はじめに
TensorFlowとKerasの活用で最も多いのが画像の認識/分類です。 Keras を使用して画像を分類または認識する方法を学びたい場合、この記事ではその方法を説明します。
Definitions
画像認識の背後にある基本概念が明確でない場合、この記事の残りの部分を完全に理解することは困難でしょう。 そこで、先に進む前に、いくつかの用語を定義しておきましょう。
TensorFlow/Keras

Credit: commons.wikimedia.org
TensorFlow は Google Brain チームが Python 用に作成したオープンソース ライブラリです。 TensorFlow は、多くの異なるアルゴリズムとモデルを一緒にコンパイルし、ユーザーが画像認識/分類や自然言語処理などのタスクで使用するための深いニューラルネットワークを実装することを可能にします。 TensorFlow は、一連の処理ノードを実装することで機能する強力なフレームワークで、各ノードは数学的操作を表し、一連のノード全体は「グラフ」と呼ばれます。
Keras に関しては、TensorFlow の関数を下で使用できる高レベル API (application programming interface) です (Theano など他の ML ライブラリと同様です)。 Kerasは、使いやすさとモジュール性を指針として設計されています。 実用的には、Keras は TensorFlow の多くの強力だがしばしば複雑な機能をできるだけ簡単に実装し、大きな変更や設定なしに Python で動作するように構成されています。
Image Recognition (Classification)
画像認識は、ニューラルネットワークに画像を入力して、その画像に対する何らかのラベルを出力させる作業を指します。 ネットワークが出力するラベルは、あらかじめ定義されたクラスに対応します。 画像のラベルは、複数のクラスがあってもよいし、1つだけであってもよい。
画像分類のサブセットにはオブジェクト検出があり、オブジェクトの特定のインスタンスが動物、車、人などの特定のクラスに属していると識別される。
特徴抽出
画像認識/分類を行うために、ニューラルネットワークは特徴抽出を行う必要がある。 特徴とは、ネットワークを介して供給される気になるデータの要素である。 画像認識の具体的なケースでは、特徴とは、ネットワークがパターン分析するオブジェクトのエッジやポイントなどのピクセルのグループです。
