- Úvod
- Definice
- TensorFlow/Keras
- Rozpoznávání obrázků (klasifikace)
- Extrakce příznaků
- Jak se neuronové sítě učí rozpoznávat obrázky
- Extrakce vlastností pomocí filtrů
- Aktivační funkce
- Sdružovací vrstvy
- Zplošťování
- Plně propojená vrstva
- Pracovní postup strojového učení
- Příprava dat
- Vytvoření modelu
- Trénování modelu
- Vyhodnocení modelu
- Rozpoznávání obrázků pomocí CNN
- Příprava dat
- Návrh modelu
- Vytvoření modelu
- Závěr
Úvod
Jedním z nejčastějších využití TensorFlow a Keras je rozpoznávání/klasifikace obrázků. Pokud se chcete naučit používat Keras ke klasifikaci nebo rozpoznávání obrázků, tento článek vás naučí, jak na to.
Definice
Pokud vám nejsou jasné základní pojmy týkající se rozpoznávání obrázků, bude pro vás obtížné zcela pochopit zbytek tohoto článku. Než tedy budeme pokračovat dále, pojďme si na chvíli definovat některé pojmy.
TensorFlow/Keras

Kredit: commons.wikimedia.org
TensorFlow je open source knihovna vytvořená pro Python týmem Google Brain. TensorFlow sestavuje dohromady mnoho různých algoritmů a modelů a umožňuje uživateli implementovat hluboké neuronové sítě pro použití v úlohách, jako je rozpoznávání/klasifikace obrazu a zpracování přirozeného jazyka. TensorFlow je výkonný framework, který funguje tak, že implementuje řadu výpočetních uzlů, přičemž každý uzel představuje matematickou operaci, přičemž celá řada uzlů se nazývá „graf“.
Pokud jde o Keras, jedná se o vysokoúrovňové API (aplikační programové rozhraní), které může využívat funkce TensorFlow pod sebou (stejně jako další ML knihovny, jako je Theano). Keras byl navržen s ohledem na uživatelskou přívětivost a modularitu jako hlavní zásady. Z praktického hlediska Keras umožňuje co nejjednodušší implementaci mnoha výkonných, ale často složitých funkcí TensorFlow a je nakonfigurován tak, aby pracoval s jazykem Python bez jakýchkoli větších úprav nebo konfigurace.
Rozpoznáváním obrázků se rozumí úloha, kdy se do neuronové sítě vloží obrázek a ta pro něj vypíše nějakou značku. Značka, kterou síť vypíše, bude odpovídat předem definované třídě. Může existovat více tříd, do kterých může být obrázek označen, nebo jen jedna. Pokud se jedná o jednu třídu, často se používá termín „rozpoznávání“, zatímco úloha rozpoznávání více tříd se často nazývá „klasifikace“.
Podskupinou klasifikace obrazu je detekce objektů, kdy se identifikují konkrétní případy objektů, které patří do určité třídy, například zvířata, auta nebo lidé.
Extrakce příznaků
Aby mohla neuronová síť provádět rozpoznávání/klasifikaci obrazu, musí provést extrakci příznaků. Funkce jsou prvky dat, které vás zajímají a které budou přivedeny do sítě. V konkrétním případě rozpoznávání obrazu jsou rysy skupiny pixelů, jako jsou hrany a body, objektu, které bude síť analyzovat na základě vzorů.
Rozpoznávání rysů (nebo extrakce rysů) je proces vytažení příslušných rysů ze vstupního obrazu, aby bylo možné tyto rysy analyzovat. Mnoho obrázků obsahuje anotace nebo metadata o obrázku, která síti pomáhají najít relevantní rysy.
Získání představy o tom, jak neuronová síť rozpoznává obrázky, vám pomůže při implementaci modelu neuronové sítě, proto se v několika následujících částech stručně seznámíme s procesem rozpoznávání obrázků.
