 Arwin Lashawn on December 04, 2020
Arwin Lashawn on December 04, 2020 
- Background
- How is Memory Managed in Python?
- Python Geheugentoewijzing
- Static vs. Dynamic Memory Allocation
- Stackgeheugen
- Heap memory
- Arena’s
- Pools
- Blokken
- Python Garbage Collection
- Monitoring Python Memory Issues
- Application Performance Monitoring (APM) Tools
- Profielmodules
- tracemalloc
- memory_profiler
- Best Practices for Improving Python Code Performance
- Profiteer van Python-bibliotheken en ingebouwde functies
- Niet “+” gebruiken voor string aaneenschakeling
- Het gebruik van itertools voor efficient looping
- Recap and Closing Thoughts
Background
Python staat niet bekend als een “snelle” programmeertaal. Echter, volgens de 2020 Stack Overflow Developer Survey resultaten, is Python de 2e meest populaire programmeertaal achter JavaScript (zoals je misschien al geraden had). Dit is grotendeels te danken aan de super vriendelijke syntaxis en de toepasbaarheid voor zowat elk doel. Hoewel Python niet de snelste taal is die er is, heeft de grote leesbaarheid in combinatie met de ongeëvenaarde ondersteuning van de gemeenschap en de beschikbaarheid van bibliotheken het zeer aantrekkelijk gemaakt om dingen gedaan te krijgen met code.
Python’s geheugenbeheer speelt ook een rol in zijn populariteit. Hoe dat zo? Het geheugenbeheer van Python is geïmplementeerd op een manier die ons leven gemakkelijker maakt. Ooit gehoord van de Python geheugenbeheerder? Het is de manager die het geheugen van Python onder controle houdt, zodat u zich kunt concentreren op uw code in plaats van u zorgen te hoeven maken over het geheugenbeheer. Door zijn eenvoud biedt Python u echter niet veel vrijheid in het beheren van geheugengebruik, in tegenstelling tot talen als C++, waar u handmatig geheugen kunt toewijzen en vrijmaken.
Een goed begrip van Python geheugenbeheer is echter een goed begin dat u in staat zal stellen efficiëntere code te schrijven. Uiteindelijk kunt u het afdwingen als een gewoonte die mogelijk kan worden overgenomen in andere programmeertalen die u kent.
Dus wat krijgen we uit het schrijven van geheugen-efficiënte code?
- Het leidt tot snellere verwerking en minder behoefte aan middelen, namelijk random access memory (RAM) gebruik. Meer beschikbaar RAM-geheugen betekent over het algemeen meer ruimte voor cache, wat de schijftoegang zal versnellen. Het mooie van het schrijven van code die geheugenefficiënt is, is dat het niet noodzakelijkerwijs vereist dat u meer regels code schrijft.
- Een ander voordeel is dat het geheugenlek voorkomt, een probleem dat ervoor zorgt dat het RAM-gebruik voortdurend toeneemt, zelfs wanneer processen worden gedood, wat uiteindelijk leidt tot vertraagde of verminderde prestaties van het apparaat. Dit wordt veroorzaakt door het falen om gebruikt geheugen vrij te maken nadat de processen zijn beëindigd.
In de tech wereld, heb je misschien gehoord dat “gedaan is beter dan perfect”. Maar stel dat je twee ontwikkelaars hebt die Python hebben gebruikt bij het ontwikkelen van dezelfde app en ze hebben het binnen dezelfde hoeveelheid tijd voltooid. Een van hen heeft een meer geheugen-efficiënte code geschreven die resulteert in een sneller presterende app. Zou je liever kiezen voor de app die soepel loopt of voor de app die merkbaar langzamer loopt? Dit is een goed voorbeeld waarbij twee personen dezelfde hoeveelheid tijd besteden aan het coderen en toch merkbaar verschillende codeprestaties hebben.
Hier volgt wat u in de gids leert:
- Hoe wordt geheugen beheerd in Python?