特徴認識 (または特徴抽出) は、入力画像から関連する特徴を引き出して、これらの特徴を分析できるようにするプロセスです。 多くの画像には、ネットワークが関連する特徴を見つけるのに役立つ画像に関する注釈またはメタデータが含まれています。
ニューラルネットワークが画像を認識する方法
ニューラルネットワークが画像を認識する方法の直観を得ることは、ニューラルネットワークモデルを実装する際に役立ちますので、次のいくつかのセクションで画像認識プロセスを簡単に探検しましょう。
フィルターによる特徴抽出
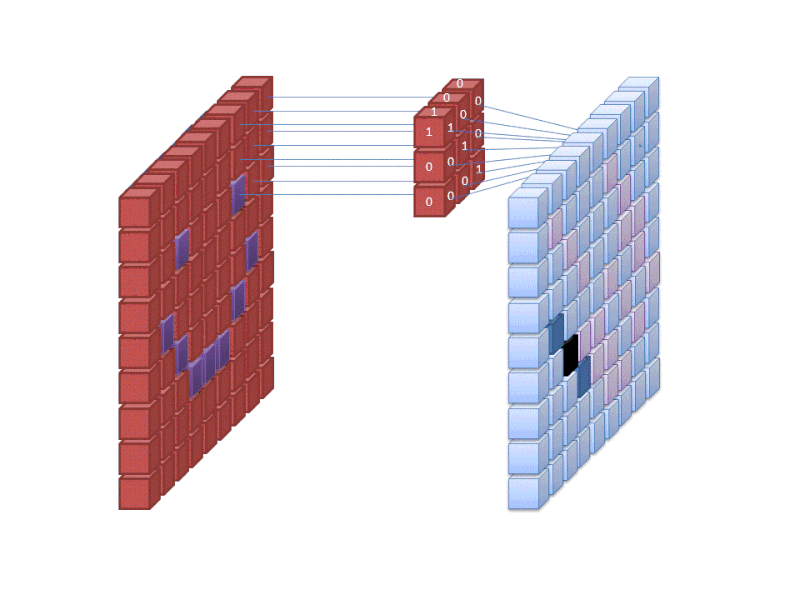
Credit: commons.wikimedia.org
ニューラルネットワークの最初の層は、イメージ内のすべてのピクセルを取り込みます。 すべてのデータがネットワークに入力された後、異なるフィルタが画像に適用され、画像のさまざまな部分の表現が形成されます。 これは特徴抽出であり、「特徴マップ」を作成します。
画像から特徴を抽出するこのプロセスは「畳み込み層」で達成され、畳み込みは単に画像の一部の表現を形成することです。 この畳み込みの概念から、画像の分類/認識で最もよく使用されるニューラルネットワークの一種であるCNN (Convolutional Neural Network) という用語が生まれました。
特徴マップの作成の仕組みを視覚化したい場合は、暗い部屋で写真に懐中電灯を照らすことを考えてみてください。 写真の上でビームを滑らせると、画像の特徴について学習することになります。 懐中電灯の光の幅は、一度に調べるイメージの量を制御しますが、ニューラルネットワークにも同様のパラメーターであるフィルター サイズがあります。 フィルター サイズは、一度に検査される画像の量、つまり何ピクセルに影響します。 CNN で使用される一般的なフィルター サイズは 3 で、これは高さと幅の両方をカバーするので、フィルターはピクセルの 3 x 3 の領域を検査します。
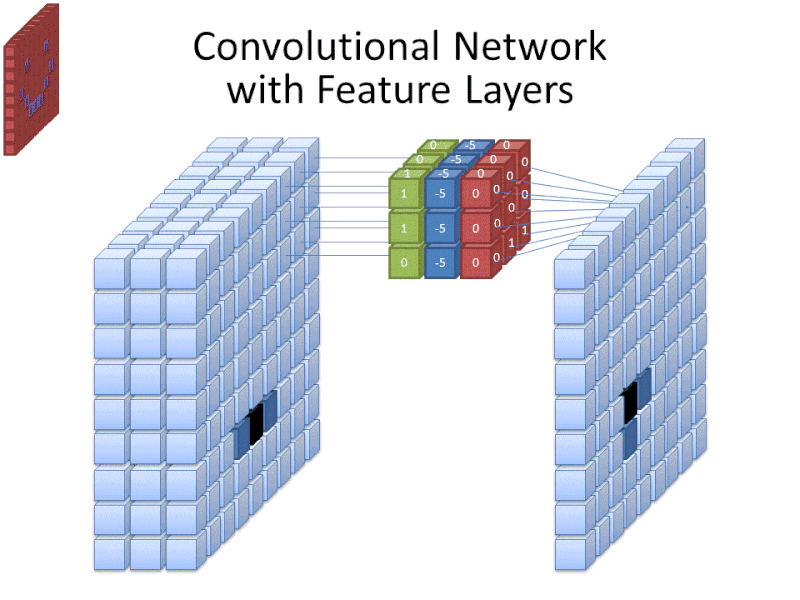
Credit: commons.wikimedia.org
フィルター サイズがフィルターの高さと幅に及ぶ一方で、フィルターの深さも指定する必要があります。
2D 画像に深度があるのはなぜですか
?