Extrakce vlastností pomocí filtrů
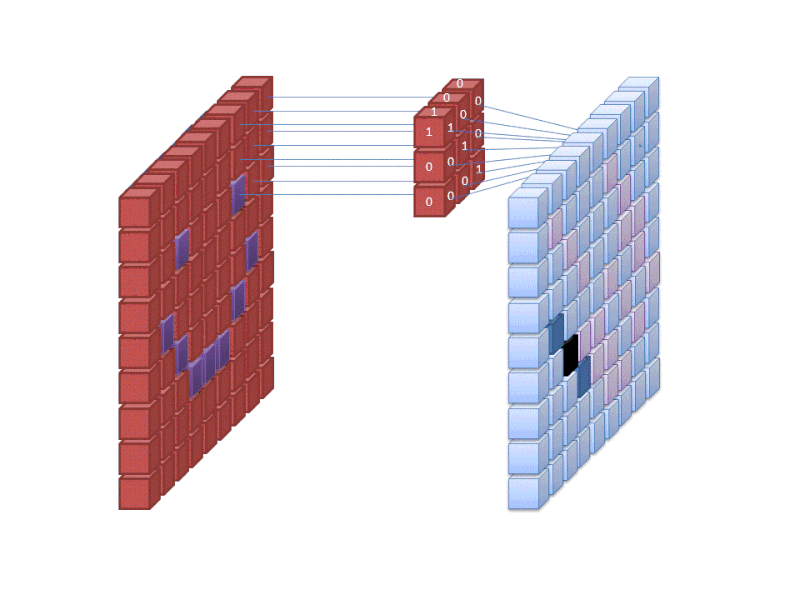
Kredit: commons.wikimedia.org
První vrstva neuronové sítě bere všechny pixely v obrázku. Poté, co jsou do sítě vložena všechna data, jsou na obraz aplikovány různé filtry, které vytvářejí reprezentace různých částí obrazu. Jedná se o extrakci rysů a vytváří se „mapy rysů“.
Tento proces extrakce rysů z obrazu se provádí pomocí „konvoluční vrstvy“ a konvoluce je jednoduše vytvoření reprezentace části obrazu. Právě z tohoto pojmu konvoluce pochází termín konvoluční neuronová síť (CNN), typ neuronové sítě, který se nejčastěji používá při klasifikaci/rozpoznávání obrazu.
Pokud si chcete představit, jak vytváření map příznaků funguje, představte si, že svítíte baterkou na obraz v tmavé místnosti. Při posouvání paprsku po obrázku se učíte o vlastnostech obrázku. Filtr je to, co síť používá k vytvoření reprezentace obrazu, a v této metafoře je filtrem světlo z baterky.
Šířka paprsku vaší baterky řídí, jak velkou část obrazu zkoumáte najednou, a neuronové sítě mají podobný parametr, velikost filtru. Velikost filtru ovlivňuje, jak velká část obrazu, kolik pixelů, je zkoumána najednou. Běžná velikost filtru používaná v sítích CNN je 3 a pokrývá výšku i šířku, takže filtr zkoumá oblast pixelů 3 x 3.
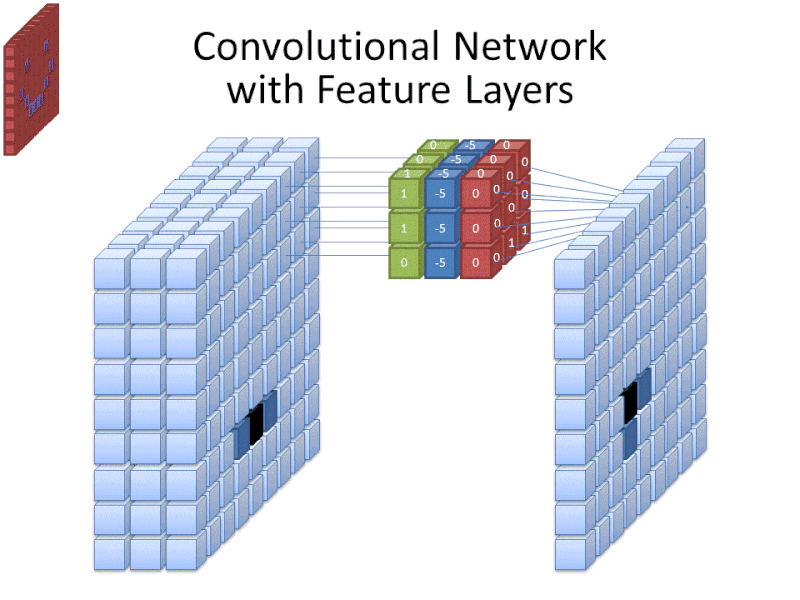
Kredit: commons.wikimedia.org
Když velikost filtru pokrývá výšku a šířku filtru, je třeba zadat také jeho hloubku.
