- Inleiding
- Definities
- TensorFlow/Keras
- Afbeeldingherkenning (Classificatie)
- Feature Extractie
- Hoe neurale netwerken leren om afbeeldingen te herkennen
- Feature Extractie met Filters
- Activeringsfuncties
- Pooling Lagen
- Flatten
- Full Connected Layer
- De Machine Learning Workflow
- Gegevensvoorbereiding
- Het model maken
- Trainen van het model
- Model Evaluatie
- Afbeeldingherkenning met een CNN
- Prepping the Data
- Het model ontwerpen
- Maak het model
- Conclusie
Inleiding
Een van de meest voorkomende toepassingen van TensorFlow en Keras is het herkennen/classificeren van afbeeldingen. Als je wilt leren hoe je Keras kunt gebruiken om afbeeldingen te classificeren of herkennen, leert dit artikel je hoe.
Definities
Als de basisconcepten achter beeldherkenning je niet duidelijk zijn, zal het moeilijk zijn om de rest van dit artikel volledig te begrijpen. Dus laten we, voordat we verder gaan, even de tijd nemen om enkele termen te definiëren.
TensorFlow/Keras

Credit: commons.wikimedia.org
TensorFlow is een open-source bibliotheek gemaakt voor Python door het Google Brain-team. TensorFlow compileert veel verschillende algoritmes en modellen samen, waardoor de gebruiker diepe neurale netwerken kan implementeren voor gebruik in taken zoals beeldherkenning/classificatie en natuurlijke taalverwerking. TensorFlow is een krachtig raamwerk dat functioneert door een reeks verwerkingsknooppunten te implementeren, waarbij elk knooppunt een wiskundige bewerking vertegenwoordigt, waarbij de hele reeks knooppunten een “grafiek” wordt genoemd.
In termen van Keras, het is een high-level API (application programming interface) die de functies van TensorFlow eronder kan gebruiken (evenals andere ML-bibliotheken zoals Theano). Keras is ontworpen met gebruikersvriendelijkheid en modulariteit als leidende principes. In praktische termen maakt Keras het implementeren van de vele krachtige maar vaak complexe functies van TensorFlow zo eenvoudig mogelijk, en het is geconfigureerd om met Python te werken zonder grote aanpassingen of configuratie.
Afbeeldingherkenning (Classificatie)
Afbeeldingherkenning verwijst naar de taak om een afbeelding in een neuraal netwerk in te voeren en het een soort label voor die afbeelding te laten uitvoeren. Het label dat het netwerk afgeeft, komt overeen met een vooraf gedefinieerde klasse. Er kunnen meerdere klassen zijn waarin het beeld kan worden gelabeld, of slechts één. Als er een enkele klasse is, wordt vaak de term “herkenning” gebruikt, terwijl een multi-klasse herkenningstaak vaak “classificatie” wordt genoemd.
Een subset van beeldclassificatie is objectdetectie, waarbij specifieke instanties van objecten worden geïdentificeerd als behorend tot een bepaalde klasse, zoals dieren, auto’s of mensen.
Feature Extractie
Om beeldherkenning/classificatie uit te voeren, moet het neurale netwerk feature-extractie uitvoeren. Kenmerken zijn de elementen van de gegevens waar je om geeft en die door het netwerk zullen worden gevoerd. In het specifieke geval van beeldherkenning zijn de kenmerken de groepen pixels, zoals randen en punten, van een object die het netwerk zal analyseren op patronen.
Featureherkenning (of feature-extractie) is het proces waarbij de relevante kenmerken uit een inputafbeelding worden gehaald, zodat deze kenmerken kunnen worden geanalyseerd. Veel afbeeldingen bevatten annotaties of metadata over de afbeelding die het netwerk helpen de relevante kenmerken te vinden.
Hoe neurale netwerken leren om afbeeldingen te herkennen
Het krijgen van een intuïtie van hoe een neuraal netwerk afbeeldingen herkent, zal u helpen wanneer u een neuraal netwerkmodel implementeert, dus laten we het beeldherkenningsproces in de volgende paar secties kort verkennen.