- Python Garbage Collection
- Monitoring Python Memory Issue
- Best Practices for Improving Python Code Performance
How is Memory Managed in Python?
Volgens de Python-documentatie (3.9.0) voor geheugenbeheer, omvat het geheugenbeheer van Python een private heap die wordt gebruikt om de objecten en gegevensstructuren van uw programma op te slaan. Vergeet ook niet dat het de Python geheugenbeheerder is die het meeste vuile werk met betrekking tot geheugenbeheer afhandelt, zodat u zich gewoon op uw code kunt concentreren.
Python Geheugentoewijzing
Alles in Python is een object. Om deze objecten nuttig te laten zijn, moeten ze in het geheugen worden opgeslagen om te kunnen worden benaderd. Voordat ze in het geheugen kunnen worden opgeslagen, moet voor elk object eerst een stuk geheugen worden toegewezen.
Op het laagste niveau zal Python’s raw memory allocator er eerst voor zorgen dat er ruimte beschikbaar is in de private heap om deze objecten op te slaan. Het doet dit door te interageren met de geheugenbeheerder van uw besturingssysteem. Zie het als je Python programma dat je besturingssysteem vraagt om een stuk geheugen om mee te werken.
Op het volgende niveau werken verschillende object-specifieke allocators op dezelfde heap en implementeren verschillende management policies, afhankelijk van het object type. Zoals u wellicht al weet, zijn enkele voorbeelden van objecttypen strings en gehele getallen. Hoewel strings en gehele getallen misschien niet zo verschillend zijn als je bedenkt hoeveel tijd we nodig hebben om ze te herkennen en te onthouden, worden ze door computers heel anders behandeld. Dit komt omdat computers verschillende opslagvereisten en snelheidsafwegingen nodig hebben voor gehele getallen in vergelijking met strings.
Een laatste ding dat je moet weten over hoe Python’s heap wordt beheerd is dat je er nul controle over hebt. Nu vraagt u zich misschien af, hoe kunnen we dan geheugen-efficiënte code schrijven als we zo weinig controle hebben over Python’s geheugenbeheer? Voordat we daar op ingaan, moeten we eerst een aantal belangrijke termen met betrekking tot geheugenbeheer verder begrijpen.
Static vs. Dynamic Memory Allocation
Nu je begrijpt wat geheugenallocatie is, is het tijd om jezelf vertrouwd te maken met de twee soorten geheugenallocatie, namelijk statisch en dynamisch, en onderscheid te maken tussen de twee.
Statische geheugentoewijzing:
- Zoals het woord “statisch” suggereert, statisch toegewezen variabelen zijn permanent, wat betekent dat ze van tevoren moeten worden toegewezen en zo lang duren als het programma loopt.
- Geheugen wordt toegewezen tijdens compileertijd, of vóór de uitvoering van het programma.
- Geïmplementeerd met behulp van de stack-gegevensstructuur, wat betekent dat variabelen in het stack-geheugen worden opgeslagen.
- Geheugen dat is toegewezen kan niet worden hergebruikt, dus geen herbruikbaarheid van geheugen.
Dynamische geheugentoewijzing:
- Zoals het woord “dynamisch” suggereert, zijn dynamisch toegewezen variabelen niet permanent en kunnen ze worden toegewezen terwijl een programma wordt uitgevoerd.
- Geheugen wordt toegewezen tijdens runtime of tijdens de uitvoering van een programma.
- Geïmplementeerd met behulp van de heap-gegevensstructuur, wat betekent dat variabelen worden opgeslagen in het heap-geheugen.
- Geheugen dat is gealloceerd, kan worden vrijgegeven en hergebruikt.
Een voordeel van dynamische geheugentoewijzing in Python is dat we ons van tevoren geen zorgen hoeven te maken over hoeveel geheugen we nodig hebben voor ons programma. Een ander voordeel is dat manipulatie van gegevensstructuren vrijelijk kan worden gedaan zonder dat we ons zorgen hoeven te maken over de noodzaak van een hogere geheugentoewijzing als de gegevensstructuur uitbreidt.
