- Bevezetés
- Fogalmak
- TensorFlow/Keras
- Képfelismerés (osztályozás)
- Jellemzők kinyerése
- Hogyan tanulják meg a neurális hálózatok a képek felismerését
- Feature Extraction With Filters
- Activation Functions
- Pooling Layers
- Flattening
- Teljesen összekapcsolt réteg
- A gépi tanulás munkafolyamata
- Adatok előkészítése
- A modell létrehozása
- A modell gyakorlása
- Modell értékelése
- Képfelismerés CNN-nel
- Az adatok előkészítése
- A modell tervezése
- A modell létrehozása
- Következtetés
Bevezetés
A TensorFlow és a Keras egyik leggyakoribb felhasználási területe a képek felismerése/osztályozása. Ha szeretnéd megtanulni, hogyan használhatod a Keras-t képek osztályozására vagy felismerésére, ez a cikk megtanít arra, hogyan.
Fogalmak
Ha nem vagy tisztában a képfelismerés alapfogalmaival, akkor nehéz lesz teljesen megérteni a cikk további részét. Mielőtt tehát továbbmennénk, szánjunk egy pillanatra néhány fogalom meghatározására.
TensorFlow/Keras

Credit: commons.wikimedia.org
A TensorFlow egy nyílt forráskódú könyvtár, amelyet a Google Brain csapata készített Pythonhoz. A TensorFlow számos különböző algoritmust és modellt állít össze, lehetővé téve a felhasználó számára, hogy mély neurális hálózatokat implementáljon olyan feladatokhoz, mint a képfelismerés/osztályozás és a természetes nyelvi feldolgozás. A TensorFlow egy nagy teljesítményű keretrendszer, amely úgy működik, hogy feldolgozási csomópontok sorozatát valósítja meg, amelyek mindegyike egy-egy matematikai műveletet képvisel, a csomópontok teljes sorozatát pedig “gráfnak” nevezik.
A Keras egy olyan magas szintű API (alkalmazásprogramozási interfész), amely alatt a TensorFlow függvényeit (valamint más ML-könyvtárakat, például a Theanót) lehet használni. A Keras tervezésekor a felhasználóbarátság és a modularitás volt a vezérelv. Gyakorlatilag a Keras a lehető legegyszerűbbé teszi a TensorFlow számos nagy teljesítményű, de gyakran összetett funkciójának megvalósítását, és úgy van beállítva, hogy nagyobb módosítások vagy konfiguráció nélkül működjön együtt a Python nyelvvel.
Képfelismerés (osztályozás)
A képfelismerés azt a feladatot jelenti, amikor egy képet beviszünk egy neurális hálózatba, és az valamilyen címkét ad ki a képre. A hálózat által kiadott címke egy előre meghatározott osztálynak felel meg. A képet több osztályba is lehet sorolni, vagy csak egy osztályba. Ha egyetlen osztály van, akkor gyakran a “felismerés” kifejezést használják, míg a több osztályos felismerési feladatot gyakran “osztályozásnak” nevezik.
A képosztályozás egy részhalmaza az objektumfelismerés, ahol a tárgyak meghatározott példányait azonosítják, mint amelyek egy bizonyos osztályba tartoznak, mint például állatok, autók vagy emberek.
Jellemzők kinyerése
A képfelismerés/osztályozás elvégzéséhez a neurális hálózatnak jellemzőkinyerést kell végeznie. A jellemzők az adatok azon elemei, amelyekkel törődünk, és amelyeket a hálózaton keresztül táplálunk. A képfelismerés konkrét esetében a jellemzők egy objektum pixelcsoportjai, például élek és pontok, amelyeket a hálózat elemezni fog minták keresése céljából.
A jellemzőfelismerés (vagy jellemzőkivonás) az a folyamat, amelynek során a bemeneti képből kivonjuk a releváns jellemzőket, hogy ezeket a jellemzőket elemezni lehessen. Sok kép tartalmaz megjegyzéseket vagy metaadatokat a képről, amelyek segítenek a hálózatnak megtalálni a releváns jellemzőket.
Hogyan tanulják meg a neurális hálózatok a képek felismerését
A neurális hálózat képfelismerési folyamatának megismerése segít a neurális hálózati modell implementálásakor, ezért a következő néhány szakaszban röviden megvizsgáljuk a képfelismerési folyamatot.
