- Esittely
- Määritelmät
- TensorFlow/Keras
- Kuvan tunnistaminen (luokittelu)
- Ominaisuuksien louhinta
- Miten neuroverkot oppivat tunnistamaan kuvia
- Feature Extraction With Filters
- Aktivointifunktiot
- Pooling-kerrokset
- Flattening
- Täysin kytketty kerros
- Koneoppimisen työnkulku
- Datan valmistelu
- Mallin luominen
- Mallin harjoittelu
- Mallin evaluointi
- Kuvan tunnistaminen CNN:llä
- Datan esivalmistelu
- Mallin suunnittelu
- Mallin luominen
- Johtopäätökset
Esittely
Yksi yleisimmistä TensorFlow’n ja Kerasin käyttötavoista on kuvien tunnistaminen/luokittelu. Jos haluat oppia käyttämään Kerasia kuvien luokitteluun tai tunnistamiseen, tämä artikkeli opettaa sinulle miten.
Määritelmät
Jos et ole selvillä kuvantunnistuksen peruskäsitteistä, on vaikea ymmärtää täysin tämän artikkelin loppuosaa. Ennen kuin siis jatkamme eteenpäin, otetaan hetki aikaa määritellä joitakin termejä.
TensorFlow/Keras

Credit: commons.wikimedia.org
TensorFlow on avoimeen lähdekoodiin perustuva kirjasto, jonka Google Brain -tiimi on luonut Pythonille. TensorFlow kokoaa yhteen monia erilaisia algoritmeja ja malleja, joiden avulla käyttäjä voi toteuttaa syviä neuroverkkoja käytettäväksi esimerkiksi kuvantunnistuksen/luokittelun ja luonnollisen kielen käsittelyn kaltaisissa tehtävissä. TensorFlow on tehokas kehys, joka toimii toteuttamalla sarjan prosessointisolmuja, joista jokainen solmu edustaa matemaattista operaatiota, ja koko solmujen sarjaa kutsutaan ”graafiksi”.
Keras on korkean tason API (sovellusohjelmointirajapinta), jonka alla voidaan käyttää TensorFlow’n toimintoja (sekä muita ML-kirjastoja, kuten Theanoa). Keras suunniteltiin käyttäjäystävällisyys ja modulaarisuus ohjenuorana. Käytännössä Keras tekee TensorFlow’n monien tehokkaiden mutta usein monimutkaisten toimintojen toteuttamisesta mahdollisimman yksinkertaista, ja se on konfiguroitu toimimaan Pythonin kanssa ilman suurempia muutoksia tai konfigurointeja.
Kuvan tunnistaminen (luokittelu)
Kuvan tunnistamisella viitataan tehtävään, jossa kuva syötetään neuroverkkoon ja se antaa tulokseksi jonkinlaisen etiketin kyseiselle kuvalle. Verkon antama merkintä vastaa ennalta määriteltyä luokkaa. Luokkia, joihin kuva voidaan merkitä, voi olla useita tai vain yksi. Jos luokkia on vain yksi, käytetään usein termiä ”tunnistaminen”, kun taas usean luokan tunnistustehtävää kutsutaan usein ”luokitteluksi”.
Kuvaluokittelun osa-alue on objektien havaitseminen, jossa tiettyjen objektien tietyt yksilöt tunnistetaan kuuluviksi tiettyyn luokkaan, kuten eläimet, autot tai ihmiset.
Ominaisuuksien louhinta
Kuvantunnistusta tai -luokittelua varten neuroverkon on tehtävä ominaisuuksien louhinta. Ominaisuudet ovat niitä datan elementtejä, joista ollaan kiinnostuneita ja jotka syötetään verkon läpi. Kuvatunnistuksen erityistapauksessa piirteet ovat kohteen pikseliryhmiä, kuten reunoja ja pisteitä, joita verkko analysoi kuvioiden löytämiseksi.
Piirteiden tunnistaminen (tai piirteiden louhinta) on prosessi, jossa syötetystä kuvasta poimitaan olennaiset piirteet, jotta näitä piirteitä voidaan analysoida. Monissa kuvissa on kuvaan liittyviä merkintöjä tai metatietoja, jotka auttavat verkkoa löytämään relevantit piirteet.
Miten neuroverkot oppivat tunnistamaan kuvia
Tuntuman saaminen siitä, miten neuroverkko tunnistaa kuvia, auttaa sinua, kun toteutat neuroverkkomallia, joten tutustutaan lyhyesti kuvantunnistusprosessiin seuraavissa kappaleissa.