Hoewel, omdat dynamische geheugentoewijzing wordt gedaan tijdens de uitvoering van het programma, zal het meer tijd vergen voor de voltooiing ervan. Ook moet geheugen dat is toegewezen, worden vrijgemaakt nadat het is gebruikt. Anders kunnen er mogelijk problemen zoals geheugenlekken optreden.
We zijn hierboven twee soorten geheugenstructuren tegengekomen – heap memory en stack memory. Laten we ze eens nader bekijken.
Stackgeheugen
Alle methoden en hun variabelen worden opgeslagen in het stackgeheugen. Weet je nog dat stackgeheugen wordt toegewezen tijdens het compileren? Dit betekent in feite dat de toegang tot dit type geheugen zeer snel is.
Wanneer in Python een methode wordt aangeroepen, wordt een stack frame toegewezen. Dit stack frame zal alle variabelen van de methode behandelen. Nadat de methode is teruggekeerd, wordt het stack frame automatisch vernietigd.
Merk op dat het stack frame ook verantwoordelijk is voor het instellen van de scope voor de variabelen van een methode.
Heap memory
Alle objecten en instance variabelen worden opgeslagen in het heap geheugen. Wanneer in Python een variabele wordt aangemaakt, wordt deze opgeslagen in een private heap, die vervolgens de mogelijkheid biedt tot allocatie en deallocatie.
Het heap-geheugen maakt het mogelijk dat deze variabelen globaal kunnen worden benaderd door alle methoden van uw programma. Nadat de variabele is teruggegeven, gaat de Python vuilnisman aan het werk, waarvan we de werking later zullen behandelen.
Nu gaan we eens kijken naar de geheugenstructuur van Python.
Python heeft drie verschillende niveaus als het gaat om zijn geheugenstructuur:
- Arena’s
- Pools
- Blokken
We beginnen met het grootste van allemaal – arena’s.
Arena’s
Stel je een bureau voor met 64 boeken die het hele oppervlak bedekken. De bovenkant van het bureau stelt één arena voor die een vaste grootte heeft van 256KiB die is toegewezen in de heap (Merk op dat KiB verschillend is van KB, maar je mag aannemen dat ze hetzelfde zijn voor deze uitleg). Een arena vertegenwoordigt de grootst mogelijke brok geheugen.
Meer specifiek, arena’s zijn geheugen mappings die worden gebruikt door de Python allocator, pymalloc, die is geoptimaliseerd voor kleine objecten (kleiner dan of gelijk aan 512 bytes). Arena’s zijn verantwoordelijk voor het toewijzen van geheugen, en daarom hoeven volgende structuren dat niet meer te doen.
Deze arena kan dan verder worden opgesplitst in 64 pools, wat de op een na grootste geheugenstructuur is.
Pools
Terugkomend op het voorbeeld van het bureau, vertegenwoordigen de boeken alle pools binnen één arena.
Elke pool heeft gewoonlijk een vaste grootte van 4Kb en kan drie mogelijke toestanden hebben:
- Leeg: De pool is leeg en dus beschikbaar voor toewijzing.
- Gebruikt: De pool bevat objecten waardoor deze noch leeg, noch vol is.
- Vol: De pool is vol en dus niet meer beschikbaar voor toewijzing.
Merk op dat de grootte van de pool moet overeenkomen met de standaard geheugen paginagrootte van uw besturingssysteem.
Een pool wordt dan opgedeeld in vele blokken, die de kleinste geheugenstructuren zijn.
Blokken
terugkomend op het bureau voorbeeld, de pagina’s binnen elk boek vertegenwoordigen alle blokken binnen een pool.
In tegenstelling tot arena’s en pools, is de grootte van een blok niet vast. De grootte van een blok varieert van 8 tot 512 bytes en moet een veelvoud van acht zijn.
