 Arwin Lashawn on December 04, 2020
Arwin Lashawn on December 04, 2020 
- Tausta
- Miten muistia hallitaan Pythonissa?
- Pythonin muistinjako
- Staattinen vs. dynaaminen muistinvaraus
- Pinomuisti
- Heap-muisti
- Arenat
- Poolit
- Lohkot
- Pythonin roskienkeruu
- Monitoring Python Memory Issues
- Application Performance Monitoring (APM) Tools
- Profiilimoduulit
- tracemalloc
- memory_profiler
- Parhaat käytännöt Python-koodin suorituskyvyn parantamiseen
- Hyödynnä Python-kirjastoja ja sisäänrakennettuja funktioita
- Ei ”+”-operaattorin käyttäminen merkkijonojen ketjuttamiseen
- Itertoolsin käyttäminen tehokkaaseen silmukointiin
- Yhteenveto ja loppuajatuksia
Tausta
Python ei ole tunnetusti ”nopea” ohjelmointikieli. Stack Overflow Developer Survey 2020 -tutkimuksen tulosten mukaan Python on kuitenkin toiseksi suosituin ohjelmointikieli JavaScriptin jälkeen (kuten ehkä arvasitkin). Tämä johtuu pitkälti sen erittäin ystävällisestä syntaksista ja sovellettavuudesta lähes mihin tahansa tarkoitukseen. Vaikka Python ei olekaan kaikkein nopein kieli, sen loistava luettavuus yhdistettynä yhteisön vertaansa vailla olevaan tukeen ja kirjastojen saatavuuteen on tehnyt siitä erittäin houkuttelevan kielen, kun haluaa tehdä asioita koodilla.
Pythonin muistinhallinnalla on myös merkitystä sen suosioon. Miten niin? Pythonin muistinhallinta on toteutettu tavalla, joka helpottaa elämäämme. Oletko koskaan kuullut Pythonin muistinhallinnasta? Se on manageri, joka pitää Pythonin muistin hallinnassa, jolloin voit keskittyä koodiisi sen sijaan, että tarvitsisit huolehtia muistinhallinnasta. Yksinkertaisuutensa vuoksi Python ei kuitenkaan anna sinulle paljon vapauksia muistin käytön hallinnassa, toisin kuin C++:n kaltaisissa kielissä, joissa voit manuaalisesti varata ja vapauttaa muistia.
Pythonin muistinhallinnan hyvä ymmärtäminen on kuitenkin hyvä alku, jonka avulla voit kirjoittaa tehokkaampaa koodia. Viime kädessä voit vakiinnuttaa sen tavaksi, jonka voit mahdollisesti ottaa käyttöön muissa osaamissasi ohjelmointikielissä.
Mitä siis saamme aikaan kirjoittamalla muistitehokasta koodia?
- Se johtaa nopeampaan prosessointiin ja vähäisempään resurssien tarpeeseen, nimittäin satunnaiskäyttömuistin (RAM) käyttöön. Enemmän käytettävissä olevaa RAM-muistia tarkoittaisi yleensä enemmän tilaa välimuistille, mikä nopeuttaa levykäyttöä. Hienoa muistitehokkaan koodin kirjoittamisessa on se, että se ei välttämättä edellytä useampien koodirivien kirjoittamista.
- Toinen hyöty on se, että se estää muistivuodon, ongelman, joka aiheuttaa RAM-muistin käytön jatkuvan lisääntymisen, vaikka prosessit lopetettaisiinkin, mikä johtaa lopulta laitteen suorituskyvyn hidastumiseen tai heikkenemiseen. Tämä johtuu siitä, että käytettyä muistia ei vapauteta prosessien lopettamisen jälkeen.
Tekniikan maailmassa olet ehkä kuullut, että ”tehty on parempi kuin täydellinen”. Oletetaan kuitenkin, että sinulla on kaksi kehittäjää, jotka ovat käyttäneet Pythonia saman sovelluksen kehittämiseen ja he ovat saaneet sen valmiiksi samassa ajassa. Toinen heistä on kirjoittanut muistitehokkaamman koodin, jonka tuloksena sovellus toimii nopeammin. Valitsisitko mieluummin sen sovelluksen, joka toimii sujuvasti, vai sen, joka toimii selvästi hitaammin? Tämä on yksi hyvä esimerkki, jossa kaksi henkilöä käyttäisi saman verran aikaa koodaamiseen ja silti koodin suorituskyky olisi huomattavan erilainen.