Feature Extraction With Filters
Credit: commons.wikimedia.org
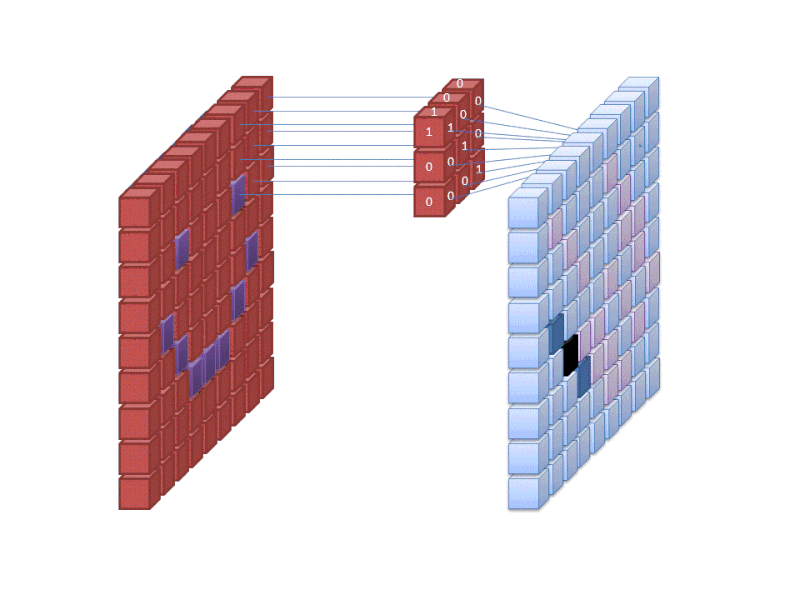
A neurális hálózat első rétege a képen belüli összes pixelt befogadja. Miután az összes adatot betáplálták a hálózatba, különböző szűrőket alkalmaznak a képre, amelyek a kép különböző részeinek reprezentációit alkotják. Ez a jellemzőkivonás, és “jellemzőtérképeket” hoz létre.
A kép jellemzőinek kivonása egy “konvolúciós réteggel” történik, és a konvolúció egyszerűen a kép egy részének reprezentációját képezi. Ebből a konvolúciós koncepcióból származik a konvolúciós neurális hálózat (CNN) kifejezés, a képosztályozásban/felismerésben leggyakrabban használt neurális hálózat típusa.
Ha el akarja képzelni, hogyan működik a jellemzőtérképek létrehozása, gondoljon arra, hogy egy sötét szobában egy zseblámpát világít egy kép fölé. Miközben a fénysugarat a kép fölé csúsztatod, megismered a kép jellemzőit. A szűrő az, amit a hálózat a kép reprezentációjának kialakításához használ, és ebben a metaforában a zseblámpa fénye a szűrő.
A zseblámpa fénysugarának szélessége szabályozza, hogy a kép mekkora részét vizsgálja egyszerre, és a neurális hálózatoknak is van egy hasonló paraméterük, a szűrő mérete. A szűrő mérete befolyásolja, hogy a kép mekkora részét, hány pixelt vizsgálunk egyszerre. A CNN-ekben használt gyakori szűrőméret a 3, és ez a magasságot és a szélességet is lefedi, tehát a szűrő egy 3 x 3 pixeles területet vizsgál.
Credit: commons.wikimedia.org
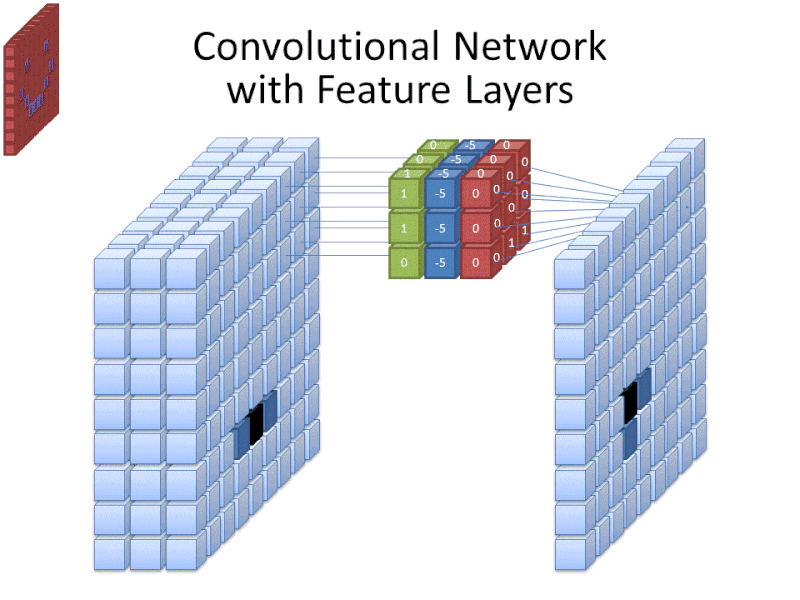
Míg a szűrőméret a szűrő magasságát és szélességét fedi le, a szűrő mélységét is meg kell adni.