Feature Extractie met Filters
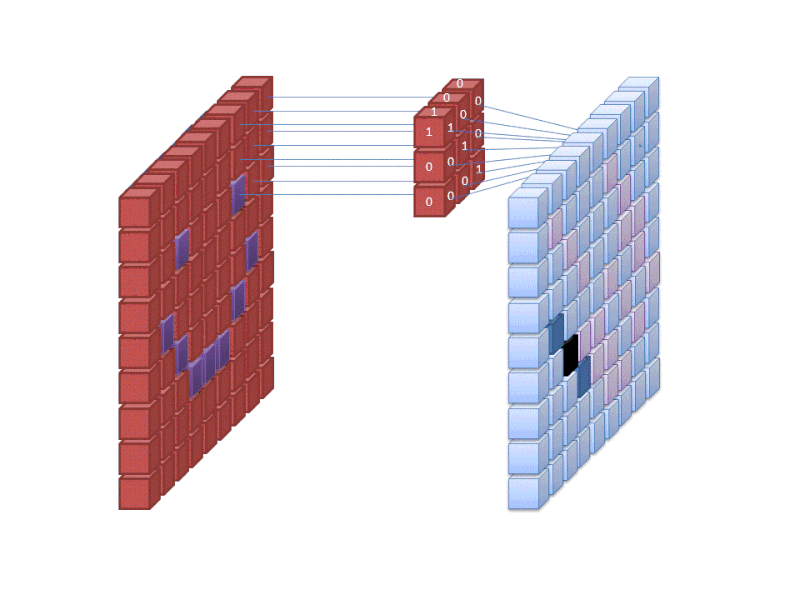
Credit: commons.wikimedia.org
De eerste laag van een neuraal netwerk neemt alle pixels in een afbeelding op. Nadat alle gegevens in het netwerk zijn ingevoerd, worden verschillende filters op het beeld toegepast, waardoor representaties van verschillende delen van het beeld worden gevormd. Dit is het extraheren van kenmerken en het creëert “kenmerkenkaarten”.
Dit proces van het extraheren van kenmerken uit een beeld wordt bereikt met een “convolutionele laag”, en convolutie is eenvoudigweg het vormen van een representatie van een deel van een beeld. Het is van dit convolutieconcept dat we de term Convolutioneel Neuraal Netwerk (CNN) krijgen, het type neuraal netwerk dat het meest wordt gebruikt in beeldclassificatie/herkenning.
Als je wilt visualiseren hoe het maken van kenmerkenkaarten werkt, denk dan aan het schijnen van een zaklamp over een foto in een donkere kamer. Terwijl je de straal over de foto laat glijden, leer je over de kenmerken van de afbeelding. Een filter is wat het netwerk gebruikt om een representatie van het beeld te vormen, en in deze metafoor is het licht van de zaklamp het filter.
De breedte van de straal van je zaklamp bepaalt hoeveel van het beeld je in één keer onderzoekt, en neurale netwerken hebben een vergelijkbare parameter, de filtergrootte. De filtergrootte bepaalt hoeveel pixels van het beeld in één keer worden onderzocht. Een gebruikelijke filtergrootte die in CNN’s wordt gebruikt, is 3, en dit omvat zowel de hoogte als de breedte, zodat het filter een gebied van 3 x 3 pixels onderzoekt.
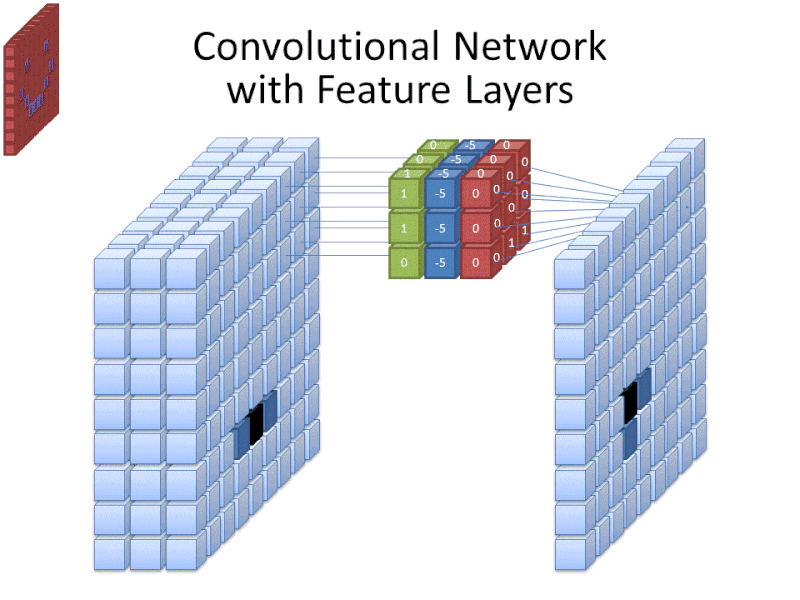
Credit: commons.wikimedia.org
Terwijl de filtergrootte de hoogte en breedte van het filter omvat, moet ook de diepte van het filter worden opgegeven.