Tässä oppaassa opit seuraavaa:
- Miten muistia hallitaan Pythonissa?
- Pythonin roskienkeruu
- Pythonin muistiongelmien valvonta
- Pythonin koodin suorituskyvyn parantamisen parhaat käytännöt
Miten muistia hallitaan Pythonissa?
Pythonin muistinhallinnan dokumentaation (3.9.0) mukaan Pythonin muistinhallinta käsittää yksityisen kasan, johon tallennetaan ohjelmasi objekteja ja tietorakenteita. Muista myös, että juuri Pythonin muistinhallinta hoitaa suurimman osan muistinhallintaan liittyvistä likaisista töistä, jotta voit vain keskittyä koodiisi.
Pythonin muistinjako
Kaikki Pythonissa on objekti. Jotta näistä objekteista olisi hyötyä, ne on tallennettava muistiin, jotta niitä voidaan käyttää. Ennen kuin ne voidaan tallentaa muistiin, jokaiselle niistä on ensin varattava tai osoitettava palanen muistia.
Alhaisimmalla tasolla Pythonin raakamuistin allokaattori varmistaa ensin, että yksityisessä kasassa on tilaa näiden objektien tallentamiseen. Se tekee tämän toimimalla vuorovaikutuksessa käyttöjärjestelmän muistinhallinnan kanssa. Ajattele sitä niin, että Python-ohjelmasi pyytää käyttöjärjestelmältäsi palan muistia käytettäväksi.
Seuraavalla tasolla useat objektikohtaiset allokaattorit toimivat samassa kasassa ja toteuttavat erilaisia hallintakäytäntöjä objektityypistä riippuen. Kuten ehkä jo tiedät, esimerkkejä objektityypeistä ovat merkkijonot ja kokonaisluvut. Vaikka merkkijonot ja kokonaisluvut eivät ehkä eroa toisistaan kovinkaan paljon ottaen huomioon, kuinka paljon aikaa niiden tunnistamiseen ja muistamiseen kuluu, tietokoneet käsittelevät niitä hyvin eri tavalla. Tämä johtuu siitä, että tietokoneet tarvitsevat erilaiset varastointivaatimukset ja nopeuskompromissit kokonaisluvuille verrattuna merkkijonoihin.
Yksi viimeinen asia, joka sinun on hyvä tietää siitä, miten Pythonin kasaa hallitaan, on se, että sinulla ei ole siihen mitään vaikutusvaltaa. Nyt saatat ihmetellä, miten me sitten kirjoitamme muistitehokasta koodia, jos meillä on niin vähän kontrollia Pythonin muistinhallintaan? Ennen kuin menemme siihen, meidän on ymmärrettävä tarkemmin joitakin tärkeitä muistinhallintaan liittyviä termejä.
Staattinen vs. dynaaminen muistinvaraus
Nyt kun ymmärrät, mitä muistinvaraus on, on aika tutustua kahteen muistinvarausmuotoon, staattiseen ja dynaamiseen muistinvarausmuotoon, ja tehdä ero näiden kahden välillä.
Staattinen muistinvaraus:
- Niin kuin sana ”staattinen” antaa ymmärtää, staattisesti allokoidut muuttujat ovat pysyviä, eli ne on varattava etukäteen ja ne kestävät niin kauan kuin ohjelma suoritetaan.
- Muisti varataan kääntämisaikana eli ennen ohjelman suorittamista.
- Toteutetaan pino-tietorakenteen avulla, mikä tarkoittaa sitä, että muuttujat tallennetaan pinon muistiin.
- Varattua muistia ei voi käyttää uudelleen, joten muistin uudelleenkäytettävyyttä ei ole.
Dynaaminen muistinvaraus:
- Niin kuin sana ”dynaaminen” antaa ymmärtää, dynaamisesti varatut muuttujat eivät ole pysyviä, vaan niitä voidaan varata ohjelman suorituksen aikana.
- Muistia varataan ohjelman suoritusajankohtana tai ohjelman suorituksen aikana.
- Toteutetaan käyttämällä heap-tietorakennetta, mikä tarkoittaa, että muuttujat tallennetaan heap-muistiin.
- Varattu muisti voidaan vapauttaa ja käyttää uudelleen.
