- Introduction
- Définitions
- TensorFlow/Keras
- Reconnaissance d’images (Classification)
- Extraction de caractéristiques
- Comment les réseaux neuronaux apprennent à reconnaître les images
- Extraction de caractéristiques avec filtres
- Fonctions d’activation
- Couches de mise en commun
- Aplatissement
- Couche entièrement connectée
- Le flux de travail d’apprentissage automatique
- Préparation des données
- Création du modèle
- Entraînement du modèle
- Évaluation du modèle
- Reconnaissance d’images avec un CNN
- Préparation des données
- Conception du modèle
- Créer le modèle
- Conclusion
Introduction
L’une des utilisations les plus courantes de TensorFlow et Keras est la reconnaissance/classification d’images. Si vous voulez apprendre à utiliser Keras pour classer ou reconnaître des images, cet article vous apprendra comment.
Définitions
Si vous n’êtes pas clair sur les concepts de base derrière la reconnaissance d’images, il sera difficile de comprendre complètement le reste de cet article. Donc, avant de poursuivre, prenons un moment pour définir certains termes.
TensorFlow/Keras

Crédit : commons.wikimedia.org
TensorFlow est une bibliothèque open source créée pour Python par l’équipe Google Brain. TensorFlow compile de nombreux algorithmes et modèles différents, permettant à l’utilisateur de mettre en œuvre des réseaux neuronaux profonds pour les utiliser dans des tâches telles que la reconnaissance/classification d’images et le traitement du langage naturel. TensorFlow est un cadre puissant qui fonctionne en mettant en œuvre une série de nœuds de traitement, chaque nœud représentant une opération mathématique, l’ensemble de la série de nœuds étant appelé un « graphe ».
En termes de Keras, il s’agit d’une API (interface de programmation d’applications) de haut niveau qui peut utiliser les fonctions de TensorFlow en dessous (ainsi que d’autres bibliothèques ML comme Theano). Keras a été conçu avec la convivialité et la modularité comme principes directeurs. En termes pratiques, Keras rend l’implémentation des nombreuses fonctions puissantes mais souvent complexes de TensorFlow aussi simple que possible, et il est configuré pour fonctionner avec Python sans aucune modification ou configuration majeure.
Reconnaissance d’images (Classification)
La reconnaissance d’images fait référence à la tâche consistant à entrer une image dans un réseau neuronal et à lui faire sortir une sorte d’étiquette pour cette image. L’étiquette que le réseau sort correspondra à une classe prédéfinie. L’image peut être étiquetée selon plusieurs classes ou une seule. S’il y a une seule classe, le terme « reconnaissance » est souvent appliqué, alors qu’une tâche de reconnaissance multi-classes est souvent appelée « classification ».
Un sous-ensemble de la classification d’images est la détection d’objets, où des instances spécifiques d’objets sont identifiées comme appartenant à une certaine classe comme les animaux, les voitures ou les personnes.
Extraction de caractéristiques
Pour effectuer la reconnaissance/classification d’images, le réseau neuronal doit effectuer une extraction de caractéristiques. Les caractéristiques sont les éléments des données qui vous intéressent et qui vont être introduits dans le réseau. Dans le cas spécifique de la reconnaissance d’images, les caractéristiques sont les groupes de pixels, comme les bords et les points, d’un objet que le réseau analysera pour trouver des modèles.
La reconnaissance de caractéristiques (ou extraction de caractéristiques) est le processus qui consiste à extraire les caractéristiques pertinentes d’une image d’entrée afin que ces caractéristiques puissent être analysées. De nombreuses images contiennent des annotations ou des métadonnées sur l’image qui aident le réseau à trouver les caractéristiques pertinentes.
Comment les réseaux neuronaux apprennent à reconnaître les images
Avoir une intuition de la façon dont un réseau neuronal reconnaît les images vous aidera lorsque vous implémenterez un modèle de réseau neuronal, alors explorons brièvement le processus de reconnaissance d’image dans les prochaines sections.