Hoe kan een 2D-afbeelding diepte hebben?
Digitale afbeeldingen worden weergegeven als hoogte, breedte en een RGB-waarde die de kleuren van de pixel definieert, dus de “diepte” die wordt gevolgd, is het aantal kleurkanalen dat de afbeelding heeft. Grayscale (niet-kleuren) beelden hebben slechts 1 kleurkanaal, terwijl kleurenbeelden 3 diepte-kanalen hebben.
Dit alles betekent dat voor een filter van grootte 3 toegepast op een full-color beeld, de afmetingen van dat filter 3 x 3 x 3 zullen zijn. Voor elke pixel die door dat filter wordt bestreken, vermenigvuldigt het netwerk de filterwaarden met de waarden in de pixels zelf om een numerieke weergave van die pixel te krijgen. Dit proces wordt dan voor het gehele beeld uitgevoerd om een volledige voorstelling te krijgen. Het filter wordt over de rest van het beeld verplaatst volgens een parameter die “stride” wordt genoemd, en die bepaalt hoeveel pixels het filter moet worden verplaatst nadat het de waarde in zijn huidige positie heeft berekend. Een conventionele stride-grootte voor een CNN is 2.
Het eindresultaat van al deze berekeningen is een feature map. Dit proces wordt meestal uitgevoerd met meer dan een filter, wat helpt de complexiteit van het beeld te behouden.
Activeringsfuncties
Nadat de feature map van het beeld is gemaakt, worden de waarden die het beeld representeren door een activeringsfunctie of activeringslaag geleid. De activeringsfunctie neemt de waarden die het beeld vertegenwoordigen, en die dankzij de convolutionele laag lineair zijn (d.w.z. slechts een lijst getallen), en verhoogt de niet-lineariteit ervan, aangezien beelden zelf niet-lineair zijn.
De typische activeringsfunctie die wordt gebruikt om dit te bereiken is een Gerectificeerde Lineaire Eenheid (ReLU), hoewel er enkele andere activeringsfuncties zijn die af en toe worden gebruikt (u kunt daarover hier lezen).
Pooling Lagen
Nadat de gegevens zijn geactiveerd, worden ze door een pooling-laag gestuurd. Pooling “downsamples” een beeld, wat betekent dat het de informatie neemt die het beeld vertegenwoordigt en comprimeert, waardoor het kleiner wordt. Het poolingproces maakt het netwerk flexibeler en bedrevener in het herkennen van objecten/afbeeldingen op basis van de relevante kenmerken.
Wanneer we naar een afbeelding kijken, zijn we meestal niet bezig met alle informatie in de achtergrond van de afbeelding, alleen met de kenmerken waar we om geven, zoals mensen of dieren.
Op vergelijkbare wijze zal een pooling-laag in een CNN de onnodige delen van het beeld abstraheren, en alleen de delen van het beeld behouden waarvan het denkt dat ze relevant zijn, zoals gecontroleerd door de gespecificeerde grootte van de pooling-laag.
Omdat het beslissingen moet nemen over de meest relevante delen van het beeld, hoopt men dat het netwerk alleen die delen van het beeld zal leren die werkelijk het object in kwestie vertegenwoordigen. Dit helpt overfitting te voorkomen, waarbij het netwerk aspecten van het trainingsgeval te goed leert en er niet in slaagt te generaliseren naar nieuwe gegevens.
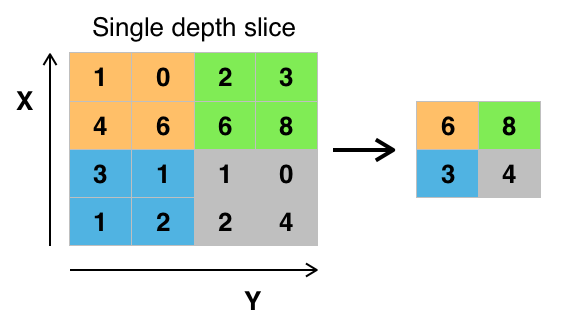
Credit: commons.wikimedia.org
Er zijn verschillende manieren om waarden te poolen, maar max pooling wordt het vaakst gebruikt. Max pooling verkrijgt de maximale waarde van de pixels binnen een enkel filter (binnen een enkele plek in de afbeelding). Hierdoor valt 3/4e van de informatie weg, ervan uitgaande dat 2 x 2 filters worden gebruikt.
