- Wprowadzenie
- Definicje
- TensorFlow/Keras
- Rozpoznawanie obrazów (klasyfikacja)
- Eksploracja cech
- Jak sieci neuronowe uczą się rozpoznawać obrazy
- Wyodrębnianie cech za pomocą filtrów
- Funkcje aktywacji
- Warstwy łączące
- Spłaszczanie
- Warstwy w pełni połączone
- Przepływ pracy uczenia maszynowego
- Przygotowanie danych
- Tworzenie modelu
- Trenowanie modelu
- Ewaluacja modelu
- Rozpoznawanie obrazów za pomocą CNN
- Prepping the Data
- Projektowanie modelu
- Tworzenie modelu
- Wniosek
Wprowadzenie
Jednym z najczęstszych zastosowań TensorFlow i Keras jest rozpoznawanie/klasyfikacja obrazów. Jeśli chcesz dowiedzieć się, jak używać Keras do klasyfikowania lub rozpoznawania obrazów, ten artykuł nauczy Cię, jak to zrobić.
Definicje
Jeśli nie masz jasności co do podstawowych pojęć stojących za rozpoznawaniem obrazów, trudno będzie w pełni zrozumieć resztę tego artykułu. Zanim więc przejdziemy dalej, poświęćmy chwilę na zdefiniowanie kilku pojęć.
TensorFlow/Keras

Credit: commons.wikimedia.org
TensorFlow to biblioteka open source stworzona dla Pythona przez zespół Google Brain. TensorFlow kompiluje wiele różnych algorytmów i modeli razem, umożliwiając użytkownikowi implementację głębokich sieci neuronowych do wykorzystania w zadaniach takich jak rozpoznawanie/klasyfikacja obrazów i przetwarzanie języka naturalnego. TensorFlow to potężny framework, który działa poprzez implementację serii węzłów przetwarzania, z których każdy reprezentuje operację matematyczną, a cała seria węzłów jest nazywana „wykresem”.
W odniesieniu do Keras, jest to wysokopoziomowy interfejs API (interfejs programowania aplikacji), który może korzystać z funkcji TensorFlow pod spodem (jak również innych bibliotek ML, takich jak Theano). Keras został zaprojektowany z myślą o przyjazności dla użytkownika i modułowości jako zasadach przewodnich. W praktyce, Keras sprawia, że implementacja wielu potężnych, ale często złożonych funkcji TensorFlow jest tak prosta, jak to tylko możliwe, i jest skonfigurowana do pracy z Pythonem bez żadnych większych modyfikacji lub konfiguracji.
Rozpoznawanie obrazów (klasyfikacja)
Rozpoznawanie obrazów odnosi się do zadania wprowadzenia obrazu do sieci neuronowej i wyprowadzenia pewnego rodzaju etykiety dla tego obrazu. Etykieta, że sieć wychodzi będzie odpowiadać wstępnie zdefiniowanej klasy. Może być wiele klas, które obraz może być oznaczony jako, lub tylko jeden. Jeśli jest jedna klasa, termin „rozpoznawanie” jest często stosowany, podczas gdy wieloklasowe zadanie rozpoznawania jest często nazywane „klasyfikacją”.
Zestaw klasyfikacji obrazu jest wykrywanie obiektów, gdzie konkretne instancje obiektów są identyfikowane jako należące do pewnej klasy, takich jak zwierzęta, samochody lub ludzie.
Eksploracja cech
W celu przeprowadzenia rozpoznania/klasyfikacji obrazu, sieć neuronowa musi przeprowadzić ekstrakcję cech. Cechy to elementy danych, na których nam zależy, a które będą przekazywane przez sieć. W konkretnym przypadku rozpoznawania obrazu, cechy są grupami pikseli, jak krawędzie i punkty obiektu, które sieć będzie analizować pod kątem wzorców.
Rozpoznawanie cech (lub ekstrakcja cech) jest procesem wyciągania odpowiednich cech z obrazu wejściowego, aby te cechy mogły być analizowane. Wiele obrazów zawiera adnotacje lub metadane o obrazie, które pomagają sieci znaleźć odpowiednie cechy.
Jak sieci neuronowe uczą się rozpoznawać obrazy
Zrozumienie, w jaki sposób sieć neuronowa rozpoznaje obrazy, pomoże Ci podczas implementacji modelu sieci neuronowej, więc krótko przeanalizujmy proces rozpoznawania obrazów w kilku następnych sekcjach.