Hogyan van egy 2D-s képnek mélysége?
A digitális képeket magasság, szélesség és valamilyen, a pixel színeit meghatározó RGB-érték formájában renderelik, így a követett “mélység” a kép színcsatornáinak száma. A szürkeárnyalatos (nem színes) képek csak 1 színcsatornával rendelkeznek, míg a színes képek 3 mélységcsatornával.
Ez azt jelenti, hogy egy teljes színű képre alkalmazott 3 méretű szűrő esetén a szűrő méretei 3 x 3 x 3. A szűrő által lefedett minden egyes pixel esetében a hálózat megszorozza a szűrő értékeit maguknak a pixeleknek az értékeivel, hogy megkapja az adott pixel numerikus ábrázolását. Ezt a folyamatot ezután az egész képre elvégezzük a teljes reprezentáció elérése érdekében. A szűrő a “stride” nevű paraméter szerint mozog a kép többi részén, amely meghatározza, hogy hány képponttal kell mozgatni a szűrőt, miután kiszámította az értéket az aktuális pozíciójában. A CNN hagyományos stride mérete 2.
A számítások végeredménye egy jellemzőtérkép. Ez a folyamat jellemzően több szűrővel történik, ami segít megőrizni a kép komplexitását.
Activation Functions
A kép jellemzőtérképének elkészülte után a képet reprezentáló értékeket egy aktivációs függvényen vagy aktivációs rétegen vezetjük át. Az aktiváló függvény a képet reprezentáló értékeket, amelyek a konvolúciós rétegnek köszönhetően lineáris formában vannak (azaz csak számok listája), átveszi, és növeli azok nemlinearitását, mivel a képek maguk is nemlineárisak.
A tipikus aktiválási függvény, amelyet ennek elérésére használnak, a Rectified Linear Unit (ReLU), bár alkalmanként más aktiválási függvényeket is használnak (ezekről itt olvashat).
Pooling Layers
Az adatok aktiválása után egy pooling rétegen keresztül kerülnek. A pooling “lemintavételezi” a képet, ami azt jelenti, hogy a képet reprezentáló információt fogadja és tömöríti, azaz kisebbé teszi. A pooling folyamat rugalmasabbá teszi a hálózatot, és ügyesebbé teszi a tárgyak/képek felismerését a releváns jellemzők alapján.
Amikor egy képet nézünk, általában nem foglalkozunk a kép hátterében lévő összes információval, csak a számunkra fontos jellemzőkkel, például az emberekkel vagy állatokkal.
Hasonlóképpen, a CNN-ben egy pooling réteg elvonatkoztatja a kép felesleges részeit, és csak a kép azon részeit tartja meg, amelyeket relevánsnak tart, amit a pooling réteg meghatározott mérete szabályoz.
Mivel a hálózatnak a kép legrelevánsabb részeiről kell döntéseket hoznia, a remény az, hogy a hálózat csak a kép azon részeit tanulja meg, amelyek valóban a szóban forgó tárgyat képviselik. Ez segít megelőzni a túlillesztést, amikor a hálózat túl jól megtanulja a képzési eset aspektusait, és nem képes általánosítani az új adatokra.
Credit: commons.wikimedia.org
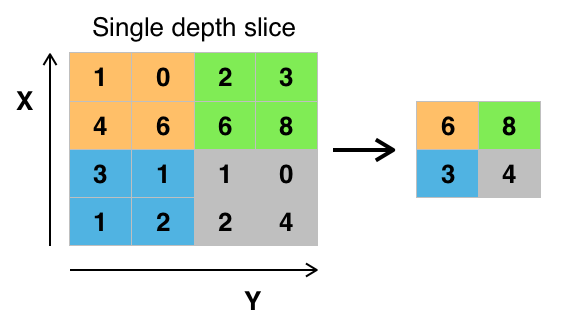
Az értékek összevonásának különböző módjai vannak, de a leggyakrabban a max poolingot használják. A max pooling a pixelek maximális értékét kapja egyetlen szűrőn belül (a kép egyetlen pontján belül). Ez az információ 3/4-ed részét ejti el, feltételezve, hogy 2 x 2 szűrőt használunk.
A pixelek maximális értékeit a kép esetleges torzulásainak figyelembevétele érdekében használjuk, és a kép paramétereit/méretét csökkentjük a túlillesztés ellenőrzése érdekében. Léteznek más pooling típusok is, mint például az átlag pooling vagy az összeg pooling, de ezeket nem használják olyan gyakran, mert a max pooling általában jobb pontosságot eredményez.
