- Indledning
- Definitioner
- TensorFlow/Keras
- Billedgenkendelse (klassifikation)
- Feature Extraction
- Hvordan neurale netværk lærer at genkende billeder
- Feature Extraction With Filters
- Aktiveringsfunktioner
- Poolinglag
- Flattening
- Fuldt forbundne lag
- Arbejdsgangen for maskinlæring
- Dataforberedelse
- Skabelse af modellen
- Træning af modellen
- Modelevaluering
- Billedgenkendelse med CNN
- Forberedelse af dataene
- Design af modellen
- Opret modellen
- Slutning
Indledning
En af de mest almindelige anvendelser af TensorFlow og Keras er genkendelse/klassificering af billeder. Hvis du vil lære at bruge Keras til at klassificere eller genkende billeder, vil denne artikel lære dig hvordan.
Definitioner
Hvis du ikke er klar over de grundlæggende begreber bag billedgenkendelse, vil det være svært at forstå resten af denne artikel helt. Så før vi går videre, skal vi tage et øjeblik til at definere nogle begreber.
TensorFlow/Keras

Kredit: commons.wikimedia.org
TensorFlow er et open source-bibliotek skabt til Python af Google Brain-teamet. TensorFlow samler mange forskellige algoritmer og modeller sammen, hvilket gør det muligt for brugeren at implementere dybe neurale netværk til brug i opgaver som billedgenkendelse/klassifikation og naturlig sprogbehandling. TensorFlow er en kraftfuld ramme, der fungerer ved at implementere en række behandlingsknuder, hvor hver knude repræsenterer en matematisk operation, og hvor hele rækken af knuder kaldes en “graf”.
Med hensyn til Keras er det en API (applikationsprogrammeringsgrænseflade) på højt niveau, der kan bruge TensorFlows funktioner nedenunder (samt andre ML-biblioteker som Theano). Keras blev designet med brugervenlighed og modularitet som ledende principper. I praksis gør Keras implementeringen af de mange kraftfulde, men ofte komplekse funktioner i TensorFlow så enkel som muligt, og det er konfigureret til at fungere med Python uden større ændringer eller konfiguration.
Billedgenkendelse (klassifikation)
Billedgenkendelse henviser til opgaven med at indtaste et billede i et neuralt netværk og få det til at output en form for etiket for dette billede. Den etiket, som netværket udsender, vil svare til en foruddefineret klasse. Der kan være flere klasser, som billedet kan mærkes som, eller der kan kun være én. Hvis der er tale om en enkelt klasse, anvendes ofte udtrykket “genkendelse”, mens en genkendelsesopgave med flere klasser ofte kaldes “klassificering”.
En delmængde af billedklassificering er objektdetektion, hvor specifikke forekomster af objekter identificeres som tilhørende en bestemt klasse som f.eks. dyr, biler eller mennesker.
Feature Extraction
For at kunne udføre billedgenkendelse/klassificering skal det neurale netværk udføre feature extraction. Funktioner er de elementer i de data, som du interesserer dig for, og som vil blive ført gennem netværket. I det specifikke tilfælde af billedgenkendelse er funktionerne de grupper af pixels, som f.eks. kanter og punkter, i et objekt, som netværket vil analysere for mønstre.
Funktioner genkendelse (eller funktionsekstraktion) er processen med at trække de relevante funktioner ud af et indgangsbillede, således at disse funktioner kan analyseres. Mange billeder indeholder annotationer eller metadata om billedet, som hjælper netværket med at finde de relevante funktioner.
Hvordan neurale netværk lærer at genkende billeder
Det vil hjælpe dig at få en fornemmelse af, hvordan et neuralt netværk genkender billeder, når du skal implementere en neuronal netværksmodel, så lad os kort udforske billedgenkendelsesprocessen i de næste par afsnit.