Yksi etu dynaamisessa muistinvarausmenetelmässä Pythonissa on se, että meidän ei tarvitse murehtia etukäteen, kuinka paljon muistia tarvitsemme ohjelmaamme. Toinen etu on se, että tietorakenteiden manipulointi voidaan tehdä vapaasti ilman, että tarvitsee huolehtia suuremmasta muistin varaustarpeesta, jos tietorakenne laajenee.
Mutta koska dynaaminen muistinvaraus tehdään ohjelman suorituksen aikana, se kuluttaa enemmän aikaa sen valmistumiseen. Lisäksi varattu muisti on vapautettava sen käytön jälkeen. Muuten saattaa mahdollisesti esiintyä muistivuodon kaltaisia ongelmia.
Työskentelimme edellä kahdenlaisten muistirakenteiden kanssa – kasan muistin ja pinon muistin. Tutustutaanpa niihin tarkemmin.
Pinomuisti
Kaikki metodit ja niiden muuttujat tallennetaan pinomuistiin. Muistatko, että pinomuisti varataan kääntämisen aikana? Tämä tarkoittaa käytännössä sitä, että pääsy tämäntyyppiseen muistiin on hyvin nopeaa.
Kun metodia kutsutaan Pythonissa, pinoavaraus varataan. Tämä pinokehys käsittelee kaikki metodin muuttujat. Kun metodi on palautettu, pinokehys tuhoutuu automaattisesti.
Huomaa, että pinokehys vastaa myös metodin muuttujien laajuuden asettamisesta.
Heap-muisti
Kaikki objektit ja instanssimuuttujat tallennetaan heap-muistiin. Kun muuttuja luodaan Pythonissa, se tallennetaan yksityiseen heap-muistiin, joka sitten mahdollistaa allokaation ja deallokaation.
Kuopan muistin avulla näitä muuttujia voidaan käyttää globaalisti kaikkien ohjelmasi metodien toimesta. Kun muuttuja on palautettu, Pythonin roskienkerääjä ryhtyy työhön, jonka toimintaa käsittelemme myöhemmin.
Katsotaan nyt Pythonin muistirakennetta.
Pythonilla on kolme eri tasoa, kun puhutaan sen muistirakenteesta:
- Arenat
- Poolit
- Lohkot
Aloitamme niistä suurimmasta, eli areenoista.
Arenat
Kuvittele työpöytä, jossa on 64 kirjaa peittämässä koko sen pinnan. Pöydän yläosa edustaa yhtä areenaa, jonka kiinteä koko on 256KiB, joka on varattu kasaan (Huomaa, että KiB on eri asia kuin KB, mutta voit olettaa, että ne ovat samat tätä selitystä varten). Areena edustaa suurinta mahdollista muistinpalaa.
Perusteellisemmin sanottuna areenat ovat muistikuvauksia, joita Pythonin allokaattori, pymalloc, käyttää ja jotka on optimoitu pienille objekteille (alle tai yhtä suuret kuin 512 tavua). Arenat vastaavat muistin allokoinnista, joten myöhempien rakenteiden ei tarvitse enää tehdä sitä.
Tämä areena voidaan sitten jakaa edelleen 64 pooliin, joka on seuraavaksi suurin muistirakenne.
Poolit
Palatakseni työpöytäesimerkkiin, kirjat edustavat kaikkia yhden areenan sisällä olevia pooleja.
Kullakin poolilla on tyypillisesti kiinteä 4Kb:n koko ja sillä voi olla kolme mahdollista tilaa:
- Tyhjä: Pool on tyhjä ja siten varattavissa.
- Käytetty: Pool sisältää objekteja, joiden vuoksi se ei ole tyhjä eikä täynnä.
- Täynnä: Pool on täynnä eikä siten ole enää käytettävissä allokointiin.
Huomaa, että poolin koon tulisi vastata käyttöjärjestelmäsi oletusarvoista muistisivukokoa.
Tällöin pool jaetaan moneen lohkoon, jotka ovat pienimpiä muistirakenteita.
Lohkot
Palatakseni kirjoituspöytäesimerkkiin, jokaisessa kirjassa olevat sivut edustavat kaikkia poolin sisältämiä lohkoja.
Toisin kuin areenoiden ja poolien kohdalla, lohkon kokoa ei ole vahvistettu. Lohkon koko vaihtelee 8 ja 512 tavun välillä, ja sen on oltava kahdeksan kerrannainen.
