
Robię dużo projektów związanych z Twitchem tu i tam, próbując zobaczyć jakie są możliwości. Jeden z moich ostatnich projektów obejmował stworzenie Twitch Emote Extension dla Chrome, gdzie pokazałem, jak uzyskać dodatkowe „sloty” emote za darmo. To mnie wciągnęło w rozszerzenia przeglądarki, więc pomyślałem, że pokażmy, jak zrobić jeden od zera, budując filtr profanacji dla czatu Twitcha.
Na końcu tego chcemy mieć rozszerzenie, które po zainstalowaniu sprawdza zestaw oflagowanych słów na czacie i zastępuje je bardziej przyjaznymi wersjami. Może to być przydatne dla dzieci oglądających strumienie, na przykład.
Jeśli chcesz tylko kod dla tego rozszerzenia, jest link do wyniku końcowego na dole tego artykułu.
W porządku, więc zajmijmy się tym najpierw. Utwórz folder gdzieś, gdzie chcesz i nazwij go profanity-filter. Ja utworzyłem swój w miejscu, gdzie synchronizuję się z GitHubem.

Teraz wewnątrz tego folderu utwórz dwa nowe pliki: manifest.json i content.js. Zobaczysz, jak będziemy ich używać, gdy zabierzemy się do budowania rozszerzenia.
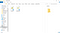
Otwórz manifest.json, który jest plik Google patrzy na metadane dotyczące rozszerzenia, i wklej następujące do niego:
{ "manifest_version": 2, "name": "Twitch Profanity Filter Extension", "version": "0.1", "content_scripts": , "js": } ]}
Jak widać, mówimy Google, że to rozszerzenie powinno działać na każdej stronie z Twitch i jesteśmy również mówiąc, że logika, która powinna być uruchomiona na tych stronach znajduje się w pliku o nazwie content.js. Zauważ, że umieściłem wersję jako 0.1, ponieważ jest to moja pierwsza próba.
Wprowadzanie logiki
Teraz otwórz content.js w wybranym edytorze tekstu. Bardzo polecam Visual Studio Code, jest to mój edytor tekstu do wszystkiego, co związane z kodowaniem i jest darmowy.
Teraz, sposób, w jaki zamierzamy to ustawić jest w kilku krokach. Co chcemy osiągnąć i jak zamierzamy to osiągnąć? Wiemy, że chcemy zmienić pewne słowa na inne, co oznacza czytanie wiadomości na czacie, skanowanie ich w poszukiwaniu oflagowanych słów, a następnie aktualizację tych słów na bardziej przyjazne. Tak więc, kiedy strona się ładuje, chcemy, aby nasza logika była w stanie wykonać następujące czynności:
- Znajdź chatbox
- Za każdym razem, gdy pojawi się nowa wiadomość na czacie, pobierz wiadomość lub kontener wiadomości
- Zmień oflagowane słowa na ich przyjazne odpowiedniki
Zajmijmy się więc tym. Pierwszą częścią jest faktyczne uruchomienie skryptu, gdy strona, a dokładniej okno, zostało załadowane. W javascript, możesz podłączyć się do tego zdarzenia ładowania i właśnie to zamierzamy zrobić. Zaktualizuj swój plik content.js, aby zawierał następujące elementy:
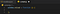
To sprawi, że cokolwiek umieścimy wewnątrz tej funkcji, zostanie wywołane, gdy strona zostanie załadowana.
Znajdź chatbox
Jak więc znajdziemy chatbox? Cóż, w wersji Chrome strony Twitch, chatbox jest zawarty w elemencie <div>, który ma klasę o nazwie chat-scrollable-area__message-container. Zamierzamy uzyskać ten element, lub węzeł, poprzez javascript. Zaktualizuj plik tak, aby wyglądał tak:

