
Jeg laver en masse Twitch-relaterede projekter her og der, og prøver at se, hvilke muligheder der er. Et af mine seneste projekter involverede oprettelse af en Twitch Emote Extension til Chrome, hvor jeg viste, hvordan man gratis kan få ekstra emote “slots”. Det fik mig ind i browserudvidelser, så jeg tænkte, at jeg ville vise, hvordan man laver en fra bunden ved at bygge et profanitetsfilter til Twitch-chatten.
I slutningen af dette vil vi have en udvidelse, der, når den er installeret, tjekker for et sæt af markerede ord i chatten og erstatter dem med mere venlige versioner. Dette kunne f.eks. være nyttigt for børn, der ser streams.
Hvis du bare vil have koden til denne udvidelse, er der et link til slutresultatet nederst i denne artikel.
Okay, så lad os gå i gang med det med hovedet først. Opret en mappe et sted, du vil, og kald den profanity-filter. Jeg oprettede min et sted, hvor jeg synkroniserer med GitHub.

Nu skal du inde i denne mappe oprette to nye filer: manifest.json og content.js. Du vil se, hvordan vi vil bruge dem, når vi kommer til at bygge udvidelsen.
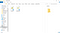
Åbn manifest.json, som er den fil, Google kigger på for metadata vedrørende din udvidelse, og indsæt følgende i den:
{ "manifest_version": 2, "name": "Twitch Profanity Filter Extension", "version": "0.1", "content_scripts": , "js": } ]}
Som du kan se, fortæller vi Google, at denne udvidelse skal fungere på enhver side fra Twitch, og vi siger også, at den logik, der skal køres på disse sider, befinder sig i filen kaldet content.js. Bemærk, at jeg har sat versionen som 0.1, da dette er mit første forsøg.
Få logikken ind
Åbn nu content.js i en teksteditor efter eget valg. Jeg vil stærkt anbefale Visual Studio Code, det er min go-to teksteditor til alt kodning relateret, og det er gratis.
Nu skal vi sætte dette op i et par trin. Hvad ønsker vi at opnå, og hvordan vil vi opnå det? Vi ved, at vi ønsker at ændre visse ord til andre, hvilket betyder, at vi skal læse chatbeskederne, scanne dem for markerede ord og derefter opdatere disse ord til mere venlige ord. Så når siden indlæses, vil vi have, at vores logik skal kunne gøre følgende:
- Find chatboksen
- Hent hver gang en ny chatbesked vises, hent beskeden eller beskedcontaineren
- Opnå ændrede markerede ord til deres venlige modstykker
Så lad os komme i gang. Den første del er faktisk at aktivere scriptet, når siden, eller mere specifikt vinduet, er blevet indlæst. I javascript kan man hooke sig ind i denne loading event, og det vil vi gøre netop det. Opdater din content.js, så den indeholder følgende:
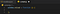
Det vil sikre, at hvad vi end sætter ind i den funktion, bliver kaldt, når siden er indlæst.
Find chatboxen
Så hvordan finder vi chatboxen? Tja, i Chrome-versionen af Twitch-webstedet er chatboksen indeholdt i et <div>-element, der har en klasse kaldet chat-scrolllable-area__message-container. Vi skal hente dette element, eller node, via javascript. Opdater filen, så den ser således ud:

