- Introduzione
- Definizioni
- TensorFlow/Keras
- Riconoscimento delle immagini (Classificazione)
- Estrazione delle caratteristiche
- Come le reti neurali imparano a riconoscere le immagini
- Estrazione delle caratteristiche con i filtri
- Funzioni di attivazione
- Strati di Pooling
- Flattening
- Strato completamente connesso
- Il flusso di lavoro dell’apprendimento automatico
- Preparazione dei dati
- Creazione del modello
- Allenamento del modello
- Valutazione del modello
- Riconoscimento di immagini con una CNN
- Preparazione dei dati
- Progettazione del modello
- Crea il modello
- Conclusione
Introduzione
Uno degli usi più comuni di TensorFlow e Keras è il riconoscimento/classificazione di immagini. Se vuoi imparare come usare Keras per classificare o riconoscere le immagini, questo articolo ti insegnerà come fare.
Definizioni
Se non ti sono chiari i concetti di base del riconoscimento delle immagini, sarà difficile capire completamente il resto di questo articolo. Quindi, prima di procedere oltre, prendiamoci un momento per definire alcuni termini.
TensorFlow/Keras

Credit: commons.wikimedia.org
TensorFlow è una libreria open source creata per Python dal team Google Brain. TensorFlow compila molti algoritmi e modelli diversi insieme, consentendo all’utente di implementare reti neurali profonde da utilizzare in compiti come il riconoscimento/classificazione delle immagini e l’elaborazione del linguaggio naturale. TensorFlow è un potente framework che funziona implementando una serie di nodi di elaborazione, ogni nodo rappresenta un’operazione matematica, e l’intera serie di nodi è chiamata “grafo”.
In termini di Keras, è un’API (interfaccia di programmazione dell’applicazione) di alto livello che può utilizzare le funzioni di TensorFlow (così come altre librerie ML come Theano). Keras è stato progettato con facilità d’uso e modularità come principi guida. In termini pratici, Keras rende l’implementazione delle molte funzioni potenti ma spesso complesse di TensorFlow il più semplice possibile, ed è configurato per funzionare con Python senza alcuna modifica o configurazione importante.
Riconoscimento delle immagini (Classificazione)
Il riconoscimento delle immagini si riferisce al compito di inserire un’immagine in una rete neurale e farle produrre una sorta di etichetta per quell’immagine. L’etichetta che la rete produce corrisponderà a una classe predefinita. Ci possono essere più classi in cui l’immagine può essere etichettata, o solo una. Se c’è una sola classe, il termine “riconoscimento” è spesso applicato, mentre un compito di riconoscimento multiclasse è spesso chiamato “classificazione”.
Un sottoinsieme della classificazione delle immagini è il rilevamento degli oggetti, dove specifiche istanze di oggetti sono identificate come appartenenti a una certa classe come animali, auto o persone.
Estrazione delle caratteristiche
Per effettuare il riconoscimento/classificazione delle immagini, la rete neurale deve effettuare l’estrazione delle caratteristiche. Le caratteristiche sono gli elementi dei dati che vi interessano e che saranno inseriti nella rete. Nel caso specifico del riconoscimento delle immagini, le caratteristiche sono i gruppi di pixel, come i bordi e i punti, di un oggetto che la rete analizzerà per i modelli.
Il riconoscimento delle caratteristiche (o estrazione delle caratteristiche) è il processo di estrazione delle caratteristiche rilevanti da un’immagine di input in modo che queste caratteristiche possano essere analizzate. Molte immagini contengono annotazioni o metadati sull’immagine che aiutano la rete a trovare le caratteristiche rilevanti.
Come le reti neurali imparano a riconoscere le immagini
Avere un’intuizione di come una rete neurale riconosce le immagini ti aiuterà quando stai implementando un modello di rete neurale, quindi esploriamo brevemente il processo di riconoscimento delle immagini nelle prossime sezioni.