デジタル画像は、高さ、幅、およびピクセルの色を定義する何らかの RGB 値としてレンダリングされるので、追跡される「深度」は画像が持つ色チャンネル数ということになります。 グレースケール (非カラー) 画像には 1 つのカラー チャンネルしかありませんが、カラー画像には 3 つの深度チャンネルがあります。
これらのことは、フルカラー画像に適用されるサイズ 3 のフィルターについて、そのフィルターの寸法が 3 x 3 x 3 になることを意味します。 この処理を画像全体に対して行うことで、完全な表現が可能になる。 フィルターは「ストライド」と呼ばれるパラメーターに従って画像の残りの部分を移動する。ストライドは、フィルターが現在の位置の値を計算した後、何ピクセル移動させるかを定義する。 CNNの一般的なストライドサイズは2.0mmです。
このような計算の最終結果が特徴マップになります。
活性化関数
画像の特徴マップが作成された後、画像を表す値は活性化関数または活性化層に渡される。 活性化関数は、畳み込み層のおかげで線形形式(つまり単なる数字の羅列)になっている画像を表す値を受け取り、画像自体が非線形であるため、その非線形性を増大させます。
これを達成するために使用される典型的な活性化関数は Rectified Linear Unit (ReLU) ですが、時々使用される他の活性化関数もあります(それらについては、こちらを参照してください)。 プーリングは、画像を「ダウンサンプリング」することで、画像を表す情報を取り出し、それを圧縮して小さくすることを意味します。 プーリング処理により、ネットワークはより柔軟になり、関連する特徴に基づいてオブジェクト/画像を認識することがより得意になります。
私たちが画像を見るとき、通常は画像の背景にあるすべての情報には関心がなく、人物や動物など、関心のある特徴だけに関心があります。
同様に、CNN のプーリング層は画像の不要な部分を抽象化し、プーリング層の指定サイズによって制御されるように、関連性があると考えられる画像の部分のみを保持します。 これは、ネットワークが学習ケースの側面を学習しすぎて、新しいデータへの汎化に失敗するオーバーフィッティングを防止するのに役立ちます。 最大値プーリングは、1つのフィルタ内(画像内の1つのスポット内)のピクセルの最大値を取得します。 これは、2 x 2 のフィルターが使用されていると仮定すると、情報の 3/4 をドロップします。
可能な画像の歪みを考慮し、オーバーフィッティングを制御するために画像のパラメータ/サイズを小さくするために、ピクセルの最大値が使用されます。 平均プーリングや合計プーリングといった他のプーリングタイプもありますが、最大プーリングの方が精度が高い傾向があるため、これらはあまり使用されません。
平坦化
CNNの最後の層、密結合層では、処理するためにデータがベクトルの形であることが必要です。 このため、データは “平坦化 “されなければならない。
完全連結層
CNNの最後の層は高密度連結層、つまり人工ニューラルネットワーク(ANN)である。 ANNの主な機能は、入力された特徴を分析し、分類を助ける異なる属性にそれらを組み合わせることである。 これらの層は基本的に、問題の物体のさまざまな部分を表すニューロンの集合体を形成しており、ニューロンの集合体は、犬のはねた耳やリンゴの赤さを表すこともある。 入力画像に反応してこれらのニューロンが十分に活性化されると、画像はオブジェクトとして分類されます。

Credit: commons.wikimedia.org
エラー、つまり計算値と学習セットでの期待値との差が、ANN によって計算されます。 その後、ネットワークはバックプロパゲーションを行い、あるニューロンが次の層のニューロンに与える影響を計算し、その影響力を調整する。 これはモデルの性能を最適化するために行われる。 このプロセスは、何度も繰り返される。 このようにしてネットワークはデータを学習し、入力特性と出力クラス間の関連性を学習する。
中間の完全接続層のニューロンは、可能なクラスに関連するバイナリ値を出力する。 4つの異なるクラス(犬、車、家、人とする)がある場合、ニューロンはイメージが表すと考えるクラスに対して「1」値を持ち、他のクラスに対して「0」値を持つ。
最後の完全接続層はその前の層の出力を受け取り、各クラスに対して確率を出し、合計を1にする。
これで画像分類器は学習され、画像を CNN に渡すことができるようになり、その画像の内容についての推測を出力するようになります。 ニューラル ネットワーク モデルをトレーニングするプロセスはかなり標準的で、4 つの異なるフェーズに分けることができます。
データの準備
最初に、データを収集し、ネットワークがトレーニングできるような形式にする必要があります。 これには画像を収集し、ラベルを付けることが必要です。 誰かが用意したデータセットをダウンロードした場合でも、それを学習に使用する前に前処理や準備が必要な場合が多いようです。 この記事では、前処理済みのデータセットを使用します。
モデルの作成