Wyodrębnianie cech za pomocą filtrów
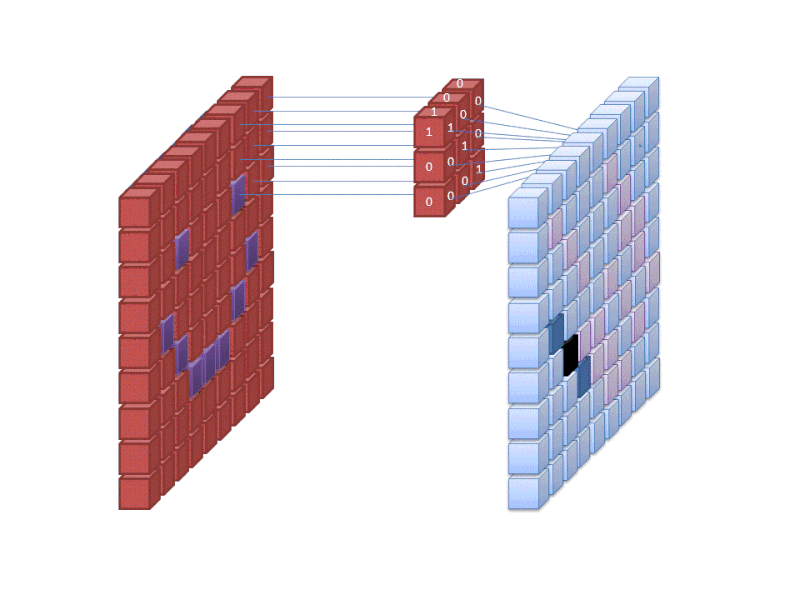
Credit: commons.wikimedia.org
Pierwsza warstwa sieci neuronowej uwzględnia wszystkie piksele w obrazie. Po wprowadzeniu wszystkich danych do sieci, różne filtry są stosowane do obrazu, który tworzy reprezentacje różnych części obrazu. To jest ekstrakcja cech i tworzy „mapy cech”.
Ten proces ekstrakcji cech z obrazu jest realizowany za pomocą „warstwy konwolucyjnej”, a konwolucja jest po prostu tworząc reprezentację części obrazu. To z tej koncepcji konwolucji, że mamy termin Convolutional Neural Network (CNN), typ sieci neuronowej najczęściej używane w klasyfikacji / rozpoznawania obrazu.
Jeśli chcesz zwizualizować, jak tworzenie map funkcji działa, pomyśl o świeceniu latarką nad obrazem w ciemnym pokoju. Przesuwając wiązkę światła po obrazie, poznajesz jego cechy. Filtr jest tym, czego sieć używa do utworzenia reprezentacji obrazu, a w tej metaforze światło latarki jest filtrem.
Szerokość wiązki światła latarki kontroluje, jak dużą część obrazu badasz za jednym razem, a sieci neuronowe mają podobny parametr, rozmiar filtra. Rozmiar filtra wpływa na to, jak duża część obrazu, jak wiele pikseli, jest badana w jednym czasie. Powszechnym rozmiarem filtra używanego w sieciach CNN jest 3, i obejmuje on zarówno wysokość, jak i szerokość, więc filtr bada obszar pikseli o wymiarach 3 x 3.
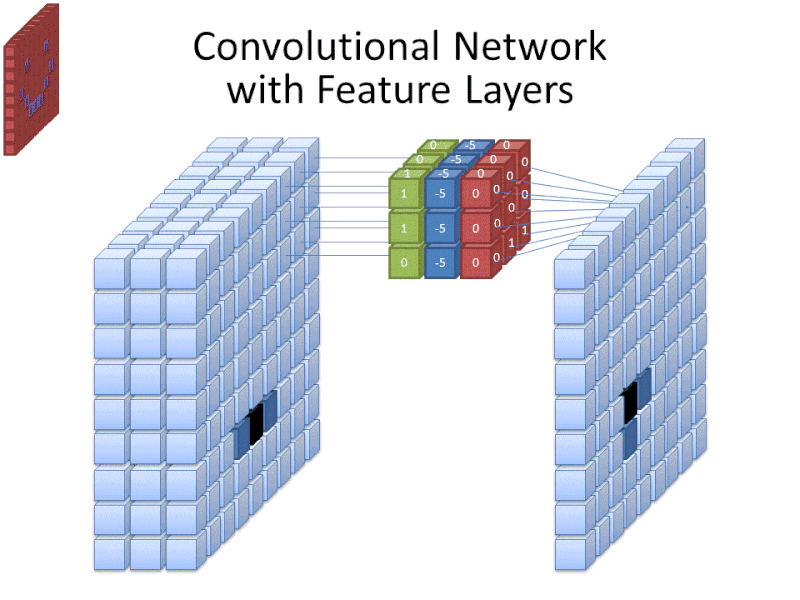
Credit: commons.wikimedia.org
Podczas gdy rozmiar filtra obejmuje wysokość i szerokość filtra, należy również określić jego głębokość.