De maximale waarden van de pixels worden gebruikt om rekening te houden met mogelijke beeldvervormingen, en de parameters/grootte van het beeld worden gereduceerd om overfitting tegen te gaan. Er zijn andere soorten pooling, zoals average pooling of sum pooling, maar deze worden niet zo vaak gebruikt omdat max pooling de neiging heeft een betere nauwkeurigheid op te leveren.
Flatten
De laatste lagen van onze CNN, de dicht op elkaar aangesloten lagen, vereisen dat de gegevens in de vorm van een vector worden verwerkt. Om deze reden moeten de gegevens worden “platgemaakt”. De waarden worden gecomprimeerd tot een lange vector of een kolom van opeenvolgende geordende getallen.
Full Connected Layer
De laatste lagen van de CNN zijn dicht verbonden lagen, of een kunstmatig neuraal netwerk (ANN). De belangrijkste functie van het ANN is het analyseren van de inputkenmerken en deze te combineren tot verschillende kenmerken die zullen helpen bij de classificatie. Deze lagen vormen in wezen verzamelingen neuronen die verschillende delen van het object in kwestie vertegenwoordigen, en een verzameling neuronen kan de flaporen van een hond of de roodheid van een appel vertegenwoordigen. Wanneer genoeg van deze neuronen worden geactiveerd in reactie op een inputbeeld, zal het beeld worden geclassificeerd als een object.

Credit: commons.wikimedia.org
De fout, of het verschil tussen de berekende waarden en de verwachte waarde in de trainingsset, wordt berekend door het ANN. Het netwerk ondergaat dan backpropagation, waarbij de invloed van een bepaald neuron op een neuron in de volgende laag wordt berekend en de invloed wordt aangepast. Dit wordt gedaan om de prestaties van het model te optimaliseren. Dit proces wordt vervolgens keer op keer herhaald. Op deze manier traint het netwerk op gegevens en leert het associaties tussen inputkenmerken en outputklassen.
De neuronen in de middelste volledig verbonden lagen zullen binaire waarden produceren met betrekking tot de mogelijke klassen. Als u vier verschillende klassen hebt (laten we zeggen een hond, een auto, een huis en een persoon), zal het neuron een “1”-waarde hebben voor de klasse waarvan het gelooft dat het beeld vertegenwoordigt en een “0”-waarde voor de andere klassen.
De laatste volledig aangesloten laag ontvangt de uitvoer van de laag ervoor en levert een waarschijnlijkheid voor elk van de klassen, gesommeerd tot één. Als er een waarde van 0,75 in de categorie “hond” is, vertegenwoordigt dit een zekerheid van 75% dat de afbeelding een hond is.
De beeldclassificator is nu getraind, en afbeeldingen kunnen aan de CNN worden doorgegeven, die nu een gok over de inhoud van die afbeelding zal uitvoeren.
De Machine Learning Workflow
Voordat we in een voorbeeld van het trainen van een beeldclassificator springen, nemen we even de tijd om de machine learning workflow of pijplijn te begrijpen. Het proces voor het trainen van een neuraal netwerkmodel is vrij standaard en kan worden onderverdeeld in vier verschillende fasen.
Gegevensvoorbereiding
Voreerst moet u uw gegevens verzamelen en deze in een vorm brengen waarop het netwerk kan trainen. Dit houdt in het verzamelen van afbeeldingen en het labelen ervan. Zelfs als je een dataset hebt gedownload die iemand anders heeft voorbereid, moet je waarschijnlijk nog voorbewerken of voorbereiden voordat je de gegevens kunt gebruiken om te trainen. Het voorbereiden van gegevens is een kunst op zich, waarbij je te maken krijgt met zaken als ontbrekende waarden, beschadigde gegevens, gegevens in het verkeerde formaat, onjuiste labels, enz.
In dit artikel zullen we een voorbewerkte gegevensverzameling gebruiken.
Het model maken
Het maken van het neurale netwerkmodel houdt in dat je keuzes moet maken over verschillende parameters en hyperparameters. U moet beslissingen nemen over het aantal lagen dat u in uw model wilt gebruiken, wat de in- en uitvoer van de lagen zal zijn, wat voor soort activeringsfuncties u zult gebruiken, of u al dan niet drop-out zult gebruiken, enz.
Het leren welke parameters en hyperparameters je moet gebruiken kost tijd (en veel studie), maar er zijn een aantal heuristieken die je kunt gebruiken om direct aan de slag te gaan en we zullen er een aantal behandelen tijdens het implementatievoorbeeld.