Feature Extraction With Filters
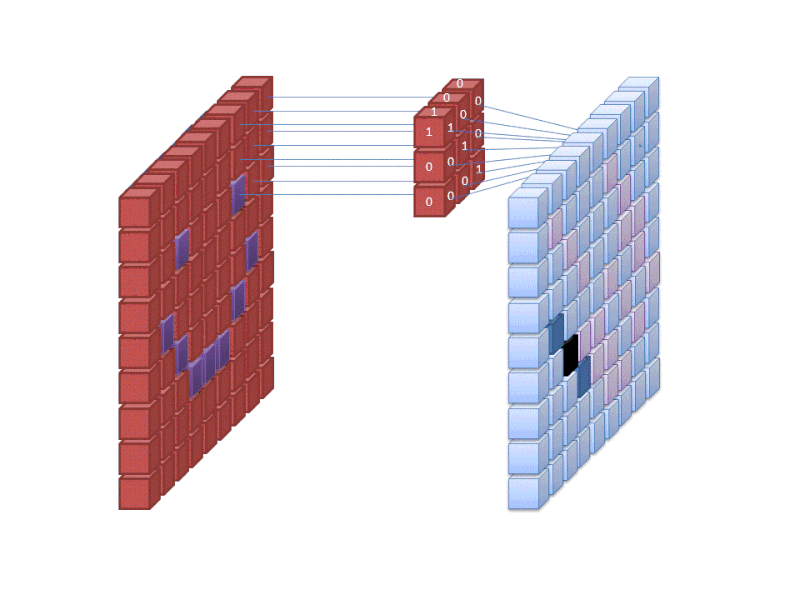
Kredit: commons.wikimedia.org
Det første lag af et neuralt netværk tager alle pixels i et billede ind. Når alle dataene er blevet ført ind i netværket, anvendes forskellige filtre på billedet, som danner repræsentationer af forskellige dele af billedet. Dette er feature ekstraktion, og det skaber “feature maps”.
Denne proces med at udtrække features fra et billede udføres med et “convolutional layer”, og convolution er simpelthen at danne en repræsentation af en del af et billede. Det er fra dette konvolutionskoncept, at vi får udtrykket Convolutional Neural Network (CNN), den type neurale netværk, der oftest anvendes til billedklassifikation/genkendelse.
Hvis du vil visualisere, hvordan det fungerer at skabe feature maps, så tænk på at lyse med en lommelygte over et billede i et mørkt rum. Når du fører strålen hen over billedet, lærer du om billedets egenskaber. Et filter er det, netværket bruger til at danne en repræsentation af billedet, og i denne metafor er lyset fra lommelygten filteret.
Bredden af din lommelygts stråle styrer, hvor meget af billedet du undersøger på én gang, og neurale netværk har en lignende parameter, nemlig filterstørrelsen. Filterstørrelsen påvirker, hvor stor en del af billedet, hvor mange pixels, der undersøges på én gang. En almindelig filterstørrelse, der anvendes i CNN’er, er 3, og dette dækker både højde og bredde, så filteret undersøger et 3 x 3 område af pixels.
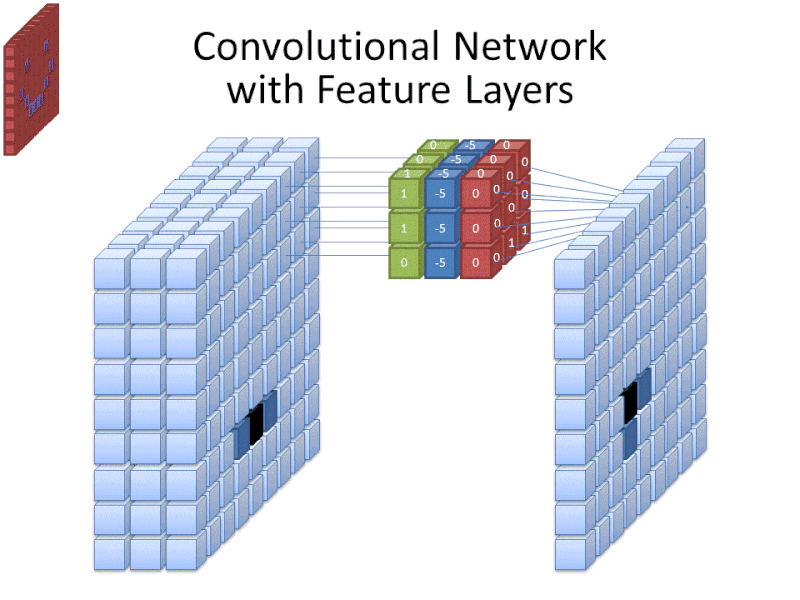
Kredit: commons.wikimedia.org
Mens filterstørrelsen dækker filterets højde og bredde, skal filterets dybde også angives.