Feature Extraction With Filters
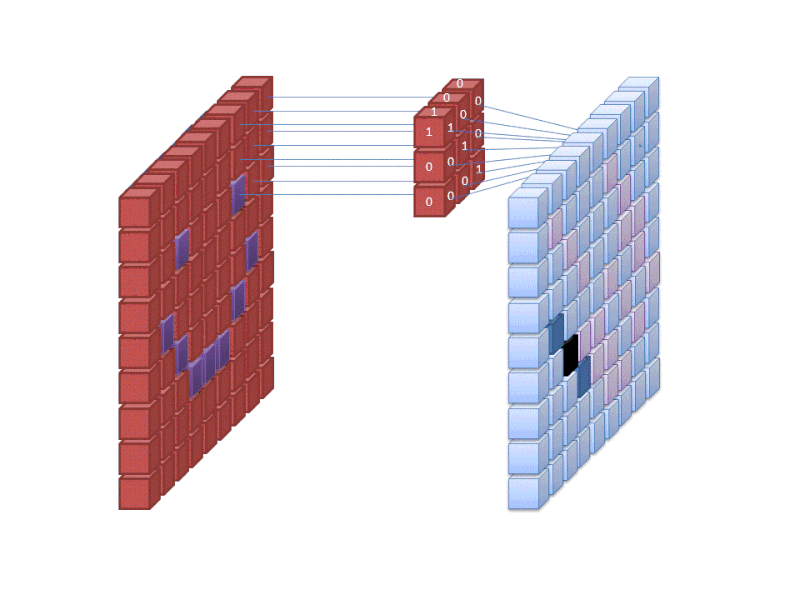
Credit: commons.wikimedia.org
Neuraaliverkon ensimmäinen kerros ottaa vastaan kaikki kuvassa olevat pikselit. Kun kaikki tiedot on syötetty verkkoon, kuvaan sovelletaan erilaisia suodattimia, jotka muodostavat esityksiä kuvan eri osista. Tämä on piirteiden louhintaa, ja sillä luodaan ”piirrekarttoja”.
Tämä piirteiden louhintaprosessi kuvasta toteutetaan ”konvoluutiokerroksella”, ja konvoluutio on yksinkertaisesti kuvan osan esityksen muodostamista. Tästä konvoluutiokonseptista saamme termin Convolutional Neural Network (CNN), neuroverkkotyyppi, jota käytetään yleisimmin kuvien luokittelussa/tunnistuksessa.
Jos haluat havainnollistaa, miten piirrekarttojen luominen toimii, ajattele, että valaisisit taskulampulla kuvan päälle pimeässä huoneessa. Kun liu’utat sädettä kuvan yli, opit kuvan piirteitä. Suodatin on se, mitä verkko käyttää muodostaakseen esityksen kuvasta, ja tässä metaforassa taskulampun valo on suodatin.
Taskulampun säteen leveys säätelee sitä, kuinka suurta osaa kuvasta tutkit kerralla, ja neuroverkoilla on samanlainen parametri, suodattimen koko. Suodattimen koko vaikuttaa siihen, kuinka suuri osa kuvasta, kuinka monta pikseliä, tutkitaan kerralla. Yleinen CNN:ssä käytetty suodatinkoko on 3, ja se kattaa sekä korkeuden että leveyden, joten suodatin tutkii 3 x 3 pikseliä käsittävän alueen.
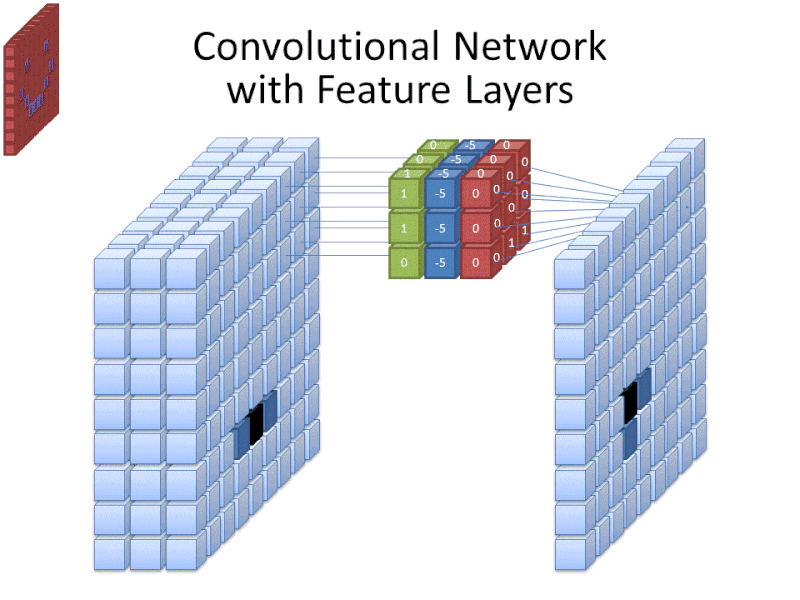
Credit: commons.wikimedia.org
Vaikka suodatinkoko kattaa suodattimen korkeuden ja leveyden, myös suodattimen syvyys on määritettävä.
