento de uso de memória, ao contrário de linguagens como C++ onde você pode alocar manualmente e memória livre.
No entanto, ter um bom entendimento do gerenciamento de memória Python é um ótimo começo que lhe permitirá escrever código mais eficiente. Em última análise, você pode reforçá-lo como um hábito que pode potencialmente ser adotado em outras linguagens de programação que você conhece.
Então o que ganhamos com a escrita de código de memória eficiente?
- Leva a um processamento mais rápido e menos necessidade de recursos, ou seja, uso de memória de acesso aleatório (RAM). Mais memória RAM disponível geralmente significaria mais espaço para cache, o que ajudará a acelerar o acesso ao disco. O ótimo de escrever código que é eficiente em termos de memória é que ele não necessariamente requer que você escreva mais linhas de código.
- Outro benefício é que ele evita vazamento de memória, um problema que faz com que o uso da RAM aumente continuamente mesmo quando os processos são mortos, eventualmente levando à lentidão ou comprometimento do desempenho do dispositivo. Isto é causado pela falha em libertar memória usada após o término dos processos.
No mundo da tecnologia, você pode ter ouvido que “feito é melhor do que perfeito”. Entretanto, digamos que você tenha dois desenvolvedores que usaram Python no desenvolvimento do mesmo aplicativo e o completaram dentro do mesmo período de tempo. Um deles escreveu um código mais eficiente para a memória, o que resulta em um aplicativo com desempenho mais rápido. Você preferiria escolher o aplicativo que roda suavemente ou o que roda visivelmente mais lento? Este é um bom exemplo onde dois indivíduos passariam o mesmo tempo codificando e ainda assim teriam performances de código visivelmente diferentes.
Aqui está o que você vai aprender no guia:
- Como a memória é gerenciada em Python?
- Python Garbage Collection
- Monitoring Python Memory Issue
- Best Practices for Improving Python Code Performance
How is Memory Managed in Python?
De acordo com a documentação Python (3.9.0) para gerenciamento de memória, o gerenciamento de memória Python envolve uma pilha privada que é usada para armazenar os objetos e estruturas de dados do seu programa. Lembre-se também que é o gerenciador de memória Python que lida com a maior parte do trabalho sujo relacionado ao gerenciamento de memória para que você possa apenas focar no seu código.
Python Memory Allocation
Qualquer coisa em Python é um objeto. Para que esses objetos sejam úteis, eles precisam ser armazenados na memória para serem acessados. Antes que eles possam ser armazenados na memória, um pedaço de memória deve primeiro ser alocado ou atribuído para cada um deles.
No nível mais baixo, o alocador de memória bruta Python irá primeiro certificar-se de que há espaço disponível na pilha privada para armazenar estes objetos. Ele faz isso interagindo com o gerenciador de memória do seu sistema operacional. Olhe para ele como seu programa Python solicitando ao seu sistema operacional um pedaço de memória para trabalhar com.
No próximo nível, vários alocadores específicos de objetos operam no mesmo heap e implementam políticas de gerenciamento distintas dependendo do tipo de objeto. Como você já deve saber, alguns exemplos de tipos de objetos são strings e inteiros. Enquanto strings e inteiros podem não ser tão diferentes considerando o tempo que levamos para reconhecê-los e memorizá-los, eles são tratados de forma muito diferente pelos computadores. Isto porque os computadores precisam de diferentes requisitos de armazenamento e velocidades de troca de inteiros em comparação com strings.
Uma última coisa que você deve saber sobre como o monte de Python é gerenciado é que você tem controle zero sobre ele. Agora você pode estar se perguntando, como podemos então escrever código de memória eficiente se temos tão pouco controle sobre o gerenciamento de memória do Python? Antes de entrarmos nisso, precisamos entender melhor alguns termos importantes relativos ao gerenciamento de memória.
Static vs. Alocação Dinâmica de Memória
Agora que você entenda o que é alocação de memória, é hora de se familiarizar com os dois tipos de alocação de memória, ou seja, estática e dinâmica, e distinguir entre os dois.
Alocação da memória estática:
- Como a palavra “estática” sugere, variáveis alocadas estaticamente são permanentes, significando que elas precisam ser alocadas de antemão e duram enquanto o programa é executado.
- Memória é alocada durante o tempo de compilação, ou antes da execução do programa.
- Aplicada usando a estrutura de dados da pilha, significando que as variáveis são armazenadas na memória da pilha.
- Memória que foi alocada não pode ser reutilizada, portanto sem reusabilidade da memória.