Estrazione delle caratteristiche con i filtri
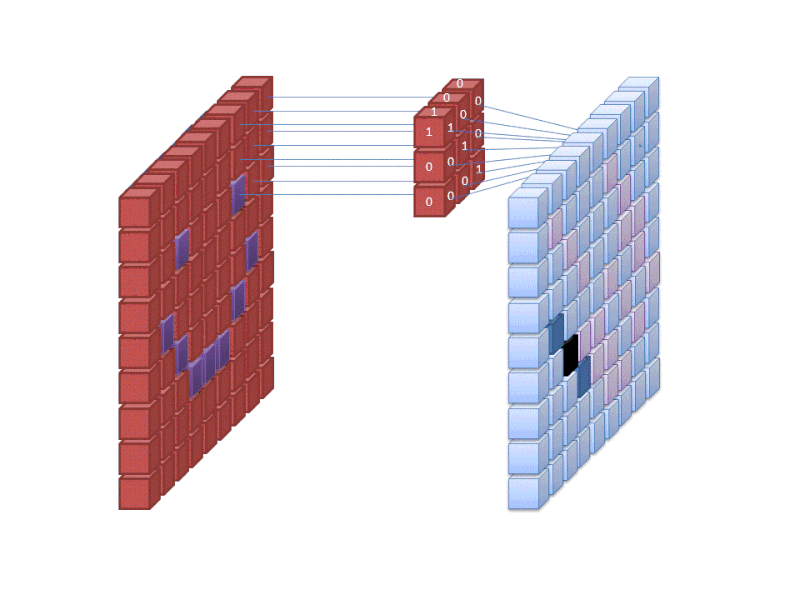
Credito: commons.wikimedia.org
Il primo strato di una rete neurale prende in considerazione tutti i pixel di un’immagine. Dopo che tutti i dati sono stati inseriti nella rete, vengono applicati diversi filtri all’immagine, che formano rappresentazioni di diverse parti dell’immagine. Questa è l’estrazione delle caratteristiche e crea “mappe di caratteristiche”.
Questo processo di estrazione delle caratteristiche da un’immagine è realizzato con uno “strato di convoluzione”, e la convoluzione è semplicemente formare una rappresentazione di una parte dell’immagine. È da questo concetto di convoluzione che deriva il termine Rete Neurale Convoluzionale (CNN), il tipo di rete neurale più comunemente usato nella classificazione/riconoscimento delle immagini.
Se vuoi visualizzare come funziona la creazione di mappe di caratteristiche, pensa a far brillare una torcia su una foto in una stanza buia. Mentre fate scorrere il raggio sull’immagine state imparando le caratteristiche dell’immagine. Un filtro è ciò che la rete usa per formare una rappresentazione dell’immagine, e in questa metafora, la luce della torcia è il filtro.
L’ampiezza del raggio della tua torcia controlla quanta parte dell’immagine esamini in una sola volta, e le reti neurali hanno un parametro simile, la dimensione del filtro. La dimensione del filtro influisce su quanta parte dell’immagine, quanti pixel, vengono esaminati in una sola volta. Una dimensione comune del filtro usata nelle CNN è 3, e questo copre sia l’altezza che la larghezza, quindi il filtro esamina un’area di pixel 3 x 3.
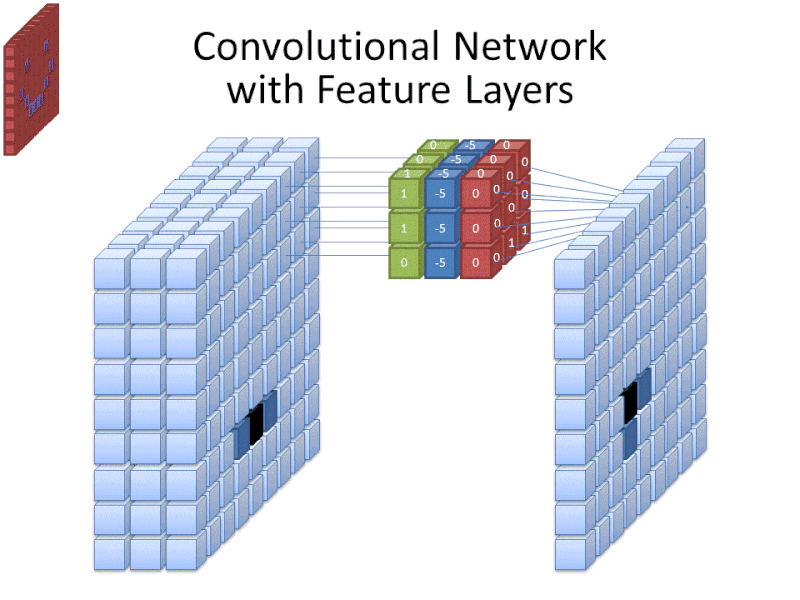
Credit: commons.wikimedia.org
Mentre la dimensione del filtro copre l’altezza e la larghezza del filtro, deve essere specificata anche la profondità del filtro.