ニューラルネットワークモデルを作成するには、さまざまなパラメーターとハイパーパラメーターを選択することが必要です。 モデルで使用する層の数、層の入力と出力のサイズ、使用する活性化関数の種類、ドロップアウトを使用するかどうかなどを決定する必要があります。
使用するパラメーターとハイパーパラメーターを学ぶには時間がかかりますが (そして多くの学習が必要です)、最初から実行するために使用できるいくつかの経験則があり、実装例でこれらのいくつかをカバーします。 モデルを学習する際に最も考慮すべきことは、モデルの学習にかかる時間です。 ネットワークの学習時間は、学習するエポック数を指定することで指定することができます。 8737>
訓練するエポック数を選択することは、感覚をつかむことであり、ネットワークの訓練がある程度進んだら、やり直す必要がないように、訓練セッションの間にネットワークの重みを保存するのが通例である。 モデル評価の最初のステップは、検証用データセット(モデルがまだ訓練されていないデータセット)に対してモデルのパフォーマンスを比較することです。 この検証セットに対してモデルのパフォーマンスを比較し、さまざまなメトリックを通じてそのパフォーマンスを分析します。
ニューラル ネットワーク モデルのパフォーマンスを決定するためのさまざまなメトリックがありますが、最も一般的なメトリックは「精度」で、正しく分類された画像の量をデータセット内の画像の合計数で割ったものです。
検証用データセットでモデルのパフォーマンスの精度を確認した後、通常、最初のトレーニングでネットワークのパフォーマンスに満足することはまずないので、少し調整したパラメーターを使用して、再度ネットワークをトレーニングすることになります。 ネットワークの精度に満足できるまで、ネットワークのパラメータを微調整し、再トレーニングし、そのパフォーマンスを測定し続けることになる。
おそらく、次のような疑問をお持ちでしょう:
なぜわざわざテスト セットで行うのですか。 というのも、パラメータを調整することと、検証セットで再テストすることを組み合わせると、ネットワークが検証セットの特異性を学習してしまい、サンプル外のデータに一般化できない可能性があるからです。
したがって、テスト セットの目的は、オーバーフィッティングなどの問題をチェックし、モデルが実世界で実行するのに本当に適していることをより確信することです。
Image Recognition with a CNN
これまで多くのことを説明してきましたが、これらの情報に少し圧倒されたのなら、データ セットで学習した分類器のサンプルにこれらの概念が集約されているのを見て、これらの概念をより具体的にする必要があります。 そこで、データのロードから評価まで、Keras による画像認識の完全な例を見てみましょう。
Credit: www.cs.toronto.eduまず最初に、学習するためのデータセットが必要です。 この例では、有名なCIFAR-10データセットを使用することにします。 CIFAR-10は、猫、飛行機、車など10種類の異なるクラスのオブジェクトを表す6万以上の画像を含む大規模な画像データセットです。
画像はフルカラーRGBですが、32 x 32とかなり小さいものです。 CIFAR-10 データセットの素晴らしい点の 1 つは、Keras にあらかじめパッケージされているため、データセットをロードするのが非常に簡単で、画像はほとんど前処理を必要としません。
最初に行うべきことは、必要なライブラリのインポートです。 これらのインポートがどのように使用されるかは追って説明しますが、今のところ、Numpy と Keras に関連するさまざまなモジュールを使用することを知っておいてください:
import numpyfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activationfrom keras.layers.convolutional import Conv2D, MaxPooling2Dfrom keras.constraints import maxnormfrom keras.utils import np_utilsこの記事で得られた結果をあなたにも再現できるように、ここではランダムシードを使用するつもりですが、そのために
numpy:# Set random seed for purposes of reproducibilityseed = 21Prepping the Data
もう 1 つのインポート、データセットを必要とします。
from keras.datasets import cifar10さて、データセットをロードしてみましょう。 データをロードする変数を指定し、
load_data()関数を使用するだけです。# loading in the data (X_train, y_train), (X_test, y_test) = cifar10.load_data()ほとんどの場合、データを使用できるようにするために何らかの前処理を行う必要がありますが、今回はパッケージされたデータセットを使っているので、ほとんど前処理を行う必要はありません。
入力データの値が広すぎる場合、ネットワークのパフォーマンスにマイナスの影響を与える可能性があります。 この場合、入力値はイメージのピクセルで、0から255の間の値を持ちます。
