 Arwin Lashawn le 04 décembre 2020
Arwin Lashawn le 04 décembre 2020 
- Background
- Comment la mémoire est-elle gérée en Python ?
- Allocation de mémoire Python
- Allocation de mémoire statique vs dynamique
- Mémoire de pile
- Mémoire de tas
- Arenas
- Pools
- Blocs
- Collecte de déchets Python
- Surveiller les problèmes de mémoire de Python
- Outils de surveillance des performances des applications (APM)
- Modules de profilage
- tracemalloc
- memory_profiler
- Bonnes pratiques pour améliorer les performances du code Python
- Prendre avantage des bibliothèques Python et des fonctions intégrées
- Ne pas utiliser « + » pour la concaténation de chaînes de caractères
- Utiliser itertools pour un bouclage efficace
- Récapitulation et pensées de clôture
Background
Python n’est pas connu pour être un langage de programmation » rapide « . Pourtant, selon les résultats de l’enquête Stack Overflow Developer Survey de 2020, Python est le 2e langage de programmation le plus populaire derrière JavaScript (comme vous l’avez peut-être deviné). Cela est dû en grande partie à sa syntaxe super conviviale et à son applicabilité à presque tous les usages. Bien que Python ne soit pas le langage le plus rapide du marché, sa grande lisibilité associée à un soutien communautaire inégalé et à la disponibilité des bibliothèques l’a rendu extrêmement attrayant pour faire des choses avec du code.
La gestion de la mémoire de Python joue également un rôle dans sa popularité. Comment ? La gestion de la mémoire de Python est implémentée d’une manière qui nous facilite la vie. Avez-vous déjà entendu parler du gestionnaire de mémoire de Python ? Il s’agit du gestionnaire qui contrôle la mémoire de Python, ce qui vous permet de vous concentrer sur votre code sans avoir à vous soucier de la gestion de la mémoire. En raison de sa simplicité, cependant, Python ne vous offre pas beaucoup de liberté dans la gestion de l’utilisation de la mémoire, contrairement à des langages comme C++ où vous pouvez allouer et libérer manuellement de la mémoire.
Cependant, avoir une bonne compréhension de la gestion de la mémoire de Python est un excellent début qui vous permettra d’écrire un code plus efficace. En fin de compte, vous pouvez l’appliquer comme une habitude qui peut potentiellement être adoptée dans d’autres langages de programmation que vous connaissez.
Alors, qu’est-ce que nous obtenons en écrivant du code efficace en mémoire ?
- Il conduit à un traitement plus rapide et à un moindre besoin de ressources, à savoir l’utilisation de la mémoire vive (RAM). Plus de RAM disponible signifierait généralement plus de place pour le cache, ce qui contribuera à accélérer l’accès au disque. L’avantage d’écrire du code efficace en termes de mémoire est que cela ne nécessite pas nécessairement d’écrire plus de lignes de code.
- Un autre avantage est qu’il empêche la fuite de mémoire, un problème qui fait que l’utilisation de la RAM augmente continuellement même lorsque les processus sont tués, ce qui conduit finalement à un ralentissement ou une altération des performances du périphérique. Cela est causé par l’incapacité à libérer la mémoire utilisée après la fin des processus.
Dans le monde de la technologie, vous avez peut-être entendu dire que « fait est mieux que parfait ». Cependant, disons que vous avez deux développeurs qui ont utilisé Python pour développer la même application et qu’ils l’ont terminée dans le même laps de temps. L’un d’eux a écrit un code plus efficace en termes de mémoire, ce qui se traduit par une application plus rapide. Préféreriez-vous choisir l’application qui fonctionne bien ou celle qui est nettement plus lente ? C’est un bon exemple où deux individus passeraient le même temps à coder et auraient pourtant des performances de code sensiblement différentes.
Voici ce que vous apprendrez dans ce guide :
- Comment la mémoire est-elle gérée en Python ?
- Collecte d’ordures de Python
- Surveiller le problème de mémoire de Python
- Bonnes pratiques pour améliorer les performances du code Python
Comment la mémoire est-elle gérée en Python ?
Selon la documentation de Python (3.9.0) pour la gestion de la mémoire, la gestion de la mémoire de Python implique un tas privé qui est utilisé pour stocker les objets et les structures de données de votre programme. De plus, n’oubliez pas que c’est le gestionnaire de mémoire de Python qui s’occupe de la plupart du sale boulot lié à la gestion de la mémoire afin que vous puissiez vous concentrer sur votre code.