Kukin lohko voi tallentaa vain yhden tietyn kokoisen Python-objektin, ja sillä on kolme mahdollista tilaa:
- Koskemattomana: Ei ole allokoitu
- Vapaa: On allokoitu, mutta vapautettu ja annettu varattavaksi
- Allokoitu: On varattu
Huomaa, että edellä käsittelemämme muistirakenteen kolme eri tasoa (areenat, poolit ja lohkot) on tarkoitettu nimenomaan pienemmille Python-objekteille. Suuret objektit ohjataan Pythonissa tavalliseen C:n allokaattoriin, joka olisi hyvää luettavaa toiselle päivälle.
Pythonin roskienkeruu
Roskienkeruu on ohjelman suorittama prosessi, jonka tarkoituksena on vapauttaa aiemmin varattua muistia objektille, joka ei ole enää käytössä. Roskienjakoa voi ajatella muistin kierrättämisenä tai uudelleenkäytönä.
Taannoin ohjelmoijat joutuivat varaamaan ja poistamaan muistia manuaalisesti. Muistin vapauttamisen unohtaminen johti muistivuotoihin, jotka heikensivät suorituksen suorituskykyä. Vielä pahempaa on, että manuaalinen muistin allokointi ja deallokointi johtaisi jopa muistin vahingossa tapahtuvaan ylikirjoittamiseen, mikä voi aiheuttaa ohjelman kaatumisen kokonaan.
Pythonissa roskienkeräys tapahtuu automaattisesti ja säästää siten paljon päänvaivaa muistin allokoinnin ja deallokoinnin manuaalisesta hallinnasta. Tarkemmin sanottuna Python käyttää viittauslaskentaa yhdistettynä geneeriseen roskienkeräykseen vapauttaakseen käyttämätöntä muistia. Viitteiden laskenta ei yksinään riitä Pythonissa, koska se ei siivoa tehokkaasti roikkuvia syklisiä viittauksia.
Sukupolvinen roskienkeräyssykli sisältää seuraavat vaiheet –
- Python alustaa ”hylkäyslistan” käyttämättömille objekteille.
- Suoritetaan algoritmi viittaussyklien havaitsemiseksi.
- Jos objektilta puuttuu ulkopuolisia viittauksia, se lisätään poisheittolistaan.
- Vapautetaan muistinvaraus hylkäyslistalla oleville objekteille.
Jos haluat oppia lisää roskienkeruusta Pythonissa, voit tutustua Python Garbage Collectioniin: A Guide for Developers post.
Monitoring Python Memory Issues
Vaikka kaikki rakastavat Pythonia, se ei kaihda muistiongelmia. Mahdollisia syitä on monia.
Pythonin (3.9.0) muistinhallinnan dokumentaation mukaan Pythonin muistinhallinta ei välttämättä vapauta muistia takaisin käyttöjärjestelmälle. Dokumentaatiossa todetaan, että ”tietyissä olosuhteissa Pythonin muistinhallinta ei välttämättä käynnistä asianmukaisia toimia, kuten roskienkeräystä, muistin tiivistämistä tai muita ennaltaehkäiseviä toimenpiteitä.”
Tämän seurauksena muistia voi joutua vapauttamaan nimenomaisesti Pythonissa. Yksi tapa tehdä tämä on pakottaa Pythonin roskienkerääjä vapauttamaan käyttämätöntä muistia käyttämällä gc-moduulia. Tätä varten on yksinkertaisesti suoritettava gc.collect(). Tästä on kuitenkin havaittavaa hyötyä vain silloin, kun käsitellään hyvin suurta määrää objekteja.
Pythonin roskienkerääjän ajoittaisen virheellisyyden lisäksi, varsinkin kun käsitellään suuria tietokokonaisuuksia, myös useiden Python-kirjastojen on tiedetty aiheuttavan muistivuotoja. Esimerkiksi Pandas on yksi tällainen tutkassa oleva työkalu. Kannattaa katsoa kaikki muistiin liittyvät ongelmat pandasin virallisessa GitHub-arkistossa!
Yksi ilmeinen syy, joka saattaa lipsahtaa jopa koodin tarkastajien tarkkojen silmien ohi, on se, että koodissa viipyy suuria objekteja, joita ei vapauteta. Samassa yhteydessä loputtomasti kasvavat tietorakenteet ovat toinen huolenaihe. Esimerkiksi kasvava sanakirjan tietorakenne ilman kiinteää kokorajoitusta.