Hvordan har et 2D-billede dybde?
Digitale billeder gengives som højde, bredde og en eller anden RGB-værdi, der definerer pixelens farver, så den “dybde”, der spores, er antallet af farvekanaler, som billedet har. Gråskala (ikke-farve) billeder har kun 1 farvekanal, mens farvebilleder har 3 dybdekanaler.
Alt dette betyder, at for et filter af størrelse 3, der anvendes på et fuldfarvebillede, vil filterets dimensioner være 3 x 3 x 3 x 3. For hver pixel, der er dækket af dette filter, multiplicerer netværket filterværdierne med værdierne i selve pixlerne for at få en numerisk repræsentation af den pågældende pixel. Denne proces gentages derefter for hele billedet for at opnå en fuldstændig repræsentation. Filteret flyttes hen over resten af billedet i henhold til en parameter kaldet “stride”, som definerer, hvor mange pixels filteret skal flyttes med, efter at det har beregnet værdien i sin nuværende position. En konventionel stride-størrelse for en CNN er 2.
Det endelige resultat af alle disse beregninger er et feature map. Denne proces udføres typisk med mere end ét filter, hvilket er med til at bevare billedets kompleksitet.
Aktiveringsfunktioner
Når feature mapet af billedet er blevet oprettet, sendes de værdier, der repræsenterer billedet, gennem en aktiveringsfunktion eller et aktiveringslag. Aktiveringsfunktionen tager værdier, der repræsenterer billedet, som er i en lineær form (dvs. blot en liste af tal) takket være det konvolutionelle lag, og øger deres ikke-linearitet, da billeder i sig selv er ikke-lineære.
Den typiske aktiveringsfunktion, der anvendes til at opnå dette, er en Rectified Linear Unit (ReLU), selv om der er nogle andre aktiveringsfunktioner, der lejlighedsvis anvendes (du kan læse om dem her).
Poolinglag
Når dataene er aktiveret, sendes de gennem et poolinglag. Pooling “downsamples” et billede, hvilket betyder, at det tager de oplysninger, der repræsenterer billedet, og komprimerer dem, så de bliver mindre. Pooling-processen gør netværket mere fleksibelt og dygtigere til at genkende objekter/billeder baseret på de relevante træk.
Når vi ser på et billede, er vi typisk ikke optaget af alle oplysningerne i baggrunden af billedet, men kun af de træk, som vi interesserer os for, f.eks. mennesker eller dyr.
På samme måde vil et poolinglag i et CNN abstrahere de unødvendige dele af billedet og kun beholde de dele af billedet, som det mener er relevante, hvilket styres af den angivne størrelse af poolinglaget.
Da det skal træffe beslutninger om de mest relevante dele af billedet, er håbet, at netværket kun lærer de dele af billedet, der virkelig repræsenterer det pågældende objekt. Dette er med til at forhindre overfitting, hvor netværket lærer aspekter af træningstilfældet for godt og ikke formår at generalisere til nye data.
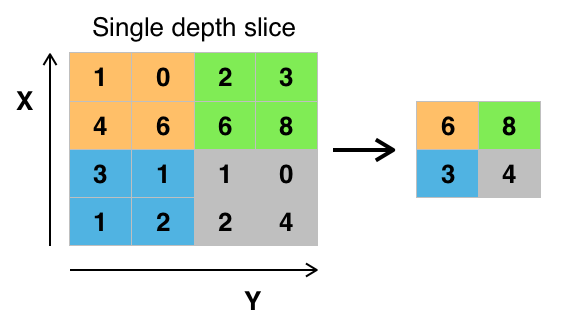
Kredit: commons.wikimedia.org
Der er forskellige måder at pulje værdier på, men max pooling er det mest almindeligt anvendte. Max pooling opnår den maksimale værdi af pixelerne inden for et enkelt filter (inden for et enkelt sted i billedet). Herved bortfalder 3/4 af oplysningerne, hvis man antager, at der anvendes 2 x 2 filtre.