Miten 2D-kuvalla on syvyyttä?
Digitaaliset kuvat renderöidään korkeutena, leveytenä ja jonain RGB-arvona, joka määrittelee pikselin värit, joten ”syvyys”, jota seurataan, on värikanavien määrä, joka kuvassa on. Harmaasävykuvissa (ei-värikuvissa) on vain yksi värikanava, kun taas värikuvissa on kolme syvyyskanavaa.
Kaikki tämä tarkoittaa, että täysvärikuvaan sovelletun 3-kokoisen suodattimen mitat ovat 3 x 3 x 3. Jokaisen suodattimen peittämän pikselin kohdalla verkko kertoo suodattimen arvot itse pikselien arvoilla saadakseen numeerisen esityksen kyseisestä pikselistä. Tämä prosessi tehdään sitten koko kuvalle, jotta saadaan täydellinen esitys. Suodatinta siirretään kuvan loppuosassa ”stride” -nimisen parametrin mukaan, joka määrittelee, kuinka monta pikseliä suodatinta siirretään sen jälkeen, kun se on laskenut arvon nykyisessä sijainnissaan. CNN:n tavanomainen stride-koko on 2.
Kaiken tämän laskennan lopputulos on piirrekartta. Tämä prosessi tehdään tyypillisesti useammalla kuin yhdellä suodattimella, mikä auttaa säilyttämään kuvan monimutkaisuuden.
Aktivointifunktiot
Kuvan piirrekartan luomisen jälkeen kuvaa edustavat arvot ohjataan aktivointifunktion tai aktivointikerroksen läpi. Aktivointifunktio ottaa kuvaa edustavat arvot, jotka ovat konvoluutiokerroksen ansiosta lineaarisessa muodossa (eli pelkkä numeroiden luettelo), ja lisää niiden epälineaarisuutta, koska kuvat itsessään ovat epälineaarisia.
Tyypillinen aktivointifunktio, jota käytetään tämän toteuttamiseen, on ReLU (Rectified Linear Unit), vaikka on olemassa joitakin muitakin aktivointifunktioita, joita käytetään satunnaisesti (voit lukea niistä täältä).
Pooling-kerrokset
Kun data on aktivoitu, se lähetetään pooling-kerroksen läpi. Pooling ”pienentää” kuvan näytettä, mikä tarkoittaa, että se ottaa kuvaa edustavan tiedon ja pakkaa sen, jolloin se pienenee. Pooling-prosessi tekee verkosta joustavamman ja taitavamman tunnistamaan kohteita/kuvia relevanttien piirteiden perusteella.
Kun katsomme kuvaa, emme yleensä ole huolissamme kaikesta kuvan taustalla olevasta informaatiosta, vaan vain niistä piirteistä, joista välitämme, kuten ihmisistä tai eläimistä.
Yhtä lailla CNN:n poolikerros abstrahoi kuvan tarpeettomat osat pois ja säilyttää vain ne kuvan osat, joita se pitää merkityksellisinä, kuten poolikerroksen määritetty koko ohjaa.
Koska sen on tehtävä päätöksiä kuvan merkityksellisimmistä osista, toiveena on, että verkko oppii vain ne kuvan osat, jotka todella edustavat kyseistä kohdetta. Näin estetään ylisovittaminen, jolloin verkko oppii harjoitustapauksen osat liian hyvin eikä pysty yleistämään uuteen dataan.
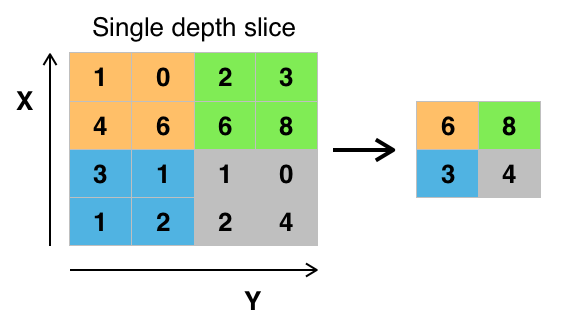
Credit: commons.wikimedia.org
Arvojen yhdistämiseen on erilaisia tapoja, mutta yleisimmin käytetään max poolingia. Max pooling -menetelmällä saadaan yhden suodattimen sisällä (kuvan yhdessä kohdassa) olevien pikselien suurin arvo. Tämä pudottaa 3/4 osaa informaatiosta, jos oletetaan, että käytetään 2 x 2 suodatinta.
Pikselien maksimiarvoja käytetään mahdollisten kuvan vääristymien huomioon ottamiseksi, ja kuvan parametreja/kokoa pienennetään ylisovittamisen hallitsemiseksi. On olemassa muitakin pooling-tyyppejä, kuten average pooling tai sum pooling, mutta niitä ei käytetä yhtä usein, koska maksimipoolingilla saavutetaan yleensä parempi tarkkuus.