Alocação da memória dinâmica:
- Como a palavra “dinâmica” sugere, variáveis alocadas dinamicamente não são permanentes e podem ser alocadas como um programa em execução.
- Memória é alocada em tempo de execução ou durante a execução do programa.
- Implementado usando a estrutura de dados heap, o que significa que as variáveis são armazenadas na memória heap.
- Memória que foi alocada pode ser liberada e reutilizada.
Uma vantagem da alocação dinâmica de memória em Python é que não precisamos nos preocupar com a quantidade de memória que precisamos para o nosso programa com antecedência. Outra vantagem é que a manipulação da estrutura de dados pode ser feita livremente sem ter que se preocupar com a necessidade de maior alocação de memória se a estrutura de dados se expandir.
No entanto, como a alocação dinâmica de memória é feita durante a execução do programa, ela vai consumir mais tempo para sua conclusão. Além disso, a memória que foi alocada precisa ser liberada após ter sido utilizada. Caso contrário, problemas como vazamentos de memória podem potencialmente ocorrer.
Contramos dois tipos de estruturas de memória acima – memória heap e memória stack. Vamos dar uma olhada mais profunda neles.
Stack memory
Todos os métodos e suas variáveis são armazenados na memória da pilha. Lembra-se que a memória da pilha é alocada durante o tempo de compilação? Isto significa efetivamente que o acesso a este tipo de memória é muito rápido.
Quando um método é chamado em Python, um frame de pilha é alocado. Este frame de pilha irá lidar com todas as variáveis do método. Após o método ser retornado, o frame de pilha é automaticamente destruído.
Note que o frame de pilha também é responsável por definir o escopo das variáveis de um método.
Memória heap
Todos os objetos e variáveis de instância são armazenados na memória heap. Quando uma variável é criada em Python, ela é armazenada em uma pilha privada que então permitirá a alocação e desalocação.
A memória heap permite que estas variáveis sejam acessadas globalmente por todos os métodos do seu programa. Após a variável ser devolvida, o coletor de lixo Python começa a funcionar, cujo funcionamento iremos cobrir mais tarde.
Agora vamos dar uma olhada na estrutura de memória do Python.
Python tem três níveis diferentes quando se trata da sua estrutura de memória:
- Arenas
- Pool
- Blocks
Comecemos com o maior de todos – arenas.
Arenas
Imagine uma mesa com 64 livros cobrindo toda a sua superfície. O topo da mesa representa uma arena que tem um tamanho fixo de 256KiB que é alocado na pilha (Note que KiB é diferente de KB, mas você pode assumir que eles são os mesmos para esta explicação). Uma arena representa o maior pedaço de memória possível.
Mais especificamente, arenas são mapeamentos de memória que são usados pelo alocador Python, pymalloc, que é otimizado para pequenos objetos (menor ou igual a 512 bytes). As arenas são responsáveis pela alocação de memória, e portanto as estruturas subsequentes não precisam mais fazer isso.
Esta arena pode então ser dividida em 64 pools, que é a próxima maior estrutura de memória.
Piscinas
Voltando ao exemplo da mesa, os livros representam todas as piscinas dentro de uma arena.
Cada piscina teria tipicamente um tamanho fixo de 4Kb e pode ter três estados possíveis:
- Vazia: A piscina está vazia e, portanto, disponível para alocação.
- Usado: O pool contém objetos que fazem com que ele não esteja vazio nem cheio.
- Cheio: O pool está cheio e, portanto, não está disponível para mais alocações.
Note que o tamanho do pool deve corresponder ao tamanho de página padrão de memória do seu sistema operacional.
Um pool é então dividido em muitos blocos, que são as menores estruturas de memória.
Blocks
Voltando ao exemplo de mesa, as páginas dentro de cada livro representam todos os blocos dentro de um pool.
Arenas e pools não semelhantes, o tamanho de um bloco não é fixo. O tamanho de um bloco varia de 8 a 512 bytes e deve ser um múltiplo de 8.
Cada bloco só pode armazenar um objecto Python de um determinado tamanho e ter três estados possíveis:
- Intocado: Não foi alocado
- Livre: Foi alocado mas foi liberado e disponibilizado para alocação
- Alocado: Foi alocado
Note que os três diferentes níveis de uma estrutura de memória (arenas, pools e blocos) que discutimos acima são especificamente para objetos Python menores. Objetos grandes são direcionados ao alocador C padrão dentro do Python, o que seria uma boa leitura para outro dia.