Allocation de mémoire Python
Tout en Python est un objet. Pour que ces objets soient utiles, ils doivent être stockés en mémoire pour être accessibles. Avant qu’ils puissent être stockés en mémoire, un morceau de mémoire doit d’abord être alloué ou assigné pour chacun d’eux.
Au niveau le plus bas, l’allocateur de mémoire brute de Python s’assurera d’abord qu’il y a de l’espace disponible dans le tas privé pour stocker ces objets. Pour ce faire, il interagit avec le gestionnaire de mémoire de votre système d’exploitation. Voyez cela comme votre programme Python demandant à votre système d’exploitation un morceau de mémoire pour travailler.
Au niveau suivant, plusieurs allocateurs spécifiques aux objets fonctionnent sur le même tas et mettent en œuvre des politiques de gestion distinctes en fonction du type d’objet. Comme vous le savez peut-être déjà, certains exemples de types d’objets sont les chaînes de caractères et les entiers. Bien que les chaînes de caractères et les nombres entiers ne soient pas si différents si l’on considère le temps que nous mettons à les reconnaître et à les mémoriser, ils sont traités très différemment par les ordinateurs. C’est parce que les ordinateurs ont besoin de différentes exigences de stockage et de compromis de vitesse pour les entiers par rapport aux chaînes de caractères.
Une dernière chose que vous devriez savoir sur la façon dont le tas de Python est géré est que vous avez zéro contrôle sur lui. Maintenant, vous vous demandez peut-être, comment écrire ensuite un code efficace en termes de mémoire si nous avons si peu de contrôle sur la gestion de la mémoire de Python ? Avant d’aborder ce sujet, nous devons comprendre davantage certains termes importants concernant la gestion de la mémoire.
Allocation de mémoire statique vs dynamique
Maintenant que vous comprenez ce qu’est l’allocation de mémoire, il est temps de vous familiariser avec les deux types d’allocation de mémoire, à savoir statique et dynamique, et de faire la distinction entre les deux.
Allocation de mémoire statique :
- Comme le suggère le mot « statique », les variables allouées statiquement sont permanentes, ce qui signifie qu’elles doivent être allouées au préalable et durent aussi longtemps que le programme s’exécute.
- La mémoire est allouée pendant la compilation, ou avant l’exécution du programme.
- Mise en œuvre en utilisant la structure de données de la pile, ce qui signifie que les variables sont stockées dans la mémoire de la pile.
- La mémoire qui a été allouée ne peut pas être réutilisée, donc pas de réutilisabilité de la mémoire.
Allocation dynamique de la mémoire :
- Comme le suggère le mot « dynamique », les variables allouées dynamiquement ne sont pas permanentes et peuvent être allouées pendant l’exécution d’un programme.
- La mémoire est allouée au moment de l’exécution ou pendant l’exécution du programme.
- Mise en œuvre en utilisant la structure de données du tas, ce qui signifie que les variables sont stockées dans la mémoire du tas.
- La mémoire qui a été allouée peut être libérée et réutilisée.
Un avantage de l’allocation dynamique de la mémoire dans Python est que nous n’avons pas besoin de nous soucier de la quantité de mémoire dont nous avons besoin pour notre programme à l’avance. Un autre avantage est que la manipulation de la structure de données peut être faite librement sans avoir à se soucier d’un besoin d’allocation de mémoire plus élevé si la structure de données s’étend.
Cependant, puisque l’allocation de mémoire dynamique est faite pendant l’exécution du programme, elle consommera plus de temps pour son achèvement. De plus, la mémoire qui a été allouée doit être libérée après avoir été utilisée. Sinon, des problèmes tels que des fuites de mémoire peuvent potentiellement se produire.
Nous avons rencontré deux types de structures de mémoire ci-dessus – la mémoire de tas et la mémoire de pile. Regardons-les plus en profondeur.
Mémoire de pile
Toutes les méthodes et leurs variables sont stockées dans la mémoire de pile. Vous vous souvenez que la mémoire de pile est allouée lors de la compilation ? Cela signifie effectivement que l’accès à ce type de mémoire est très rapide.
Lorsqu’une méthode est appelée en Python, un cadre de pile est alloué. Ce cadre de pile va gérer toutes les variables de la méthode. Après le retour de la méthode, le cadre de pile est automatiquement détruit.
Notez que le cadre de pile est également responsable de la définition de la portée des variables d’une méthode.