Flattening
CNN:n viimeiset kerrokset, tiheästi kytketyt kerrokset, edellyttävät, että käsiteltävä data on vektorin muodossa. Tästä syystä data on ”litistettävä”. Arvot pakataan pitkäksi vektoriksi tai sarakkeeksi, joka koostuu peräkkäin järjestetyistä numeroista.
Täysin kytketty kerros
CNN:n viimeiset kerrokset ovat tiheästi kytkettyjä kerroksia eli keinotekoista neuroverkkoa (ANN). ANN:n ensisijainen tehtävä on analysoida syötetyt piirteet ja yhdistää ne erilaisiksi attribuuteiksi, jotka auttavat luokittelussa. Nämä kerrokset muodostavat lähinnä neuronikokoelmia, jotka edustavat kyseisen kohteen eri osia, ja neuronikokoelma voi edustaa koiran luppakorvia tai omenan punaisuutta. Kun tarpeeksi monta näistä neuroneista aktivoituu vastauksena syötekuvaan, kuva luokitellaan objektiksi.

Credit: commons.wikimedia.org
ANN laskee virheen eli laskettujen arvojen ja harjoitusjoukon odotusarvon välisen eron. Tämän jälkeen verkko käy läpi backpropagationin, jossa tietyn neuronin vaikutus seuraavan kerroksen neuroniin lasketaan ja sen vaikutusta säädetään. Näin optimoidaan mallin suorituskyky. Prosessi toistetaan uudelleen ja uudelleen. Näin verkko harjaantuu dataan ja oppii yhteyksiä syötettyjen ominaisuuksien ja tuotettujen luokkien välillä.
Keskimmäisten täysin kytkettyjen kerrosten neuronit tuottavat binääriarvoja, jotka liittyvät mahdollisiin luokkiin. Jos on neljä eri luokkaa (vaikkapa koira, auto, talo ja ihminen), neuroni antaa ”1”-arvon sille luokalle, jota se uskoo kuvan edustavan, ja ”0”-arvon muille luokille.
Viimeinen täysin kytketty kerros vastaanottaa sitä edeltävän kerroksen tulosteet ja antaa kullekin luokalle todennäköisyyden, jonka summa on yksi. Jos luokassa ”koira” on arvo 0,75, se edustaa 75 prosentin varmuutta siitä, että kuva on koira.
Kuvaluokittelija on nyt koulutettu, ja kuvat voidaan välittää CNN:lle, joka nyt antaa tulokseksi arvauksen kuvan sisällöstä.
Koneoppimisen työnkulku
Ennen kuin hyppäämme esimerkkiin kuvaluokittimen kouluttamisesta, otamme hetken aikaa aikaa ymmärtääksemme koneoppimisen työnkulkua tai putkea. Neuroverkkomallin kouluttamisprosessi on melko vakiomuotoinen, ja se voidaan jakaa neljään eri vaiheeseen.
Datan valmistelu
Aluksi sinun on kerättävä datasi ja saatettava se sellaiseen muotoon, että verkko voi kouluttaa sen. Tähän kuuluu kuvien kerääminen ja niiden merkitseminen. Vaikka olisitkin ladannut jonkun muun valmisteleman datasarjan, sinun on todennäköisesti suoritettava esikäsittelyä tai valmistelua, ennen kuin voit käyttää sitä harjoitteluun. Datan valmistelu on oma taiteenlajinsa, johon kuuluu esimerkiksi puuttuvien arvojen, korruptoituneen datan, väärässä muodossa olevan datan, virheellisten merkintöjen jne. käsittely.
Tässä artikkelissa käytämme esikäsiteltyä datasarjaa.
Mallin luominen
Neuraaliverkon mallin luomiseen kuuluu valintojen tekeminen erilaisista parametreista ja hyperparametreista. Sinun on tehtävä päätöksiä siitä, kuinka monta kerrosta käytät mallissasi, mitkä ovat kerrosten tulo- ja lähtökoot, millaisia aktivointifunktioita käytät, käytätkö pudotusta vai et jne.
Käyttämiesi parametrien ja hyperparametrien oppiminen vaatii aikaa (ja paljon opiskelua), mutta heti alkuun on olemassa joitakin heuristiikkoja, joita voit käyttää, jotta pääset vauhtiin, ja käsittelemme joitakin näistä toteutusesimerkin aikana.
Mallin harjoittelu
Mallin luomisen jälkeen luot yksinkertaisesti mallin instanssin ja sovitat sen harjoitteludatan kanssa. Suurin huomio mallia koulutettaessa on se, kuinka paljon aikaa mallin kouluttaminen vie. Voit määrittää verkon harjoittelun keston määrittämällä harjoittelun epookkien määrän. Mitä pidempään treenaat mallia, sitä enemmän sen suorituskyky paranee, mutta liian monta treeniepokkia ja vaarana on ylisovittaminen.