Python Garbage Collection
Garbage Collection é um processo realizado por um programa para liberar memória previamente alocada para um objeto que não está mais em uso. Pode-se pensar na alocação de lixo como reciclagem ou reutilização de memória.
Back in the day, os programadores tinham que alocar e desalocar manualmente a memória. Esquecer de desalocar a memória levaria a um vazamento de memória, levando a uma queda no desempenho de execução. Pior, alocação e desalocação manual de memória é até provável que leve a uma sobrescrita acidental de memória, o que pode causar o programa a falhar completamente.
Em Python, a coleta de lixo é feita automaticamente e, portanto, economiza muita dor de cabeça para gerenciar manualmente a alocação e desalocação de memória. Especificamente, Python usa contagem de referência combinada com a coleta de lixo geracional para liberar a memória não utilizada. A razão pela qual a contagem de referências por si só não é suficiente para Python porque não limpa eficazmente as referências cíclicas penduradas.
Um ciclo de coleta de lixo geracional contém os seguintes passos –
- Python inicializa uma “lista de descarte” para objetos não utilizados.
- Um algoritmo é executado para detectar ciclos de referência.
- Se um objeto estiver ausente fora das referências, ele é inserido na lista de descarte.
- Liberta a alocação de memória para os objetos na lista de descarte.
Para saber mais sobre a coleta de lixo em Python, você pode conferir nossa coleta de lixo Python: A Guide for Developers post.
Monitoring Python Memory Issues
Embora todos adorem Python, ele não se intimida em ter problemas de memória. Há muitas razões possíveis.
De acordo com a documentação Python (3.9.0) para gerenciamento de memória, o gerenciador de memória Python não necessariamente libera a memória de volta ao seu sistema operacional. É declarado na documentação que “sob certas circunstâncias, o gerenciador de memória Python pode não acionar ações apropriadas, como coleta de lixo, compactação de memória ou outras medidas preventivas”
Como resultado, pode-se ter que explicitamente liberar a memória em Python. Uma maneira de fazer isso é forçar o coletor de lixo Python a liberar memória não utilizada, fazendo uso do módulo gc. Basta executar gc.collect() para fazer isso. Isto, no entanto, só fornece benefícios notáveis quando se manipula um grande número de objetos.
Parte da natureza ocasionalmente errada do coletor de lixo Python, especialmente quando se lida com grandes conjuntos de dados, várias bibliotecas Python também têm sido conhecidas por causar vazamentos de memória. Pandas, por exemplo, é uma dessas ferramentas no radar. Considere dar uma olhada em todos os problemas relacionados à memória no repositório oficial do GitHub pandas!
Uma razão óbvia que pode passar até mesmo pelos olhos aguçados dos revisores de código é que há objetos grandes e persistentes dentro do código que não são liberados. Na mesma nota, o crescimento infinito das estruturas de dados é outro motivo de preocupação. Por exemplo, uma estrutura de dados em crescimento do dicionário sem um limite de tamanho fixo.
Uma maneira de resolver a estrutura de dados em crescimento é converter o dicionário em uma lista se possível e definir um tamanho máximo para a lista. Caso contrário, simplesmente defina um limite para o tamanho do dicionário e limpe-o sempre que o limite for atingido.
Agora você pode estar se perguntando, como faço para detectar problemas de memória em primeiro lugar? Uma opção é tirar proveito de uma ferramenta de Monitoramento de Desempenho de Aplicativos (APM). Além disso, muitos módulos Python úteis podem ajudá-lo a rastrear e rastrear problemas de memória. Vamos ver nossas opções, começando com as ferramentas APM.
Ferramentas de Monitoramento de Desempenho de Aplicações (APM)
Então o que exatamente é Monitoramento de Desempenho de Aplicações e como ele ajuda no rastreamento de problemas de memória? Uma ferramenta APM permite que você observe as métricas de desempenho em tempo real de um programa, permitindo uma otimização contínua à medida que você descobre problemas que estão limitando o desempenho.
Baseado nos relatórios gerados pelas ferramentas APM, você será capaz de ter uma idéia geral sobre como seu programa está se desempenhando. Como você pode receber e monitorar métricas de desempenho em tempo real, você pode tomar medidas imediatas sobre qualquer problema observado. Uma vez que você tenha reduzido as possíveis áreas do seu programa que podem ser os culpados por problemas de memória, você pode então mergulhar no código e discuti-lo com os outros contribuidores de código para determinar melhor as linhas específicas de código que precisam ser corrigidas.