Extraction de caractéristiques avec filtres
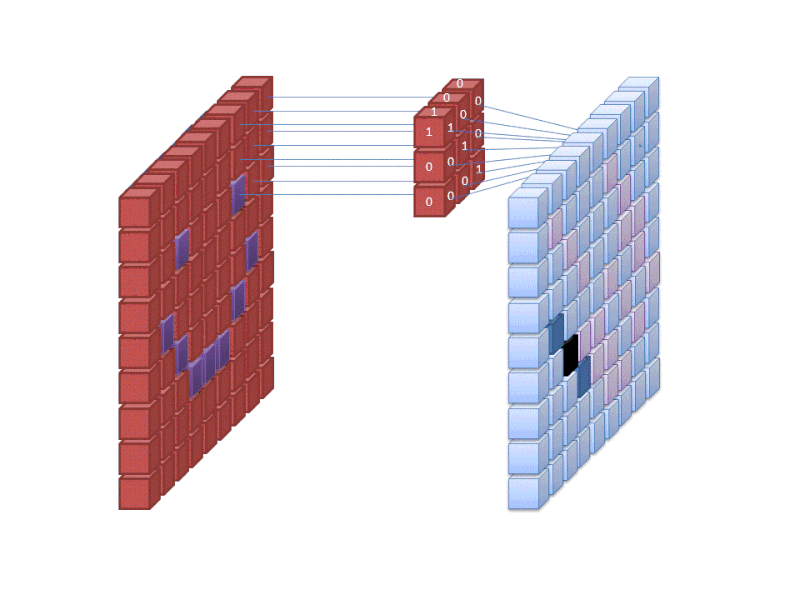
Crédit : commons.wikimedia.org
La première couche d’un réseau neuronal prend en compte tous les pixels d’une image. Une fois que toutes les données ont été introduites dans le réseau, différents filtres sont appliqués à l’image, ce qui forme des représentations de différentes parties de l’image. C’est l’extraction de caractéristiques et cela crée des « cartes de caractéristiques ».
Ce processus d’extraction de caractéristiques d’une image est accompli avec une « couche convolutionnelle », et la convolution consiste simplement à former une représentation d’une partie d’une image. C’est à partir de ce concept de convolution que nous obtenons le terme Réseau neuronal convolutif (CNN), le type de réseau neuronal le plus couramment utilisé dans la classification/reconnaissance d’images.
Si vous voulez visualiser comment fonctionne la création de cartes de caractéristiques, pensez à éclairer une lampe de poche sur une image dans une pièce sombre. Lorsque vous faites glisser le faisceau sur l’image, vous apprenez à connaître les caractéristiques de l’image. Un filtre est ce que le réseau utilise pour former une représentation de l’image, et dans cette métaphore, la lumière de la lampe de poche est le filtre.
La largeur du faisceau de votre lampe de poche contrôle la quantité de l’image que vous examinez en une seule fois, et les réseaux neuronaux ont un paramètre similaire, la taille du filtre. La taille du filtre affecte la quantité de l’image, le nombre de pixels, examinés en une seule fois. Une taille de filtre commune utilisée dans les CNN est 3, et cela couvre à la fois la hauteur et la largeur, de sorte que le filtre examine une zone de pixels de 3 x 3.
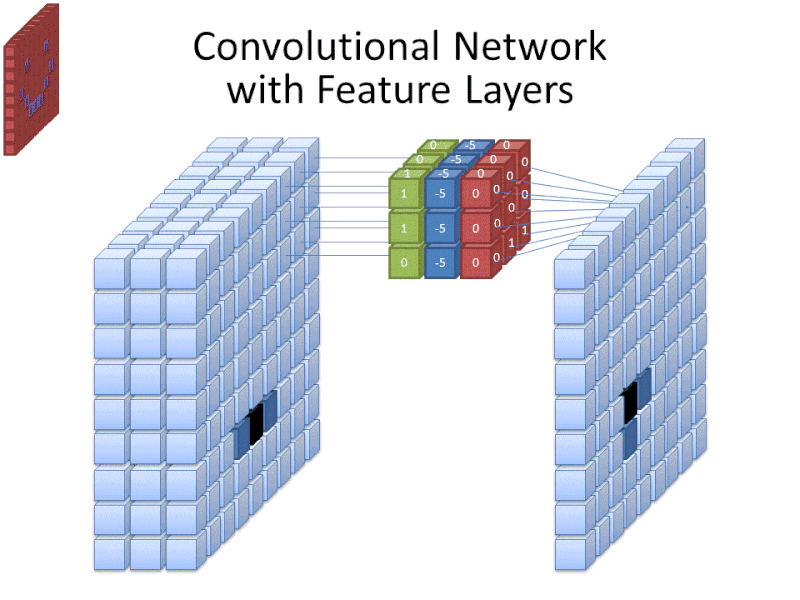
Crédit : commons.wikimedia.org
Alors que la taille du filtre couvre la hauteur et la largeur du filtre, la profondeur du filtre doit également être spécifiée.