Mémoire de tas
Tous les objets et les variables d’instance sont stockés dans la mémoire de tas. Lorsqu’une variable est créée en Python, elle est stockée dans un heap privé qui permettra ensuite l’allocation et la désallocation.
La mémoire heap permet à ces variables d’être accédées globalement par toutes les méthodes de votre programme. Après le retour de la variable, le ramasseur de déchets Python se met au travail, dont nous couvrirons les rouages plus tard.
Maintenant, jetons un coup d’œil à la structure de la mémoire de Python.
Python a trois niveaux différents quand il s’agit de sa structure de mémoire :
- Arenas
- Pools
- Blocks
Nous commencerons par le plus grand de tous – les arènes.
Arenas
Imaginez un bureau avec 64 livres couvrant toute sa surface. Le haut du bureau représente une arène qui a une taille fixe de 256KiB qui est allouée dans le tas (Notez que KiB est différent de KB, mais vous pouvez supposer qu’ils sont les mêmes pour cette explication). Une arène représente le plus grand morceau de mémoire possible.
Plus spécifiquement, les arènes sont des mappages de mémoire qui sont utilisés par l’allocateur Python, pymalloc, qui est optimisé pour les petits objets (inférieur ou égal à 512 octets). Les arènes sont responsables de l’allocation de la mémoire, et donc les structures suivantes n’ont plus à le faire.
Cette arène peut ensuite être décomposée en 64 pools, qui est la prochaine plus grande structure de mémoire.
Pools
Pour revenir à l’exemple du bureau, les livres représentent tous les pools au sein d’une arène.
Chaque pool aurait typiquement une taille fixe de 4Kb et peut avoir trois états possibles :
- Vide : Le pool est vide et donc disponible pour l’allocation.
- Utilisé : Le pool contient des objets qui font qu’il n’est ni vide ni plein.
- Plein : Le pool est plein et donc non disponible pour une nouvelle allocation.
Notez que la taille du pool doit correspondre à la taille de page mémoire par défaut de votre système d’exploitation.
Un pool est ensuite décomposé en de nombreux blocs, qui sont les plus petites structures de mémoire.
Blocs
Retournant à l’exemple du bureau, les pages de chaque livre représentent tous les blocs d’un pool.
Contrairement aux arènes et aux pools, la taille d’un bloc n’est pas fixe. La taille d’un bloc va de 8 à 512 octets et doit être un multiple de huit.
Chaque bloc ne peut stocker qu’un objet Python d’une certaine taille et a trois états possibles :
- Non touché : N’a pas été alloué
- Libre : A été alloué mais a été libéré et rendu disponible pour l’allocation
- Alloué : A été alloué
Notez que les trois différents niveaux d’une structure mémoire (arènes, pools et blocs) dont nous avons parlé ci-dessus sont spécifiquement destinés aux petits objets Python. Les gros objets sont dirigés vers l’allocateur standard C au sein de Python, ce qui serait une bonne lecture pour un autre jour.
Collecte de déchets Python
La collecte de déchets est un processus effectué par un programme pour libérer la mémoire précédemment allouée pour un objet qui n’est plus utilisé. Vous pouvez considérer l’allocation d’ordures comme le recyclage ou la réutilisation de la mémoire.
Auparavant, les programmeurs devaient allouer et désallouer manuellement la mémoire. Oublier de désallouer la mémoire conduisait à une fuite de mémoire, entraînant une baisse des performances d’exécution. Pire encore, l’allocation et la désallocation manuelles de la mémoire sont même susceptibles d’entraîner un écrasement accidentel de la mémoire, ce qui peut provoquer le plantage pur et simple du programme.
Dans Python, le garbage collection se fait automatiquement et vous évite donc bien des maux de tête pour gérer manuellement l’allocation et la désallocation de la mémoire. Plus précisément, Python utilise le comptage de références combiné au garbage collection générationnel pour libérer la mémoire inutilisée. La raison pour laquelle le comptage de références seul ne suffit pas pour Python car il ne nettoie pas efficacement les références cycliques pendantes.
Un cycle de garbage collection générationnel contient les étapes suivantes –
- Python initialise une « discard list » pour les objets non utilisés.
- Un algorithme est exécuté pour détecter les cycles de référence.
- Si un objet manque de références extérieures, il est inséré dans la liste de mise au rebut.
- Libère l’allocation de mémoire pour les objets de la liste de rejet.