Traçar a raiz dos problemas de vazamento de memória em si pode ser uma tarefa assustadora. Consertá-la é outro pesadelo, pois você precisa realmente entender seu código. Se você se encontrar nessa posição, não procure mais porque o ScoutAPM é uma ferramenta APM proficiente que pode analisar construtivamente e otimizar a performance da sua aplicação. O ScoutAPM fornece uma visão em tempo real para que você possa identificar rapidamente & resolver problemas antes que seus clientes possam detectá-los.
Profile Modules
Existem muitos módulos Python úteis que você pode usar para resolver problemas de memória, seja um vazamento de memória ou um travamento do seu programa devido ao uso excessivo de memória. Dois dos módulos recomendados são:
- tracemalloc
- memory-profiler
Note que apenas o módulo tracemalloc é incorporado, então certifique-se de instalar primeiro o outro módulo se você gostaria de usá-lo.
tracemalloc
De acordo com a documentação Python (3.9.0) para tracemalloc, usando este módulo pode fornecer as seguintes informações:
- Traceback onde um objeto foi alocado.
- Estatísticas dos blocos de memória alocados por nome de arquivo e por número de linha: tamanho total, número e o tamanho médio dos blocos de memória alocados.
- Calcule a diferença entre dois instantâneos para detectar vazamentos de memória.
Um primeiro passo recomendado que você deve fazer ao determinar a origem do problema de memória é primeiro exibir os arquivos alocando a maior quantidade de memória. Você pode fazer isso facilmente usando o primeiro exemplo de código mostrado na documentação.
Isso não significa, entretanto, que arquivos que alocam uma pequena quantidade de memória não irão crescer indefinidamente para causar vazamentos de memória no futuro.
memory_profiler
Este módulo é divertido. Eu trabalhei com isso e é um favorito pessoal porque ele fornece a opção de simplesmente adicionar o @profile decorator a qualquer função que você deseja investigar. A saída dada como resultado também é muito fácil de entender.
Outra razão que faz deste meu favorito pessoal é que este módulo permite que você desenhe um gráfico de uso de memória baseado no tempo. Às vezes, você simplesmente precisa verificar rapidamente se o uso de memória continua a aumentar indefinidamente ou não. Esta é a solução perfeita para isso, pois você não precisa fazer um perfil de memória linha por linha para confirmar isso. Você pode simplesmente observar o gráfico traçado após deixar o profiler rodar por uma certa duração. Aqui está um exemplo do gráfico que é gerado –
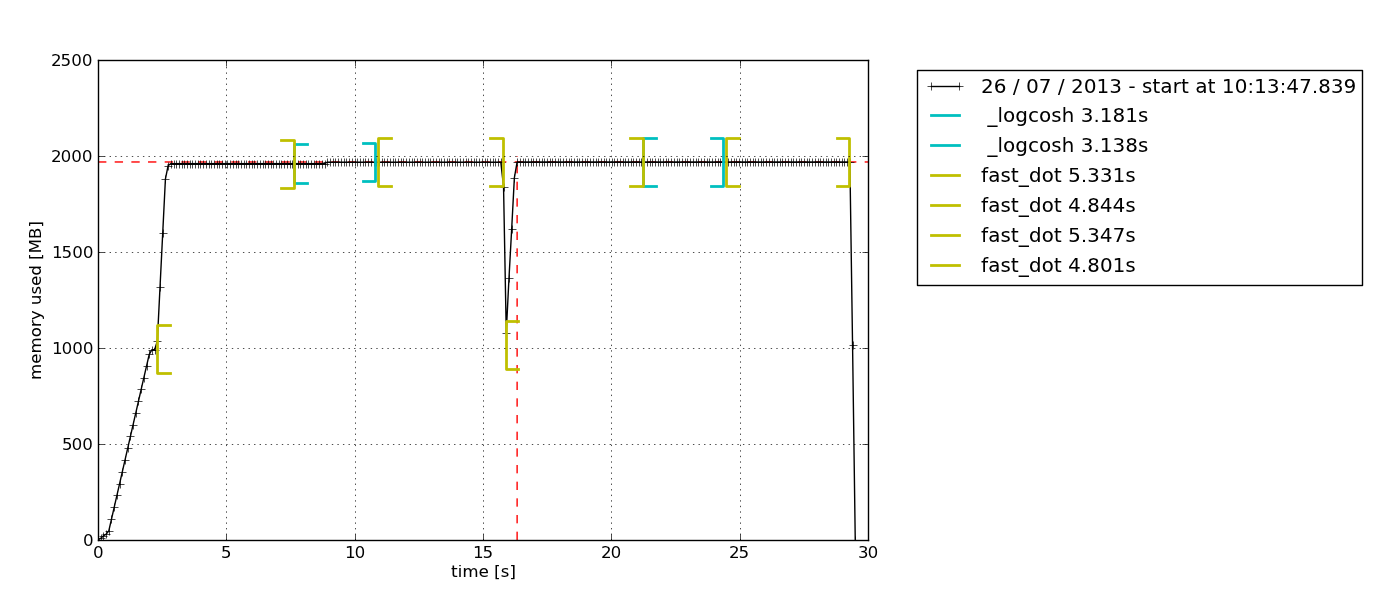
De acordo com a descrição na documentação do perfil da memória, este módulo Python é para monitorar o consumo de memória de um processo, bem como uma análise linha por linha do mesmo para programas Python. É um módulo Python puro que depende da biblioteca psutil.