Comment une image 2D a-t-elle une profondeur ?
Les images numériques sont rendues sous forme de hauteur, de largeur et d’une certaine valeur RVB qui définit les couleurs du pixel, donc la « profondeur » qui est suivie est le nombre de canaux de couleur que l’image possède. Les images en niveaux de gris (non colorées) n’ont qu’un seul canal de couleur alors que les images en couleurs ont 3 canaux de profondeur.
Tout cela signifie que pour un filtre de taille 3 appliqué à une image en couleurs, les dimensions de ce filtre seront 3 x 3 x 3. Pour chaque pixel couvert par ce filtre, le réseau multiplie les valeurs du filtre avec les valeurs des pixels eux-mêmes pour obtenir une représentation numérique de ce pixel. Ce processus est ensuite appliqué à l’ensemble de l’image pour obtenir une représentation complète. Le filtre est déplacé sur le reste de l’image en fonction d’un paramètre appelé « stride », qui définit de combien de pixels le filtre doit être déplacé après avoir calculé la valeur de sa position actuelle. Une taille de stride conventionnelle pour un CNN est de 2.
Le résultat final de tous ces calculs est une carte de caractéristiques. Ce processus est généralement effectué avec plus d’un filtre, ce qui permet de préserver la complexité de l’image.
Fonctions d’activation
Après la création de la carte de caractéristiques de l’image, les valeurs qui représentent l’image sont passées par une fonction d’activation ou une couche d’activation. La fonction d’activation prend les valeurs qui représentent l’image, qui sont sous une forme linéaire (c’est-à-dire juste une liste de nombres) grâce à la couche convolutive, et augmente leur non-linéarité puisque les images elles-mêmes sont non linéaires.
La fonction d’activation typique utilisée pour accomplir ceci est une unité linéaire rectifiée (ReLU), bien qu’il y ait quelques autres fonctions d’activation qui sont occasionnellement utilisées (vous pouvez lire à leur sujet ici).
Couches de mise en commun
Après que les données soient activées, elles sont envoyées à travers une couche de mise en commun. Le pooling « déséchantillonne » une image, ce qui signifie qu’il prend l’information qui représente l’image et la compresse, la rendant plus petite. Le processus de pooling rend le réseau plus flexible et plus apte à reconnaître des objets/images en fonction des caractéristiques pertinentes.
Lorsque nous regardons une image, nous ne sommes généralement pas concernés par toutes les informations en arrière-plan de l’image, mais seulement par les caractéristiques qui nous intéressent, comme les personnes ou les animaux.
De même, une couche de mise en commun dans un CNN fera abstraction des parties inutiles de l’image, ne conservant que les parties de l’image qu’il juge pertinentes, comme contrôlé par la taille spécifiée de la couche de mise en commun.
Parce qu’il doit prendre des décisions sur les parties les plus pertinentes de l’image, l’espoir est que le réseau n’apprenne que les parties de l’image qui représentent vraiment l’objet en question. Cela permet d’éviter l’overfitting, où le réseau apprend trop bien certains aspects du cas d’entraînement et ne parvient pas à généraliser à de nouvelles données.
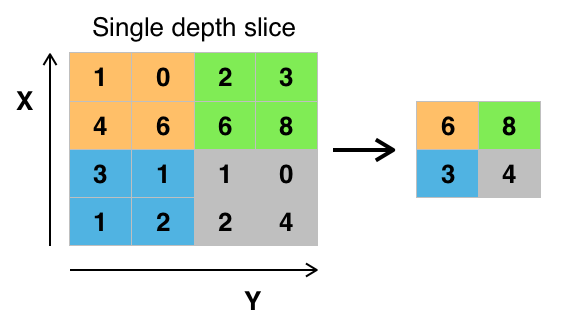
Crédit : commons.wikimedia.org
Il existe différentes façons de mettre en commun les valeurs, mais le max pooling est le plus couramment utilisé. Le max pooling obtient la valeur maximale des pixels dans un seul filtre (dans un seul point de l’image). Cela fait tomber les 3/4 de l’information, en supposant que 2 x 2 filtres sont utilisés.
Les valeurs maximales des pixels sont utilisées afin de prendre en compte les éventuelles distorsions de l’image, et les paramètres/taille de l’image sont réduits afin de contrôler l’overfitting. Il existe d’autres types de pooling comme le pooling moyen ou le pooling par somme, mais ils ne sont pas utilisés aussi fréquemment car le pooling max a tendance à donner une meilleure précision.