Pixelernes maksimale værdier anvendes for at tage højde for eventuelle billedforvrængninger, og billedets parametre/størrelse reduceres for at kontrollere for overpasning. Der findes andre pooling-typer såsom average pooling eller sum pooling, men disse anvendes ikke så hyppigt, fordi max pooling har tendens til at give bedre nøjagtighed.
Flattening
De sidste lag i vores CNN, de tæt forbundne lag, kræver, at dataene er i form af en vektor, der skal behandles. Af denne grund skal dataene “flattened”. Værdierne komprimeres til en lang vektor eller en kolonne af sekventielt ordnede tal.
Fuldt forbundne lag
De sidste lag i CNN er tæt forbundne lag, eller et kunstigt neuralt netværk (ANN). ANN’s primære funktion er at analysere de indgående funktioner og kombinere dem til forskellige attributter, der vil hjælpe med klassificeringen. Disse lag danner i det væsentlige samlinger af neuroner, der repræsenterer forskellige dele af det pågældende objekt, og en samling af neuroner kan repræsentere en hunds fløjlsøre eller et æbles rødme. Når tilstrækkeligt mange af disse neuroner aktiveres som reaktion på et indgangsbillede, vil billedet blive klassificeret som et objekt.

Kredit: commons.wikimedia.org
Den fejl, eller forskellen mellem de beregnede værdier og den forventede værdi i træningssættet, beregnes af ANN’en. Netværket gennemgår derefter backpropagation, hvor en given neurons indflydelse på en neuron i det næste lag beregnes, og dens indflydelse justeres. Dette gøres for at optimere modellens ydeevne. Denne proces gentages derefter igen og igen. På denne måde træner netværket på data og lærer associationer mellem inputfunktioner og outputklasser.
Neuronerne i de midterste fuldt forbundne lag vil outputte binære værdier i forbindelse med de mulige klasser. Hvis der er fire forskellige klasser (lad os sige en hund, en bil, et hus og en person), vil neuronet have en “1”-værdi for den klasse, det mener, at billedet repræsenterer, og en “0”-værdi for de andre klasser.
Det sidste fuldt forbundne lag vil modtage output fra det foregående lag og levere en sandsynlighed for hver af klasserne, der summeres til en. Hvis der er en værdi på 0,75 i kategorien “hund”, repræsenterer det en sikkerhed på 75 % for, at billedet er en hund.
Billedklassificatoren er nu blevet trænet, og billederne kan sendes ind i CNN’en, som nu vil udstede et gæt om indholdet af det pågældende billede.
Arbejdsgangen for maskinlæring
Hvor vi hopper ind i et eksempel på træning af en billedklassificator, skal vi bruge et øjeblik på at forstå arbejdsgangen eller pipelinen for maskinlæring. Processen for træning af en neurale netværksmodel er ret standard og kan opdeles i fire forskellige faser.
Dataforberedelse
Først skal du indsamle dine data og lægge dem i en form, som netværket kan træne på. Dette indebærer indsamling af billeder og mærkning af dem. Selv hvis du har downloadet et datasæt, som en anden har udarbejdet, vil der sandsynligvis være en forbehandling eller forberedelse, som du skal foretage, før du kan bruge det til træning. Forberedelse af data er en kunst i sig selv, der indebærer håndtering af ting som manglende værdier, beskadigede data, data i det forkerte format, forkerte etiketter osv.
I denne artikel vil vi bruge et forbehandlet datasæt.
Skabelse af modellen
Skabelsen af modellen for det neurale netværk indebærer, at der skal træffes valg om forskellige parametre og hyperparametre. Du skal træffe beslutninger om antallet af lag, der skal bruges i din model, hvad lagrenes input- og outputstørrelser skal være, hvilken type aktiveringsfunktioner du vil bruge, om du vil bruge dropout eller ej osv.
Læringen af, hvilke parametre og hyperparametre du skal bruge, vil komme med tiden (og en masse studier), men lige fra starten er der nogle heuristikker, du kan bruge for at komme i gang, og vi vil dække nogle af disse under implementeringseksemplet.
Træning af modellen
Når du har oprettet din model, opretter du simpelthen en instans af modellen og tilpasser den med dine træningsdata. Den største overvejelse, når du træner en model, er, hvor lang tid det tager at træne modellen. Du kan angive længden af træningstiden for et netværk ved at angive antallet af epokeringer, der skal trænes over. Jo længere tid du træner en model, jo mere vil dens ydeevne blive forbedret, men for mange træningsepoke, og du risikerer overtilpasning.