Come fa un’immagine 2D ad avere profondità?
Le immagini digitali sono rese come altezza, larghezza e qualche valore RGB che definisce i colori del pixel, quindi la “profondità” che viene monitorata è il numero di canali di colore che l’immagine ha. Le immagini in scala di grigi (non a colori) hanno solo 1 canale di colore mentre le immagini a colori hanno 3 canali di profondità.
Tutto questo significa che per un filtro di dimensione 3 applicato a un’immagine a colori, le dimensioni di quel filtro saranno 3 x 3 x 3. Per ogni pixel coperto da quel filtro, la rete moltiplica i valori del filtro con i valori nei pixel stessi per ottenere una rappresentazione numerica di quel pixel. Questo processo viene poi fatto per l’intera immagine per ottenere una rappresentazione completa. Il filtro viene spostato attraverso il resto dell’immagine secondo un parametro chiamato “stride”, che definisce di quanti pixel il filtro deve essere spostato dopo aver calcolato il valore nella sua posizione attuale. Una dimensione convenzionale di stride per una CNN è 2.
Il risultato finale di tutti questi calcoli è una mappa di caratteristiche. Questo processo è tipicamente fatto con più di un filtro, che aiuta a preservare la complessità dell’immagine.
Funzioni di attivazione
Dopo che la mappa delle caratteristiche dell’immagine è stata creata, i valori che rappresentano l’immagine sono passati attraverso una funzione di attivazione o strato di attivazione. La funzione di attivazione prende i valori che rappresentano l’immagine, che sono in forma lineare (cioè solo una lista di numeri) grazie allo strato di convoluzione, e aumenta la loro non linearità poiché le immagini stesse sono non lineari.
La tipica funzione di attivazione usata per realizzare questo è una Rectified Linear Unit (ReLU), anche se ci sono alcune altre funzioni di attivazione che sono occasionalmente usate (puoi leggere qui).
Strati di Pooling
Dopo che i dati sono attivati, vengono inviati attraverso uno strato di pooling. Il pooling “ridimensiona” un’immagine, cioè prende le informazioni che rappresentano l’immagine e le comprime, rendendole più piccole. Il processo di pooling rende la rete più flessibile e più abile nel riconoscere oggetti/immagini basati sulle caratteristiche rilevanti.
Quando guardiamo un’immagine, di solito non siamo interessati a tutte le informazioni sullo sfondo dell’immagine, ma solo alle caratteristiche che ci interessano, come le persone o gli animali.
Similmente, uno strato di raggruppamento in una CNN astrae le parti non necessarie dell’immagine, mantenendo solo le parti dell’immagine che ritiene rilevanti, come controllato dalla dimensione specificata dello strato di raggruppamento.
Perché deve prendere decisioni sulle parti più rilevanti dell’immagine, la speranza è che la rete apprenda solo le parti dell’immagine che rappresentano veramente l’oggetto in questione. Questo aiuta a prevenire l’overfitting, dove la rete impara troppo bene gli aspetti del caso di allenamento e non riesce a generalizzare ai nuovi dati.
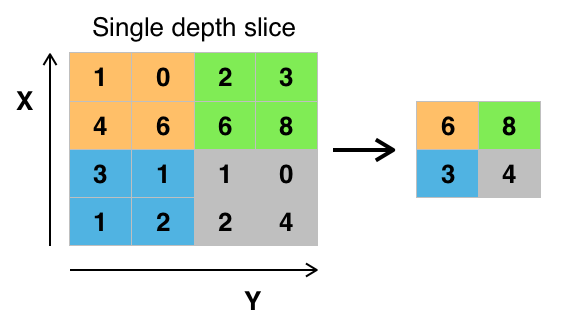
Credit: commons.wikimedia.org
Ci sono vari modi per raggruppare i valori, ma il max pooling è il più comunemente usato. Il max pooling ottiene il valore massimo dei pixel all’interno di un singolo filtro (all’interno di un singolo punto dell’immagine). Questo elimina 3/4 di informazione, supponendo che vengano usati 2 x 2 filtri.