Treenattavien epookkien lukumäärän valitseminen on asia, johon saat tuntumaa, ja on tapana tallentaa verkon painot harjoittelujaksojen välissä, jotta sinun ei tarvitse aloittaa alusta, kun olet edistynyt verkon harjoittelemisessa.
Mallin evaluointi
Mallin evaluoinnissa on useita vaiheita. Ensimmäinen vaihe mallin arvioinnissa on verrata mallin suorituskykyä validointitietoaineistoon, eli aineistoon, johon mallia ei ole koulutettu. Vertaat mallin suorituskykyä tähän validointitietoaineistoon ja analysoit sen suorituskykyä eri mittareiden avulla.
Neuraaliverkkomallin suorituskyvyn määrittämiseksi on olemassa erilaisia mittareita, mutta yleisin mittari on ”tarkkuus” eli oikein luokiteltujen kuvien määrä jaettuna aineistosi kuvien kokonaismäärällä.
Kun olet nähnyt mallin suorituskyvyn tarkkuuden validointidatajoukossa, palaat yleensä takaisin ja harjoittelet verkon uudelleen käyttämällä hieman viritettyjä parametreja, koska on epätodennäköistä, että olet tyytyväinen verkon suorituskykyyn ensimmäisellä harjoittelukerralla. Jatkat verkon parametrien säätämistä, sen uudelleenkouluttamista ja sen suorituskyvyn mittaamista, kunnes olet tyytyväinen verkon tarkkuuteen.
Viimeiseksi testataan verkon suorituskyky testausjoukolla. Tämä testausjoukko on toinen datajoukko, jota mallisi ei ole koskaan ennen nähnyt.
Mahdollisesti ihmettelet:
Miksi vaivautua testausjoukon kanssa? Jos saat käsityksen mallisi tarkkuudesta, eikö se ole validointijoukon tarkoitus?
On hyvä pitää testausta varten erä dataa, jota verkko ei ole koskaan nähnyt, koska kaikki tekemäsi parametrien hienosäätö yhdistettynä validointijoukkoon kohdistuvaan uudelleentestaukseen voi tarkoittaa, että verkko on oppinut joitakin validointijoukkoon liittyviä erityispiirteitä, jotka eivät ole yleistettävissä otoksen ulkopuoliseen dataan.
Testausjoukon tarkoituksena on siis tarkastaa, ettei siihen liiallista sovittamista tapahdu, ja olla varmempi siitä, että mallisi on todella sopiva toimimaan todellisessa maailmassa.
Kuvan tunnistaminen CNN:llä
Olemme käsitelleet paljon tähän mennessä, ja jos kaikki tämä tieto on ollut hieman ylivoimaista, näiden käsitteiden näkeminen yhdessä esimerkkiluokittimessa, joka on koulutettu data-aineistolla, tekee käsitteistä konkreettisempia. Tarkastellaan siis täydellistä esimerkkiä kuvantunnistuksesta Kerasilla, datan lataamisesta arviointiin.

Credit: www.cs.toronto.edu
Aluksi tarvitsemme datasetin, jolla voimme kouluttaa. Tässä esimerkissä käytämme kuuluisaa CIFAR-10-tietoaineistoa. CIFAR-10 on suuri kuvatietokanta, joka sisältää yli 60 000 kuvaa, jotka edustavat 10 eri luokkaa esineitä, kuten kissoja, lentokoneita ja autoja.
Kuvat ovat täysvärisiä RGB-kuvia, mutta ne ovat melko pieniä, vain 32 x 32. Yksi hieno asia CIFAR-10-datasetissa on se, että se tulee valmiiksi pakattuna Kerasin kanssa, joten datasetin lataaminen on erittäin helppoa ja kuvat vaativat hyvin vähän esikäsittelyä.
Ensimmäinen asia, joka meidän pitäisi tehdä, on tuoda tarvittavat kirjastot. Näytän, miten näitä tuonteja käytetään, kun menemme eteenpäin, mutta nyt tiedämme, että käytämme Numpya ja erilaisia Kerasiin liittyviä moduuleja:
import numpyfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activationfrom keras.layers.convolutional import Conv2D, MaxPooling2Dfrom keras.constraints import maxnormfrom keras.utils import np_utilsKäytämme tässä satunnaista siementä, jotta tässä artikkelissa saavutetut tulokset ovat toistettavissa, minkä vuoksi tarvitsemme numpy:
# Set random seed for purposes of reproducibilityseed = 21Datan esivalmistelu
Tarvitsemme vielä yhden tuontitiedoston: datasetin.
from keras.datasets import cifar10Ladataan nyt dataset sisään. Voimme tehdä sen yksinkertaisesti määrittämällä, mihin muuttujiin haluamme ladata datan, ja käyttämällä sitten load_data()-funktiota:
# loading in the data (X_train, y_train), (X_test, y_test) = cifar10.load_data()Useimmissa tapauksissa sinun on tehtävä datallesi jonkin verran esikäsittelyä saadaksesi sen valmiiksi käyttöä varten, mutta koska käytämme valmiiksi pakattua datasettiä, esikäsittelyä on tehtävä hyvin vähän. Yksi asia, jonka haluamme tehdä, on normalisoida syöttötiedot.