Elk blok kan slechts één Python object van een bepaalde grootte opslaan en heeft drie mogelijke toestanden:
- Onaangeroerd: Is niet gealloceerd
- Free: Is gealloceerd maar is vrijgegeven en beschikbaar gemaakt voor allocatie
- Allocated: Is toegewezen
Merk op dat de drie verschillende niveaus van een geheugenstructuur (arenas, pools, en blocks) die we hierboven hebben besproken specifiek zijn voor kleinere Python objecten. Grote objecten worden doorverwezen naar de standaard C allocator binnen Python, wat een goede lezing zou zijn voor een andere dag.
Python Garbage Collection
Garbage collection is een proces dat wordt uitgevoerd door een programma om eerder toegewezen geheugen vrij te maken voor een object dat niet langer in gebruik is. Je kunt vuilnis toewijzen zien als geheugen recyclen of hergebruiken.
Ooit moesten programmeurs geheugen handmatig toewijzen en dealloceren. Vergeten geheugen te dealloceren kon leiden tot een geheugenlek, wat leidde tot een daling van de uitvoeringsprestaties. Erger nog, handmatig geheugen toewijzen en dealloceren kan zelfs leiden tot het per ongeluk overschrijven van geheugen, waardoor het programma helemaal kan crashen.
In Python, wordt garbage collection automatisch gedaan en bespaart u dus een hoop hoofdpijn om handmatig geheugen toewijzing en deallocatie te beheren. Python gebruikt referentietelling in combinatie met generieke afvalverzameling om ongebruikt geheugen vrij te maken. De reden waarom referentietelling alleen niet voldoende is voor Python is omdat het niet effectief dangling cyclische referenties opruimt.
Een generationele garbage collection cyclus bevat de volgende stappen –
- Python initialiseert een “discard list” voor ongebruikte objecten.
- Een algoritme wordt uitgevoerd om referentiecycli te detecteren.
- Als een object referenties van buitenaf mist, wordt het in de weggooilijst geplaatst.
- Maakt geheugentoewijzing vrij voor de objecten in de weggooilijst.
Om meer te leren over garbage collection in Python, kunt u kijken op onze Python Garbage Collection: A Guide for Developers post.
Monitoring Python Memory Issues
Hoewel iedereen van Python houdt, schrikt het er niet voor terug om geheugenproblemen te hebben. Er zijn veel mogelijke redenen.
Volgens de Python (3.9.0) documentatie voor geheugenbeheer, geeft de Python geheugenbeheerder het geheugen niet noodzakelijkerwijs terug aan uw besturingssysteem. In de documentatie staat dat “onder bepaalde omstandigheden de Python-geheugenbeheerder mogelijk niet de juiste acties in gang zet, zoals garbage collection, geheugencompactie of andere preventieve maatregelen.”
Dientengevolge kan het nodig zijn om expliciet geheugen vrij te maken in Python. Een manier om dit te doen is om de Python garbage collector te dwingen ongebruikt geheugen vrij te maken door gebruik te maken van de gc module. Men hoeft alleen maar gc.collect() uit te voeren om dit te doen. Dit levert echter alleen merkbare voordelen op bij het manipuleren van een zeer groot aantal objecten.
Naast het soms foutieve karakter van de Python garbage collector, vooral bij het werken met grote datasets, staan ook verschillende Python bibliotheken bekend om het veroorzaken van geheugenlekken. Pandas, bijvoorbeeld, is zo’n tool op de radar. Kijk maar eens naar alle geheugen-gerelateerde problemen in de officiële GitHub repository van pandas!
Een voor de hand liggende reden die zelfs langs de scherpe ogen van code reviewers kan glippen, is dat er grote objecten in de code blijven hangen die niet worden vrijgegeven. Ook oneindig groeiende gegevensstructuren zijn een reden tot zorg. Bijvoorbeeld een groeiende dictionary datastructuur zonder een vaste limiet voor de grootte.