Det er noget, du får en fornemmelse for at vælge antallet af epokers til træning, og det er almindeligt at gemme vægtene i et netværk mellem træningssessionerne, så du ikke behøver at starte forfra, når du har gjort fremskridt med at træne netværket.
Modelevaluering
Der er flere trin i evalueringen af modellen. Det første trin i evalueringen af modellen er at sammenligne modellens ydeevne med et valideringsdatasæt, et datasæt, som modellen ikke er blevet trænet på. Du sammenligner modellens ydeevne med dette valideringsdatasæt og analyserer dens ydeevne ved hjælp af forskellige målinger.
Der findes forskellige målinger til bestemmelse af en neurale netværksmodels ydeevne, men den mest almindelige måling er “nøjagtighed”, dvs. antallet af korrekt klassificerede billeder divideret med det samlede antal billeder i dit datasæt.
Når du har set nøjagtigheden af modellens ydeevne på et valideringsdatasæt, vil du typisk gå tilbage og træne netværket igen med let justerede parametre, fordi det er usandsynligt, at du er tilfreds med dit netværks ydeevne første gang, du træner. Du vil blive ved med at justere parametrene for dit netværk, træne det igen og måle dets ydeevne, indtil du er tilfreds med netværkets nøjagtighed.
Sidst tester du netværkets ydeevne på et testsæt. Dette testsæt er et andet sæt data, som din model aldrig har set før.
Måske undrer du dig over:
Hvorfor gider du bruge testsæt? Hvis du får en idé om din models nøjagtighed, er det så ikke formålet med valideringssættet?
Det er en god idé at beholde et parti data, som netværket aldrig har set, til testning, fordi alle de justeringer af parametrene, du foretager, kombineret med den fornyede testning på valideringssættet, kan betyde, at dit netværk har lært nogle idiosynkrasier ved valideringssættet, som ikke vil kunne generaliseres til data uden for stikprøven.
Det er derfor formålet med testsættene at kontrollere for problemer som overtilpasning og være mere sikker på, at din model virkelig er egnet til at fungere i den virkelige verden.
Billedgenkendelse med CNN
Vi har dækket en masse indtil videre, og hvis alle disse oplysninger har været lidt overvældende, bør det at se disse begreber blive samlet i en prøveklassificator, der er trænet på et datasæt, gøre dem mere konkrete. Så lad os se på et fuldstændigt eksempel på billedgenkendelse med Keras, fra indlæsning af data til evaluering.

Kredit: www.cs.toronto.edu
Til at begynde med har vi brug for et datasæt at træne på. I dette eksempel vil vi bruge det berømte CIFAR-10-datasæt. CIFAR-10 er et stort billeddatasæt, der indeholder over 60.000 billeder, der repræsenterer 10 forskellige klasser af objekter som katte, fly og biler.
Billederne er RGB-billeder i fuld farve, men de er ret små, kun 32 x 32. En god ting ved CIFAR-10-datasættet er, at det leveres færdigpakket med Keras, så det er meget nemt at indlæse datasættet, og billederne kræver meget lidt forbehandling.
Den første ting, vi skal gøre, er at importere de nødvendige biblioteker. Jeg vil vise, hvordan disse importer bruges efterhånden, men indtil videre ved du, at vi vil gøre brug af Numpy og forskellige moduler, der er forbundet med Keras:
import numpyfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activationfrom keras.layers.convolutional import Conv2D, MaxPooling2Dfrom keras.constraints import maxnormfrom keras.utils import np_utilsVi vil bruge et tilfældigt frø her, så de resultater, der opnås i denne artikel, kan replikeres af dig, hvorfor vi har brug for numpy:
# Set random seed for purposes of reproducibilityseed = 21Forberedelse af dataene
Vi har brug for endnu en import: datasættet.
from keras.datasets import cifar10Nu skal vi indlæse datasættet. Det kan vi ganske enkelt gøre ved at angive, hvilke variabler vi vil indlæse dataene i, og derefter bruge funktionen load_data():
# loading in the data (X_train, y_train), (X_test, y_test) = cifar10.load_data()I de fleste tilfælde skal du foretage en vis forbehandling af dine data for at gøre dem klar til brug, men da vi bruger et prepackaged datasæt, er det meget lidt forbehandling, der skal foretages. En ting, vi ønsker at gøre, er at normalisere inputdataene.