Yksi tapa ratkaista kasvava tietorakenne on muuntaa sanakirja mahdollisuuksien mukaan listaksi ja asettaa listalle maksimikoko. Muussa tapauksessa aseta yksinkertaisesti rajoitus sanakirjan koolle ja tyhjennä se aina, kun raja saavutetaan.
Voit nyt ihmetellä, miten ylipäätään havaitsen muistiongelmat? Yksi vaihtoehto on hyödyntää Application Performance Monitoring (APM) -työkalua. Lisäksi monet hyödylliset Python-moduulit voivat auttaa sinua seuraamaan ja jäljittämään muistiongelmia. Katsotaanpa vaihtoehtoja alkaen APM-työkaluista.
Application Performance Monitoring (APM) Tools
Mitä siis tarkalleen ottaen on Application Performance Monitoring ja miten se auttaa muistiongelmien jäljittämisessä? APM-työkalun avulla voit tarkkailla ohjelman reaaliaikaisia suorituskykymittareita, mikä mahdollistaa jatkuvan optimoinnin, kun havaitset suorituskykyä rajoittavia ongelmia.
APM-työkalujen tuottamien raporttien perusteella saat yleiskäsityksen siitä, miten ohjelmasi toimii. Koska voit vastaanottaa ja seurata reaaliaikaisia suorituskykymittareita, voit ryhtyä välittömästi toimiin havaittujen ongelmien suhteen. Kun olet rajannut ohjelmasi mahdolliset alueet, jotka voivat olla syyllisiä muistiongelmiin, voit sitten sukeltaa koodiin ja keskustella siitä muiden koodin tekijöiden kanssa määrittääksesi tarkemmin tietyt koodirivit, jotka on korjattava.
Muistivuoto-ongelmien juurisyiden jäljittäminen itsessään voi olla pelottava tehtävä. Sen korjaaminen on toinen painajainen, sillä sinun on todella ymmärrettävä koodiasi. Jos joskus joudut tuohon tilanteeseen, älä etsi enempää, sillä ScoutAPM on pätevä APM-työkalu, joka voi rakentavasti analysoida ja optimoida sovelluksesi suorituskykyä. ScoutAPM antaa sinulle reaaliaikaisen näkemyksen, joten voit nopeasti paikantaa & ratkaista ongelmat ennen kuin asiakkaasi huomaavat ne.
Profiilimoduulit
On olemassa monia käteviä Python-moduuleja, joita voit käyttää muistiongelmien ratkaisemiseen, olipa kyse sitten muistivuodosta tai siitä, että ohjelmasi kaatuu liiallisen muistinkäytön vuoksi. Kaksi suositeltavista on:
- tracemalloc
- memory-profiler
Huomaa, että vain tracemalloc-moduuli on sisäänrakennettu, joten muista asentaa ensin toinen moduuli, jos haluat käyttää sitä.
tracemalloc
Pythonin (3.9.0) tracemalloc-dokumentaation mukaan tämän moduulin käyttäminen voi antaa seuraavat tiedot:
- Traceback, jossa objekti allokoitiin.
- Tilastoja allokoiduista muistilohkoista tiedostonimittäin ja rivinumeroittain: allokoitujen muistilohkojen kokonaiskoko, lukumäärä ja keskimääräinen koko.
- Laskekaa kahden tilannekuvan erotus muistivuodon havaitsemiseksi.
Suositeltu ensimmäinen askel, joka kannattaa tehdä muistiongelman lähteen selvittämiseksi, on näyttää ensin eniten muistia allokoivat tiedostot. Voit tehdä tämän helposti dokumentaatiossa esitetyn ensimmäisen koodiesimerkin avulla.
Tämä ei kuitenkaan tarkoita, etteivätkö pientä määrää muistia varaavat tiedostot kasvaisi loputtomiin aiheuttaen muistivuotoja tulevaisuudessa.
memory_profiler
Tämä moduuli on hauska. Olen työskennellyt tämän kanssa ja se on henkilökohtainen suosikkini, koska se tarjoaa mahdollisuuden yksinkertaisesti lisätä @profile-koristeen mihin tahansa funktioon, jota haluat tutkia. Tuloksena annettu tuloste on myös hyvin helposti ymmärrettävissä.