Jak obraz 2D ma głębię?
Obrazy cyfrowe są renderowane jako wysokość, szerokość i pewna wartość RGB, która definiuje kolory piksela, więc „głębia”, która jest śledzona, to liczba kanałów kolorystycznych obrazu. Obrazy w skali szarości (niekolorowe) mają tylko 1 kanał koloru, podczas gdy obrazy kolorowe mają 3 kanały głębi.
Wszystko to oznacza, że dla filtra o rozmiarze 3 zastosowanego do obrazu w pełnym kolorze, wymiary tego filtra będą wynosić 3 x 3 x 3. Dla każdego piksela objętego tym filtrem, sieć mnoży wartości filtra z wartościami w samych pikselach, aby uzyskać numeryczną reprezentację tego piksela. Proces ten jest następnie wykonywany dla całego obrazu, aby uzyskać kompletną reprezentację. Filtr jest przesuwany przez resztę obrazu zgodnie z parametrem zwanym „stride”, który definiuje o ile pikseli ma być przesunięty filtr po obliczeniu wartości w jego aktualnej pozycji. Konwencjonalna wielkość kroku dla CNN wynosi 2.
Wynikiem końcowym wszystkich tych obliczeń jest mapa cech. Proces ten jest zwykle wykonywany z więcej niż jednym filtrem, co pomaga zachować złożoność obrazu.
Funkcje aktywacji
Po utworzeniu mapy cech obrazu, wartości, które reprezentują obraz są przekazywane przez funkcję aktywacji lub warstwę aktywacji. Funkcja aktywacji bierze wartości, które reprezentują obraz, które są w formie liniowej (tj. po prostu lista liczb) dzięki warstwie konwolucyjnej i zwiększa ich nieliniowość, ponieważ obrazy same w sobie są nieliniowe.
Typową funkcją aktywacji używaną do osiągnięcia tego celu jest Rectified Linear Unit (ReLU), chociaż istnieje kilka innych funkcji aktywacji, które są czasami używane (możesz o nich przeczytać tutaj).
Warstwy łączące
Po aktywacji danych, są one przesyłane przez warstwę łączącą. Pooling „downsamples” obraz, co oznacza, że bierze informacje, które reprezentują obraz i kompresuje go, czyniąc go mniejszym. Proces łączenia sprawia, że sieć jest bardziej elastyczna i bardziej sprawna w rozpoznawaniu obiektów/obrazów na podstawie odpowiednich cech.
Gdy patrzymy na obraz, zazwyczaj nie jesteśmy zainteresowani wszystkimi informacjami w tle obrazu, tylko cechami, na których nam zależy, takimi jak ludzie lub zwierzęta.
Podobnie, warstwa łącząca w CNN będzie abstrahować od niepotrzebnych części obrazu, zachowując tylko te części obrazu, które uważa za istotne, kontrolowane przez określony rozmiar warstwy łączącej.
Ponieważ musi podejmować decyzje dotyczące najbardziej istotnych części obrazu, nadzieja jest taka, że sieć nauczy się tylko tych części obrazu, które naprawdę reprezentują dany obiekt. Pomaga to uniknąć przepasowania, gdzie sieć uczy się aspektów przypadku szkoleniowego zbyt dobrze i nie udaje się uogólnić na nowe dane.
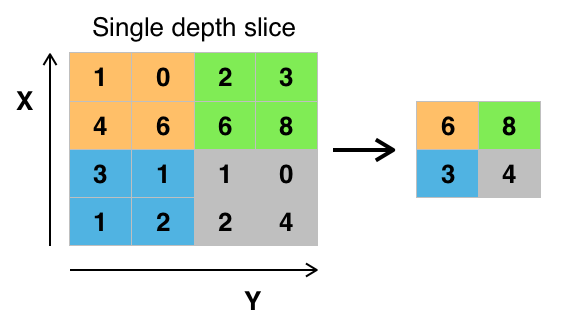
Credit: commons.wikimedia.org
Istnieją różne sposoby łączenia wartości, ale najczęściej używane jest łączenie maksymalne. Max pooling uzyskuje maksymalną wartość pikseli w obrębie jednego filtra (w obrębie jednego miejsca na obrazie). Zrzuca to 3/4 informacji, przy założeniu, że używane są filtry 2 x 2.
Maksymalne wartości pikseli są używane w celu uwzględnienia możliwych zniekształceń obrazu, a parametry/rozmiar obrazu są zmniejszane w celu kontroli nadmiernego dopasowania. Istnieją inne typy łączenia, takie jak łączenie średnie lub łączenie sum, ale nie są one używane tak często, ponieważ łączenie maksymalne ma tendencję do dawania lepszej dokładności.