Aplatissement
Les couches finales de notre CNN, les couches densément connectées, nécessitent que les données soient sous la forme d’un vecteur pour être traitées. Pour cette raison, les données doivent être « aplaties ». Les valeurs sont compressées en un long vecteur ou une colonne de nombres ordonnés séquentiellement.
Couche entièrement connectée
Les couches finales du CNN sont des couches densément connectées, ou un réseau neuronal artificiel (ANN). La fonction principale de l’ANN est d’analyser les caractéristiques d’entrée et de les combiner en différents attributs qui aideront à la classification. Ces couches forment essentiellement des collections de neurones qui représentent différentes parties de l’objet en question. Une collection de neurones peut représenter les oreilles tombantes d’un chien ou la rougeur d’une pomme. Lorsqu’un nombre suffisant de ces neurones sont activés en réponse à une image d’entrée, l’image sera classée comme un objet.

Crédit : commons.wikimedia.org
L’erreur, ou la différence entre les valeurs calculées et la valeur attendue dans l’ensemble d’apprentissage, est calculée par le réseau ANN. Le réseau subit ensuite une rétropropagation, où l’influence d’un neurone donné sur un neurone de la couche suivante est calculée et son influence ajustée. Cette opération a pour but d’optimiser les performances du modèle. Ce processus est ensuite répété à l’infini. C’est ainsi que le réseau s’entraîne sur les données et apprend les associations entre les caractéristiques d’entrée et les classes de sortie.
Les neurones des couches intermédiaires entièrement connectées sortiront des valeurs binaires relatives aux classes possibles. Si vous avez quatre classes différentes (disons un chien, une voiture, une maison et une personne), le neurone aura une valeur « 1 » pour la classe qu’il pense que l’image représente et une valeur « 0 » pour les autres classes.
La couche finale entièrement connectée recevra la sortie de la couche qui la précède et délivrera une probabilité pour chacune des classes, dont la somme sera égale à un. S’il y a une valeur de 0,75 dans la catégorie » chien « , cela représente une certitude de 75 % que l’image est un chien.
Le classificateur d’images a maintenant été formé, et les images peuvent être passées dans le CNN, qui va maintenant sortir une supposition sur le contenu de cette image.
Le flux de travail d’apprentissage automatique
Avant de sauter dans un exemple de formation d’un classificateur d’images, prenons un moment pour comprendre le flux de travail ou pipeline d’apprentissage automatique. Le processus de formation d’un modèle de réseau neuronal est assez standard et peut être décomposé en quatre phases différentes.
Préparation des données
D’abord, vous devrez collecter vos données et les mettre sous une forme sur laquelle le réseau peut s’entraîner. Cela implique de collecter des images et de les étiqueter. Même si vous avez téléchargé un ensemble de données que quelqu’un d’autre a préparé, il y aura probablement un prétraitement ou une préparation à faire avant de pouvoir l’utiliser pour l’entraînement. La préparation des données est un art à part entière, qui implique de traiter des choses comme les valeurs manquantes, les données corrompues, les données dans le mauvais format, les étiquettes incorrectes, etc.
Dans cet article, nous utiliserons un ensemble de données prétraitées.
Création du modèle
La création du modèle de réseau neuronal implique de faire des choix sur divers paramètres et hyperparamètres. Vous devez prendre des décisions sur le nombre de couches à utiliser dans votre modèle, sur la taille des entrées et des sorties des couches, sur le type de fonctions d’activation que vous utiliserez, sur l’utilisation ou non du dropout, etc.
Apprendre quels paramètres et hyperparamètres utiliser viendra avec le temps (et beaucoup d’études), mais dès le départ, il y a quelques heuristiques que vous pouvez utiliser pour vous lancer et nous en couvrirons certaines pendant l’exemple d’implémentation.
Entraînement du modèle
Après avoir créé votre modèle, vous créez simplement une instance du modèle et l’ajustez avec vos données d’entraînement. La plus grande considération lors de la formation d’un modèle est la durée de formation du modèle. Vous pouvez spécifier la durée de l’entraînement d’un réseau en indiquant le nombre d’époques d’entraînement. Plus vous entraînez un modèle, plus ses performances s’amélioreront, mais trop d’époques d’entraînement et vous risquez de faire de l’overfitting.