Pour en savoir plus sur le garbage collection en Python, vous pouvez consulter notre Python Garbage Collection : A Guide for Developers post.
Surveiller les problèmes de mémoire de Python
Bien que tout le monde aime Python, il ne recule pas devant les problèmes de mémoire. Il y a plusieurs raisons possibles.
Selon la documentation de Python (3.9.0) pour la gestion de la mémoire, le gestionnaire de mémoire de Python ne libère pas nécessairement la mémoire en retour à votre système d’exploitation. Il est indiqué dans la documentation que « dans certaines circonstances, le gestionnaire de mémoire Python peut ne pas déclencher les actions appropriées, comme la collecte des déchets, le compactage de la mémoire ou d’autres mesures préventives. »
En conséquence, on peut avoir à libérer explicitement la mémoire dans Python. Une façon de le faire est de forcer le garbage collector de Python à libérer la mémoire inutilisée en faisant usage du module gc. Pour ce faire, il suffit d’exécuter gc.collect(). Cependant, cela n’offre des avantages notables que lors de la manipulation d’un très grand nombre d’objets.
En dehors de la nature parfois erronée du ramasseur d’ordures Python, en particulier lors du traitement de grands ensembles de données, plusieurs bibliothèques Python sont également connues pour provoquer des fuites de mémoire. Pandas, par exemple, est l’un de ces outils. Pensez à jeter un coup d’œil à tous les problèmes liés à la mémoire dans le dépôt GitHub officiel de Pandas !
Une raison évidente qui peut échapper même aux yeux aiguisés des réviseurs de code est qu’il y a de gros objets persistants dans le code qui ne sont pas libérés. Sur la même note, la croissance infinie des structures de données est une autre cause de préoccupation. Par exemple, une structure de données de dictionnaire croissant sans limite de taille fixe.
Une façon de résoudre la structure de données croissante est de convertir le dictionnaire en une liste si possible et de fixer une taille maximale pour la liste. Sinon, il suffit de fixer une limite pour la taille du dictionnaire et de l’effacer chaque fois que la limite est atteinte.
Maintenant, vous vous demandez peut-être, comment puis-je même détecter les problèmes de mémoire en premier lieu ? Une option consiste à tirer parti d’un outil de surveillance des performances des applications (APM). En outre, de nombreux modules Python utiles peuvent vous aider à suivre et à tracer les problèmes de mémoire. Examinons nos options, en commençant par les outils APM.
Outils de surveillance des performances des applications (APM)
Alors, qu’est-ce que la surveillance des performances des applications exactement et comment aide-t-elle à traquer les problèmes de mémoire ? Un outil APM vous permet d’observer les mesures de performance en temps réel d’un programme, ce qui permet une optimisation continue à mesure que vous découvrez les problèmes qui limitent les performances.
Sur la base des rapports générés par les outils APM, vous serez en mesure d’avoir une idée générale de la façon dont votre programme fonctionne. Comme vous pouvez recevoir et surveiller les mesures de performance en temps réel, vous pouvez prendre des mesures immédiates sur les problèmes observés. Une fois que vous avez réduit les zones possibles de votre programme qui peuvent être les coupables des problèmes de mémoire, vous pouvez alors plonger dans le code et en discuter avec les autres contributeurs de code pour déterminer plus précisément les lignes de code spécifiques qui doivent être corrigées.
Tracer la racine des problèmes de fuite de mémoire elle-même peut être une tâche intimidante. La corriger est un autre cauchemar car vous devez vraiment comprendre votre code. Si vous vous trouvez un jour dans cette position, ne cherchez plus car ScoutAPM est un outil APM compétent qui peut analyser et optimiser de manière constructive les performances de votre application. ScoutAPM vous donne un aperçu en temps réel afin que vous puissiez rapidement repérer &résoudre les problèmes avant que vos clients puissent les repérer.
Modules de profilage
Il existe de nombreux modules Python pratiques que vous pouvez utiliser pour résoudre les problèmes de mémoire, qu’il s’agisse d’une fuite de mémoire ou du plantage de votre programme en raison d’une utilisation excessive de la mémoire. Deux des modules recommandés sont :
- tracemalloc
- memory-profiler
Notez que seul le module tracemalloc est intégré, donc assurez-vous d’installer d’abord l’autre module si vous souhaitez l’utiliser.
tracemalloc
Selon la documentation Python (3.9.0) pour tracemalloc, l’utilisation de ce module peut vous fournir les informations suivantes :
- Traceback où un objet a été alloué.