Spłaszczanie
Ostatnie warstwy naszego CNN, gęsto połączone warstwy, wymagają, aby dane były w formie wektora do przetworzenia. Z tego powodu, dane muszą być „spłaszczone”. Wartości są kompresowane do długiego wektora lub kolumny sekwencyjnie uporządkowanych liczb.
Warstwy w pełni połączone
Ostatnimi warstwami CNN są warstwy gęsto połączone, czyli sztuczna sieć neuronowa (ANN). Podstawową funkcją ANN jest analiza cech wejściowych i łączenie ich w różne atrybuty, które pomogą w klasyfikacji. Warstwy te zasadniczo tworzą zbiory neuronów, które reprezentują różne części danego obiektu, a zbiór neuronów może reprezentować klapnięte uszy psa lub czerwoność jabłka. Gdy wystarczająca liczba tych neuronów zostanie aktywowana w odpowiedzi na obraz wejściowy, obraz zostanie sklasyfikowany jako obiekt.

Credit: commons.wikimedia.org
Błąd, czyli różnica między obliczonymi wartościami a wartością oczekiwaną w zbiorze treningowym, jest obliczany przez ANN. Następnie sieć poddawana jest wstecznej propagacji, gdzie obliczany jest wpływ danego neuronu na neuron w następnej warstwie i korygowany jest jego wpływ. Robi się to w celu optymalizacji działania modelu. Proces ten jest następnie powtarzany w kółko. W ten sposób sieć trenuje na danych i uczy się skojarzeń między cechami wejściowymi a klasami wyjściowymi.
Neurony w środkowych, w pełni połączonych warstwach będą podawać wartości binarne odnoszące się do możliwych klas. Jeśli masz cztery różne klasy (powiedzmy psa, samochód, dom i osobę), neuron będzie miał wartość „1” dla klasy, którą jego zdaniem reprezentuje obraz, a wartość „0” dla pozostałych klas.
Końcowa w pełni połączona warstwa otrzyma wyjście z warstwy przed nią i dostarczy prawdopodobieństwo dla każdej z klas, sumując je do jednego. Jeśli w kategorii „pies” jest wartość 0,75, oznacza to 75% pewności, że obraz jest psem.
Klasyfikator obrazu został już wytrenowany, a obrazy mogą być przekazywane do CNN, która będzie teraz generować przypuszczenia dotyczące zawartości tego obrazu.
Przepływ pracy uczenia maszynowego
Zanim przejdziemy do przykładu szkolenia klasyfikatora obrazu, poświęćmy chwilę na zrozumienie przepływu pracy uczenia maszynowego. Proces szkolenia modelu sieci neuronowej jest dość standardowy i można go podzielić na cztery różne fazy.
Przygotowanie danych
Po pierwsze, trzeba będzie zebrać dane i umieścić je w formie, na której sieć może trenować. Wymaga to zebrania obrazów i oznaczenia ich etykietami. Nawet jeśli pobrałeś zestaw danych przygotowany przez kogoś innego, prawdopodobnie będziesz musiał dokonać wstępnego przetworzenia lub przygotowania, zanim będziesz mógł użyć go do treningu. Przygotowanie danych jest sztuką samą w sobie, obejmującą radzenie sobie z takimi rzeczami, jak brakujące wartości, uszkodzone dane, dane w niewłaściwym formacie, nieprawidłowe etykiety itp.
W tym artykule będziemy używać wstępnie przetworzonego zestawu danych.
Tworzenie modelu
Tworzenie modelu sieci neuronowej obejmuje dokonywanie wyborów dotyczących różnych parametrów i hiperparametrów. Musisz podjąć decyzje dotyczące liczby warstw, których użyjesz w swoim modelu, jakie będą rozmiary wejścia i wyjścia warstw, jakiego rodzaju funkcji aktywacji użyjesz, czy będziesz używał dropoutu, czy nie, itd.
Nauczenie się, które parametry i hiperparametry użyć przyjdzie z czasem (i dużą ilością nauki), ale zaraz za bramą są pewne heurystyki, których możesz użyć, aby zacząć działać, a my zajmiemy się niektórymi z nich podczas przykładu implementacji.
Trenowanie modelu
Po utworzeniu modelu, po prostu tworzysz instancję modelu i dopasowujesz ją do danych treningowych. Najważniejszym czynnikiem podczas trenowania modelu jest czas potrzebny na jego wytrenowanie. Możesz określić długość treningu sieci, określając liczbę epok, przez które ma być trenowana. Im dłużej trenujesz model, tym bardziej poprawi się jego wydajność, ale zbyt wiele epok treningowych i ryzykujesz przepasowanie.