Choisir le nombre d’époques pour s’entraîner est quelque chose pour lequel vous aurez un feeling, et il est habituel de sauvegarder les poids d’un réseau entre les sessions d’entraînement afin que vous n’ayez pas besoin de recommencer une fois que vous avez fait quelques progrès dans l’entraînement du réseau.
Évaluation du modèle
Il y a plusieurs étapes pour évaluer le modèle. La première étape de l’évaluation du modèle consiste à comparer les performances du modèle à un ensemble de données de validation, un ensemble de données sur lequel le modèle n’a pas été entraîné. Vous comparerez les performances du modèle à cet ensemble de validation et analyserez ses performances à l’aide de différentes métriques.
Il existe différentes métriques pour déterminer les performances d’un modèle de réseau neuronal, mais la métrique la plus courante est la « précision », la quantité d’images correctement classées divisée par le nombre total d’images de votre ensemble de données.
Après avoir constaté la précision des performances du modèle sur un ensemble de données de validation, vous allez généralement revenir en arrière et former à nouveau le réseau en utilisant des paramètres légèrement modifiés, car il est peu probable que vous soyez satisfait des performances de votre réseau dès la première formation. Vous continuerez à modifier les paramètres de votre réseau, à le former à nouveau et à mesurer ses performances jusqu’à ce que vous soyez satisfait de la précision du réseau.
Enfin, vous testerez les performances du réseau sur un ensemble de test. Cet ensemble de test est un autre ensemble de données que votre modèle n’a jamais vu auparavant.
Parfois, vous vous demandez :
Pourquoi s’embêter avec l’ensemble de test ? Si vous obtenez une idée de la précision de votre modèle, n’est-ce pas le but de l’ensemble de validation ?
C’est une bonne idée de garder un lot de données que le réseau n’a jamais vu pour les tests, car tous les réglages des paramètres que vous faites, combinés aux nouveaux tests sur l’ensemble de validation, pourraient signifier que votre réseau a appris certaines idiosyncrasies de l’ensemble de validation qui ne se généraliseront pas aux données hors échantillon.
Donc, le but de l’ensemble de test est de vérifier les problèmes tels que le surajustement et d’être plus confiant que votre modèle est vraiment adapté pour fonctionner dans le monde réel.
Reconnaissance d’images avec un CNN
Nous avons couvert beaucoup de choses jusqu’à présent, et si toutes ces informations ont été un peu écrasantes, voir ces concepts réunis dans un exemple de classificateur entraîné sur un ensemble de données devrait rendre ces concepts plus concrets. Examinons donc un exemple complet de reconnaissance d’images avec Keras, du chargement des données à l’évaluation.

Crédit : www.cs.toronto.edu
Pour commencer, nous aurons besoin d’un ensemble de données sur lequel nous entraîner. Dans cet exemple, nous allons utiliser le célèbre jeu de données CIFAR-10. CIFAR-10 est un grand jeu de données d’images contenant plus de 60 000 images représentant 10 classes différentes d’objets comme des chats, des avions et des voitures.
Les images sont en couleur RVB, mais elles sont assez petites, seulement 32 x 32. Une grande chose à propos du jeu de données CIFAR-10 est qu’il est livré préemballé avec Keras, il est donc très facile de charger le jeu de données et les images nécessitent très peu de prétraitement.
La première chose que nous devons faire est d’importer les bibliothèques nécessaires. Je montrerai comment ces importations sont utilisées au fur et à mesure, mais pour l’instant sachez que nous allons utiliser Numpy, et divers modules associés à Keras :
import numpyfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activationfrom keras.layers.convolutional import Conv2D, MaxPooling2Dfrom keras.constraints import maxnormfrom keras.utils import np_utilsNous allons utiliser ici une graine aléatoire afin que les résultats obtenus dans cet article puissent être reproduits par vous, c’est pourquoi nous avons besoin de numpy:
# Set random seed for purposes of reproducibilityseed = 21Préparation des données
Nous avons besoin d’une importation supplémentaire : le jeu de données.
from keras.datasets import cifar10Maintenant, chargeons l’ensemble de données. Nous pouvons le faire simplement en spécifiant les variables dans lesquelles nous voulons charger les données, puis en utilisant la fonction load_data():
# loading in the data (X_train, y_train), (X_test, y_test) = cifar10.load_data()Dans la plupart des cas, vous devrez faire un certain prétraitement de vos données pour qu’elles soient prêtes à être utilisées, mais puisque nous utilisons un jeu de données préemballé, très peu de prétraitement doit être fait. Une chose que nous voulons faire est de normaliser les données d’entrée.