Jak má 2D obrázek hloubku?“
Digitální obrázky se vykreslují jako výška, šířka a nějaká hodnota RGB, která definuje barvy pixelu, takže sledovaná „hloubka“ je počet barevných kanálů, které obrázek má. Obrázky ve stupních šedi (nebarevné) mají pouze 1 barevný kanál, zatímco barevné obrázky mají 3 hloubkové kanály.
To vše znamená, že pro filtr velikosti 3 aplikovaný na plnobarevný obrázek budou rozměry tohoto filtru 3 x 3 x 3. Pro každý pixel pokrytý tímto filtrem síť vynásobí hodnoty filtru s hodnotami v samotných pixelech a získá číselnou reprezentaci daného pixelu. Tento proces se pak provede pro celý obraz, aby se dosáhlo úplné reprezentace. Filtr se pohybuje po zbytku obrazu podle parametru nazvaného „krok“, který určuje, o kolik pixelů se má filtr posunout poté, co vypočítá hodnotu ve své aktuální pozici. Běžná velikost kroku pro CNN je 2.
Konečným výsledkem všech těchto výpočtů je mapa prvků. Tento proces se obvykle provádí s více než jedním filtrem, což pomáhá zachovat složitost obrazu.
Aktivační funkce
Po vytvoření mapy rysů obrazu jsou hodnoty, které reprezentují obraz, předány aktivační funkci neboli aktivační vrstvě. Aktivační funkce přebírá hodnoty, které reprezentují obraz a které jsou díky konvoluční vrstvě v lineární podobě (tj. pouze seznam čísel), a zvyšuje jejich nelinearitu, protože obrazy samy o sobě jsou nelineární.
Typickou aktivační funkcí, která se k tomuto účelu používá, je rektifikovaná lineární jednotka (ReLU), ačkoli občas se používají i jiné aktivační funkce (o těch si můžete přečíst zde).
Sdružovací vrstvy
Po aktivaci se data posílají přes sdružovací vrstvu. Pooling „zmenšuje“ obrázek, což znamená, že vezme informace, které obrázek reprezentují, a zkomprimuje je, čímž je zmenší. Proces sdružování činí síť pružnější a zdatnější v rozpoznávání objektů/obrazů na základě relevantních rysů.
Když se díváme na obrázek, obvykle nás nezajímají všechny informace na pozadí obrázku, ale pouze rysy, které nás zajímají, například lidé nebo zvířata.
Podobně i sdružovací vrstva v síti CNN bude abstrahovat nepotřebné části obrazu a ponechá si pouze ty části obrazu, které považuje za relevantní, což je řízeno zadanou velikostí sdružovací vrstvy.
Protože se musí rozhodovat o nejrelevantnějších částech obrazu, je naděje, že se síť naučí pouze ty části obrazu, které skutečně představují daný objekt. To pomáhá zabránit nadměrnému přizpůsobení, kdy se síť naučí aspekty trénovacího případu příliš dobře a nedokáže zobecnit na nová data.
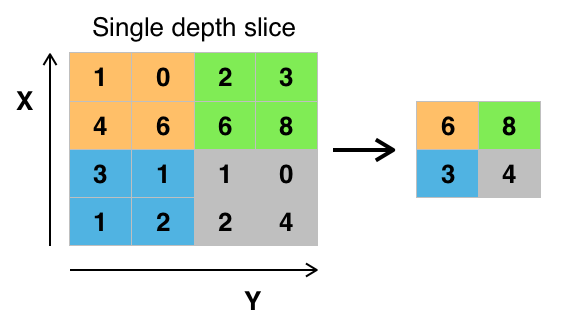
Kredit: commons.wikimedia.org
Existují různé způsoby sdružování hodnot, ale nejčastěji se používá maximální sdružování. Max pooling získá maximální hodnotu pixelů v rámci jednoho filtru (v rámci jednoho místa na obrázku). Tím odpadnou 3/4 informace za předpokladu, že jsou použity 2 x 2 filtry.