Wybór liczby epok treningowych jest czymś, do czego będziesz się przyzwyczajać, i zwyczajowo zapisuje się wagi sieci pomiędzy sesjami treningowymi, aby nie trzeba było zaczynać od nowa, gdy już zrobisz jakiś postęp w trenowaniu sieci.
Ewaluacja modelu
Ocena modelu składa się z wielu kroków. Pierwszym krokiem w ocenie modelu jest porównanie jego wydajności z zestawem danych walidacyjnych, zestawem danych, na którym model nie był trenowany. Porównasz wydajność modelu z tym zestawem walidacyjnym i przeanalizujesz jego wydajność za pomocą różnych metryk.
Istnieją różne metryki określające wydajność modelu sieci neuronowej, ale najczęstszą metryką jest „dokładność”, ilość poprawnie sklasyfikowanych obrazów podzielona przez całkowitą liczbę obrazów w zestawie danych.
Po zobaczeniu dokładności działania modelu na zbiorze danych walidacyjnych, zazwyczaj wracamy i trenujemy sieć ponownie, używając lekko zmienionych parametrów, ponieważ jest mało prawdopodobne, że będziemy zadowoleni z działania sieci za pierwszym razem, gdy trenujemy. Będziesz nadal dostosowywać parametry sieci, przekwalifikowywać ją i mierzyć jej wydajność, aż będziesz zadowolony z dokładności sieci.
Na koniec przetestujesz wydajność sieci na zbiorze testowym. Ten zestaw testowy to inny zestaw danych, których model nigdy wcześniej nie widział.
Może zastanawiasz się:
Po co zawracać sobie głowę zestawem testowym? Jeśli chcesz poznać dokładność swojego modelu, czyż nie taki jest cel zbioru walidacyjnego?
Dobrym pomysłem jest zachowanie partii danych, których sieć nigdy nie widziała, do testowania, ponieważ wszystkie zmiany parametrów, które wykonujesz, w połączeniu z ponownym testowaniem na zbiorze walidacyjnym, mogą oznaczać, że sieć nauczyła się pewnych idiosynkrazji zbioru walidacyjnego, które nie będą uogólniać się na dane spoza próby.
W związku z tym, celem zestawu testowego jest sprawdzenie problemów takich jak przepasowanie i być bardziej pewnym, że twój model jest naprawdę dopasowany do działania w prawdziwym świecie.
Rozpoznawanie obrazów za pomocą CNN
Do tej pory wiele wyjaśniliśmy, a jeśli wszystkie te informacje były nieco przytłaczające, zobaczenie tych koncepcji w przykładowym klasyfikatorze wytrenowanym na zbiorze danych powinno sprawić, że staną się one bardziej konkretne. Przyjrzyjmy się więc pełnemu przykładowi rozpoznawania obrazu za pomocą Keras, od załadowania danych do oceny.

Credit: www.cs.toronto.edu
Na początek potrzebujemy zbioru danych, na którym będziemy trenować. W tym przykładzie, będziemy używać słynnego zbioru danych CIFAR-10. CIFAR-10 jest dużym zbiorem danych obrazów zawierającym ponad 60 000 obrazów reprezentujących 10 różnych klas obiektów, takich jak koty, samoloty i samochody.
Obrazy są pełnokolorowe RGB, ale są dość małe, tylko 32 x 32. Świetną rzeczą w zbiorze danych CIFAR-10 jest to, że jest on dostarczany w pakiecie z Keras, więc bardzo łatwo jest załadować zbiór danych, a obrazy wymagają bardzo niewielkiego przetwarzania wstępnego.
Pierwszą rzeczą, jaką powinniśmy zrobić, jest zaimportowanie niezbędnych bibliotek. Pokażę, jak te importy są używane, ale na razie wiedz, że będziemy korzystać z Numpy i różnych modułów związanych z Keras:
import numpyfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activationfrom keras.layers.convolutional import Conv2D, MaxPooling2Dfrom keras.constraints import maxnormfrom keras.utils import np_utilsBędziemy używać losowego ziarna, aby wyniki osiągnięte w tym artykule mogły być replikowane przez ciebie, dlatego potrzebujemy numpy:
# Set random seed for purposes of reproducibilityseed = 21Prepping the Data
Potrzebujemy jeszcze jednego importu: zbioru danych.
from keras.datasets import cifar10Załadujmy teraz zbiór danych. Możemy to zrobić po prostu określając, do których zmiennych chcemy załadować dane, a następnie używając funkcji load_data():
# loading in the data (X_train, y_train), (X_test, y_test) = cifar10.load_data()W większości przypadków będziesz musiał wykonać pewne wstępne przetwarzanie danych, aby były gotowe do użycia, ale ponieważ używamy gotowego zbioru danych, nie trzeba wykonywać zbyt wiele wstępnego przetwarzania. Jedną z rzeczy, którą chcemy zrobić, jest normalizacja danych wejściowych.