Flattening
CNN-ünk utolsó rétegei, a sűrűn kapcsolt rétegek megkövetelik, hogy a feldolgozandó adatok vektor formájában legyenek. Emiatt az adatokat “laposítani” kell. Az értékeket hosszú vektorba vagy egymás után sorba rendezett számok oszlopába tömörítjük.
Teljesen összekapcsolt réteg
A CNN utolsó rétegei a sűrűn összekapcsolt rétegek, vagyis a mesterséges neurális hálózat (ANN). Az ANN elsődleges feladata a bemeneti jellemzők elemzése és kombinálása különböző attribútumokká, amelyek segítenek az osztályozásban. Ezek a rétegek lényegében neuronok gyűjteményeit alkotják, amelyek a kérdéses tárgy különböző részeit képviselik, és a neuronok egy gyűjteménye képviselheti egy kutya lógó fülét vagy egy alma piros színét. Ha elég sok ilyen neuron aktiválódik egy bemeneti kép hatására, a képet objektumként fogja besorolni.

Credit: commons.wikimedia.org
A hibát, vagyis a kiszámított értékek és a képzési halmazban várható érték közötti különbséget az ANN kiszámítja. A hálózat ezután backpropagáción megy keresztül, ahol egy adott neuron befolyása a következő rétegben lévő neuronra kiszámításra kerül, és annak befolyása kiigazításra kerül. Ez a modell teljesítményének optimalizálása érdekében történik. Ez a folyamat ezután újra és újra megismétlődik. Így gyakorol a hálózat az adatokon, és tanulja meg a bemeneti jellemzők és a kimeneti osztályok közötti összefüggéseket.
A középső, teljesen összekapcsolt rétegekben lévő neuronok a lehetséges osztályokhoz kapcsolódó bináris értékeket adnak ki. Ha négy különböző osztály van (mondjuk egy kutya, egy autó, egy ház és egy ember), a neuron egy “1” értéket fog adni arra az osztályra, amelyet a kép szerinte képvisel, és egy “0” értéket a többi osztályra.
A végső, teljesen összekapcsolt réteg megkapja az előtte lévő réteg kimenetét, és minden egyes osztályra egy valószínűséget ad, amelyet egybe összegez. Ha a “kutya” kategóriában 0,75 érték van, az 75%-os bizonyosságot jelent, hogy a kép egy kutya.
A képosztályozót most már betanítottuk, és a képeket átadhatjuk a CNN-nek, amely most már ki fog adni egy tippet az adott kép tartalmáról.
A gépi tanulás munkafolyamata
Mielőtt belevágnánk egy képosztályozó képzésének példájába, szánjunk egy percet a gépi tanulás munkafolyamatának vagy pipeline-jának megértésére. Egy neurális hálózati modell képzésének folyamata meglehetősen szabványos, és négy különböző fázisra bontható.
Adatok előkészítése
Először is össze kell gyűjtenünk az adatokat, és olyan formába kell hoznunk őket, amelyen a hálózat képes a képzésre. Ez magában foglalja a képek összegyűjtését és címkézését. Még akkor is, ha letöltött egy olyan adatkészletet, amelyet valaki más készített, valószínűleg előfeldolgozást vagy előkészítést kell végeznie, mielőtt felhasználhatja a képzéshez. Az adatok előkészítése egy külön művészet, amely magában foglalja az olyan dolgok kezelését, mint a hiányzó értékek, sérült adatok, rossz formátumú adatok, helytelen címkék stb.
Ebben a cikkben egy előfeldolgozott adathalmazt fogunk használni.
A modell létrehozása
A neurális hálózat modelljének létrehozása magában foglalja a különböző paraméterek és hiperparaméterek kiválasztását. Döntéseket kell hoznia arról, hogy hány réteget használjon a modellben, mekkora legyen a rétegek bemeneti és kimeneti mérete, milyen aktiválási függvényeket használjon, használjon-e kiesést vagy sem stb.
Az, hogy milyen paramétereket és hiperparamétereket használj, idővel (és sok tanulással) fog jönni, de rögtön az elején van néhány heurisztika, amit használhatsz, és ezek közül néhányat az implementációs példa során tárgyalunk.
A modell gyakorlása
A modell létrehozását követően egyszerűen létrehozod a modell egy példányát, és illeszted a gyakorlóadatokkal. A modell betanításakor a legnagyobb szempont az, hogy mennyi időt vesz igénybe a modell betanítása. A hálózat képzésének hosszát az epochák számának megadásával adhatja meg. Minél hosszabb ideig edzünk egy modellt, annál jobban javul a teljesítménye, de ha túl sok edzési epochát használunk, akkor fennáll a túlillesztés veszélye.