Maximální hodnoty pixelů se používají proto, aby se zohlednilo možné zkreslení obrazu, a parametry/velikost obrazu se zmenšují, aby se kontrolovalo nadměrné přizpůsobení. Existují i jiné typy sdružování, například sdružování průměrných hodnot nebo sdružování součtů, ale ty se nepoužívají tak často, protože sdružování maximálních hodnot obvykle přináší lepší přesnost.
Zplošťování
Závěrečné vrstvy naší sítě CNN, hustě propojené vrstvy, vyžadují, aby data byla ve formě vektoru, který má být zpracován. Z tohoto důvodu musí být data „zploštěna“. Hodnoty jsou zkomprimovány do dlouhého vektoru nebo sloupce postupně uspořádaných čísel.
Plně propojená vrstva
Závěrečné vrstvy CNN jsou hustě propojené vrstvy neboli umělá neuronová síť (ANN). Hlavní funkcí ANN je analyzovat vstupní funkce a kombinovat je do různých atributů, které pomohou při klasifikaci. Tyto vrstvy v podstatě vytvářejí kolekce neuronů, které představují různé části daného objektu, a kolekce neuronů může představovat plandavé uši psa nebo červenost jablka. Když se v reakci na vstupní obrázek aktivuje dostatečný počet těchto neuronů, obrázek bude klasifikován jako objekt.

Kredit: commons.wikimedia.org
Chybu neboli rozdíl mezi vypočtenými hodnotami a očekávanou hodnotou v trénovací množině vypočítá ANN. Síť pak prochází zpětným šířením, kdy se vypočítá vliv daného neuronu na neuron v další vrstvě a jeho vliv se upraví. To se provádí za účelem optimalizace výkonu modelu. Tento proces se pak opakuje stále dokola. Tímto způsobem se síť trénuje na datech a učí se asociace mezi vstupními funkcemi a výstupními třídami.
Neurony ve středních plně propojených vrstvách budou výstupem binárních hodnot týkajících se možných tříd. Pokud máte čtyři různé třídy (řekněme pes, auto, dům a člověk), bude mít neuron hodnotu „1“ pro třídu, kterou podle něj obrázek představuje, a hodnotu „0“ pro ostatní třídy.
Poslední plně propojená vrstva obdrží výstup vrstvy před ní a dodá pravděpodobnost pro každou z tříd, která se sečte do jedné. Pokud je v kategorii „pes“ hodnota 0,75, představuje to 75% jistotu, že na obrázku je pes.
Klasifikátor obrázků byl nyní natrénován a obrázky lze předat do sítě CNN, která nyní vyprodukuje odhad o obsahu daného obrázku.
Pracovní postup strojového učení
Než se vrhneme na příklad trénování klasifikátoru obrázků, věnujme chvíli pochopení pracovního postupu neboli pipeline strojového učení. Proces trénování modelu neuronové sítě je poměrně standardní a lze jej rozdělit do čtyř různých fází.
Příprava dat
Nejprve je třeba shromáždit data a uvést je do podoby, na které je síť může trénovat. To zahrnuje shromažďování obrázků a jejich označování. I když jste si stáhli sadu dat, kterou připravil někdo jiný, je pravděpodobné, že než ji budete moci použít k trénování, bude nutné provést předzpracování nebo přípravu. Příprava dat je sama o sobě uměním, které zahrnuje řešení takových problémů, jako jsou chybějící hodnoty, poškozená data, data ve špatném formátu, nesprávná označení atd.
V tomto článku budeme používat předzpracovanou sadu dat.
Vytvoření modelu
Vytvoření modelu neuronové sítě zahrnuje výběr různých parametrů a hyperparametrů. Musíte se rozhodnout, kolik vrstev v modelu použijete, jaká bude velikost vstupů a výstupů vrstev, jaký druh aktivačních funkcí použijete, zda použijete dropout atd.
Naučení, které parametry a hyperparametry použít, přijde časem (a spoustou studia), ale hned zpočátku existuje několik heuristických postupů, které můžete použít, abyste se rozběhli, a některými z nich se budeme zabývat během příkladu implementace.