I valori massimi dei pixel sono usati per tenere conto di possibili distorsioni dell’immagine, e i parametri/dimensioni dell’immagine sono ridotti per controllare l’overfitting. Ci sono altri tipi di pooling come il pooling medio o il pooling della somma, ma questi non sono usati così frequentemente perché il pooling massimo tende a dare una migliore accuratezza.
Flattening
Gli strati finali della nostra CNN, gli strati densamente connessi, richiedono che i dati siano sotto forma di un vettore per essere elaborati. Per questo motivo, i dati devono essere “appiattiti”. I valori sono compressi in un lungo vettore o in una colonna di numeri ordinati in modo sequenziale.
Strato completamente connesso
Gli strati finali della CNN sono strati densamente connessi, o una rete neurale artificiale (ANN). La funzione primaria della RNA è quella di analizzare le caratteristiche di input e combinarle in diversi attributi che aiuteranno nella classificazione. Questi strati stanno essenzialmente formando collezioni di neuroni che rappresentano diverse parti dell’oggetto in questione, e una collezione di neuroni può rappresentare le orecchie flosce di un cane o il rosso di una mela. Quando un numero sufficiente di questi neuroni viene attivato in risposta a un’immagine di input, l’immagine sarà classificata come un oggetto.

Credit: commons.wikimedia.org
L’errore, o la differenza tra i valori calcolati e il valore atteso nel set di allenamento, viene calcolato dalla RNA. La rete viene poi sottoposta a backpropagation, dove l’influenza di un dato neurone su un neurone nello strato successivo viene calcolata e la sua influenza regolata. Questo viene fatto per ottimizzare le prestazioni del modello. Questo processo viene poi ripetuto più e più volte. Questo è il modo in cui la rete si allena sui dati e impara le associazioni tra le caratteristiche di input e le classi di output.
I neuroni negli strati centrali completamente connessi emetteranno valori binari relativi alle possibili classi. Se avete quattro classi diverse (diciamo un cane, una macchina, una casa e una persona), il neurone avrà un valore “1” per la classe che crede che l’immagine rappresenti e un valore “0” per le altre classi.
Lo strato finale completamente connesso riceverà l’output dello strato precedente e fornirà una probabilità per ciascuna delle classi, sommando a uno. Se c’è un valore di 0.75 nella categoria “cane”, rappresenta una certezza del 75% che l’immagine sia un cane.
Il classificatore di immagini è stato ora addestrato, e le immagini possono essere passate alla CNN, che ora produrrà un’ipotesi sul contenuto di quell’immagine.
Il flusso di lavoro dell’apprendimento automatico
Prima di saltare in un esempio di addestramento di un classificatore di immagini, prendiamoci un momento per capire il flusso di lavoro dell’apprendimento automatico o pipeline. Il processo di addestramento di un modello di rete neurale è abbastanza standard e può essere suddiviso in quattro diverse fasi.
Preparazione dei dati
Prima di tutto, è necessario raccogliere i dati e metterli in una forma su cui la rete possa addestrarsi. Questo comporta la raccolta di immagini e la loro etichettatura. Anche se avete scaricato un set di dati che qualcun altro ha preparato, è probabile che ci sia una pre-elaborazione o preparazione che dovete fare prima di poterli usare per l’addestramento. La preparazione dei dati è un’arte a sé stante, che coinvolge cose come valori mancanti, dati corrotti, dati nel formato sbagliato, etichette errate, ecc.
In questo articolo, useremo un set di dati pre-elaborati.
Creazione del modello
Creare il modello della rete neurale implica fare scelte su vari parametri e iperparametri. Devi prendere decisioni sul numero di strati da usare nel tuo modello, quali saranno le dimensioni di input e output degli strati, che tipo di funzioni di attivazione userai, se userai o meno il dropout, ecc.
Imparare quali parametri e iperparametri usare richiederà tempo (e molto studio), ma ci sono alcune euristiche che puoi usare per iniziare a lavorare e ne tratteremo alcune durante l’esempio di implementazione.
Allenamento del modello
Dopo aver creato il tuo modello, devi semplicemente creare un’istanza del modello e adattarla ai tuoi dati di allenamento. La considerazione più importante quando si allena un modello è la quantità di tempo che il modello impiega per allenarsi. È possibile specificare la durata dell’addestramento di una rete specificando il numero di epoche per l’addestramento. Più a lungo si addestra un modello, maggiori saranno le sue prestazioni, ma troppe epoche di addestramento e si rischia l’overfitting.