Trainen van het model
Nadat je je model hebt gemaakt, maak je eenvoudigweg een instantie van het model en pas je het met je trainingsgegevens. De belangrijkste overweging bij het trainen van een model is de hoeveelheid tijd die het model nodig heeft om te trainen. Je kunt de duur van de training voor een netwerk bepalen door het aantal tijdperken op te geven waarover moet worden getraind. Hoe langer u een model traint, hoe beter het zal presteren, maar als u te veel epochs traint, riskeert u overfitting.
Het kiezen van het aantal epochs om te trainen is iets waar u gevoel voor krijgt, en het is gebruikelijk om de gewichten van een netwerk op te slaan tussen trainingssessies in, zodat u niet opnieuw hoeft te beginnen als u eenmaal enige vooruitgang hebt geboekt met het trainen van het netwerk.
Model Evaluatie
Er zijn meerdere stappen om het model te evalueren. De eerste stap bij het evalueren van het model is het vergelijken van de prestaties van het model met een validatiedataset, een dataset waarop het model nog niet is getraind. U zult de prestaties van het model vergelijken met deze validatieset en de prestaties analyseren aan de hand van verschillende metrieken.
Er zijn verschillende metrieken voor het bepalen van de prestaties van een neuraal netwerkmodel, maar de meest voorkomende metriek is “nauwkeurigheid”, het aantal correct geclassificeerde afbeeldingen gedeeld door het totale aantal afbeeldingen in uw dataset.
Nadat je de nauwkeurigheid van de prestaties van het model op een validatie dataset hebt gezien, ga je meestal terug en train je het netwerk opnieuw met licht aangepaste parameters, omdat het onwaarschijnlijk is dat je tevreden zult zijn met de prestaties van je netwerk de eerste keer dat je traint. Je blijft de parameters van je netwerk aanpassen, opnieuw trainen en de prestaties meten totdat je tevreden bent met de nauwkeurigheid van het netwerk.
Ten slotte test je de prestaties van het netwerk op een testset. Deze testset is een andere verzameling gegevens die je model nog nooit heeft gezien.
Misschien vraag je je af:
Waarom die testset? Als je een idee krijgt van de nauwkeurigheid van je model, is dat dan niet het doel van de validatieset?
Het is een goed idee om een partij gegevens die het netwerk nog nooit heeft gezien, te bewaren voor testen, omdat alle aanpassingen aan de parameters die je doet, in combinatie met het opnieuw testen op de validatieset, ertoe kunnen leiden dat je netwerk een aantal eigenaardigheden van de validatieset heeft geleerd die niet zullen generaliseren naar gegevens die buiten de steekproeven vallen.
Daarom is het doel van de testset om te controleren op zaken als overfitting en er meer vertrouwen in te hebben dat je model echt geschikt is om in de echte wereld te presteren.
Afbeeldingherkenning met een CNN
We hebben tot nu toe veel behandeld, en als al deze informatie een beetje overweldigend is geweest, zou het zien van deze concepten samenkomen in een voorbeeldclassifier getraind op een dataset deze concepten concreter moeten maken. Laten we daarom eens kijken naar een volledig voorbeeld van beeldherkenning met Keras, van het laden van de gegevens tot de evaluatie.

Credit: www.cs.toronto.edu
Om te beginnen hebben we een dataset nodig om op te trainen. In dit voorbeeld gebruiken we de beroemde CIFAR-10 dataset. CIFAR-10 is een grote beelddataset met meer dan 60.000 afbeeldingen die 10 verschillende klassen van objecten vertegenwoordigen, zoals katten, vliegtuigen en auto’s.
De afbeeldingen zijn full-color RGB, maar ze zijn vrij klein, slechts 32 x 32. Een geweldig ding over de CIFAR-10 dataset is dat het wordt geleverd voorverpakt met Keras, dus het is heel gemakkelijk om de dataset te laden en de afbeeldingen hebben heel weinig voorbewerking nodig.
Het eerste wat we moeten doen, is de nodige bibliotheken importeren. Ik zal laten zien hoe deze importen worden gebruikt als we verder gaan, maar voor nu weet dat we gebruik zullen maken van Numpy, en verschillende modules geassocieerd met Keras:
import numpyfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activationfrom keras.layers.convolutional import Conv2D, MaxPooling2Dfrom keras.constraints import maxnormfrom keras.utils import np_utilsWe gaan hier een willekeurig zaad gebruiken zodat de resultaten die in dit artikel zijn bereikt door jou kunnen worden gerepliceerd, daarom hebben we numpy nodig:
# Set random seed for purposes of reproducibilityseed = 21Prepping the Data
We hebben nog een import nodig: de dataset.
from keras.datasets import cifar10Nu gaan we de dataset inladen. Dat kunnen we eenvoudig doen door op te geven in welke variabelen we de gegevens willen laden, en dan de functie load_data() te gebruiken:
# loading in the data (X_train, y_train), (X_test, y_test) = cifar10.load_data()In de meeste gevallen moet u uw gegevens wat voorbewerken om ze gebruiksklaar te maken, maar omdat we een voorverpakte dataset gebruiken, hoeft er maar weinig voorbewerkt te worden. Eén ding dat we willen doen is de invoergegevens normaliseren.