Hvis værdierne i inputdataene ligger i et for stort interval kan det have en negativ indvirkning på, hvordan netværket præsterer. I dette tilfælde er inputværdierne pixelerne i billedet, som har en værdi mellem 0 og 255.
Så for at normalisere dataene kan vi simpelthen dividere billedværdierne med 255. For at gøre dette skal vi først gøre dataene til en float-type, da de i øjeblikket er hele tal. Det kan vi gøre ved at bruge kommandoen astype() Numpy og derefter erklære, hvilken datatype vi ønsker:
# normalize the inputs from 0-255 to between 0 and 1 by dividing by 255 X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = X_train / 255.0X_test = X_test / 255.0En anden ting, vi skal gøre for at gøre dataene klar til netværket, er at one-hot-kode værdierne. Jeg vil ikke gå ind i detaljerne om one-hot-kodning her, men ved nu, at billederne ikke kan bruges af netværket, som de er, de skal kodes først, og one-hot-kodning bruges bedst, når man laver binær klassifikation.
Vi laver faktisk binær klassifikation her, fordi et billede enten hører til en klasse eller ej, det kan ikke falde et sted midt imellem. Numpy-kommandoen to_categorical() bruges til one-hot-kodning. Det er derfor, vi importerede np_utils-funktionen fra Keras, da den indeholder to_categorical().
Vi skal også angive antallet af klasser, der er i datasættet, så vi ved, hvor mange neuroner vi skal komprimere det sidste lag ned til:
# one hot encode outputsy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)class_num = y_test.shapeDesign af modellen
Vi er nået til det stadie, hvor vi designer CNN-modellen. Det første, vi skal gøre, er at definere det format, vi ønsker at bruge til modellen, Keras har flere forskellige formater eller blueprints til at bygge modeller på, men Sequential er det mest almindeligt anvendte, og derfor har vi importeret det fra Keras.
Opret modellen
model = Sequential()Det første lag i vores model er et konvolutionelt lag. Det vil tage imod input og køre konvolutionelle filtre på dem.
Når vi implementerer disse i Keras, skal vi angive antallet af kanaler/filtre, vi ønsker (det er de 32 nedenfor), størrelsen af det filter, vi ønsker (3 x 3 i dette tilfælde), inputformen (når vi opretter det første lag) og den aktivering og padding, vi har brug for.
Som nævnt er relu den mest almindelige aktivering, og padding='same' betyder bare, at vi slet ikke ændrer størrelsen på billedet:
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape, padding='same'))model.add(Activation('relu'))Notat: Du kan også kæde aktiveringerne og polstringerne sammen, som her:
model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), activation='relu', padding='same'))Nu vil vi lave et dropout-lag for at forhindre overfitting, som fungerer ved tilfældigt at fjerne nogle af forbindelserne mellem lagene (0.2 betyder, at den fjerner 20 % af de eksisterende forbindelser):
model.add(Dropout(0.2))Vi ønsker måske også at foretage en batch-normalisering her. Batch Normalization normaliserer indgangene på vej ind i det næste lag, hvilket sikrer, at netværket altid skaber aktiveringer med den samme fordeling, som vi ønsker:
model.add(BatchNormalization())Nu kommer endnu et konvolutionelt lag, men filterstørrelsen øges, så netværket kan lære mere komplekse repræsentationer:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))Her er pooling laget, som diskuteret før dette hjælper med at gøre billedklassificatoren mere robust, så den kan lære relevante mønstre. Der er også dropout- og batch-normalisering:
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization())Det er det grundlæggende flow for den første halvdel af en CNN-implementering: Convolutional, aktivering, dropout, pooling. Du kan nu se, hvorfor vi har importeret Dropout, BatchNormalization, Activation, Conv2d og MaxPooling2d.
Du kan variere det nøjagtige antal konvolutionelle lag efter din smag, selv om hvert lag tilføjer flere beregningsudgifter. Bemærk, at når du tilføjer konvolutionelle lag, øger du typisk deres antal filtre, så modellen kan lære mere komplekse repræsentationer. Hvis de valgte tal for disse lag virker noget arbitrært, skal du blot vide, at du generelt øger filtrene efterhånden som du fortsætter, og det anbefales at gøre dem til potenser af 2, hvilket kan give en lille fordel ved træning på en GPU.