Jeśli wartości danych wejściowych są w zbyt szerokim zakresie, może to negatywnie wpłynąć na działanie sieci. W tym przypadku wartościami wejściowymi są piksele na obrazie, które mają wartości od 0 do 255.
Więc, aby znormalizować dane, możemy po prostu podzielić wartości obrazu przez 255. Aby to zrobić, musimy najpierw przekształcić dane w typ float, ponieważ obecnie są one liczbami całkowitymi. Możemy to zrobić, używając polecenia astype() Numpy, a następnie deklarując, jaki typ danych chcemy uzyskać:
# normalize the inputs from 0-255 to between 0 and 1 by dividing by 255 X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = X_train / 255.0X_test = X_test / 255.0Inną rzeczą, którą będziemy musieli zrobić, aby przygotować dane do sieci, jest jednokrotne kodowanie wartości. Nie będę tutaj zagłębiał się w specyfikę kodowania one-hot, ale na razie wiedz, że obrazy nie mogą być używane przez sieć w takiej postaci, w jakiej są, muszą być najpierw zakodowane, a kodowanie one-hot jest najlepiej używane podczas klasyfikacji binarnej.
Wykonujemy tutaj klasyfikację binarną, ponieważ obraz albo należy do jednej klasy, albo nie, nie może znaleźć się gdzieś pomiędzy. Polecenie Numpy to_categorical() jest używane do kodowania one-hot. Dlatego właśnie zaimportowaliśmy funkcję np_utils z Keras, ponieważ zawiera ona to_categorical().
Musimy również określić liczbę klas w zbiorze danych, abyśmy wiedzieli, do ilu neuronów skompresować warstwę końcową:
# one hot encode outputsy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)class_num = y_test.shapeProjektowanie modelu
Dotarliśmy do etapu, w którym projektujemy model CNN. Pierwszą rzeczą do zrobienia jest określenie formatu, którego chcielibyśmy użyć dla modelu, Keras ma kilka różnych formatów lub schematów, na których można budować modele, ale Sequential jest najczęściej używany i z tego powodu zaimportowaliśmy go z Keras.
Tworzenie modelu
model = Sequential()Pierwszą warstwą naszego modelu jest warstwa konwolucyjna. Będzie ona przyjmować dane wejściowe i uruchamiać na nich filtry konwolucyjne.
Podczas ich implementacji w Keras musimy określić liczbę kanałów/filtrów, które chcemy (to 32 poniżej), rozmiar filtra, który chcemy (3 x 3 w tym przypadku), kształt danych wejściowych (podczas tworzenia pierwszej warstwy) oraz aktywację i padding, których potrzebujemy.
Jak wspomniano, relu jest najczęstszą aktywacją, a padding='same' oznacza po prostu, że nie zmieniamy rozmiaru obrazu w ogóle:
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape, padding='same'))model.add(Activation('relu'))Uwaga: Możesz również łączyć aktywacje i pule razem, tak jak to:
model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), activation='relu', padding='same'))Teraz zrobimy warstwę zrzutową, aby zapobiec przepasowaniu, która działa poprzez losowe eliminowanie niektórych połączeń między warstwami (0.2 oznacza, że usuwa 20% istniejących połączeń):
model.add(Dropout(0.2))Możemy również chcieć wykonać tutaj normalizację wsadową. Normalizacja wsadowa normalizuje dane wejściowe kierowane do następnej warstwy, zapewniając, że sieć zawsze tworzy aktywacje o takim samym rozkładzie, jaki chcemy:
model.add(BatchNormalization())Teraz pojawia się kolejna warstwa konwolucyjna, ale rozmiar filtra zwiększa się, więc sieć może uczyć się bardziej złożonych reprezentacji:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))Tutaj znajduje się warstwa łączenia, jak omówiono wcześniej, pomaga to uczynić klasyfikator obrazu bardziej odpornym, aby mógł uczyć się odpowiednich wzorców. Jest też zrzut i normalizacja partii:
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization())To jest podstawowy przepływ dla pierwszej połowy implementacji CNN: Konwolucyjna, aktywacja, zrzut, pooling. Możesz teraz zobaczyć, dlaczego zaimportowaliśmy Dropout, BatchNormalization, Activation, Conv2d i MaxPooling2d.