Trénování modelu
Po vytvoření modelu jednoduše vytvoříte instanci modelu a přizpůsobíte ji tréninkovým datům. Největší pozornost při trénování modelu věnujte době, kterou trénování modelu zabere. Délku trénování sítě můžete určit zadáním počtu epoch, po které se má trénovat. Čím déle budete model trénovat, tím více se zlepší jeho výkonnost, ale příliš mnoho tréninkových epoch a hrozí riziko přílišného přizpůsobení.
Volba počtu epoch pro trénování je něco, co si osaháte, a je obvyklé ukládat váhy sítě mezi tréninky, abyste nemuseli začínat znovu, jakmile jste dosáhli určitého pokroku při trénování sítě.
Vyhodnocení modelu
Vyhodnocení modelu probíhá v několika krocích. Prvním krokem při vyhodnocování modelu je porovnání výkonu modelu s validační sadou dat, tedy sadou dat, na které model nebyl trénován. Porovnáte výkonnost modelu s touto validační sadou a analyzujete jeho výkonnost pomocí různých metrik.
Existují různé metriky pro určení výkonnosti modelu neuronové sítě, ale nejběžnější metrikou je „přesnost“, množství správně klasifikovaných obrázků vydělené celkovým počtem obrázků v datové sadě.
Po zjištění přesnosti výkonu modelu na validační sadě dat se obvykle vrátíte a síť znovu natrénujete s mírně upravenými parametry, protože je nepravděpodobné, že byste byli s výkonem sítě spokojeni hned při prvním tréninku. Budete dále upravovat parametry sítě, znovu ji trénovat a měřit její výkonnost, dokud nebudete s přesností sítě spokojeni.
Nakonec otestujete výkonnost sítě na testovací sadě. Tato testovací sada je další sada dat, kterou váš model nikdy předtím neviděl.
Možná se ptáte:
Proč se obtěžovat s testovací sadou? Pokud získáváte představu o přesnosti svého modelu, není to účel validační sady?“
Je dobré ponechat si pro testování dávku dat, kterou síť nikdy neviděla, protože veškeré úpravy parametrů, které provádíte, v kombinaci s opakovaným testováním na validační sadě mohou znamenat, že se vaše síť naučila některé zvláštnosti validační sady, které se nezobecní na data mimo vzorek.
Účelem testovací sady je tedy zkontrolovat, zda nedochází k problémům, jako je přefitování, a získat větší jistotu, že váš model je skutečně vhodný pro fungování v reálném světě.
Dosud jsme toho probrali hodně, a pokud vás všechny tyto informace poněkud zahltily, měli byste tyto pojmy vidět pohromadě v ukázkovém klasifikátoru natrénovaném na souboru dat. Podívejme se tedy na celý příklad rozpoznávání obrázků pomocí Keras, od načtení dat až po vyhodnocení.

Kredit: www.cs.toronto.edu
Na začátek budeme potřebovat sadu dat, na které budeme trénovat. V tomto příkladu budeme používat známou datovou sadu CIFAR-10. CIFAR-10 je rozsáhlá sada obrazových dat obsahující více než 60 000 obrázků představujících 10 různých tříd objektů, jako jsou kočky, letadla a auta.
Obrázky jsou plnobarevné RGB, ale jsou poměrně malé, pouze 32 x 32. Jednou ze skvělých věcí na datové sadě CIFAR-10 je, že je dodávána s předpřipraveným balíčkem Keras, takže je velmi snadné datovou sadu načíst a obrázky potřebují jen velmi málo předzpracování.
První věc, kterou bychom měli udělat, je importovat potřebné knihovny. Postupně ukážu, jak se tyto importy používají, ale zatím vězte, že budeme využívat Numpy a různé moduly spojené s Kerasem:
import numpyfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flatten, BatchNormalization, Activationfrom keras.layers.convolutional import Conv2D, MaxPooling2Dfrom keras.constraints import maxnormfrom keras.utils import np_utilsBudeme zde používat náhodný seed, abyste mohli výsledky dosažené v tomto článku zopakovat, proto potřebujeme numpy:
# Set random seed for purposes of reproducibilityseed = 21Příprava dat
Potřebujeme ještě jeden import: dataset.
from keras.datasets import cifar10Nyní načteme datovou sadu. Můžeme to udělat jednoduše tak, že určíme, do kterých proměnných chceme data načíst, a pak použijeme funkci load_data():
# loading in the data (X_train, y_train), (X_test, y_test) = cifar10.load_data()Ve většině případů bude třeba provést nějaké předzpracování dat, aby byla připravena k použití, ale protože používáme předpřipravenou datovou sadu, je třeba provést jen velmi málo předzpracování. Jednou z věcí, kterou chceme udělat, je normalizovat vstupní data.