Det er vigtigt ikke at have for mange poolinglag, da hver pooling kasserer nogle data. Hvis du puljer for ofte, vil det føre til, at der næsten ikke er noget for de tæt forbundne lag at lære om, når dataene når frem til dem.
Det nøjagtige antal poolinglag, du bør bruge, varierer afhængigt af den opgave, du udfører, og det er noget, du får en fornemmelse for over tid. Da billederne er så små her allerede, vil vi ikke pulje mere end to gange.
Du kan nu gentage disse lag for at give dit netværk flere repræsentationer at arbejde ud fra:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Når vi er færdige med de konvolutionelle lag, skal vi Flatten dataene, hvilket er grunden til, at vi importerede funktionen ovenfor. Vi tilføjer også et dropout-lag igen:
model.add(Flatten())model.add(Dropout(0.2))Nu gør vi brug af Dense importen og opretter det første tæt forbundne lag. Vi skal angive antallet af neuroner i det tætte lag. Bemærk, at antallet af neuroner i de efterfølgende lag falder og til sidst nærmer sig det samme antal neuroner, som der er klasser i datasættet (i dette tilfælde 10). Kernebegrænsningen kan regulere dataene, efterhånden som den lærer, hvilket også er med til at forhindre overtilpasning. Dette er grunden til, at vi importerede maxnorm tidligere.
model.add(Dense(256, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Dense(128, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())I dette sidste lag indsender vi antallet af klasser for antallet af neuroner. Hver neuron repræsenterer en klasse, og outputtet fra dette lag vil være en vektor med 10 neuroner, hvor hver neuron lagrer en vis sandsynlighed for, at det pågældende billede tilhører den klasse, den repræsenterer.
Slutteligt vælger softmax-aktiveringsfunktionen den neuron med den højeste sandsynlighed som output, hvilket stemmer for, at billedet tilhører den pågældende klasse:
model.add(Dense(class_num))model.add(Activation('softmax'))Nu har vi designet den model, vi vil bruge, og vi skal bare kompilere den. Lad os angive antallet af epokerne, vi ønsker at træne i, samt den optimizer, vi ønsker at bruge.
Optimeren er det, der vil afstemme vægtene i dit netværk for at nærme sig det punkt med det laveste tab. Adam-algoritmen er en af de mest almindeligt anvendte optimizere, fordi den giver god ydelse på de fleste problemer:
epochs = 25optimizer = 'adam'Lad os nu kompilere modellen med vores valgte parametre. Lad os også angive en metrik, der skal bruges:
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=)Vi kan udskrive modeloversigten for at se, hvordan hele modellen ser ud.
print(model.summary())Udskrivningen af oversigten vil give os en hel del info:
Results: Layer (type) Output Shape Param #=================================================================conv2d_1 (Conv2D) (None, 32, 32, 32) 896_________________________________________________________________activation_1 (Activation) (None, 32, 32, 32) 0_________________________________________________________________dropout_1 (Dropout) (None, 32, 32, 32) 0_________________________________________________________________batch_normalization_1 (Batch (None, 32, 32, 32) 128_________________________________________________________________conv2d_2 (Conv2D) (None, 32, 32, 64) 18496_________________________________________________________________activation_2 (Activation) (None, 32, 32, 64) 0_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0_________________________________________________________________dropout_2 (Dropout) (None, 16, 16, 64) 0_________________________________________________________________batch_normalization_2 (Batch (None, 16, 16, 64) 256_________________________________________________________________conv2d_3 (Conv2D) (None, 16, 16, 64) 36928_________________________________________________________________activation_3 (Activation) (None, 16, 16, 64) 0_________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0_________________________________________________________________dropout_3 (Dropout) (None, 8, 8, 64) 0_________________________________________________________________batch_normalization_3 (Batch (None, 8, 8, 64) 256_________________________________________________________________conv2d_4 (Conv2D) (None, 8, 8, 128) 73856_________________________________________________________________activation_4 (Activation) (None, 8, 8, 128) 0_________________________________________________________________dropout_4 (Dropout) (None, 8, 8, 128) 0_________________________________________________________________batch_normalization_4 (Batch (None, 8, 8, 128) 512_________________________________________________________________flatten_1 (Flatten) (None, 8192) 0_________________________________________________________________dropout_5 (Dropout) (None, 8192) 0_________________________________________________________________dense_1 (Dense) (None, 256) 2097408_________________________________________________________________activation_5 (Activation) (None, 256) 0_________________________________________________________________dropout_6 (Dropout) (None, 256) 0_________________________________________________________________batch_normalization_5 (Batch (None, 256) 1024_________________________________________________________________dense_2 (Dense) (None, 128) 32896_________________________________________________________________activation_6 (Activation) (None, 128) 0_________________________________________________________________dropout_7 (Dropout) (None, 128) 0_________________________________________________________________batch_normalization_6 (Batch (None, 128) 512_________________________________________________________________dense_3 (Dense) (None, 10) 1290_________________________________________________________________activation_7 (Activation) (None, 10) 0=================================================================Total params: 2,264,458Trainable params: 2,263,114Non-trainable params: 1,344Nu kommer vi til at træne modellen. For at gøre dette skal vi blot kalde fit()-funktionen på modellen og indtaste de valgte parametre.