Scegliere il numero di epoche di addestramento è qualcosa per cui ci si farà un’idea, ed è consuetudine salvare i pesi di una rete tra le sessioni di addestramento in modo da non dover ricominciare una volta che si sono fatti dei progressi nell’addestramento della rete.
Valutazione del modello
Ci sono più passi per valutare il modello. Il primo passo nella valutazione del modello è confrontare le prestazioni del modello con un set di dati di validazione, un set di dati su cui il modello non è stato addestrato. Confronterete le prestazioni del modello rispetto a questo set di convalida e analizzerete le sue prestazioni attraverso diverse metriche.
Ci sono varie metriche per determinare le prestazioni di un modello di rete neurale, ma la metrica più comune è la “precisione”, la quantità di immagini classificate correttamente divisa per il numero totale di immagini nel vostro set di dati.
Dopo aver visto l’accuratezza delle prestazioni del modello su un set di dati di convalida, di solito si torna indietro e si allena nuovamente la rete utilizzando parametri leggermente modificati, perché è improbabile che si sia soddisfatti delle prestazioni della rete la prima volta che si allena. Continuerete a modificare i parametri della vostra rete, ad addestrarla nuovamente e a misurarne le prestazioni fino a quando non sarete soddisfatti dell’accuratezza della rete.
Infine, testerete le prestazioni della rete su un set di test. Questo set di test è un altro set di dati che il vostro modello non ha mai visto prima.
Forse vi state chiedendo:
Perché preoccuparsi del set di test? Se ti stai facendo un’idea dell’accuratezza del tuo modello, non è questo lo scopo del set di validazione?
È una buona idea tenere un gruppo di dati che la rete non ha mai visto per i test, perché tutto il ritocco dei parametri che fai, combinato con il retesting sul set di validazione, potrebbe significare che la tua rete ha imparato alcune idiosincrasie del set di validazione che non saranno generalizzate ai dati fuori campione.
Quindi, lo scopo del set di test è quello di controllare problemi come l’overfitting ed essere più sicuri che il vostro modello sia veramente adatto a funzionare nel mondo reale.
Riconoscimento di immagini con una CNN
Abbiamo coperto molto finora, e se tutte queste informazioni sono state un po’ travolgenti, vedere questi concetti riuniti in un classificatore campione addestrato su un set di dati dovrebbe rendere questi concetti più concreti. Vediamo quindi un esempio completo di riconoscimento di immagini con Keras, dal caricamento dei dati alla valutazione.

Credit: www.cs.toronto.edu
Per cominciare, abbiamo bisogno di un set di dati su cui allenarci. In questo esempio, useremo il famoso dataset CIFAR-10. CIFAR-10 è un grande dataset di immagini che contiene oltre 60.000 immagini che rappresentano 10 diverse classi di oggetti come gatti, aerei e automobili.
Le immagini sono RGB a colori, ma sono abbastanza piccole, solo 32 x 32. Una grande cosa del dataset CIFAR-10 è che viene fornito preconfezionato con Keras, quindi è molto facile caricare il dataset e le immagini hanno bisogno di pochissima pre-elaborazione.
La prima cosa che dovremmo fare è importare le librerie necessarie. Mostrerò come queste importazioni vengono utilizzate man mano che andiamo avanti, ma per ora sappiate che faremo uso di Numpy, e vari moduli associati a Keras:
import numpyfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activationfrom keras.layers.convolutional import Conv2D, MaxPooling2Dfrom keras.constraints import maxnormfrom keras.utils import np_utilsUtilizzeremo qui un seme casuale in modo che i risultati ottenuti in questo articolo possano essere replicati da voi, ed è per questo che abbiamo bisogno di numpy:
# Set random seed for purposes of reproducibilityseed = 21Preparazione dei dati
Abbiamo bisogno di un’altra importazione: il dataset.
from keras.datasets import cifar10Ora carichiamo il dataset. Possiamo farlo semplicemente specificando in quali variabili vogliamo caricare i dati, e poi usando la funzione load_data():
# loading in the data (X_train, y_train), (X_test, y_test) = cifar10.load_data()Nella maggior parte dei casi avrete bisogno di fare qualche pre-elaborazione dei vostri dati per renderli pronti all’uso, ma dato che stiamo usando un dataset preconfezionato, è necessario fare pochissima pre-elaborazione. Una cosa che vogliamo fare è normalizzare i dati di input.