- Statistiques sur les blocs de mémoire alloués par nom de fichier et par numéro de ligne : taille totale, nombre et taille moyenne des blocs de mémoire alloués.
- Compter la différence entre deux instantanés pour détecter les fuites de mémoire.
Une première étape recommandée que vous devriez faire pour déterminer la source du problème de mémoire est d’abord d’afficher les fichiers allouant le plus de mémoire. Vous pouvez facilement le faire en utilisant le premier exemple de code présenté dans la documentation.
Cela ne signifie cependant pas que les fichiers qui allouent une petite quantité de mémoire ne vont pas croître indéfiniment pour causer des fuites de mémoire dans le futur.
memory_profiler
Ce module est un module amusant. J’ai travaillé avec et c’est un favori personnel parce qu’il offre la possibilité d’ajouter simplement le décorateur @profile à n’importe quelle fonction que vous souhaitez étudier. La sortie donnée comme résultat est également très facile à comprendre.
Une autre raison qui en fait mon favori personnel est que ce module vous permet de tracer un graphique de l’utilisation de la mémoire en fonction du temps. Parfois, vous avez simplement besoin d’une vérification rapide pour voir si l’utilisation de la mémoire continue à augmenter indéfiniment ou non. C’est la solution parfaite pour cela car vous n’avez pas besoin de faire un profilage de la mémoire ligne par ligne pour le confirmer. Vous pouvez simplement observer le graphique tracé après avoir laissé le profileur fonctionner pendant une certaine durée. Voici un exemple du graphique qui est sorti –
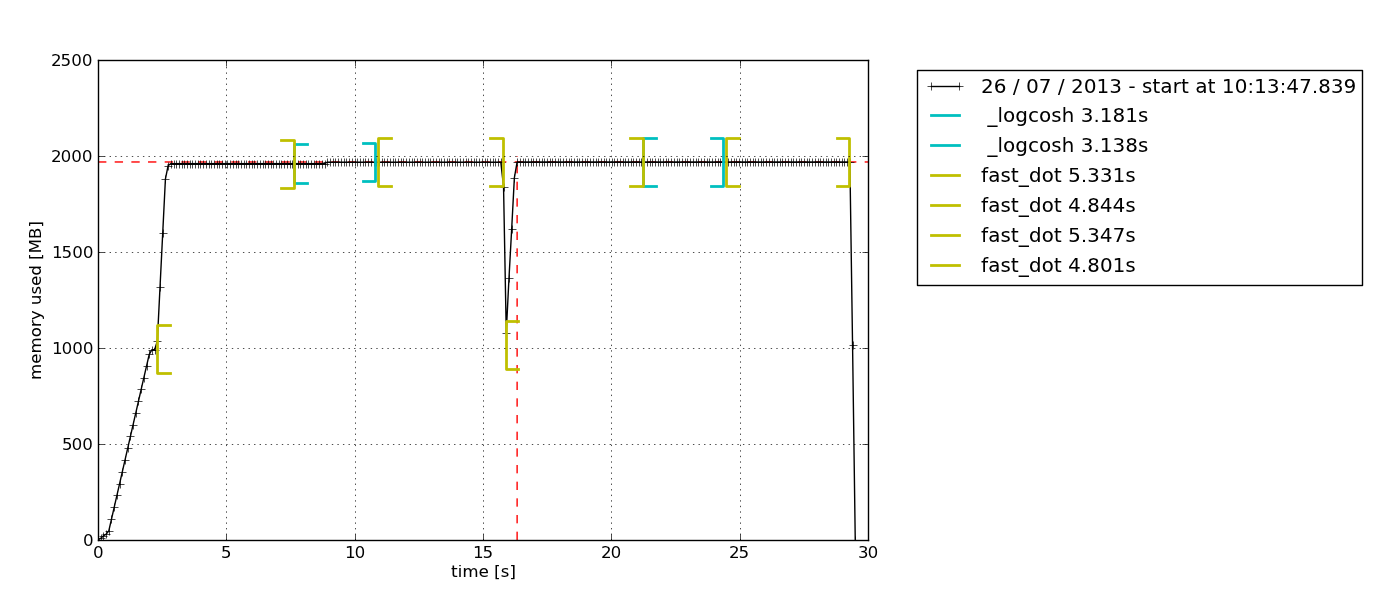
Selon la description dans la documentation de memory-profiler, ce module Python permet de surveiller la consommation de mémoire d’un processus ainsi qu’une analyse ligne par ligne de celle-ci pour les programmes Python. C’est un module Python pur qui dépend de la bibliothèque psutil.