Możesz zmieniać dokładną liczbę warstw konwolucyjnych według własnych upodobań, choć każda z nich dodaje więcej wydatków obliczeniowych. Zauważ, że dodając warstwy konwolucyjne, zwykle zwiększasz liczbę ich filtrów, aby model mógł uczyć się bardziej złożonych reprezentacji. Jeśli liczby wybrane dla tych warstw wydają się nieco arbitralne, wiedz, że ogólnie rzecz biorąc, zwiększasz liczbę filtrów w miarę ich dodawania i zaleca się, aby były to potęgi 2, co może przynieść niewielkie korzyści podczas treningu na GPU.
Ważne jest, aby nie mieć zbyt wielu warstw łączących, ponieważ każde łączenie odrzuca część danych. Zbyt częste łączenie doprowadzi do tego, że gęsto połączone warstwy nie będą miały prawie nic do nauczenia się, gdy dane do nich dotrą.
Dokładna liczba warstw łączących, których powinieneś użyć, będzie się różnić w zależności od zadania, które wykonujesz, i jest to coś, co poznasz z czasem. Ponieważ obrazy są tutaj tak małe, nie będziemy ich łączyć więcej niż dwa razy.
Możesz teraz powtórzyć te warstwy, aby dać sieci więcej reprezentacji do pracy:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Po zakończeniu pracy z warstwami konwolucyjnymi musimy Flatten dane, dlatego zaimportowaliśmy powyższą funkcję. Dodamy też ponownie warstwę zrzutową:
model.add(Flatten())model.add(Dropout(0.2))Teraz wykorzystujemy import Dense i tworzymy pierwszą warstwę gęsto połączoną. Musimy określić liczbę neuronów w warstwie gęsto połączonej. Zauważmy, że liczba neuronów w kolejnych warstwach maleje, ostatecznie zbliżając się do liczby neuronów równej liczbie klas w zbiorze danych (w tym przypadku 10). Ograniczenie jądra może regularyzować dane podczas uczenia się, co również pomaga uniknąć przepełnienia. To dlatego zaimportowaliśmy maxnorm wcześniej.
model.add(Dense(256, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Dense(128, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())W tej ostatniej warstwie przekazujemy liczbę klas do liczby neuronów. Każdy neuron reprezentuje klasę, a wyjściem tej warstwy będzie wektor 10 neuronów, z których każdy przechowuje pewne prawdopodobieństwo, że dany obraz należy do klasy, którą reprezentuje.
Na koniec, funkcja aktywacji softmax wybiera neuron o najwyższym prawdopodobieństwie jako wyjście, głosując, że obraz należy do tej klasy:
model.add(Dense(class_num))model.add(Activation('softmax'))Teraz, gdy zaprojektowaliśmy model, którego chcemy użyć, musimy go skompilować. Określmy liczbę epok, przez które chcemy trenować, a także optymalizator, którego chcemy użyć.
Optymalizator jest tym, co dostroi wagi w sieci, aby zbliżyć się do punktu najmniejszej straty. Algorytm Adam jest jednym z najczęściej używanych optymalizatorów, ponieważ zapewnia dużą wydajność w przypadku większości problemów:
epochs = 25optimizer = 'adam'Skompilujmy teraz model z wybranymi przez nas parametrami. Określmy też metrykę, której będziemy używać.
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=)Możemy wydrukować podsumowanie modelu, aby zobaczyć, jak wygląda cały model.