Jsou-li hodnoty vstupních dat v příliš širokém rozmezí, může to negativně ovlivnit výkon sítě. V tomto případě jsou vstupními hodnotami pixely v obrázku, které mají hodnotu v rozmezí 0 až 255.
Pro normalizaci dat tedy můžeme jednoduše vydělit hodnoty obrázku číslem 255. V tomto případě se jedná o pixely v obrázku. Abychom to mohli provést, musíme nejprve z dat vytvořit typ float, protože v současné době jsou to celá čísla. To můžeme provést pomocí příkazu astype() Numpy a následně deklarovat, jaký typ dat chceme:
# normalize the inputs from 0-255 to between 0 and 1 by dividing by 255 X_train = X_train.astype('float32')X_test = X_test.astype('float32')X_train = X_train / 255.0X_test = X_test / 255.0Další věc, kterou budeme muset udělat, abychom data připravili pro síť, je jednorázové zakódování hodnot. Nebudu zde rozebírat specifika one-hot kódování, ale prozatím vězte, že obrázky nemohou být sítí použity tak, jak jsou, musí být nejprve zakódovány a one-hot kódování se nejlépe používá při binární klasifikaci.
Ve skutečnosti zde provádíme binární klasifikaci, protože obrázek buď patří do jedné třídy, nebo ne, nemůže spadat někam mezi. K jednorázovému kódování se používá příkaz Numpy to_categorical(). Proto jsme z Kerasu importovali funkci np_utils, protože obsahuje to_categorical().
Také musíme zadat počet tříd, které jsou v datové sadě, abychom věděli, na kolik neuronů máme poslední vrstvu zkomprimovat:
# one hot encode outputsy_train = np_utils.to_categorical(y_train)y_test = np_utils.to_categorical(y_test)class_num = y_test.shapeDospěli jsme do fáze, kdy navrhujeme model CNN. Nejprve je třeba definovat formát, který chceme pro model použít, Keras má několik různých formátů neboli blueprintů pro tvorbu modelů, ale Sequential je nejčastěji používaný, a proto jsme jej importovali z Kerasu.
Vytvoření modelu
model = Sequential()První vrstvou našeho modelu je konvoluční vrstva. Bude přijímat vstupy a spouštět na nich konvoluční filtry.
Při jejich implementaci v Kerasu musíme zadat počet kanálů/filtrů, které chceme (to je těch 32 níže), velikost filtru, který chceme (v tomto případě 3 x 3), tvar vstupu (při vytváření první vrstvy) a aktivaci a padding, které potřebujeme.
Jak již bylo zmíněno, relu je nejběžnější aktivace a padding='same' pouze znamená, že vůbec neměníme velikost obrázku:
model.add(Conv2D(32, (3, 3), input_shape=X_train.shape, padding='same'))model.add(Activation('relu'))Poznámka: Aktivace a vycpávky můžete také řetězit dohromady, například takto:
model.add(Conv2D(32, (3, 3), input_shape=(3, 32, 32), activation='relu', padding='same'))Nyní vytvoříme vrstvu s výpadkem, abychom zabránili nadměrnému přizpůsobení, která funguje tak, že náhodně eliminuje některá spojení mezi vrstvami (0 .2 znamená, že vyřadí 20 % existujících spojení):
model.add(Dropout(0.2))Můžeme zde také provést dávkovou normalizaci. Dávková normalizace normalizuje vstupy směřující do další vrstvy, čímž zajistí, že síť vždy vytvoří aktivace se stejným rozložením, jaké si přejeme:
model.add(BatchNormalization())Nyní přichází další konvoluční vrstva, ale velikost filtru se zvětšuje, aby se síť mohla učit složitější reprezentace:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))Zde je vrstva sdružování, jak již bylo řečeno dříve, pomáhá učinit klasifikátor obrazu robustnějším, aby se mohl učit relevantní vzory. Je zde také dropout a dávková normalizace:
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization())To je základní průběh první poloviny implementace CNN: Konvoluční, aktivace, dropout, pooling. Nyní vidíte, proč jsme importovali Dropout, BatchNormalization, Activation, Conv2d a MaxPooling2d.