Jos syöttötietojen arvot ovat liian laajalla alueella, se voi vaikuttaa negatiivisesti verkon suorituskykyyn. Tässä tapauksessa syöttöarvot ovat kuvan pikseleitä, joiden arvo on välillä 0-255.
Normalisoidaksemme datan voimme siis yksinkertaisesti jakaa kuvan arvot luvulla 255. Tätä varten meidän on ensin tehtävä tiedoista float-tyyppisiä, sillä tällä hetkellä ne ovat kokonaislukuja. Voimme tehdä tämän käyttämällä astype() Numpy-komentoa ja ilmoittamalla sitten, minkä datatyypin haluamme:
# normalize the inputs from 0-255 to between 0 and 1 by dividing by 255 X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = X_train / 255.0X_test = X_test / 255.0Toinen asia, joka meidän on tehtävä saadaksemme datan valmiiksi verkkoa varten, on arvojen one-hot-koodaus. En aio mennä one-hot-koodauksen yksityiskohtiin tässä, mutta nyt tiedetään, että verkko ei voi käyttää kuvia sellaisenaan, vaan ne täytyy ensin koodata, ja one-hot-koodausta käytetään parhaiten silloin, kun tehdään binääriluokitusta.
Tehdään tässä käytännössä binääriluokitusta, koska kuva joko kuuluu johonkin luokkaan tai sitten ei, se ei voi kuulua jonnekin siltä väliltä. Numpy-komentoa to_categorical() käytetään one-hot-koodaukseen. Tämän vuoksi tuotiin np_utils-funktio Kerasista, koska se sisältää to_categorical().
Meidän on myös määritettävä datasetissä olevien luokkien määrä, jotta tiedämme, kuinka moneen neuroniin viimeinen kerros on pakattava:
# one hot encode outputsy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)class_num = y_test.shapeMallin suunnittelu
Olemme päässeet vaiheeseen, jossa suunnittelemme CNN-mallin. Ensimmäiseksi on määriteltävä formaatti, jota haluamme käyttää mallissa, Kerasilla on useita eri formaatteja tai pohjapiirroksia, joihin mallit voidaan rakentaa, mutta Sequential on yleisimmin käytetty, ja tästä syystä olemme tuoneet sen Kerasista.
Mallin luominen
model = Sequential()Mallimme ensimmäinen kerros on konvoluutiokerros. Se ottaa vastaan syötteet ja ajaa niihin konvoluutiosuodattimia.
Toteuttaessamme näitä Kerasissa, meidän on määritettävä haluamiemme kanavien/suodattimien määrä (tuo alla oleva 32), haluamamme suodattimen koko (tässä tapauksessa 3 x 3), syötteen muoto (ensimmäistä kerrosta luodessamme) ja tarvitsemamme aktivointi ja pehmuste.
Kuten mainittiin, relu on yleisin aktivointi, ja padding='same' tarkoittaa vain sitä, ettemme muuta kuvan kokoa lainkaan:
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape, padding='same'))model.add(Activation('relu'))Huomautus: Voit myös ketjuttaa aktivoinnit ja poolaukset yhteen, esimerkiksi näin:
model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), activation='relu', padding='same'))Tehdään nyt ylisovittamisen estämiseksi pudotuskerros (dropout layer), joka toimii siten, että satunnaisesti eliminoidaan osa kerrosten välisistä kytkennöistä (0.2 tarkoittaa, että se pudottaa 20 % olemassa olevista yhteyksistä):
model.add(Dropout(0.2))Tässä yhteydessä voimme myös tehdä eränormalisoinnin. Eränormalisointi normalisoi seuraavaan kerrokseen menevät syötteet varmistaen, että verkko luo aina aktivointeja, joiden jakauma on sama kuin haluamamme:
model.add(BatchNormalization())Nyt tulee toinen konvoluutiokerros, mutta suodatinkoko kasvaa, jotta verkko voi oppia monimutkaisempia representaatioita:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))Tässä on pooling-kerros, kuten aiemmin käsiteltiin, tämä auttaa tekemään kuvaluokittimestamme kestävämmän, niin että se voi oppia relevantteja kuvioita. Tässä on myös pudotus ja erän normalisointi:
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization())Tässä on CNN-toteutuksen ensimmäisen puoliskon perusvirtaus: Convolutional, aktivointi, dropout, pooling. Nyt näet, miksi olemme tuoneet Dropout, BatchNormalization, Activation, Conv2d ja MaxPooling2d.