Toinen syy, joka tekee tästä henkilökohtaisen suosikkini, on se, että tämän moduulin avulla voit piirtää aikapohjaisen muistinkäytön kuvaajan. Joskus tarvitset vain nopean tarkistuksen siitä, jatkuuko muistin käyttö loputtomiin vai ei. Tämä on täydellinen ratkaisu tähän, koska sinun ei tarvitse tehdä rivi riviltä muistiprofilointia asian vahvistamiseksi. Voit yksinkertaisesti tarkkailla piirrettyä kuvaajaa, kun olet antanut profiloijan toimia tietyn ajan. Tässä on esimerkki tulostettavasta kuvaajasta –
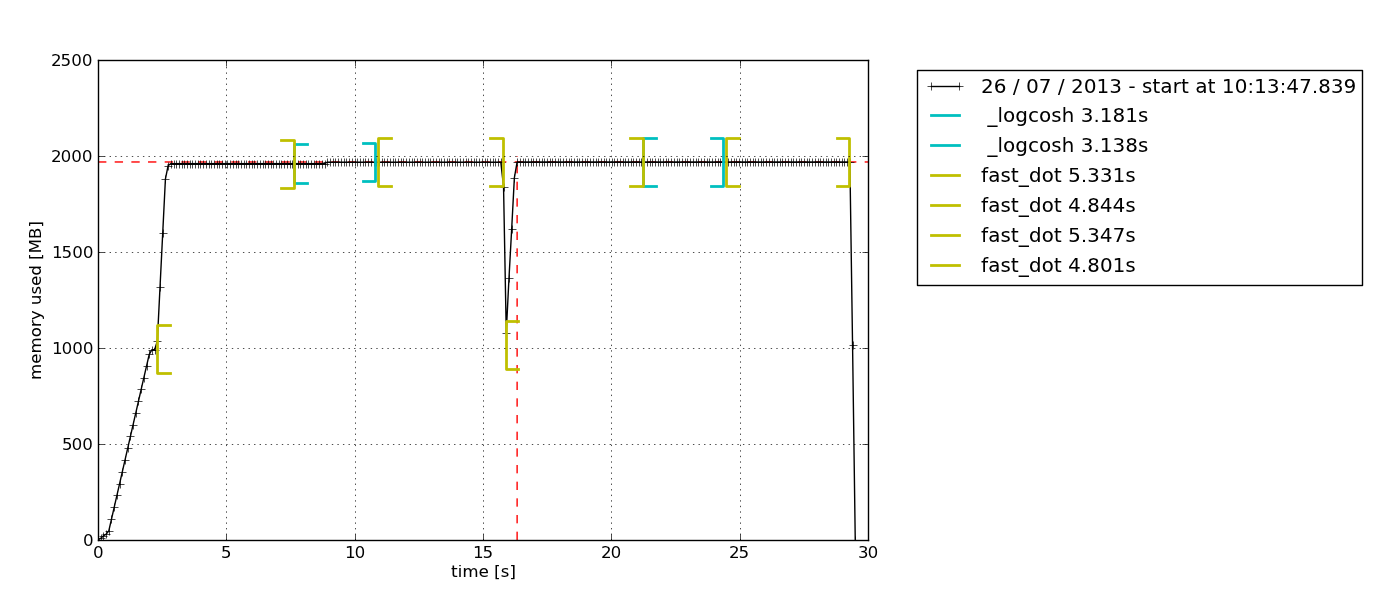
Muistiprofiilin dokumentaation kuvauksen mukaan tämä Python-moduuli on tarkoitettu prosessin muistinkulutuksen seurantaan sekä Python-ohjelmien rivikohtaiseen analyysiin. Se on puhdas Python-moduuli, joka on riippuvainen psutil-kirjastosta.
Suosittelen lukemaan tämän Medium-blogin, jotta voit tutustua tarkemmin memory-profilerin käyttöön. Siellä opit myös käyttämään toista Python-moduulia, muppy:tä (uusin on muppy3).
Parhaat käytännöt Python-koodin suorituskyvyn parantamiseen
Kyllä riittää kaikki muistinhallinnan yksityiskohdat. Tutustutaan nyt joihinkin hyviin tapoihin muistitehokkaan Python-koodin kirjoittamisessa.