Přesný počet konvolučních vrstev můžete měnit podle svých představ, i když každá z nich zvyšuje výpočetní náklady. Všimněte si, že s přidáváním konvolučních vrstev obvykle zvyšujete počet jejich filtrů, aby se model mohl naučit složitější reprezentaci. Pokud se vám zdá, že počty zvolené pro tyto vrstvy jsou poněkud libovolné, vězte, že obecně platí, že filtry zvyšujete postupně a doporučuje se, aby byly mocninou 2, což může poskytnout mírnou výhodu při trénování na grafickém procesoru.
Je důležité nemít příliš mnoho slučovacích vrstev, protože každé slučování zahazuje některá data. Příliš časté sdružování povede k tomu, že hustě propojené vrstvy se nebudou mít téměř co učit, až se k nim data dostanou.
Přesný počet vrstev pro sdružování se bude lišit v závislosti na prováděné úloze a je to něco, co časem poznáte. Vzhledem k tomu, že obrázky jsou zde již tak malé, nebudeme sdružovat více než dvakrát.
Tyto vrstvy můžete nyní opakovat, aby vaše síť měla k dispozici více reprezentací pro práci:
model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Conv2D(128, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())Po dokončení konvolučních vrstev potřebujeme Flatten data, což je důvod, proč jsme výše importovali funkci. Znovu také přidáme vrstvu výpadku:
model.add(Flatten())model.add(Dropout(0.2))Nyní využijeme import Dense a vytvoříme první hustě propojenou vrstvu. Musíme zadat počet neuronů v hustě propojené vrstvě. Všimněte si, že počty neuronů v následujících vrstvách se snižují, až se nakonec přiblíží stejnému počtu neuronů, kolik je tříd v souboru dat (v tomto případě 10). Omezení jádra může při učení regulovat data, což je další věc, která pomáhá zabránit nadměrnému přizpůsobení. Proto jsme dříve importovali maxnorm.
model.add(Dense(256, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization()) model.add(Dense(128, kernel_constraint=maxnorm(3)))model.add(Activation('relu'))model.add(Dropout(0.2))model.add(BatchNormalization())V této poslední vrstvě předáváme počet tříd pro počet neuronů. Každý neuron reprezentuje jednu třídu a výstupem této vrstvy bude vektor 10 neuronů, přičemž každý neuron bude uchovávat určitou pravděpodobnost, že daný obrázek patří do třídy, kterou reprezentuje.
Nakonec aktivační funkce softmax vybere jako svůj výstup neuron s nejvyšší pravděpodobností, čímž bude hlasovat, že obrázek patří do dané třídy:
model.add(Dense(class_num))model.add(Activation('softmax'))Teď, když jsme navrhli model, který chceme použít, stačí ho zkompilovat. Zadáme počet epoch, po které chceme trénovat, a také optimalizátor, který chceme použít.
Optimalizátor je to, co vyladí váhy v síti tak, aby se blížily bodu nejnižší ztráty. Algoritmus Adam je jedním z nejčastěji používaných optimalizátorů, protože poskytuje skvělý výkon u většiny problémů:
epochs = 25optimizer = 'adam'Nyní sestavíme model s námi zvolenými parametry. Zadejme také metriku, kterou chceme použít.
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=)Můžeme vytisknout souhrn modelu, abychom viděli, jak celý model vypadá.