Een manier om de groeiende datastructuur op te lossen is door de dictionary om te zetten in een lijst indien mogelijk en een maximale grootte voor de lijst in te stellen. Anders stelt u gewoon een limiet in voor de grootte van het woordenboek en wist u het wanneer de limiet is bereikt.
Nu vraagt u zich misschien af, hoe kan ik überhaupt geheugenproblemen opsporen? Een optie is om gebruik te maken van een Application Performance Monitoring (APM) tool. Daarnaast zijn er veel handige Python modules die je kunnen helpen om geheugenproblemen op te sporen en te traceren. Laten we eens kijken naar onze opties, te beginnen met APM-tools.
Application Performance Monitoring (APM) Tools
Dus wat is Application Performance Monitoring precies en hoe helpt het bij het opsporen van geheugenproblemen? Met een APM-tool kunt u real-time prestatiecijfers van een programma observeren, zodat u voortdurend kunt optimaliseren als u problemen ontdekt die de prestaties beperken.
Op basis van de rapporten die door APM-tools worden gegenereerd, kunt u een algemeen idee krijgen over hoe uw programma presteert. Aangezien u realtime prestatiecijfers kunt ontvangen en controleren, kunt u onmiddellijk actie ondernemen op geconstateerde problemen. Zodra u de mogelijke gebieden van uw programma hebt beperkt die de boosdoeners voor geheugenproblemen kunnen zijn, kunt u dan in de code duiken en het met de andere code medewerkers bespreken om verder de specifieke lijnen van code te bepalen die moeten worden hersteld.
Het opsporen van de wortel van geheugenlek problemen zelf kan een ontmoedigende taak zijn. Het oplossen ervan is een andere nachtmerrie, omdat u uw code echt moet begrijpen. Als u zich ooit in die positie bevindt, zoek dan niet verder want ScoutAPM is een bekwaam APM gereedschap dat constructief de prestaties van uw applicatie kan analyseren en optimaliseren. ScoutAPM geeft u real-time inzicht, zodat u snel &problemen kunt opsporen en oplossen voordat uw klanten ze kunnen opmerken.
Profielmodules
Er zijn veel handige Python-modules die u kunt gebruiken om geheugenproblemen op te lossen, of het nu gaat om een geheugenlek of uw programma dat crasht door overmatig geheugengebruik. Twee van de aanbevolen modules zijn:
- tracemalloc
- memory-profiler
Merk op dat alleen de tracemalloc module is ingebouwd, dus zorg ervoor dat u eerst de andere module installeert als u deze wilt gebruiken.
tracemalloc
Volgens de Python (3.9.0) documentatie voor tracemalloc kan het gebruik van deze module u de volgende informatie verschaffen:
- Traceback waar een object werd gealloceerd.
- Statistieken over toegewezen geheugenblokken per bestandsnaam en per regelnummer: totale grootte, aantal, en de gemiddelde grootte van toegewezen geheugenblokken.
- Bereken het verschil tussen twee snapshots om geheugenlekken te detecteren.
Een aanbevolen eerste stap die u moet doen om de bron van het geheugenprobleem te bepalen, is om eerst de bestanden weer te geven die het meeste geheugen toewijzen. U kunt dit eenvoudig doen met behulp van het eerste code voorbeeld dat in de documentatie wordt getoond.
Dit betekent echter niet dat bestanden die een kleine hoeveelheid geheugen toewijzen, niet oneindig zullen groeien om in de toekomst geheugenlekken te veroorzaken.
memory_profiler
Deze module is een leuke. Ik heb hiermee gewerkt en het is een persoonlijke favoriet omdat het de mogelijkheid biedt om eenvoudig de @profile decorator toe te voegen aan elke functie die je wilt onderzoeken. De output die als resultaat wordt gegeven is ook heel gemakkelijk te begrijpen.