Si les valeurs des données d’entrée sont dans une gamme trop large, cela peut avoir un impact négatif sur la façon dont le réseau fonctionne. Dans ce cas, les valeurs d’entrée sont les pixels de l’image, qui ont une valeur comprise entre 0 et 255.
Donc, afin de normaliser les données, nous pouvons simplement diviser les valeurs de l’image par 255. Pour ce faire, nous devons d’abord faire des données un type flottant, car elles sont actuellement des entiers. Nous pouvons le faire en utilisant la commande astype() Numpy et en déclarant ensuite quel type de données nous voulons :
# normalize the inputs from 0-255 to between 0 and 1 by dividing by 255 X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = X_train / 255.0X_test = X_test / 255.0Une autre chose que nous devrons faire pour que les données soient prêtes pour le réseau est de coder les valeurs en un coup. Je ne vais pas entrer dans les détails de l’encodage one-hot ici, mais pour l’instant sachez que les images ne peuvent pas être utilisées par le réseau telles qu’elles sont, elles doivent être encodées d’abord et l’encodage one-hot est mieux utilisé quand on fait une classification binaire.
Nous faisons effectivement une classification binaire ici parce qu’une image appartient à une classe ou pas, elle ne peut pas tomber quelque part entre les deux. La commande Numpy to_categorical() est utilisée pour coder à un coup. C’est pourquoi nous avons importé la fonction np_utils de Keras, car elle contient to_categorical().
Nous devons également spécifier le nombre de classes qui sont dans le jeu de données, afin de savoir à combien de neurones comprimer la couche finale :
# one hot encode outputsy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)class_num = y_test.shapeConception du modèle
Nous sommes arrivés à l’étape où nous concevons le modèle CNN. La première chose à faire est de définir le format que nous souhaitons utiliser pour le modèle, Keras dispose de plusieurs formats ou plans différents pour construire des modèles, mais Sequential est le plus couramment utilisé, et pour cette raison, nous l’avons importé de Keras.
Créer le modèle
model = Sequential()La première couche de notre modèle est une couche convolutive. Elle va prendre les entrées et exécuter des filtres convolutifs sur elles.
Lorsque nous les implémentons dans Keras, nous devons spécifier le nombre de canaux/filtres que nous voulons (c’est le 32 ci-dessous), la taille du filtre que nous voulons (3 x 3 dans ce cas), la forme de l’entrée (lors de la création de la première couche) et l’activation et le padding dont nous avons besoin.
Comme mentionné, relu est l’activation la plus commune, et padding='same' signifie simplement que nous ne changeons pas du tout la taille de l’image :
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape, padding='same'))model.add(Activation('relu'))Note : Vous pouvez également enchaîner les activations et les regroupements ensemble, comme ceci :
model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), activation='relu', padding='same'))Maintenant, nous allons faire une couche de décrochage pour empêcher l’overfitting, qui fonctionne en éliminant aléatoirement certaines des connexions entre les couches (0.2 signifie qu’elle élimine 20% des connexions existantes):
model.add(Dropout(0.2))Nous pouvons également vouloir faire une normalisation par lot ici. La normalisation par lot normalise les entrées se dirigeant vers la couche suivante, en s’assurant que le réseau crée toujours des activations avec la même distribution que nous désirons :
model.add(BatchNormalization())Vient maintenant une autre couche convolutive, mais la taille du filtre augmente afin que le réseau puisse apprendre des représentations plus complexes :
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))Voici la couche de mise en commun, comme discuté précédemment, cela aide à rendre le classificateur d’images plus robuste afin qu’il puisse apprendre des modèles pertinents. Il y a aussi le dropout et la normalisation des lots:
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization())C’est le flux de base pour la première moitié d’une implémentation CNN : Convolutionnel, activation, dropout, pooling. Vous pouvez maintenant voir pourquoi nous avons importé Dropout, BatchNormalization, Activation, Conv2d, et MaxPooling2d.
Vous pouvez varier le nombre exact de couches convolutives que vous avez à votre goût, bien que chacune d’entre elles ajoute plus de dépenses de calcul. Notez qu’à mesure que vous ajoutez des couches convolutives, vous augmentez généralement leur nombre de filtres afin que le modèle puisse apprendre des représentations plus complexes. Si les nombres choisis pour ces couches semblent quelque peu arbitraires, sachez simplement qu’en général, vous augmentez les filtres au fur et à mesure et qu’il est conseillé d’en faire des puissances de 2, ce qui peut accorder un léger avantage lors de l’entraînement sur un GPU.