Als de waarden van de invoergegevens in een te groot bereik liggen, kan dit een negatieve invloed hebben op hoe het netwerk presteert. In dit geval zijn de invoerwaarden de pixels in de afbeelding, die een waarde hebben tussen 0 en 255.
Om de gegevens te normaliseren kunnen we dus simpelweg de beeldwaarden delen door 255. Om dit te doen moeten we eerst van de gegevens een float-type maken, omdat het nu gehele getallen zijn. We kunnen dit doen door het astype() Numpy commando te gebruiken en dan te verklaren welk datatype we willen:
# normalize the inputs from 0-255 to between 0 and 1 by dividing by 255 X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = X_train / 255.0X_test = X_test / 255.0Een ander ding dat we moeten doen om de data klaar te maken voor het netwerk is de waarden een-hot coderen. Ik zal hier niet ingaan op de details van one-hot codering, maar voor nu weet dat de beelden niet kunnen worden gebruikt door het netwerk zoals ze zijn, ze moeten eerst worden gecodeerd en one-hot codering wordt het beste gebruikt bij het doen van binaire classificatie.
We zijn hier effectief bezig met binaire classificatie, omdat een beeld ofwel tot een klasse behoort of niet, het kan niet ergens tussenin vallen. Het Numpy commando to_categorical() wordt gebruikt om één-hot te coderen. Daarom hebben we de functie np_utils uit Keras geïmporteerd, omdat die to_categorical() bevat.
We moeten ook het aantal klassen in de dataset opgeven, zodat we weten tot hoeveel neuronen we de laatste laag moeten comprimeren:
# one hot encode outputsy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)class_num = y_test.shapeHet model ontwerpen
We zijn nu bij het stadium aangekomen waarin we het CNN-model ontwerpen. Het eerste wat we moeten doen is het formaat bepalen dat we willen gebruiken voor het model, Keras heeft verschillende formaten of blauwdrukken om modellen op te bouwen, maar Sequential is het meest gebruikte, en om die reden hebben we het geïmporteerd uit Keras.
Maak het model
model = Sequential()De eerste laag van ons model is een convolutionele laag. Het zal de inputs binnenhalen en convolutionele filters op hen uitvoeren.
Wanneer we deze in Keras implementeren, moeten we het aantal kanalen/filters opgeven dat we willen (dat zijn de 32 hieronder), de grootte van het filter dat we willen (3 x 3 in dit geval), de inputvorm (bij het maken van de eerste laag) en de activering en padding die we nodig hebben.
Zoals gezegd is relu de meest gebruikelijke activering, en padding='same' betekent alleen dat we de grootte van de afbeelding helemaal niet veranderen:
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape, padding='same'))model.add(Activation('relu'))Note: U kunt de activeringen en opvullingen ook aan elkaar rijgen, zoals dit:
model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), activation='relu', padding='same'))Nu zullen we een dropout-laag maken om overfitting te voorkomen, die functioneert door willekeurig enkele verbindingen tussen de lagen te elimineren (0.2 betekent dat 20% van de bestaande verbindingen wegvalt):
model.add(Dropout(0.2))Wij willen hier misschien ook een batch-normalisatie uitvoeren. Batchnormalisatie normaliseert de ingangen die naar de volgende laag gaan, zodat het netwerk altijd activeringen creëert met dezelfde verdeling die we wensen:
model.add(BatchNormalization())Nu komt er weer een convolutionele laag, maar de filtergrootte neemt toe zodat het netwerk complexere representaties kan leren:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))Hier is de pooling-laag, zoals eerder besproken helpt dit om de beeldclassificator robuuster te maken zodat het relevante patronen kan leren. Er is ook de dropout en batch normalisatie:
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization())Dat is de basis stroom voor de eerste helft van een CNN implementatie: Convolutional, activatie, dropout, pooling. Je kunt nu zien waarom we Dropout, BatchNormalization, Activation, Conv2d, en MaxPooling2d hebben geïmporteerd.