Powód, dla którego dodajemy .item(0) za nim, jest taki, że getElementsByClassName() zwraca tablicę elementów. Ponieważ wiemy, że tylko jeden element ma tę klasę, pobieramy go z tablicy, określając, że chcemy pierwszą rzecz (większość języków programowania zaczyna liczyć od 0).
Get every new message in chat
To jest trochę bardziej skomplikowane do zrozumienia, jeśli nie jesteś przyzwyczajony do programowania lub nie jesteś przyzwyczajony do wzorców obserwatora. Sposób w jaki będziemy pobierać każdą nową wiadomość jest poprzez użycie MutationObserver na węźle chatbox, który właśnie odebraliśmy. Zaktualizuj plik, aby pasował do poniższego, a następnie przejdziemy przez to, co się dzieje:
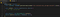
Po pierwsze, w linii 4, definiujemy funkcję wywołania zwrotnego, która pobiera listę mutacji i obserwatora, którego utworzymy w linii 8. Logika w tej funkcji jest tym, co jest wywoływane za każdym razem, gdy coś się zmienia lub mutuje w węźle, który obserwujemy.
W linii 8 tworzymy obserwatora i przekazujemy mu naszą funkcję wywołania zwrotnego. Następnie, w linii 9, mówimy obserwatorowi, aby zaczął obserwować nasz węzeł docelowy i przekazujemy konfigurację, która mówi, że jesteśmy zainteresowani tylko mutacjami w childList. Wiadomości pojawiają się jako węzły potomne w węźle chatbox, który obserwujemy, więc nasza funkcja wywołania zwrotnego zostanie wywołana za każdym razem, gdy pojawi się nowa wiadomość na czacie. To jest dokładnie to, czego chcemy!
Ale teraz musimy jeszcze uzyskać rzeczywiste elementy wiadomości i w tym celu dodajemy jeszcze jedną linię kodu w naszym wywołaniu zwrotnym:
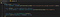
Nazwa może wydawać się nieco dziwna, ale wszystkie części tekstowe wiadomości (nie skanujemy emotek, tylko rzeczywiste teksty) są umieszczane w <span>elementach HTML, które mają klasę text-fragment. Ponadto, ponieważ funkcja ta jest wywoływana przy każdej nowej wiadomości, wiemy, że wiadomość, której potrzebujemy, musi być ostatnim elementem w węźle chatbox, więc dlatego chwytamy lastElementChild.
Zmień oflagowane słowa na ich przyjazne odpowiedniki
Przejdźmy do soczystego kawałka. Jeśli chcemy zmienić oflagowane słowa, potrzebujemy najpierw czegoś, co powie nam, jakie są oflagowane słowa i ich odpowiedniki. Zrobimy to za pomocą prostego słownika. Zaktualizuj plik, aby wyglądał tak:
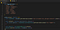
Teraz przeczytamy rzeczywisty tekst we wszystkich elementach text-fragment, zapętlimy wszystkie zakazane słowa i zastąpimy je, jeśli to konieczne. Rozpocznijmy tę pętlę, więc zaktualizuj swoją funkcję wywołania zwrotnego o następujące elementy:

To, co się tutaj dzieje, to zapętlenie wszystkich tych elementów, które zawierają tekst. W linii 18 bierzemy jeden konkretny element na raz, a w linii 19 pobieramy z niego rzeczywisty tekst pisany małymi literami, ponieważ wszystkie nasze oflagowane słowa również pisane są małymi literami. Ułatwia to porównywanie, ale w bardziej zaawansowanej wersji zadbalibyśmy o staranne zachowanie wielkości liter. Teraz, gdy mamy już nasz tekst, chcemy zapętlić nasze oflagowane słowa i sprawdzić, czy są one obecne. Jeśli tak, to je usuwamy. Zaktualizuj funkcję:

Słownik, który stworzyliśmy, działa na parach klucz-wartość, gdzie kluczami są oflagowane słowa, a wartościami przyjazne słowa, więc w linii 21 otrzymujemy po prostu tablicę wszystkich kluczy, która jest tablicą oflagowanych słów, nad którymi chcemy zapętlić pętlę. W pętli pobieramy oflagowane słowo, na które aktualnie patrzymy i jeśli nasz tekst zawiera jedno lub więcej z nich, pobieramy przyjazne słowo i aktualizujemy nasz tekst zastępując oflagowane słowa. To już prawie wszystko, teraz musimy tylko wziąć nasz nowy i poprawiony tekst i umieścić go z powrotem w elemencie, z którego go wzięliśmy:

W linii 31 umieściliśmy tekst z powrotem w elemencie i to wszystko! Przejdźmy do testowania tego w Chrome.
Test
Otwórz Chrome i przejdź do chrome://extensions. Powinieneś zobaczyć swoje rozszerzenia, a w prawym górnym rogu zobaczysz tryb dewelopera. Włącz go, jeśli jeszcze nie jest włączony. Następnie, w prawym górnym rogu, zobaczysz opcję Załaduj rozpakowane. Użyjemy jej, by załadować nasze lokalne rozszerzenie bez konieczności przechodzenia przez Chrome Web Store. Kliknij na nią i wybierz folder, w którym znajdują się pliki:
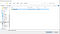
To powinno sprawić, że od razu pojawi się ono na naszej liście rozszerzeń:
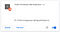
Dobrze! Teraz przejdźmy na dowolny kanał, na którym możemy porozmawiać. Pójdę na kanał mojego przyjaciela Bjarke’a, zabawnego duńskiego streamera, i wypróbuję go:

No i proszę, działa! Nasz własny filtr przekleństw. Nie było tak trudno, prawda? Pozostaje tylko wypuścić go do Chrome Web Store, jeśli chcesz. Będę rozwijać się na tej liście słów i uwalniając to, więc jeśli nie potrzebujesz więcej niż to, nie musisz go zwolnić, widząc, jak to wymaga opłaty, aby dostać się do programu. Nie będę zagłębiał się w to, jak działa wydanie, ale jeśli jesteś zainteresowany, zrobiłem Twitch Emote Extension, aby uzyskać własne nieograniczone sloty emote i ten artykuł wyjaśnia, jak wydać rozszerzenia na końcu.
Jeśli chcesz zobaczyć cały kod dla tego rozszerzenia, sprawdź GitHub repo tutaj. Wesołego kodowania!