Il est important de ne pas avoir trop de couches de pooling, car chaque pooling rejette certaines données. Une mise en commun trop fréquente conduira à ce qu’il n’y ait presque rien à apprendre pour les couches densément connectées lorsque les données les atteignent.
Le nombre exact de couches de mise en commun que vous devriez utiliser variera en fonction de la tâche que vous effectuez, et c’est quelque chose que vous obtiendrez une sensation au fil du temps. Puisque les images sont si petites ici déjà, nous ne mettrons pas en commun plus de deux fois.
Vous pouvez maintenant répéter ces couches pour donner à votre réseau plus de représentations à partir desquelles travailler :
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Après avoir terminé avec les couches de convolution, nous devons Flattenles données, ce qui explique pourquoi nous avons importé la fonction ci-dessus. Nous allons également ajouter une couche de décrochage à nouveau:
model.add(Flatten())model.add(Dropout(0.2))Maintenant, nous faisons usage de l’importation Dense et créons la première couche densément connectée. Nous devons spécifier le nombre de neurones dans la couche dense. Notez que le nombre de neurones dans les couches successives diminue, pour finalement se rapprocher du même nombre de neurones qu’il y a de classes dans l’ensemble de données (dans ce cas 10). La contrainte du noyau peut régulariser les données au fur et à mesure de l’apprentissage, une autre chose qui aide à prévenir l’overfitting. C’est pourquoi nous avons importé maxnorm plus tôt.
model.add(Dense(256, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Dense(128, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Dans cette couche finale, nous passons le nombre de classes pour le nombre de neurones. Chaque neurone représente une classe, et la sortie de cette couche sera un vecteur de 10 neurones, chaque neurone stockant une certaine probabilité que l’image en question appartienne à la classe qu’il représente.
Enfin, la fonction d’activation softmax sélectionne le neurone avec la probabilité la plus élevée comme sortie, votant que l’image appartient à cette classe:
model.add(Dense(class_num))model.add(Activation('softmax'))Maintenant que nous avons conçu le modèle que nous voulons utiliser, nous devons juste le compiler. Spécifions le nombre d’époques pour lesquelles nous voulons nous entraîner, ainsi que l’optimiseur que nous voulons utiliser.
L’optimiseur est ce qui va régler les poids de votre réseau pour approcher le point de perte la plus faible. L’algorithme Adam est l’un des optimiseurs les plus utilisés car il donne de grandes performances sur la plupart des problèmes :
epochs = 25optimizer = 'adam'Compilons maintenant le modèle avec les paramètres que nous avons choisis. Spécifions également une métrique à utiliser.
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=)Nous pouvons imprimer le résumé du modèle pour voir à quoi ressemble l’ensemble du modèle.
print(model.summary())L’impression du résumé nous donnera pas mal d’informations:
Results: Layer (type) Output Shape Param #=================================================================conv2d_1 (Conv2D) (None, 32, 32, 32) 896_________________________________________________________________activation_1 (Activation) (None, 32, 32, 32) 0_________________________________________________________________dropout_1 (Dropout) (None, 32, 32, 32) 0_________________________________________________________________batch_normalization_1 (Batch (None, 32, 32, 32) 128_________________________________________________________________conv2d_2 (Conv2D) (None, 32, 32, 64) 18496_________________________________________________________________activation_2 (Activation) (None, 32, 32, 64) 0_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0_________________________________________________________________dropout_2 (Dropout) (None, 16, 16, 64) 0_________________________________________________________________batch_normalization_2 (Batch (None, 16, 16, 64) 256_________________________________________________________________conv2d_3 (Conv2D) (None, 16, 16, 64) 36928_________________________________________________________________activation_3 (Activation) (None, 16, 16, 64) 0_________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0_________________________________________________________________dropout_3 (Dropout) (None, 8, 8, 64) 0_________________________________________________________________batch_normalization_3 (Batch (None, 8, 8, 64) 256_________________________________________________________________conv2d_4 (Conv2D) (None, 8, 8, 128) 73856_________________________________________________________________activation_4 (Activation) (None, 8, 8, 128) 0_________________________________________________________________dropout_4 (Dropout) (None, 8, 8, 128) 0_________________________________________________________________batch_normalization_4 (Batch (None, 8, 8, 128) 512_________________________________________________________________flatten_1 (Flatten) (None, 8192) 0_________________________________________________________________dropout_5 (Dropout) (None, 8192) 0_________________________________________________________________dense_1 (Dense) (None, 256) 2097408_________________________________________________________________activation_5 (Activation) (None, 256) 0_________________________________________________________________dropout_6 (Dropout) (None, 256) 0_________________________________________________________________batch_normalization_5 (Batch (None, 256) 1024_________________________________________________________________dense_2 (Dense) (None, 128) 32896_________________________________________________________________activation_6 (Activation) (None, 128) 0_________________________________________________________________dropout_7 (Dropout) (None, 128) 0_________________________________________________________________batch_normalization_6 (Batch (None, 128) 512_________________________________________________________________dense_3 (Dense) (None, 10) 1290_________________________________________________________________activation_7 (Activation) (None, 10) 0=================================================================Total params: 2,264,458Trainable params: 2,263,114Non-trainable params: 1,344Maintenant nous passons à l’entraînement du modèle. Pour cela, il suffit d’appeler la fonction fit() sur le modèle et de passer les paramètres choisis.