Je vous recommande de lire ce blogue Medium pour explorer davantage la façon dont memory-profiler est utilisé. Vous y apprendrez également comment utiliser un autre module Python, muppy (le dernier en date est muppy3).
Bonnes pratiques pour améliorer les performances du code Python
Assez de tous ces détails sur la gestion de la mémoire. Maintenant, explorons certaines des bonnes habitudes pour écrire du code Python efficace en mémoire.
Prendre avantage des bibliothèques Python et des fonctions intégrées
Oui, c’est une bonne habitude qui peut assez souvent être négligée. Python a un soutien communautaire inégalé et cela se reflète dans l’abondance des bibliothèques Python disponibles pour à peu près n’importe quel objectif, allant des appels d’API à la science des données.
S’il existe une bibliothèque Python qui vous permet de faire la même chose que ce que vous avez déjà mis en œuvre, ce que vous pouvez faire est de comparer les performances de votre code lorsque vous utilisez la bibliothèque par rapport à l’utilisation de votre code personnalisé. Il y a de fortes chances que les bibliothèques Python (surtout les plus populaires) soient plus efficaces en termes de mémoire que votre code, car elles sont constamment améliorées en fonction des commentaires de la communauté. Préférez-vous vous fier à un code qui a été conçu du jour au lendemain ou à un code qui a été rigoureusement amélioré pendant une période prolongée ?
Le plus important, c’est que les bibliothèques Python vous permettront d’économiser de nombreuses lignes de code, alors pourquoi pas ?
Ne pas utiliser « + » pour la concaténation de chaînes de caractères
À un moment donné, nous avons tous été coupables de concaténer des chaînes de caractères en utilisant l’opérateur « + » parce que cela semble si facile.
Notez que les chaînes de caractères sont immuables. Par conséquent, chaque fois que vous ajoutez un élément à une chaîne avec l’opérateur « + », Python doit créer une nouvelle chaîne avec une nouvelle allocation de mémoire. Avec des chaînes plus longues, l’inefficacité mémoire du code deviendra plus prononcée.
Utiliser itertools pour un bouclage efficace
Le bouclage est une partie essentielle de l’automatisation des choses. Comme nous continuons à utiliser les boucles de plus en plus, nous nous retrouverons éventuellement à devoir utiliser des boucles imbriquées, qui sont connues pour être inefficaces en raison de leur complexité d’exécution élevée.
C’est là que le module itertools vient à la rescousse. Selon la documentation itertools de Python, « Le module standardise un ensemble de base d’outils rapides et efficaces en mémoire qui sont utiles seuls ou en combinaison. Ensemble, ils permettent de construire des outils spécialisés de manière succincte et efficace en Python pur. »
En d’autres termes, le module itertools permet un bouclage efficace en mémoire en se débarrassant des boucles inutiles. De manière intéressante, le module itertools est appelé un joyau car il permet de composer des solutions élégantes pour une myriade de problèmes.
Je suis à peu près sûr que vous allez travailler avec au moins une boucle dans votre prochain morceau de code, alors essayez d’implémenter itertools !
Récapitulation et pensées de clôture
Appliquer de bonnes habitudes de gestion de la mémoire en Python n’est pas pour le programmeur occasionnel. Si vous vous en sortez habituellement avec des scripts simples, vous ne devriez pas du tout rencontrer de problèmes liés à la mémoire. Grâce au matériel et aux logiciels qui continuent de progresser rapidement à l’heure où vous lisez ces lignes, le modèle de base d’à peu près n’importe quel appareil, quelle que soit sa marque, devrait pouvoir exécuter les programmes courants sans problème. La nécessité d’un code efficace en termes de mémoire ne commence à se manifester que lorsque vous commencez à travailler sur une base de code importante, en particulier pour la production, où les performances sont essentielles.
Cependant, cela ne suggère pas que la gestion de la mémoire en Python est un concept difficile à appréhender, et cela ne signifie pas non plus qu’elle n’est pas importante. En effet, l’importance accordée aux performances des applications augmente chaque jour. Un jour, il ne s’agira plus d’une simple question de « fait ». Au lieu de cela, les développeurs seront en concurrence pour fournir une solution qui est non seulement capable de résoudre avec succès les besoins des clients, mais aussi de le faire avec une vitesse fulgurante et des ressources minimales.