Az edzendő epochák számának kiválasztása olyasmi, amire rá fogunk érezni, és szokás a hálózat súlyait két edzés között elmenteni, hogy ne kelljen újra kezdeni, ha már elértünk némi haladást a hálózat edzésében.
Modell értékelése
A modell értékelésének több lépése van. A modell kiértékelésének első lépése a modell teljesítményének összehasonlítása egy validációs adathalmazzal, egy olyan adathalmazzal, amelyen a modellt nem képezték ki. Összehasonlítja a modell teljesítményét ezzel a validációs adathalmazzal, és különböző mérőszámok segítségével elemzi a teljesítményét.
Egy neurális hálózati modell teljesítményének meghatározására különböző mérőszámok léteznek, de a leggyakoribb mérőszám a “pontosság”, azaz a helyesen osztályozott képek száma osztva az adathalmazban lévő képek teljes számával.
Azt követően, hogy megnézte a modell teljesítményének pontosságát egy validációs adathalmazon, általában visszamegy, és kissé módosított paraméterekkel újra betanítja a hálózatot, mert nem valószínű, hogy már az első betanításkor elégedett lesz a hálózat teljesítményével. Folyamatosan módosítja a hálózat paramétereit, újratanítja azt, és addig méri a teljesítményét, amíg elégedett nem lesz a hálózat pontosságával.
Végül teszteli a hálózat teljesítményét egy tesztkészleten. Ez a tesztkészlet egy másik adathalmaz, amelyet a modellje még soha nem látott.
Talán elgondolkodik:
Miért vesződjön a tesztkészlettel? Ha képet kap a modellje pontosságáról, nem ez a célja a validációs halmaznak?
Ez a jó ötlet, hogy egy olyan adathalmazt tartson meg tesztelésre, amelyet a hálózat még soha nem látott, mert a paraméterek összes finomhangolása, amit a validációs halmazon végzett újrateszteléssel együtt azt jelentheti, hogy a hálózata megtanulta a validációs halmaz néhány sajátosságát, amelyek nem fognak általánosítani a mintán kívüli adatokra.
A tesztkészlet célja tehát az, hogy ellenőrizze az olyan problémákat, mint a túlillesztés, és biztosabb legyen abban, hogy a modellje valóban alkalmas a valós világban való teljesítményre.
Képfelismerés CNN-nel
Eddig sok mindent lefedtünk, és ha mindez az információ egy kicsit nyomasztó volt, akkor ha látjuk, hogy ezek a fogalmak egy adathalmazon kiképzett mintaosztályozóban egyesülnek, akkor ezeknek a fogalmaknak konkrétabbá kell válniuk. Nézzünk tehát egy teljes példát a képfelismerésre a Keras segítségével, az adatok betöltésétől a kiértékelésig.

Credit: www.cs.toronto.edu
Kezdésnek szükségünk lesz egy adathalmazra, amin gyakorolhatunk. Ebben a példában a híres CIFAR-10 adathalmazt fogjuk használni. A CIFAR-10 egy nagyméretű képadatkészlet, amely több mint 60 000 képet tartalmaz, amelyek 10 különböző osztályba tartozó tárgyat, például macskákat, repülőgépeket és autókat képviselnek.
A képek teljes RGB színűek, de meglehetősen kicsik, mindössze 32 x 32 képméretűek. A CIFAR-10 adathalmaz egyik nagyszerű tulajdonsága, hogy előre csomagolva érkezik a Keras-szal, így nagyon könnyű betölteni az adathalmazt, és a képek nagyon kevés előfeldolgozást igényelnek.
Az első dolog, amit tennünk kell, az a szükséges könyvtárak importálása. Majd menet közben megmutatom, hogyan használjuk ezeket az importokat, de egyelőre annyit tudjunk, hogy a Numpy-t és a Kerashoz kapcsolódó különböző modulokat fogjuk használni:
import numpyfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activationfrom keras.layers.convolutional import Conv2D, MaxPooling2Dfrom keras.constraints import maxnormfrom keras.utils import np_utilsVéletlenszerű magot fogunk itt használni, hogy a cikkben elért eredményeket megismételhessük, ezért van szükségünk numpy:
# Set random seed for purposes of reproducibilityseed = 21Az adatok előkészítése
Még egy importra van szükségünk: az adatkészletre.
from keras.datasets import cifar10Most töltsük be az adatkészletet. Ezt egyszerűen megtehetjük, ha megadjuk, hogy milyen változókba akarjuk betölteni az adatokat, majd használjuk a load_data() függvényt:
# loading in the data (X_train, y_train), (X_test, y_test) = cifar10.load_data()A legtöbb esetben szükségünk lesz az adatok előfeldolgozására, hogy használatra készek legyenek, de mivel mi egy előre csomagolt adatkészletet használunk, nagyon kevés előfeldolgozásra van szükség. Az egyik dolog, amit meg akarunk tenni, az a bemeneti adatok normalizálása.