print(model.summary())Wydrukowanie podsumowania da nam sporo informacji:
Results: Layer (type) Output Shape Param #=================================================================conv2d_1 (Conv2D) (None, 32, 32, 32) 896_________________________________________________________________activation_1 (Activation) (None, 32, 32, 32) 0_________________________________________________________________dropout_1 (Dropout) (None, 32, 32, 32) 0_________________________________________________________________batch_normalization_1 (Batch (None, 32, 32, 32) 128_________________________________________________________________conv2d_2 (Conv2D) (None, 32, 32, 64) 18496_________________________________________________________________activation_2 (Activation) (None, 32, 32, 64) 0_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0_________________________________________________________________dropout_2 (Dropout) (None, 16, 16, 64) 0_________________________________________________________________batch_normalization_2 (Batch (None, 16, 16, 64) 256_________________________________________________________________conv2d_3 (Conv2D) (None, 16, 16, 64) 36928_________________________________________________________________activation_3 (Activation) (None, 16, 16, 64) 0_________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0_________________________________________________________________dropout_3 (Dropout) (None, 8, 8, 64) 0_________________________________________________________________batch_normalization_3 (Batch (None, 8, 8, 64) 256_________________________________________________________________conv2d_4 (Conv2D) (None, 8, 8, 128) 73856_________________________________________________________________activation_4 (Activation) (None, 8, 8, 128) 0_________________________________________________________________dropout_4 (Dropout) (None, 8, 8, 128) 0_________________________________________________________________batch_normalization_4 (Batch (None, 8, 8, 128) 512_________________________________________________________________flatten_1 (Flatten) (None, 8192) 0_________________________________________________________________dropout_5 (Dropout) (None, 8192) 0_________________________________________________________________dense_1 (Dense) (None, 256) 2097408_________________________________________________________________activation_5 (Activation) (None, 256) 0_________________________________________________________________dropout_6 (Dropout) (None, 256) 0_________________________________________________________________batch_normalization_5 (Batch (None, 256) 1024_________________________________________________________________dense_2 (Dense) (None, 128) 32896_________________________________________________________________activation_6 (Activation) (None, 128) 0_________________________________________________________________dropout_7 (Dropout) (None, 128) 0_________________________________________________________________batch_normalization_6 (Batch (None, 128) 512_________________________________________________________________dense_3 (Dense) (None, 10) 1290_________________________________________________________________activation_7 (Activation) (None, 10) 0=================================================================Total params: 2,264,458Trainable params: 2,263,114Non-trainable params: 1,344Teraz przechodzimy do treningu modelu. Aby to zrobić, wystarczy wywołać funkcję fit() na modelu i przekazać wybrane parametry.
Tutaj używam wybranego przeze mnie ziarna, dla celów odtwarzalności.
numpy.random.seed(seed)model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)Będziemy trenować na 50000 próbkach i sprawdzać poprawność na 10000 próbkach.
Wykonanie tego fragmentu kodu da następujące wyniki:
Epoch 1/2564/50000 - ETA: 16:57 - loss: 3.1479 - acc: 0.0938128/50000 - ETA: 10:12 - loss: 3.0212 - acc: 0.0938192/50000 - ETA: 7:57 - loss: 2.9781 - acc: 0.1250256/50000 - ETA: 6:48 - loss: 2.8830 - acc: 0.1484320/50000 - ETA: 6:07 - loss: 2.8878 - acc: 0.1469384/50000 - ETA: 5:40 - loss: 2.8732 - acc: 0.1458448/50000 - ETA: 5:20 - loss: 2.8842 - acc: 0.1406.........49664/50000 - ETA: 1s - loss: 1.5160 - acc: 0.461149728/50000 - ETA: 1s - loss: 1.5157 - acc: 0.461249792/50000 - ETA: 1s - loss: 1.5153 - acc: 0.461449856/50000 - ETA: 0s - loss: 1.5147 - acc: 0.461549920/50000 - ETA: 0s - loss: 1.5144 - acc: 0.461749984/50000 - ETA: 0s - loss: 1.5141 - acc: 0.461750000/50000 - 262s 5ms/step - loss: 1.5140 - acc: 0.4618 - val_loss: 1.0715 - val_acc: 0.6195End of Epoch 1Zauważ, że w większości przypadków chcesz mieć zbiór walidacyjny, który różni się od zbioru testowego, a więc określasz procent danych treningowych do użycia jako zbiór walidacyjny. W tym przypadku, po prostu przekażemy dane testowe, aby upewnić się, że dane testowe są odłożone na bok i nie są trenowane. W tym przykładzie będziemy mieli tylko dane testowe, aby zachować prostotę.
Teraz możemy ocenić model i zobaczyć, jak sobie radził. Wystarczy, że zadzwonimy do model.evaluate():
# Model evaluationscores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%" % (scores*100))I zostaniemy przywitani wynikiem:
Accuracy: 83.01%I to wszystko! Mamy teraz wytrenowaną sieć rozpoznawania obrazów CNN. Nieźle jak na pierwsze uruchomienie, ale prawdopodobnie chciałbyś pobawić się strukturą modelu i parametrami, aby sprawdzić, czy nie możesz uzyskać lepszej wydajności.
Wniosek
Teraz, gdy zaimplementowałeś swoją pierwszą sieć rozpoznawania obrazów w Keras, dobrym pomysłem jest pobawienie się modelem i sprawdzenie, jak zmiana parametrów wpływa na jego wydajność.
To da ci intuicję na temat najlepszych wyborów dla różnych parametrów modelu. Powinieneś również zapoznać się z różnymi wyborami parametrów i hiperparametrów, gdy to robisz. Po tym, jak poczujesz się z tym komfortowo, możesz spróbować zaimplementować swój własny klasyfikator obrazu na innym zbiorze danych.
Jeśli chciałbyś pobawić się kodem lub po prostu zbadać go nieco głębiej, projekt jest załadowany na GitHub!
.