Een andere reden waarom dit mijn persoonlijke favoriet is, is dat deze module je in staat stelt om een grafiek te plotten van tijd-gebaseerd geheugengebruik. Soms heb je gewoon een snelle controle nodig om te zien of het geheugengebruik oneindig blijft toenemen of niet. Dit is de perfecte oplossing daarvoor omdat je geen regel-voor-regel geheugenprofilering hoeft te doen om dat te bevestigen. U kunt gewoon de geplotte grafiek bekijken nadat u de profiler gedurende een bepaalde tijd hebt laten draaien. Hier is een voorbeeld van de grafiek die wordt weergegeven –
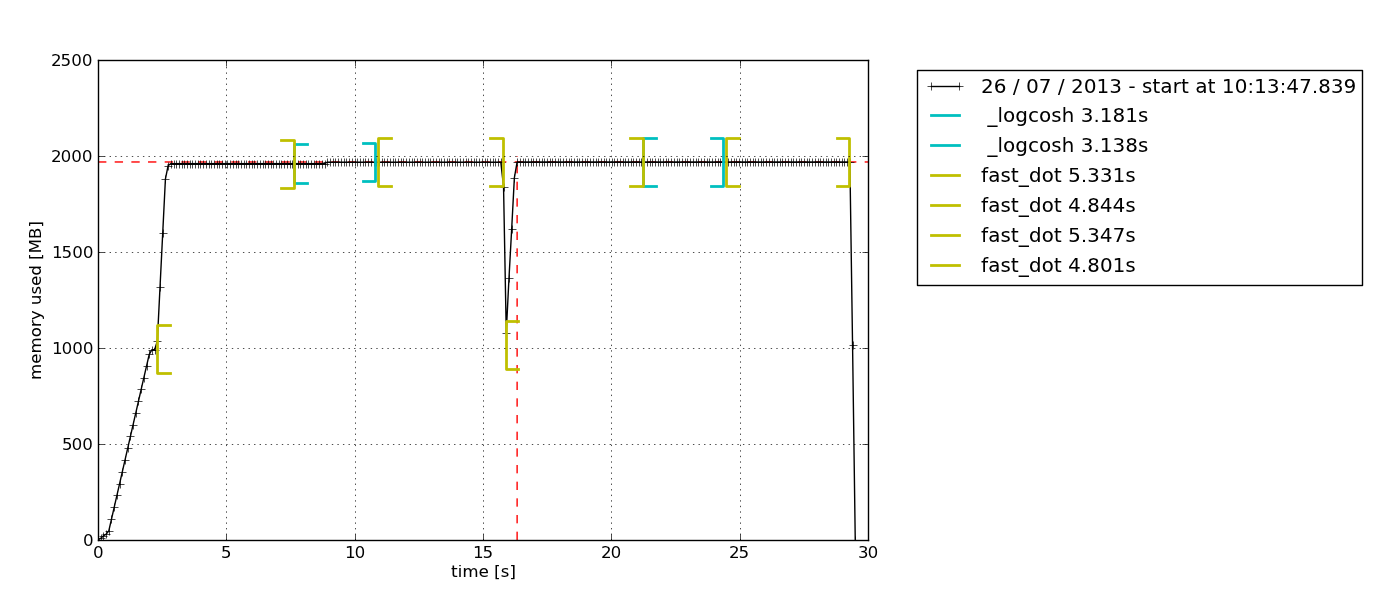
Volgens de beschrijving in de documentatie van de memory-profiler is deze Python-module bedoeld voor het monitoren van het geheugengebruik van een proces, evenals voor een regel-voor-regel-analyse van hetzelfde voor Python-programma’s. Het is een pure Python module die afhankelijk is van de psutil bibliotheek.
Ik raad aan deze Medium blog te lezen om verder te onderzoeken hoe memory-profiler wordt gebruikt. Daar leer je ook hoe je een andere Python-module kunt gebruiken, muppy (de nieuwste is muppy3).
Best Practices for Improving Python Code Performance
Genoeg van alle details over geheugenbeheer. Laten we nu eens kijken naar een aantal goede gewoonten bij het schrijven van geheugenefficiënte Python-code.