Se i valori dei dati di input sono in un intervallo troppo ampio, può avere un impatto negativo sulle prestazioni della rete. In questo caso, i valori di input sono i pixel dell’immagine, che hanno un valore compreso tra 0 e 255.
Quindi per normalizzare i dati possiamo semplicemente dividere i valori dell’immagine per 255. Per fare questo abbiamo prima bisogno di rendere i dati di tipo float, dato che attualmente sono interi. Possiamo farlo usando il comando astype() Numpy e poi dichiarando quale tipo di dati vogliamo:
# normalize the inputs from 0-255 to between 0 and 1 by dividing by 255 X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = X_train / 255.0X_test = X_test / 255.0Un’altra cosa che dovremo fare per avere i dati pronti per la rete è codificare i valori in un solo colpo. Non entrerò nello specifico della codifica one-hot qui, ma per ora sappiate che le immagini non possono essere usate dalla rete così come sono, devono essere prima codificate e la codifica one-hot è meglio usata quando si fa la classificazione binaria.
Stiamo effettivamente facendo la classificazione binaria qui perché un’immagine o appartiene a una classe o non appartiene, non può cadere da qualche parte nel mezzo. Il comando Numpy to_categorical() è usato per la codifica one-hot. Questo è il motivo per cui abbiamo importato la funzione np_utils da Keras, poiché contiene to_categorical().
Abbiamo anche bisogno di specificare il numero di classi che sono nel dataset, così sappiamo a quanti neuroni comprimere lo strato finale:
# one hot encode outputsy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)class_num = y_test.shapeProgettazione del modello
Siamo arrivati alla fase in cui progettiamo il modello CNN. La prima cosa da fare è definire il formato che vorremmo usare per il modello, Keras ha diversi formati o progetti su cui costruire i modelli, ma Sequential è il più comunemente usato, e per questo motivo, lo abbiamo importato da Keras.
Crea il modello
model = Sequential()Il primo strato del nostro modello è uno strato convoluzionario. Prenderà gli input ed eseguirà i filtri convoluzionali su di essi.
Quando implementiamo questi in Keras, dobbiamo specificare il numero di canali/filtri che vogliamo (che è il 32 sotto), la dimensione del filtro che vogliamo (3 x 3 in questo caso), la forma dell’input (quando si crea il primo strato) e l’attivazione e il padding di cui abbiamo bisogno.
Come detto, relu è l’attivazione più comune, e padding='same' significa solo che non stiamo cambiando affatto la dimensione dell’immagine:
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape, padding='same'))model.add(Activation('relu'))Nota: Puoi anche mettere insieme le attivazioni e i raggruppamenti, come questo:
model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), activation='relu', padding='same'))Ora faremo uno strato di dropout per prevenire l’overfitting, che funziona eliminando in modo casuale alcune delle connessioni tra gli strati (0.2 significa che elimina il 20% delle connessioni esistenti):
model.add(Dropout(0.2))Potremmo anche voler fare la normalizzazione batch qui. La normalizzazione batch normalizza gli input che vanno allo strato successivo, assicurando che la rete crei sempre attivazioni con la stessa distribuzione che desideriamo:
model.add(BatchNormalization())Ora arriva un altro strato convoluzionale, ma la dimensione del filtro aumenta in modo che la rete possa imparare rappresentazioni più complesse:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))Ecco lo strato di pooling, come discusso prima questo aiuta a rendere il classificatore di immagini più robusto in modo che possa imparare modelli rilevanti. C’è anche il dropout e la normalizzazione del batch:
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization())Questo è il flusso di base per la prima metà di un’implementazione CNN: Convoluzione, attivazione, dropout, pooling. Ora puoi vedere perché abbiamo importato Dropout, BatchNormalization, Activation, Conv2d, e MaxPooling2d.