Je kunt het precieze aantal convolutionele lagen dat je hebt naar wens variëren, hoewel elke laag meer rekenkosten toevoegt. Merk op dat als je convolutionele lagen toevoegt, je typisch hun aantal filters verhoogt, zodat het model complexere voorstellingen kan leren. Als de aantallen die je voor deze lagen kiest enigszins willekeurig lijken, weet dan dat je in het algemeen de filters steeds verder uitbreidt en dat het aan te raden is om ze machten van 2 te maken, wat een klein voordeel kan opleveren bij het trainen op een GPU.
Het is belangrijk om niet te veel pooling lagen te hebben, omdat elke pooling wat data weggooit. Te vaak poolen leidt ertoe dat de dicht op elkaar aangesloten lagen bijna niets meer te weten kunnen komen wanneer de gegevens hen bereiken.
Het precieze aantal pooling-lagen dat u moet gebruiken, hangt af van de taak die u uitvoert, en is iets waar u na verloop van tijd gevoel voor krijgt. Omdat de afbeeldingen hier al zo klein zijn, zullen we niet meer dan twee keer poolen.
U kunt deze lagen nu herhalen om uw netwerk meer representaties te geven om mee te werken:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Nadat we klaar zijn met de convolutionele lagen, moeten we de gegevens Flatten, dat is waarom we de functie hierboven hebben geïmporteerd. We voegen ook weer een dropout-laag toe:
model.add(Flatten())model.add(Dropout(0.2))Nu maken we gebruik van de Dense import en maken we de eerste dicht verbonden laag. We moeten het aantal neuronen in de dichte laag opgeven. Merk op dat het aantal neuronen in de opeenvolgende lagen afneemt, om uiteindelijk hetzelfde aantal neuronen te benaderen als er klassen in de dataset zijn (in dit geval 10). De kernelrestrictie kan de gegevens reguleren terwijl het leert, nog iets dat helpt overfitting te voorkomen. Daarom hebben we eerder maxnorm geïmporteerd.
model.add(Dense(256, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Dense(128, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())In deze laatste laag geven we het aantal klassen door voor het aantal neuronen. Elk neuron vertegenwoordigt een klasse, en de output van deze laag zal een vector van 10 neuronen zijn, waarbij elk neuron een waarschijnlijkheid opslaat dat het beeld in kwestie behoort tot de klasse die het vertegenwoordigt.
Ten slotte selecteert de activeringsfunctie softmax het neuron met de hoogste waarschijnlijkheid als output, waarbij wordt aangenomen dat het beeld tot die klasse behoort:
model.add(Dense(class_num))model.add(Activation('softmax'))Nu we het model hebben ontworpen dat we willen gebruiken, hoeven we het alleen nog maar te compileren. Laten we het aantal tijdperken specificeren waarvoor we willen trainen, evenals de optimizer die we willen gebruiken.
De optimizer is wat de gewichten in uw netwerk zal afstemmen om het punt van het laagste verlies te benaderen. Het Adam-algoritme is een van de meest gebruikte optimizers, omdat het voor de meeste problemen goede prestaties levert:
epochs = 25optimizer = 'adam'Laten we nu het model compileren met de door ons gekozen parameters. Laten we ook een metriek specificeren om te gebruiken.
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=)We kunnen de modelsamenvatting uitprinten om te zien hoe het hele model eruit ziet.