Hyödynnä Python-kirjastoja ja sisäänrakennettuja funktioita
Tämä on hyvä tapa, joka saattaa melko usein jäädä huomiotta. Pythonilla on vertaansa vailla oleva yhteisön tuki, ja tämä näkyy siinä, että tarjolla on runsaasti Python-kirjastoja lähes kaikkiin tarkoituksiin API-kutsuista datatieteeseen.
Jos on olemassa Python-kirjasto, jonka avulla voit tehdä saman asian kuin mitä olet jo toteuttanut, voit verrata koodisi suorituskykyä kirjastoa käyttäessäsi verrattuna siihen, että käyttäisit räätälöimääsi koodia. Todennäköisesti Python-kirjastot (etenkin suositut) ovat muistitehokkaampia kuin koodisi, koska niitä parannetaan jatkuvasti yhteisön palautteen perusteella. Luottaisitko mieluummin koodiin, joka on tehty yhdessä yössä, vai sellaiseen, jota on paranneltu tiukasti pitkän ajanjakson ajan?
Parasta on, että Python-kirjastot säästävät monia rivejä koodia, joten miksipä ei?
Ei ”+”-operaattorin käyttäminen merkkijonojen ketjuttamiseen
Jossain vaiheessa olemme kaikki syyllistyneet siihen, että olemme ketjuttaneet merkkijonoja ”+”-operaattorilla, koska se näyttää niin helpolta.
Huomioithan, että merkkijonot ovat muuttumattomia. Näin ollen joka kerta, kun lisäät elementin merkkijonoon ”+”-operaattorilla, Pythonin on luotava uusi merkkijono uudella muistinvarauksella. Kun merkkijonot ovat pidempiä, koodin muistin tehottomuus korostuu.
Itertoolsin käyttäminen tehokkaaseen silmukointiin
Silmukointi on olennainen osa asioiden automatisointia. Kun käytämme silmukoita yhä enemmän ja enemmän, joudumme lopulta käyttämään sisäkkäisiä silmukoita, jotka ovat tunnetusti tehottomia niiden suuren ajonaikaisen monimutkaisuuden vuoksi.
Tässä kohtaa itertools-moduuli tulee apuun. Pythonin itertools-dokumentaation mukaan: ”Moduuli standardoi ydinjoukon nopeita, muistitehokkaita työkaluja, jotka ovat käyttökelpoisia yksinään tai yhdessä. Yhdessä ne mahdollistavat erikoistuneiden työkalujen rakentamisen ytimekkäästi ja tehokkaasti puhtaalla Pythonilla.”
Muistitehokkaan silmukoiden tekemisen itertools-moduuli mahdollistaa siis muistitehokkaan silmukoiden tekemisen hankkiutumalla eroon tarpeettomista silmukoista. Mielenkiintoista on, että itertools-moduulia kutsutaan helmeksi, koska se mahdollistaa tyylikkäiden ratkaisujen koostamisen lukemattomiin ongelmiin.
Olen melko varma, että tulet työskentelemään ainakin yhden silmukan kanssa seuraavassa koodissasi, joten kokeile sitten itertools-moduulin toteuttamista!”
Yhteenveto ja loppuajatuksia
Hyvien muistinhallintatapojen soveltaminen Pythonissa ei ole satunnaista ohjelmoijaa varten. Jos yleensä pärjäät yksinkertaisilla skripteillä, sinun ei pitäisi törmätä muistiin liittyviin ongelmiin lainkaan. Kiitos laitteistojen ja ohjelmistojen, jotka kehittyvät edelleen nopeasti tätä lukiessasi, lähes minkä tahansa laitteen perusmallin, merkistä riippumatta, pitäisi pyörittää jokapäiväisiä ohjelmia hienosti. Muistitehokkaan koodin tarve alkaa näkyä vasta, kun aletaan työstää isoa koodipohjaa, erityisesti tuotantoa varten, jossa suorituskyky on avainasemassa.
Tämä ei kuitenkaan tarkoita, että muistinhallinta Pythonissa olisi vaikea käsite ymmärtää, eikä se tarkoita, että se ei olisi tärkeää. Tämä johtuu siitä, että sovellusten suorituskyvyn korostaminen kasvaa päivä päivältä. Jonain päivänä se ei ole enää pelkkä ”tehty” kysymys. Sen sijaan kehittäjät kilpailevat toimittamaan ratkaisun, joka ei ainoastaan kykene onnistuneesti ratkaisemaan asiakkaiden tarpeita, vaan tekee sen myös huikealla nopeudella ja minimaalisilla resursseilla.