Puoi variare il numero esatto di strati convoluzionali che hai a tuo piacimento, anche se ognuno aggiunge più spese di calcolo. Notate che man mano che aggiungete strati di convoluzione, in genere aumentate il loro numero di filtri in modo che il modello possa imparare rappresentazioni più complesse. Se i numeri scelti per questi strati sembrano un po’ arbitrari, sappiate che in generale, si aumentano i filtri man mano che si va avanti e si consiglia di renderli potenze di 2, il che può garantire un leggero vantaggio quando si allena su una GPU.
È importante non avere troppi strati di pooling, poiché ogni pooling scarta alcuni dati. Fare il pooling troppo spesso porterà a non avere quasi nulla da imparare per gli strati densamente connessi quando i dati li raggiungono.
Il numero esatto di strati di pooling che dovreste usare varierà a seconda del compito che state svolgendo, ed è qualcosa che capirete col tempo. Dal momento che le immagini sono già così piccole, non metteremo in comune più di due volte.
Ora puoi ripetere questi strati per dare alla tua rete più rappresentazioni su cui lavorare:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Dopo aver finito con gli strati convoluzionali, abbiamo bisogno di Flatten i dati, che è il motivo per cui abbiamo importato la funzione sopra. Aggiungeremo di nuovo uno strato di dropout:
model.add(Flatten())model.add(Dropout(0.2))Ora facciamo uso dell’importazione Dense e creiamo il primo strato densamente connesso. Dobbiamo specificare il numero di neuroni nello strato denso. Si noti che il numero di neuroni negli strati successivi diminuisce, avvicinandosi alla fine allo stesso numero di neuroni delle classi del dataset (in questo caso 10). Il vincolo del kernel può regolarizzare i dati durante l’apprendimento, un’altra cosa che aiuta a prevenire l’overfitting. Questo è il motivo per cui abbiamo importato maxnorm in precedenza.
model.add(Dense(256, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Dense(128, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())In questo strato finale, passiamo il numero di classi per il numero di neuroni. Ogni neurone rappresenta una classe, e l’output di questo strato sarà un vettore di 10 neuroni con ogni neurone che memorizza una certa probabilità che l’immagine in questione appartenga alla classe che rappresenta.
Infine, la funzione di attivazione softmax seleziona il neurone con la probabilità più alta come suo output, votando che l’immagine appartiene a quella classe:
model.add(Dense(class_num))model.add(Activation('softmax'))Ora che abbiamo progettato il modello che vogliamo usare, dobbiamo solo compilarlo. Specifichiamo il numero di epoche per cui vogliamo allenarci, così come l’ottimizzatore che vogliamo usare.
L’ottimizzatore è quello che sintonizzerà i pesi della rete per avvicinarsi al punto di minor perdita. L’algoritmo Adam è uno degli ottimizzatori più comunemente usati perché dà grandi prestazioni sulla maggior parte dei problemi:
epochs = 25optimizer = 'adam'Compiliamo ora il modello con i parametri scelti. Specifichiamo anche una metrica da utilizzare.
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=)Possiamo stampare il riassunto del modello per vedere come appare l’intero modello.
print(model.summary())Stampare il riassunto ci darà un bel po’ di informazioni:
Results: Layer (type) Output Shape Param #=================================================================conv2d_1 (Conv2D) (None, 32, 32, 32) 896_________________________________________________________________activation_1 (Activation) (None, 32, 32, 32) 0_________________________________________________________________dropout_1 (Dropout) (None, 32, 32, 32) 0_________________________________________________________________batch_normalization_1 (Batch (None, 32, 32, 32) 128_________________________________________________________________conv2d_2 (Conv2D) (None, 32, 32, 64) 18496_________________________________________________________________activation_2 (Activation) (None, 32, 32, 64) 0_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0_________________________________________________________________dropout_2 (Dropout) (None, 16, 16, 64) 0_________________________________________________________________batch_normalization_2 (Batch (None, 16, 16, 64) 256_________________________________________________________________conv2d_3 (Conv2D) (None, 16, 16, 64) 36928_________________________________________________________________activation_3 (Activation) (None, 16, 16, 64) 0_________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0_________________________________________________________________dropout_3 (Dropout) (None, 8, 8, 64) 0_________________________________________________________________batch_normalization_3 (Batch (None, 8, 8, 64) 256_________________________________________________________________conv2d_4 (Conv2D) (None, 8, 8, 128) 73856_________________________________________________________________activation_4 (Activation) (None, 8, 8, 128) 0_________________________________________________________________dropout_4 (Dropout) (None, 8, 8, 128) 0_________________________________________________________________batch_normalization_4 (Batch (None, 8, 8, 128) 512_________________________________________________________________flatten_1 (Flatten) (None, 8192) 0_________________________________________________________________dropout_5 (Dropout) (None, 8192) 0_________________________________________________________________dense_1 (Dense) (None, 256) 2097408_________________________________________________________________activation_5 (Activation) (None, 256) 0_________________________________________________________________dropout_6 (Dropout) (None, 256) 0_________________________________________________________________batch_normalization_5 (Batch (None, 256) 1024_________________________________________________________________dense_2 (Dense) (None, 128) 32896_________________________________________________________________activation_6 (Activation) (None, 128) 0_________________________________________________________________dropout_7 (Dropout) (None, 128) 0_________________________________________________________________batch_normalization_6 (Batch (None, 128) 512_________________________________________________________________dense_3 (Dense) (None, 10) 1290_________________________________________________________________activation_7 (Activation) (None, 10) 0=================================================================Total params: 2,264,458Trainable params: 2,263,114Non-trainable params: 1,344Ora possiamo allenare il modello. Per fare questo, tutto quello che dobbiamo fare è chiamare la funzione fit() sul modello e passare i parametri scelti.
Ecco dove uso il seme che ho scelto, ai fini della riproducibilità.
numpy.random.seed(seed)model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)Ci alleniamo su 50000 campioni e validiamo su 10000 campioni.
Eseguendo questo pezzo di codice otterremo:
Epoch 1/2564/50000 - ETA: 16:57 - loss: 3.1479 - acc: 0.0938128/50000 - ETA: 10:12 - loss: 3.0212 - acc: 0.0938192/50000 - ETA: 7:57 - loss: 2.9781 - acc: 0.1250256/50000 - ETA: 6:48 - loss: 2.8830 - acc: 0.1484320/50000 - ETA: 6:07 - loss: 2.8878 - acc: 0.1469384/50000 - ETA: 5:40 - loss: 2.8732 - acc: 0.1458448/50000 - ETA: 5:20 - loss: 2.8842 - acc: 0.1406.........49664/50000 - ETA: 1s - loss: 1.5160 - acc: 0.461149728/50000 - ETA: 1s - loss: 1.5157 - acc: 0.461249792/50000 - ETA: 1s - loss: 1.5153 - acc: 0.461449856/50000 - ETA: 0s - loss: 1.5147 - acc: 0.461549920/50000 - ETA: 0s - loss: 1.5144 - acc: 0.461749984/50000 - ETA: 0s - loss: 1.5141 - acc: 0.461750000/50000 - 262s 5ms/step - loss: 1.5140 - acc: 0.4618 - val_loss: 1.0715 - val_acc: 0.6195End of Epoch 1Nota che nella maggior parte dei casi, vorrai avere un set di validazione che sia diverso dal set di test, e quindi specificherai una percentuale dei dati di allenamento da usare come set di validazione. In questo caso, passeremo solo i dati di test per assicurarci che i dati di test siano messi da parte e non addestrati. Avremo solo dati di test in questo esempio, per mantenere le cose semplici.
Ora possiamo valutare il modello e vedere come si è comportato. Basta chiamare model.evaluate():
# Model evaluationscores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%" % (scores*100))E siamo accolti dal risultato:
Accuracy: 83.01%E questo è tutto! Ora abbiamo una CNN addestrata al riconoscimento delle immagini. Non male per la prima esecuzione, ma probabilmente vorrai giocare con la struttura e i parametri del modello per vedere se puoi ottenere prestazioni migliori.
Conclusione
Ora che hai implementato la tua prima rete di riconoscimento delle immagini in Keras, sarebbe una buona idea giocare con il modello e vedere come cambiare i suoi parametri influenza le sue prestazioni.
Questo ti darà qualche intuizione sulle scelte migliori per diversi parametri del modello. Dovresti anche documentarti sulle diverse scelte di parametri e iperparametri mentre lo fai. Dopo esservi sentiti a vostro agio con questi parametri, potete provare a implementare il vostro classificatore di immagini su un diverso set di dati.
Se volete giocare con il codice o semplicemente studiarlo un po’ più a fondo, il progetto è caricato su GitHub!