したがって、データを正規化するために、イメージの値を255で単純に割ることができます。 これを行うには、まずデータが現在整数であるため、float 型にする必要があります。
# normalize the inputs from 0-255 to between 0 and 1 by dividing by 255 X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = X_train / 255.0X_test = X_test / 255.0もうひとつ、データをネットワークで利用するために必要なことは、値を一発でエンコードすることです。 ここではワンホットエンコーディングの詳細には触れませんが、とりあえず、画像はそのままではネットワークで使用できないので、最初にエンコードする必要があり、ワンホットエンコーディングはバイナリ分類を行うときに最もよく使用されます。 Numpyコマンド
to_categorical()は、ワンホットエンコードに使用されます。また、データセットにあるクラスの数を指定する必要があるので、最終層を圧縮するニューロンの数を知ることができます:
# one hot encode outputsy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)class_num = y_test.shapeDesigning the Model
CNNモデルを設計する段階に来ました。 Kerasにはモデルを構築するためのいくつかの異なるフォーマットや青写真がありますが、
Sequentialは最も一般的に使用されており、そのためKerasからインポートしました。Create the Model
model = Sequential()このモデルの最初の層は、畳み込み層です。 これは、入力を取り込み、それに対して畳み込みフィルタを実行します。
Kerasでこれらを実装する場合、必要なチャンネル/フィルタの数(これは下の32)、必要なフィルタのサイズ(この場合は3 x 3)、入力形状(第1層を作成するとき)、必要な活性化とパディングを指定しなければなりません。
前述のように、
reluは最も一般的な活性化で、padding='same'は画像のサイズを全く変えないことを意味します。model.add(Conv2D(32, (3, 3), input_shape=X_train.shape, padding='same'))model.add(Activation('relu'))注:活性化とパディングは、次のように一緒に列挙することもできます:
model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), activation='relu', padding='same'))次に、オーバーフィットを防止するドロップアウト層を作って、層間の接続をいくつかランダムに排除して機能を果たします(0。2は既存の接続の20%を削除することを意味します):
model.add(Dropout(0.2))ここで一括正規化も行いたいところです。 バッチ正規化は、次の層に向かう入力を正規化し、ネットワークが常に私たちが望むのと同じ分布で活性化を作成することを保証する:
model.add(BatchNormalization())ここで別の畳み込み層が来るが、フィルターサイズはネットワークがより複雑な表現を学習できるように増加する:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))ここでプール層、前に述べたようにこれは画像分類器をより堅牢にして関連パターンを学習できるようにするのを助ける。 また、ドロップアウトとバッチ正規化もあります。
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization())これが、CNN 実装の前半の基本フローです。 畳み込み、活性化、ドロップアウト、プーリング。
Dropout,BatchNormalization,Activation,Conv2d,MaxPooling2dをインポートした理由がわかりました。畳み込み層の数はお好みで変えられますが、1つ増えるごとに計算量が増えます。 畳み込み層を追加するとき、モデルがより複雑な表現を学習できるように、一般的にそれらのフィルタの数を増やすことに注意してください。 これらの層に選択された数がいくらか任意に思える場合、一般的に、続行するにつれてフィルターを増やし、GPU でトレーニングするときにわずかな利点を与えることができる、2のべき乗にすることを推奨することを知っておいてください。
使用すべきプーリング層の正確な数は、行っているタスクによって異なり、時間をかけて感覚をつかむものです。
ネットワークをより多くの表現で動作させるために、これらの層を繰り返すことができます:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())畳み込み層が終了したら、データを