Grunden til, at vi tilføjer .item(0) bagved, er, at getElementsByClassName() returnerer et array af elementer. Da vi ved, at kun ét element har denne klasse, tager vi det fra arrayet ved at angive, at vi vil have den første ting (de fleste programmeringssprog begynder at tælle ved 0).
Hent hver ny besked i chatten
Dette er lidt mere tricky at forstå, hvis man ikke er vant til programmering eller ikke er vant til observatørmønstre. Måden vi vil få hver ny besked på er ved at bruge en MutationObserver på chatbox-noden, som vi lige har hentet. Opdater filen, så den passer til følgende, og så vil vi gennemgå, hvad der foregår:
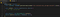
Først, på linje 4, definerer vi en callback-funktion, der tager en liste af mutationer og den observatør, vi opretter på linje 8. Logikken i denne funktion er det, der bliver kaldt, når der sker ændringer eller mutationer i den node, vi observerer.
I linje 8 opretter vi observatøren og giver den vores callback-funktion. Derefter fortæller vi i linje 9 observatøren, at den skal begynde at observere vores målknude, og vi videregiver en konfiguration, der siger, at vi kun er interesseret i mutationer i childList. Meddelelser vises som underordnede noder i den chatbox-knude, vi ser på, så vores callback-funktion vil blive udløst, hver gang en ny chat-meddelelse vises. Det er præcis, hvad vi ønsker!
Men nu har vi stadig brug for at få de faktiske beskedelementer, og til det tilføjer vi endnu en kodelinje i vores callback:
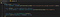
Navnet virker måske lidt underligt, men alle tekstdele i en besked (vi scanner ikke emotes, kun de faktiske tekster) placeres i <span> HTML-elementer, der har klassen text-fragment. Fordi denne funktion udløses ved hver ny besked, ved vi også, at den besked, vi vil have, skal være det sidste element i chatbox-knuden, så det er derfor, vi tager fat i lastElementChild.
Omskifter markerede ord til deres venlige modstykker
Lad os komme til den saftige del. Hvis vi vil ændre markerede ord, har vi først brug for noget, der fortæller os, hvad markerede ord og deres modstykker er. Det gør vi ved at bruge en simpel ordbog. Opdater filen, så den ser således ud:
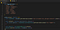
Nu skal vi læse den faktiske tekst i alle tekstfragmentelementerne, løbe over alle forbudte ord og erstatte dem om nødvendigt. Lad os få den sløjfe i gang, så opdater din callback-funktion med følgende:

Det, der sker her, er, at vi løber gennem alle disse elementer, der indeholder tekst. På linje 18 tager vi et specifikt element ad gangen, og på linje 19 får vi den faktiske tekst fra det i små bogstaver, fordi vores markerede ord også alle er i små bogstaver. Det gør det nemmere for sammenligningsformål, men i en mere avanceret version ville vi sørge for at opretholde kasetteringen på en pæn måde. Nu, hvor vi har vores tekst, vil vi gerne køre en løkke over vores markerede ord og kontrollere, om de er til stede. Hvis det er tilfældet, sletter vi dem. Opdater funktionen:

Den ordbog, vi lavede, fungerer med nøgle-værdipar, hvor nøglerne er de markerede ord og værdierne er de venlige ord, så i linje 21 får vi simpelthen et array af alle nøglerne, som er arrayet af markerede ord, som vi ønsker at løbe over. I sløjfen henter vi det markerede ord, som vi ser på i øjeblikket, og hvis vores tekst indeholder et eller flere af dem, henter vi det venlige ord og opdaterer vores tekst ved at erstatte de markerede ord. Det er næsten det hele, nu skal vi bare tage vores nye og forbedrede tekst og sætte den tilbage i det element vi tog den fra:

I linje 31 har vi nu sat teksten tilbage i elementet, og det er det! Lad os komme i gang med at teste dette i Chrome.
Testen
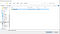
Åbn Chrome, og gå til chrome://extensions. Du bør se dine udvidelser, og øverst til højre vil du se Developer mode (udviklertilstand). Slå den til, hvis den ikke er det endnu. Herefter vil du i øverste højre hjørne se indstillingen Indlæs udpakket. Vi vil bruge den til at indlæse vores lokale udvidelse uden at skulle gå gennem Chrome Web Store-ruten endnu. Klik på den og vælg den mappe, hvor filerne ligger:
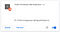
Det skulle få den til at dukke op med det samme i vores udvidelsesliste:
Godt! Lad os nu gå over til en hvilken som helst kanal, hvor vi kan chatte. Jeg går ind på min ven Bjarkes kanal, en hylende morsom dansk streamer, og prøver det af:

Sådan, det virker! Vores helt eget filter for blasfemi. Det var ikke så svært, vel? Det eneste, der er tilbage, er at frigive det til Chrome Web Store, hvis du har lyst til det. Jeg vil udvide denne liste af ord og frigive dette, så hvis du ikke har brug for mere end dette, behøver du ikke at frigive det, da det kræver et gebyr for at komme ind i programmet. Jeg vil ikke gå ind i hvordan udgivelsen fungerer, men hvis du er interesseret, har jeg lavet en Twitch Emote Extension for at få dine egne ubegrænsede emote slots, og denne artikel forklarer hvordan man udgiver udvidelser til sidst.
Hvis du vil se al koden til denne udvidelse, kan du tjekke GitHub repo’en her. Glædelig kodning!