Profiteer van Python-bibliotheken en ingebouwde functies
Ja, dit is een goede gewoonte die misschien nogal eens over het hoofd wordt gezien. Python heeft een ongeëvenaarde ondersteuning van de gemeenschap en dit wordt weerspiegeld door de overvloedige Python-bibliotheken die beschikbaar zijn voor zowat elk doel, variërend van API-oproepen tot data science.
Als er een Python-bibliotheek is waarmee u hetzelfde kunt doen als wat u al hebt geïmplementeerd, wat u kunt doen is de prestaties van uw code vergelijken wanneer u de bibliotheek gebruikt in vergelijking met wanneer u uw aangepaste code gebruikt. De kans is groot dat Python bibliotheken (vooral de populaire) geheugenefficiënter zijn dan uw code omdat ze voortdurend worden verbeterd op basis van feedback van de gemeenschap. Vertrouwt u liever op code die van de ene op de andere dag is gemaakt of op code die gedurende een langere periode rigoureus is verbeterd?
En het mooiste van alles is dat Python-bibliotheken u veel regels code besparen, dus waarom niet?
Niet “+” gebruiken voor string aaneenschakeling
Ooit hebben we ons allemaal schuldig gemaakt aan het aaneenschakelen van strings met behulp van de “+”-operator omdat het er zo gemakkelijk uitziet.
Merk op dat strings onveranderlijk zijn. Dus elke keer dat je een element toevoegt aan een string met de “+” operator, moet Python een nieuwe string maken met een nieuwe geheugentoewijzing. Met langere strings, zal de geheugen inefficiëntie van de code meer uitgesproken worden.
Het gebruik van itertools voor efficient looping
Looping is een essentieel onderdeel van het automatiseren van dingen. Naarmate we meer en meer lussen gebruiken, zullen we uiteindelijk geneste lussen moeten gebruiken, waarvan bekend is dat ze inefficiënt zijn vanwege hun hoge runtime complexiteit.
Dit is waar de itertools module ons te hulp schiet. Volgens de Python itertools documentatie, “De module standaardiseert een kernset van snelle, geheugen-efficiënte tools die nuttig zijn op zichzelf of in combinatie. Samen maken ze het mogelijk om gespecialiseerde tools beknopt en efficiënt te construeren in pure Python.”
Met andere woorden, de itertools module maakt geheugen-efficiënt looping mogelijk door zich te ontdoen van onnodige lussen. Interessant genoeg wordt de itertools module een juweeltje genoemd omdat het elegante oplossingen voor een groot aantal problemen mogelijk maakt.
Ik ben er vrij zeker van dat je in je volgende stuk code met minstens één lus zult werken, dus probeer itertools dan eens te implementeren!
Recap and Closing Thoughts
Het toepassen van goede Python geheugenbeheer gewoonten is niet voor de gelegenheids-programmeur weggelegd. Als je meestal eenvoudige scripts maakt, zou je helemaal niet tegen geheugenproblemen aan moeten lopen. Dankzij hardware en software die snel blijven evolueren terwijl je dit leest, zou het basismodel van zowat elk toestel dat er is, ongeacht het merk, alledaagse programma’s prima moeten draaien. De noodzaak voor geheugen-efficiënte code begint pas te tonen wanneer je begint te werken aan een grote codebase, vooral voor productie, waar prestaties de sleutel zijn.
Dit suggereert echter niet dat geheugenbeheer in Python een moeilijk concept is om te begrijpen, noch betekent dit dat het niet belangrijk is. Dit komt omdat de nadruk op de prestaties van applicaties elke dag groter wordt. Op een dag zal het niet meer alleen een kwestie zijn van “klaar”. In plaats daarvan zullen ontwikkelaars concurreren om een oplossing te leveren die niet alleen in staat is om de behoeften van klanten succesvol op te lossen, maar dat ook nog eens doet met een enorme snelheid en minimale middelen.