Ha a bemeneti adatok értékei túl széles tartományban vannak, az negatívan befolyásolhatja a hálózat teljesítményét. Ebben az esetben a bemeneti értékek a kép képpontjai, amelyek értéke 0 és 255 között van.
Az adatok normalizálásához tehát egyszerűen elosztjuk a kép értékeit 255-tel. Ehhez először is float típusúvá kell tennünk az adatokat, mivel jelenleg egész számok. Ezt úgy tudjuk megtenni, hogy a astype() Numpy parancsot használjuk, majd deklaráljuk, hogy milyen adattípust szeretnénk:
# normalize the inputs from 0-255 to between 0 and 1 by dividing by 255 X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = X_train / 255.0X_test = X_test / 255.0A másik dolog, amit meg kell tennünk, hogy az adatok készen álljanak a hálózatra, az az értékek one-hot kódolása. A one-hot kódolás részleteibe itt nem megyek bele, de egyelőre annyit tudjunk, hogy a képeket a hálózat nem tudja úgy használni, ahogy vannak, előbb kódolni kell őket, és a one-hot kódolás akkor a legjobb, ha bináris osztályozást végzünk.
Itt gyakorlatilag bináris osztályozást végzünk, mert egy kép vagy az egyik osztályba tartozik, vagy nem, nem eshet valahova a kettő közé. A Numpy to_categorical() parancsot használjuk az egy-hot kódoláshoz. Ezért importáltuk a np_utils függvényt a Kerasból, mivel az tartalmazza a to_categorical()-t.
Meg kell adnunk azt is, hogy hány osztály van az adathalmazban, hogy tudjuk, hány neuronra kell tömöríteni az utolsó réteget:
# one hot encode outputsy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)class_num = y_test.shapeA modell tervezése
Elérkeztünk ahhoz a szakaszhoz, amikor a CNN modellt tervezzük. Az első dolog, amit meg kell tennünk, hogy meghatározzuk a formátumot, amit a modellhez használni szeretnénk, a Kerasnak több különböző formátuma vagy tervrajza van a modellek felépítéséhez, de a Sequential a leggyakrabban használt, és emiatt importáltuk a Kerasból.
A modell létrehozása
model = Sequential()A modellünk első rétege egy konvolúciós réteg. Ez fogja fogadni a bemeneteket és konvolúciós szűrőket futtat rajtuk.
A Kerasban történő implementáláskor meg kell adnunk a kívánt csatornák/szűrők számát (ez alul a 32), a kívánt szűrő méretét (jelen esetben 3 x 3), a bemeneti alakot (az első réteg létrehozásakor) és a szükséges aktiválást és kitöltést.
Mint említettük, a relu a leggyakoribb aktiválás, a padding='same' pedig csak azt jelenti, hogy egyáltalán nem változtatjuk meg a kép méretét:
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape, padding='same'))model.add(Activation('relu'))Megjegyzés: Az aktiválásokat és az összevonásokat össze is fűzhetjük, így:
model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), activation='relu', padding='same'))Most létrehozunk egy kieső réteget a túlillesztés megelőzésére, ami úgy működik, hogy véletlenszerűen megszüntetjük a rétegek közötti kapcsolatok egy részét (0.2 azt jelenti, hogy a meglévő kapcsolatok 20%-át ejti ki):
model.add(Dropout(0.2))Itt is elvégezhetjük a tételes normalizálást. A tételes normalizálás normalizálja a következő rétegbe kerülő bemeneteket, így biztosítva, hogy a hálózat mindig olyan eloszlású aktivációkat hozzon létre, amilyenre vágyunk:
model.add(BatchNormalization())Most egy újabb konvolúciós réteg következik, de a szűrő mérete nő, így a hálózat komplexebb reprezentációkat tud megtanulni:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))Itt van a pooling réteg, mint korábban tárgyaltuk ez segít robusztusabbá tenni a képosztályozót, hogy releváns mintákat tudjon tanulni. Itt van még a kiesés és a tételes normalizálás:
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization())Ez a CNN implementáció első felének alapfolyamata: Konvolúció, aktiválás, kiesés, összevonás. Most már láthatod, hogy miért importáltuk a Dropout, BatchNormalization, Activation, Conv2d és MaxPooling2d kódokat.