print(model.summary())Het uitprinten van de samenvatting geeft ons een heleboel info:
Results: Layer (type) Output Shape Param #=================================================================conv2d_1 (Conv2D) (None, 32, 32, 32) 896_________________________________________________________________activation_1 (Activation) (None, 32, 32, 32) 0_________________________________________________________________dropout_1 (Dropout) (None, 32, 32, 32) 0_________________________________________________________________batch_normalization_1 (Batch (None, 32, 32, 32) 128_________________________________________________________________conv2d_2 (Conv2D) (None, 32, 32, 64) 18496_________________________________________________________________activation_2 (Activation) (None, 32, 32, 64) 0_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0_________________________________________________________________dropout_2 (Dropout) (None, 16, 16, 64) 0_________________________________________________________________batch_normalization_2 (Batch (None, 16, 16, 64) 256_________________________________________________________________conv2d_3 (Conv2D) (None, 16, 16, 64) 36928_________________________________________________________________activation_3 (Activation) (None, 16, 16, 64) 0_________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0_________________________________________________________________dropout_3 (Dropout) (None, 8, 8, 64) 0_________________________________________________________________batch_normalization_3 (Batch (None, 8, 8, 64) 256_________________________________________________________________conv2d_4 (Conv2D) (None, 8, 8, 128) 73856_________________________________________________________________activation_4 (Activation) (None, 8, 8, 128) 0_________________________________________________________________dropout_4 (Dropout) (None, 8, 8, 128) 0_________________________________________________________________batch_normalization_4 (Batch (None, 8, 8, 128) 512_________________________________________________________________flatten_1 (Flatten) (None, 8192) 0_________________________________________________________________dropout_5 (Dropout) (None, 8192) 0_________________________________________________________________dense_1 (Dense) (None, 256) 2097408_________________________________________________________________activation_5 (Activation) (None, 256) 0_________________________________________________________________dropout_6 (Dropout) (None, 256) 0_________________________________________________________________batch_normalization_5 (Batch (None, 256) 1024_________________________________________________________________dense_2 (Dense) (None, 128) 32896_________________________________________________________________activation_6 (Activation) (None, 128) 0_________________________________________________________________dropout_7 (Dropout) (None, 128) 0_________________________________________________________________batch_normalization_6 (Batch (None, 128) 512_________________________________________________________________dense_3 (Dense) (None, 10) 1290_________________________________________________________________activation_7 (Activation) (None, 10) 0=================================================================Total params: 2,264,458Trainable params: 2,263,114Non-trainable params: 1,344Nu gaan we het model trainen. Hiervoor hoeven we alleen maar de fit()-functie op het model aan te roepen en de gekozen parameters door te geven.
Hier gebruik ik het zaad dat ik gekozen heb, met het oog op reproduceerbaarheid.
numpy.random.seed(seed)model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)We trainen op 50000 monsters en valideren op 10000 monsters.
Het uitvoeren van dit stukje code levert het volgende op:
Epoch 1/2564/50000 - ETA: 16:57 - loss: 3.1479 - acc: 0.0938128/50000 - ETA: 10:12 - loss: 3.0212 - acc: 0.0938192/50000 - ETA: 7:57 - loss: 2.9781 - acc: 0.1250256/50000 - ETA: 6:48 - loss: 2.8830 - acc: 0.1484320/50000 - ETA: 6:07 - loss: 2.8878 - acc: 0.1469384/50000 - ETA: 5:40 - loss: 2.8732 - acc: 0.1458448/50000 - ETA: 5:20 - loss: 2.8842 - acc: 0.1406.........49664/50000 - ETA: 1s - loss: 1.5160 - acc: 0.461149728/50000 - ETA: 1s - loss: 1.5157 - acc: 0.461249792/50000 - ETA: 1s - loss: 1.5153 - acc: 0.461449856/50000 - ETA: 0s - loss: 1.5147 - acc: 0.461549920/50000 - ETA: 0s - loss: 1.5144 - acc: 0.461749984/50000 - ETA: 0s - loss: 1.5141 - acc: 0.461750000/50000 - 262s 5ms/step - loss: 1.5140 - acc: 0.4618 - val_loss: 1.0715 - val_acc: 0.6195End of Epoch 1Merk op dat je in de meeste gevallen een validatieset wilt hebben die verschilt van de testset, en dus specificeer je een percentage van de trainingsdata om als validatieset te gebruiken. In dit geval geven we alleen de test data door om er zeker van te zijn dat de test data apart gezet wordt en niet getraind wordt. We hebben in dit voorbeeld alleen testdata, om het eenvoudig te houden.
Nu kunnen we het model evalueren en kijken hoe het presteerde. Roep gewoon model.evaluate():
# Model evaluationscores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%" % (scores*100))En we worden begroet met het resultaat:
Accuracy: 83.01%En dat is het! We hebben nu een getrainde beeldherkenning CNN. Niet slecht voor de eerste keer, maar je zou waarschijnlijk wat willen spelen met de modelstructuur en parameters om te zien of je geen betere prestaties kunt krijgen.
Conclusie
Nu je je eerste beeldherkenningsnetwerk in Keras hebt geïmplementeerd, zou het een goed idee zijn om wat met het model te spelen en te zien hoe het veranderen van de parameters de prestaties beïnvloedt.
Dit zal je wat intuïtie geven over de beste keuzes voor verschillende modelparameters. U moet zich ook inlezen in de verschillende parameter- en hyperparameter-keuzes. Nadat je je hiermee vertrouwd hebt gemaakt, kun je proberen je eigen beeldclassificator op een andere dataset te implementeren.
Als je met de code wilt spelen of deze gewoon wat dieper wilt bestuderen, is het project geüpload op GitHub!