Eu recomendo a leitura deste blog Medium para explorar melhor como o memory-profiler é usado. Lá você também aprenderá como usar outro módulo Python, muppy (o mais recente é muppy3).
Best Practices for Improving Python Code Performance
Suficiente de todos os detalhes sobre gerenciamento de memória. Agora vamos explorar alguns dos bons hábitos de escrever código Python eficiente em memória.
Tirar vantagem das bibliotecas Python e funções incorporadas
Sim, este é um bom hábito que pode ser muitas vezes negligenciado. Python tem um suporte incomparável à comunidade e isso é refletido pelas abundantes bibliotecas Python disponíveis para praticamente qualquer propósito, desde chamadas de API até ciência de dados.
Se existe uma biblioteca Python por aí que permite que você faça a mesma coisa que já implementou, o que você pode fazer é comparar a performance do seu código ao usar a biblioteca comparada com quando você usa seu código personalizado. É provável que as bibliotecas Python (especialmente as populares) sejam mais eficientes em termos de memória do que o seu código porque elas são continuamente melhoradas com base no feedback da comunidade. Você prefere confiar no código que foi criado da noite para o dia ou que foi rigorosamente melhorado por um período prolongado?
Best of all, as bibliotecas Python irão salvar muitas linhas de código, então porque não?
Não usar “+” para concatenação de strings
Em algum momento, todos nós temos sido culpados de concatenar strings usando o operador “+” porque parece tão fácil.
Note que as strings são imutáveis. Assim, cada vez que você adiciona um elemento a uma string com o operador “+”, Python tem que criar uma nova string com uma nova alocação de memória. Com strings mais longas, a ineficiência de memória do código tornar-se-á mais pronunciada.
Usar itertools para looping eficiente
Looping é uma parte essencial da automatização de coisas. À medida que continuamos a utilizar cada vez mais loops, acabaremos por ter de utilizar loops aninhados, que são conhecidos por serem ineficientes devido à sua elevada complexidade de tempo de execução.
É aqui que o módulo itertools vem em socorro. De acordo com a documentação do itertools do Python, “O módulo padroniza um conjunto central de ferramentas rápidas e eficientes na memória que são úteis por si só ou em combinação”. Juntos, eles tornam possível construir ferramentas especializadas de forma sucinta e eficiente em Python puro”
Em outras palavras, o módulo itertools permite o looping memory-efficient ao se livrar de loops desnecessários. Curiosamente, o módulo itertools é chamado de gem pois permite compor soluções elegantes para uma infinidade de problemas.
Tenho certeza que você estará trabalhando com pelo menos um loop no seu próximo código, então tente implementar itertools!
Recap and Closing Thoughts
Aplicar bons hábitos de gerenciamento de memória Python não é para o programador casual. Se você normalmente se dá bem com scripts simples, você não deve se deparar com problemas relacionados à memória. Graças ao hardware e software que continuam a sofrer rápidos avanços à medida que você lê isto, o modelo base de praticamente qualquer dispositivo lá fora, independentemente das suas marcas, deve executar programas do dia-a-dia muito bem. A necessidade de código de memória eficiente só começa a aparecer quando você começa a trabalhar em uma grande base de código, especialmente para produção, onde o desempenho é fundamental.
No entanto, isso não sugere que o gerenciamento de memória em Python é um conceito difícil de entender, nem isso significa que não é importante. Isto é porque a ênfase na performance das aplicações está crescendo a cada dia. Um dia, não será mais apenas uma mera questão de “feito”. Em vez disso, os desenvolvedores estarão competindo para entregar uma solução que não só seja capaz de resolver com sucesso as necessidades dos clientes, mas que também o faça com velocidade e recursos mínimos.