Flattenする必要があります。 また、再びドロップアウトの層を追加します:model.add(Flatten())model.add(Dropout(0.2))ここで、
Denseインポートを利用し、最初の密結合層を作成します。 密な層のニューロン数を指定する必要があります。 後続の層のニューロン数は減少し、最終的にはデータセット中のクラスと同じニューロン数(この場合は10)に近づくことに注意してください。 カーネル制約は、学習する際にデータを正則化することができ、これもオーバーフィッティングを防ぐのに役立ちます。model.add(Dense(256, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Dense(128, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())この最終層では、ニューロン数に対してクラス数を渡している。
最後に、
softmax活性化関数は、最も高い確率を持つニューロンを出力として選択し、画像がそのクラスに属していることを投票します:model.add(Dense(class_num))model.add(Activation('softmax'))これで、使用したいモデルを設計したので、あとはそれをコンパイルするだけです。 使用するオプティマイザーと同様に、学習するエポック数を指定しましょう。
オプティマイザーは、損失の最も少ないポイントに近づくようにネットワークの重みを調整するものです。
Adamアルゴリズムは、ほとんどの問題で優れたパフォーマンスを発揮するため、最も一般的に使用されるオプティマイザーの 1 つです。model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=)モデル全体がどのようなものかを見るために、モデルのサマリーを印刷することができます。
ここで、再現性を高めるために、私が選んだ種を使用します。
このコードを実行すると、次の結果が得られます:
Epoch 1/2564/50000 - ETA: 16:57 - loss: 3.1479 - acc: 0.0938128/50000 - ETA: 10:12 - loss: 3.0212 - acc: 0.0938192/50000 - ETA: 7:57 - loss: 2.9781 - acc: 0.1250256/50000 - ETA: 6:48 - loss: 2.8830 - acc: 0.1484320/50000 - ETA: 6:07 - loss: 2.8878 - acc: 0.1469384/50000 - ETA: 5:40 - loss: 2.8732 - acc: 0.1458448/50000 - ETA: 5:20 - loss: 2.8842 - acc: 0.1406.........49664/50000 - ETA: 1s - loss: 1.5160 - acc: 0.461149728/50000 - ETA: 1s - loss: 1.5157 - acc: 0.461249792/50000 - ETA: 1s - loss: 1.5153 - acc: 0.461449856/50000 - ETA: 0s - loss: 1.5147 - acc: 0.461549920/50000 - ETA: 0s - loss: 1.5144 - acc: 0.461749984/50000 - ETA: 0s - loss: 1.5141 - acc: 0.461750000/50000 - 262s 5ms/step - loss: 1.5140 - acc: 0.4618 - val_loss: 1.0715 - val_acc: 0.6195End of Epoch 1ほとんどの場合、テストセットとは異なる検証セットを持ちたいので、検証セットとして使用するトレーニングデータの割合を指定することに注意してください。 今回は、テストデータを脇に置いて学習させないようにするために、テストデータだけを渡します。
さて、モデルを評価し、どのように動作するかを確認しましょう。
model.evaluate():# Model evaluationscores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%" % (scores*100))を呼び出すと、結果が表示されます。 これで画像認識CNNを学習させることができました。 最初の実行としては悪くないですが、おそらくモデル構造とパラメータを弄って、より良いパフォーマンスが得られないかどうかを確認したいと思うでしょう。
結論
今、あなたは Keras で最初の画像認識ネットワークを実装しました。 また、そうしている間に、さまざまなパラメータとハイパーパラメータの選択について読んでおく必要があります。 これらに慣れたら、別のデータセットで独自の画像分類器を実装してみましょう。
このコードで遊んでみたい、あるいは単にもう少し深く研究したいという場合は、プロジェクトが GitHub にアップロードされています!
。