Voit vaihdella konvoluutiokerrosten tarkkaa lukumäärää mieleisesi mukaan, joskin jokainen lisää laskentakuluja. Huomaa, että kun lisäät konvoluutiokerroksia, kasvatat yleensä niiden suodattimien määrää, jotta malli voi oppia monimutkaisempia esityksiä. Jos näille kerroksille valitut luvut vaikuttavat jokseenkin mielivaltaisilta, tiedä vain, että yleensä suodattimia lisätään sitä mukaa kuin jatkat, ja on suositeltavaa tehdä niistä 2:n potensseja, mikä voi antaa pientä etua, kun harjoittelet grafiikkasuorittimella.
On tärkeää, ettei allokointikerroksia ole liikaa, sillä jokainen allokointi hylkää osan datasta. Liian tiheä poolaus johtaa siihen, että tiheästi kytketyillä kerroksilla ei ole juuri mitään opittavaa, kun data saavuttaa ne.
Poolauskerrosten tarkka määrä, jota sinun tulisi käyttää, vaihtelee tehtävästä riippuen, ja se on jotain, johon saat tuntuman ajan myötä. Koska kuvat ovat tässä jo nyt niin pieniä, emme poolaa enempää kuin kaksi kertaa.
Voit nyt toistaa näitä kerroksia antaaksesi verkollesi enemmän representaatioita, joiden pohjalta työskennellä:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Kun olemme valmiita konvoluutiokerrosten kanssa, meidän täytyy Flatten käsitellä dataa, minkä vuoksi tulimme tuonneet yllä olevan funktion. Lisäämme myös jälleen pudotuskerroksen:
model.add(Flatten())model.add(Dropout(0.2))Nyt hyödynnämme Dense tuontia ja luomme ensimmäisen tiheästi kytketyn kerroksen. Meidän on määritettävä tiheästi kytketyn kerroksen neuronien lukumäärä. Huomaa, että neuronien määrä seuraavissa kerroksissa vähenee ja lähestyy lopulta samaa määrää neuroneita kuin tietokokonaisuudessa on luokkia (tässä tapauksessa 10). Ydinrajoitus voi säännöllistää dataa oppimisen aikana, mikä on toinen asia, joka auttaa estämään ylisovittamisen. Tämän vuoksi otimme aiemmin käyttöön maxnorm.
model.add(Dense(256, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Dense(128, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Tässä viimeisessä kerroksessa välitämme luokkien lukumäärän neuronien lukumääräksi. Jokainen neuroni edustaa yhtä luokkaa, ja tämän kerroksen ulostulo on 10 neuronin vektori, jossa jokainen neuroni tallentaa jonkin todennäköisyyden sille, että kyseinen kuva kuuluu edustamaansa luokkaan.
Viimeiseksi aktivointifunktio softmax valitsee ulostuloksi neuronin, jolla on suurin todennäköisyys, äänestäen, että kuva kuuluu kyseiseen luokkaan:
model.add(Dense(class_num))model.add(Activation('softmax'))Nyt kun olemme suunnitelleet haluamamme mallin, meidän täytyy vain koota se. Määritellään epookkien määrä, jonka haluamme treenata, sekä optimoija, jota haluamme käyttää.
Optimoija on se, joka virittää verkon painot niin, että ne lähestyvät pienimmän tappion pistettä. Adam-algoritmi on yksi yleisimmin käytetyistä optimoijista, koska se antaa hyvän suorituskyvyn useimmissa ongelmissa:
epochs = 25optimizer = 'adam'Kootaan nyt malli valitsemillamme parametreilla. Määritellään myös käytettävä metriikka.
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=)Voidaan tulostaa mallin yhteenveto nähdäksemme miltä koko malli näyttää.