A konvolúciós rétegek pontos számát tetszés szerint variálhatod, bár mindegyik több számítási költséggel jár. Vegye észre, hogy a konvolúciós rétegek hozzáadásával jellemzően növeli a szűrők számát, így a modell összetettebb reprezentációkat tud megtanulni. Ha a rétegek számára választott számok kissé önkényesnek tűnnek, csak tudd, hogy általában a szűrők számát növeled, ahogy haladsz előre, és tanácsos a szűrőket 2-es hatványokra tenni, ami némi előnyt biztosíthat GPU-n történő tréning esetén.
Fontos, hogy ne legyen túl sok pooling réteged, mivel minden egyes pooling elvet néhány adatot. A túl gyakori pooling azt eredményezi, hogy a sűrűn összekapcsolt rétegek számára szinte semmi sem marad, amiről tanulhatnának, amikor az adatok elérik őket.
Az, hogy pontosan hány pooling réteget érdemes használni, a feladat függvényében változik, és ez olyasmi, amire idővel ráérezhetünk. Mivel a képek itt már olyan kicsik, nem fogunk kétszeresnél többet poololni.
Most megismételheti ezeket a rétegeket, hogy a hálózatának több reprezentációt adjon, amiből dolgozhat:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Miután végeztünk a konvolúciós rétegekkel, szükségünk van az Flatten adatokra, ezért importáltuk a fenti függvényt. Újra hozzáadunk egy kieső réteget is:
model.add(Flatten())model.add(Dropout(0.2))Most kihasználjuk az Dense importot, és létrehozzuk az első sűrűn kapcsolt réteget. Meg kell adnunk a neuronok számát a sűrű rétegben. Vegyük észre, hogy az egymást követő rétegekben a neuronok száma csökken, és végül megközelíti azt a neuronszámot, ahány osztály van az adathalmazban (ebben az esetben 10). A kernel megkötés a tanulás során regularizálhatja az adatokat, ami szintén segít megelőzni a túlillesztést. Ezért importáltuk korábban a maxnorm értéket.
model.add(Dense(256, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Dense(128, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Ebben az utolsó rétegben az osztályok számát adjuk meg a neuronok számának. Minden neuron egy osztályt képvisel, és ennek a rétegnek a kimenete egy 10 neuronból álló vektor lesz, ahol minden neuron tárol valamilyen valószínűséget arra, hogy a kérdéses kép az általa képviselt osztályba tartozik.
Végül az softmax aktivációs függvény a legnagyobb valószínűségű neuront választja ki kimenetként, megszavazva, hogy a kép az adott osztályba tartozik:
model.add(Dense(class_num))model.add(Activation('softmax'))Most, hogy megterveztük a használni kívánt modellt, már csak össze kell állítanunk. Adjuk meg az epochák számát, amire edzeni szeretnénk, valamint az optimalizálót, amit használni szeretnénk.
Az optimalizáló az, ami a hálózat súlyait úgy fogja hangolni, hogy megközelítse a legkisebb veszteséggel járó pontot. A Adam algoritmus az egyik leggyakrabban használt optimalizáló, mert a legtöbb problémánál nagyszerű teljesítményt nyújt:
epochs = 25optimizer = 'adam'Elkészítsük most a modellt a választott paramétereinkkel. Adjuk meg a használni kívánt metrikát is.
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=)Kinyomtathatjuk a modell összefoglalóját, hogy lássuk, hogyan néz ki a teljes modell.