C’est ici que j’utilise la graine que j’ai choisie, à des fins de reproductibilité.
numpy.random.seed(seed)model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)Nous allons nous entraîner sur 50000 échantillons et valider sur 10000 échantillons.
L’exécution de ce morceau de code donnera :
Epoch 1/2564/50000 - ETA: 16:57 - loss: 3.1479 - acc: 0.0938128/50000 - ETA: 10:12 - loss: 3.0212 - acc: 0.0938192/50000 - ETA: 7:57 - loss: 2.9781 - acc: 0.1250256/50000 - ETA: 6:48 - loss: 2.8830 - acc: 0.1484320/50000 - ETA: 6:07 - loss: 2.8878 - acc: 0.1469384/50000 - ETA: 5:40 - loss: 2.8732 - acc: 0.1458448/50000 - ETA: 5:20 - loss: 2.8842 - acc: 0.1406.........49664/50000 - ETA: 1s - loss: 1.5160 - acc: 0.461149728/50000 - ETA: 1s - loss: 1.5157 - acc: 0.461249792/50000 - ETA: 1s - loss: 1.5153 - acc: 0.461449856/50000 - ETA: 0s - loss: 1.5147 - acc: 0.461549920/50000 - ETA: 0s - loss: 1.5144 - acc: 0.461749984/50000 - ETA: 0s - loss: 1.5141 - acc: 0.461750000/50000 - 262s 5ms/step - loss: 1.5140 - acc: 0.4618 - val_loss: 1.0715 - val_acc: 0.6195End of Epoch 1Notez que dans la plupart des cas, vous voudriez avoir un ensemble de validation qui est différent de l’ensemble de test, et donc vous spécifieriez un pourcentage des données de formation à utiliser comme ensemble de validation. Dans ce cas, nous allons simplement passer dans les données de test pour nous assurer que les données de test sont mises de côté et ne sont pas formées. Nous n’aurons que des données de test dans cet exemple, afin de garder les choses simples.
Maintenant, nous pouvons évaluer le modèle et voir comment il s’est comporté. Il suffit d’appeler model.evaluate():
# Model evaluationscores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%" % (scores*100))Et nous sommes accueillis avec le résultat:
Accuracy: 83.01%Et c’est tout ! Nous avons maintenant un CNN de reconnaissance d’image entraîné. Pas mal pour la première exécution, mais vous voudriez probablement jouer avec la structure et les paramètres du modèle pour voir si vous ne pouvez pas obtenir de meilleures performances.
Conclusion
Maintenant que vous avez implémenté votre premier réseau de reconnaissance d’image dans Keras, ce serait une bonne idée de jouer avec le modèle et de voir comment la modification de ses paramètres affecte ses performances.
Cela vous donnera une certaine intuition sur les meilleurs choix pour les différents paramètres du modèle. Vous devriez également lire sur les différents choix de paramètres et d’hyperparamètres pendant que vous le faites. Une fois que vous êtes à l’aise avec ceux-ci, vous pouvez essayer de mettre en œuvre votre propre classificateur d’images sur un ensemble de données différent.
Si vous souhaitez jouer avec le code ou simplement l’étudier un peu plus en profondeur, le projet est téléchargé sur GitHub !
.