print(model.summary())Tulostamalla yhteenvedon saamme melko paljon tietoa:
Results: Layer (type) Output Shape Param #=================================================================conv2d_1 (Conv2D) (None, 32, 32, 32) 896_________________________________________________________________activation_1 (Activation) (None, 32, 32, 32) 0_________________________________________________________________dropout_1 (Dropout) (None, 32, 32, 32) 0_________________________________________________________________batch_normalization_1 (Batch (None, 32, 32, 32) 128_________________________________________________________________conv2d_2 (Conv2D) (None, 32, 32, 64) 18496_________________________________________________________________activation_2 (Activation) (None, 32, 32, 64) 0_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0_________________________________________________________________dropout_2 (Dropout) (None, 16, 16, 64) 0_________________________________________________________________batch_normalization_2 (Batch (None, 16, 16, 64) 256_________________________________________________________________conv2d_3 (Conv2D) (None, 16, 16, 64) 36928_________________________________________________________________activation_3 (Activation) (None, 16, 16, 64) 0_________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0_________________________________________________________________dropout_3 (Dropout) (None, 8, 8, 64) 0_________________________________________________________________batch_normalization_3 (Batch (None, 8, 8, 64) 256_________________________________________________________________conv2d_4 (Conv2D) (None, 8, 8, 128) 73856_________________________________________________________________activation_4 (Activation) (None, 8, 8, 128) 0_________________________________________________________________dropout_4 (Dropout) (None, 8, 8, 128) 0_________________________________________________________________batch_normalization_4 (Batch (None, 8, 8, 128) 512_________________________________________________________________flatten_1 (Flatten) (None, 8192) 0_________________________________________________________________dropout_5 (Dropout) (None, 8192) 0_________________________________________________________________dense_1 (Dense) (None, 256) 2097408_________________________________________________________________activation_5 (Activation) (None, 256) 0_________________________________________________________________dropout_6 (Dropout) (None, 256) 0_________________________________________________________________batch_normalization_5 (Batch (None, 256) 1024_________________________________________________________________dense_2 (Dense) (None, 128) 32896_________________________________________________________________activation_6 (Activation) (None, 128) 0_________________________________________________________________dropout_7 (Dropout) (None, 128) 0_________________________________________________________________batch_normalization_6 (Batch (None, 128) 512_________________________________________________________________dense_3 (Dense) (None, 10) 1290_________________________________________________________________activation_7 (Activation) (None, 10) 0=================================================================Total params: 2,264,458Trainable params: 2,263,114Non-trainable params: 1,344Nyt pääsemme harjoittelemaan mallia. Tätä varten meidän tarvitsee vain kutsua mallin fit()-funktiota ja syöttää valitut parametrit.
Tässä kohtaa käytän valitsemaani siementä toistettavuuden vuoksi.
numpy.random.seed(seed)model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)Koulutamme 50000 näytteellä ja validoimme 10000 näytteellä.
Tämän koodinpätkän suorittaminen antaa tulokseksi:
Epoch 1/2564/50000 - ETA: 16:57 - loss: 3.1479 - acc: 0.0938128/50000 - ETA: 10:12 - loss: 3.0212 - acc: 0.0938192/50000 - ETA: 7:57 - loss: 2.9781 - acc: 0.1250256/50000 - ETA: 6:48 - loss: 2.8830 - acc: 0.1484320/50000 - ETA: 6:07 - loss: 2.8878 - acc: 0.1469384/50000 - ETA: 5:40 - loss: 2.8732 - acc: 0.1458448/50000 - ETA: 5:20 - loss: 2.8842 - acc: 0.1406.........49664/50000 - ETA: 1s - loss: 1.5160 - acc: 0.461149728/50000 - ETA: 1s - loss: 1.5157 - acc: 0.461249792/50000 - ETA: 1s - loss: 1.5153 - acc: 0.461449856/50000 - ETA: 0s - loss: 1.5147 - acc: 0.461549920/50000 - ETA: 0s - loss: 1.5144 - acc: 0.461749984/50000 - ETA: 0s - loss: 1.5141 - acc: 0.461750000/50000 - 262s 5ms/step - loss: 1.5140 - acc: 0.4618 - val_loss: 1.0715 - val_acc: 0.6195End of Epoch 1Huomaa, että useimmissa tapauksissa haluaisit validointijoukon, joka eroaa testausjoukosta, joten määrittelisit prosentuaalisen osuuden harjoitusdatasta validointijoukkona käytettäväksi. Tässä tapauksessa annamme vain testidatan, jotta varmistetaan, että testidata asetetaan syrjään eikä sitä kouluteta. Tässä esimerkissä meillä on vain testidataa, jotta asiat pysyvät yksinkertaisina.
Nyt voimme arvioida mallia ja katsoa, miten se toimi. Kutsumme vain model.evaluate():
# Model evaluationscores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%" % (scores*100))Ja meitä tervehtii tulos:
Accuracy: 83.01%Ja se on siinä! Meillä on nyt koulutettu kuvantunnistus-CNN. Ei hassummin ensimmäiseksi ajokerraksi, mutta haluaisit luultavasti leikkiä mallin rakenteella ja parametreilla nähdäksesi, etkö saisi parempaa suorituskykyä.
Johtopäätökset
Nyt kun olet toteuttanut ensimmäisen kuvantunnistusverkkosi Kerasilla, olisi hyvä idea leikkiä mallin kanssa ja katsoa, miten sen parametrien muuttaminen vaikuttaa sen suorituskykyyn.
Siten saat jonkinlaista intuitiota parhaista valinnoista mallin eri parametreille. Kannattaa myös lukea samalla eri parametri- ja hyperparametrivalinnoista. Kun olet tutustunut näihin, voit kokeilla oman kuvaluokittimesi toteuttamista eri aineistolle.
Jos haluat leikkiä koodilla tai vain tutkia sitä hieman syvällisemmin, projekti on ladattu GitHubiin!