print(model.summary())Az összefoglaló kinyomtatásával elég sok információt kapunk:
Results: Layer (type) Output Shape Param #=================================================================conv2d_1 (Conv2D) (None, 32, 32, 32) 896_________________________________________________________________activation_1 (Activation) (None, 32, 32, 32) 0_________________________________________________________________dropout_1 (Dropout) (None, 32, 32, 32) 0_________________________________________________________________batch_normalization_1 (Batch (None, 32, 32, 32) 128_________________________________________________________________conv2d_2 (Conv2D) (None, 32, 32, 64) 18496_________________________________________________________________activation_2 (Activation) (None, 32, 32, 64) 0_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0_________________________________________________________________dropout_2 (Dropout) (None, 16, 16, 64) 0_________________________________________________________________batch_normalization_2 (Batch (None, 16, 16, 64) 256_________________________________________________________________conv2d_3 (Conv2D) (None, 16, 16, 64) 36928_________________________________________________________________activation_3 (Activation) (None, 16, 16, 64) 0_________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0_________________________________________________________________dropout_3 (Dropout) (None, 8, 8, 64) 0_________________________________________________________________batch_normalization_3 (Batch (None, 8, 8, 64) 256_________________________________________________________________conv2d_4 (Conv2D) (None, 8, 8, 128) 73856_________________________________________________________________activation_4 (Activation) (None, 8, 8, 128) 0_________________________________________________________________dropout_4 (Dropout) (None, 8, 8, 128) 0_________________________________________________________________batch_normalization_4 (Batch (None, 8, 8, 128) 512_________________________________________________________________flatten_1 (Flatten) (None, 8192) 0_________________________________________________________________dropout_5 (Dropout) (None, 8192) 0_________________________________________________________________dense_1 (Dense) (None, 256) 2097408_________________________________________________________________activation_5 (Activation) (None, 256) 0_________________________________________________________________dropout_6 (Dropout) (None, 256) 0_________________________________________________________________batch_normalization_5 (Batch (None, 256) 1024_________________________________________________________________dense_2 (Dense) (None, 128) 32896_________________________________________________________________activation_6 (Activation) (None, 128) 0_________________________________________________________________dropout_7 (Dropout) (None, 128) 0_________________________________________________________________batch_normalization_6 (Batch (None, 128) 512_________________________________________________________________dense_3 (Dense) (None, 10) 1290_________________________________________________________________activation_7 (Activation) (None, 10) 0=================================================================Total params: 2,264,458Trainable params: 2,263,114Non-trainable params: 1,344 Most jöhet a modell betanítása. Ehhez nem kell mást tennünk, mint meghívni a fit() függvényt a modellen, és átadni a kiválasztott paramétereket.
Itt használom az általam választott magot, a reprodukálhatóság érdekében.
numpy.random.seed(seed)model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)50000 mintán fogunk edzeni, és 10000 mintán fogjuk validálni.
Ez a kódrészlet futtatásával:
Epoch 1/2564/50000 - ETA: 16:57 - loss: 3.1479 - acc: 0.0938128/50000 - ETA: 10:12 - loss: 3.0212 - acc: 0.0938192/50000 - ETA: 7:57 - loss: 2.9781 - acc: 0.1250256/50000 - ETA: 6:48 - loss: 2.8830 - acc: 0.1484320/50000 - ETA: 6:07 - loss: 2.8878 - acc: 0.1469384/50000 - ETA: 5:40 - loss: 2.8732 - acc: 0.1458448/50000 - ETA: 5:20 - loss: 2.8842 - acc: 0.1406.........49664/50000 - ETA: 1s - loss: 1.5160 - acc: 0.461149728/50000 - ETA: 1s - loss: 1.5157 - acc: 0.461249792/50000 - ETA: 1s - loss: 1.5153 - acc: 0.461449856/50000 - ETA: 0s - loss: 1.5147 - acc: 0.461549920/50000 - ETA: 0s - loss: 1.5144 - acc: 0.461749984/50000 - ETA: 0s - loss: 1.5141 - acc: 0.461750000/50000 - 262s 5ms/step - loss: 1.5140 - acc: 0.4618 - val_loss: 1.0715 - val_acc: 0.6195End of Epoch 1Megjegyezzük, hogy a legtöbb esetben olyan validálási halmazt szeretnénk, amely különbözik a tesztelési halmaztól, és így megadjuk a képzési adatok egy százalékát, amelyet validálási halmazként használunk. Ebben az esetben csak a tesztadatokat adjuk meg, hogy a tesztadatokat félretegyük, és ne képezzük ki. Ebben a példában csak tesztadatokat fogunk használni, hogy a dolgok egyszerűek maradjanak.
Most kiértékelhetjük a modellt, és megnézhetjük, hogyan teljesített. Csak hívjuk meg a model.evaluate():
# Model evaluationscores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%" % (scores*100))És az eredmény fogad minket:
Accuracy: 83.01%És ennyi! Most már van egy betanított képfelismerő CNN-ünk. Első nekifutásra nem rossz, de valószínűleg érdemes lenne játszani a modell szerkezetével és paramétereivel, hogy megnézzük, nem tudunk-e jobb teljesítményt elérni.
Következtetés
Most, hogy implementáltuk az első képfelismerő hálózatunkat Kerasban, jó ötlet lenne játszani a modellel, és megnézni, hogyan befolyásolja a paraméterek változtatása a teljesítményét.
Ez ad némi intuíciót a különböző modellparaméterek legjobb választásaira. Érdemes közben utánaolvasni a különböző paraméter- és hiperparaméter-választásoknak is. Miután megbarátkoztál ezekkel, megpróbálhatod a saját képosztályozódat egy másik adathalmazon megvalósítani.
Ha szeretnél játszani a kóddal, vagy egyszerűen csak egy kicsit mélyebben tanulmányozni, a projekt fel van töltve a GitHubra!