Her bruger jeg det frø, jeg har valgt, af hensyn til reproducerbarheden.
numpy.random.seed(seed)model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)Vi træner på 50000 prøver og validerer på 10000 prøver.
Kørsel af dette stykke kode vil give:
Epoch 1/2564/50000 - ETA: 16:57 - loss: 3.1479 - acc: 0.0938128/50000 - ETA: 10:12 - loss: 3.0212 - acc: 0.0938192/50000 - ETA: 7:57 - loss: 2.9781 - acc: 0.1250256/50000 - ETA: 6:48 - loss: 2.8830 - acc: 0.1484320/50000 - ETA: 6:07 - loss: 2.8878 - acc: 0.1469384/50000 - ETA: 5:40 - loss: 2.8732 - acc: 0.1458448/50000 - ETA: 5:20 - loss: 2.8842 - acc: 0.1406.........49664/50000 - ETA: 1s - loss: 1.5160 - acc: 0.461149728/50000 - ETA: 1s - loss: 1.5157 - acc: 0.461249792/50000 - ETA: 1s - loss: 1.5153 - acc: 0.461449856/50000 - ETA: 0s - loss: 1.5147 - acc: 0.461549920/50000 - ETA: 0s - loss: 1.5144 - acc: 0.461749984/50000 - ETA: 0s - loss: 1.5141 - acc: 0.461750000/50000 - 262s 5ms/step - loss: 1.5140 - acc: 0.4618 - val_loss: 1.0715 - val_acc: 0.6195End of Epoch 1Bemærk, at du i de fleste tilfælde ønsker at have et valideringssæt, der er forskelligt fra testsættet, og du vil derfor angive en procentdel af træningsdataene, der skal bruges som valideringssæt. I dette tilfælde overfører vi blot testdataene for at sikre, at testdataene er sat til side og ikke trænes på. Vi vil kun have testdata i dette eksempel for at holde tingene enkle.
Nu kan vi evaluere modellen og se, hvordan den har klaret sig. Vi skal blot kalde model.evaluate():
# Model evaluationscores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%" % (scores*100))Og vi bliver mødt med resultatet:
Accuracy: 83.01%Og det var det! Vi har nu en trænet billedgenkendelses-CNNN. Ikke dårligt for den første kørsel, men du vil sikkert gerne lege lidt med modellens struktur og parametre for at se, om du ikke kan få en bedre ydeevne.
Slutning
Nu, hvor du har implementeret dit første billedgenkendelsesnetværk i Keras, vil det være en god idé at lege lidt med modellen og se, hvordan ændrede parametre påvirker dens ydeevne.
Dette vil give dig en vis intuition om de bedste valg for forskellige modelparametre. Du bør også læse op på de forskellige valg af parametre og hyperparametre, mens du gør det. Når du er fortrolig med disse, kan du prøve at implementere din egen billedklassifikator på et andet datasæt.
Hvis du gerne vil lege med koden eller blot studere den lidt dybere, er projektet uploadet på GitHub!