print(model.summary())Vytisknutí souhrnu nám poskytne poměrně dost informací:
Results: Layer (type) Output Shape Param #=================================================================conv2d_1 (Conv2D) (None, 32, 32, 32) 896_________________________________________________________________activation_1 (Activation) (None, 32, 32, 32) 0_________________________________________________________________dropout_1 (Dropout) (None, 32, 32, 32) 0_________________________________________________________________batch_normalization_1 (Batch (None, 32, 32, 32) 128_________________________________________________________________conv2d_2 (Conv2D) (None, 32, 32, 64) 18496_________________________________________________________________activation_2 (Activation) (None, 32, 32, 64) 0_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 16, 16, 64) 0_________________________________________________________________dropout_2 (Dropout) (None, 16, 16, 64) 0_________________________________________________________________batch_normalization_2 (Batch (None, 16, 16, 64) 256_________________________________________________________________conv2d_3 (Conv2D) (None, 16, 16, 64) 36928_________________________________________________________________activation_3 (Activation) (None, 16, 16, 64) 0_________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 8, 8, 64) 0_________________________________________________________________dropout_3 (Dropout) (None, 8, 8, 64) 0_________________________________________________________________batch_normalization_3 (Batch (None, 8, 8, 64) 256_________________________________________________________________conv2d_4 (Conv2D) (None, 8, 8, 128) 73856_________________________________________________________________activation_4 (Activation) (None, 8, 8, 128) 0_________________________________________________________________dropout_4 (Dropout) (None, 8, 8, 128) 0_________________________________________________________________batch_normalization_4 (Batch (None, 8, 8, 128) 512_________________________________________________________________flatten_1 (Flatten) (None, 8192) 0_________________________________________________________________dropout_5 (Dropout) (None, 8192) 0_________________________________________________________________dense_1 (Dense) (None, 256) 2097408_________________________________________________________________activation_5 (Activation) (None, 256) 0_________________________________________________________________dropout_6 (Dropout) (None, 256) 0_________________________________________________________________batch_normalization_5 (Batch (None, 256) 1024_________________________________________________________________dense_2 (Dense) (None, 128) 32896_________________________________________________________________activation_6 (Activation) (None, 128) 0_________________________________________________________________dropout_7 (Dropout) (None, 128) 0_________________________________________________________________batch_normalization_6 (Batch (None, 128) 512_________________________________________________________________dense_3 (Dense) (None, 10) 1290_________________________________________________________________activation_7 (Activation) (None, 10) 0=================================================================Total params: 2,264,458Trainable params: 2,263,114Non-trainable params: 1,344Nyní se dostaneme k trénování modelu. K tomu stačí zavolat funkci fit() na modelu a předat jí zvolené parametry.
Tady použiji zvolený seed pro účely reprodukovatelnosti.
numpy.random.seed(seed)model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=epochs, batch_size=64)Budeme trénovat na 50000 vzorcích a ověřovat na 10000 vzorcích.
Spuštěním této části kódu získáme:
Epoch 1/2564/50000 - ETA: 16:57 - loss: 3.1479 - acc: 0.0938128/50000 - ETA: 10:12 - loss: 3.0212 - acc: 0.0938192/50000 - ETA: 7:57 - loss: 2.9781 - acc: 0.1250256/50000 - ETA: 6:48 - loss: 2.8830 - acc: 0.1484320/50000 - ETA: 6:07 - loss: 2.8878 - acc: 0.1469384/50000 - ETA: 5:40 - loss: 2.8732 - acc: 0.1458448/50000 - ETA: 5:20 - loss: 2.8842 - acc: 0.1406.........49664/50000 - ETA: 1s - loss: 1.5160 - acc: 0.461149728/50000 - ETA: 1s - loss: 1.5157 - acc: 0.461249792/50000 - ETA: 1s - loss: 1.5153 - acc: 0.461449856/50000 - ETA: 0s - loss: 1.5147 - acc: 0.461549920/50000 - ETA: 0s - loss: 1.5144 - acc: 0.461749984/50000 - ETA: 0s - loss: 1.5141 - acc: 0.461750000/50000 - 262s 5ms/step - loss: 1.5140 - acc: 0.4618 - val_loss: 1.0715 - val_acc: 0.6195End of Epoch 1Všimněte si, že ve většině případů byste chtěli mít validační množinu, která se liší od testovací množiny, a proto byste zadali procento trénovacích dat, které použijete jako validační množinu. V tomto případě pouze předáme testovací data, abychom se ujistili, že testovací data jsou odložena stranou a netrénují se na nich. V tomto příkladu budeme mít pouze testovací data, aby to bylo jednoduché.
Nyní můžeme model vyhodnotit a zjistit, jak si vedl. Stačí zavolat model.evaluate():
# Model evaluationscores = model.evaluate(X_test, y_test, verbose=0)print("Accuracy: %.2f%%" % (scores*100))A přivítá nás výsledek:
Accuracy: 83.01%A je to! Nyní máme natrénovanou CNN pro rozpoznávání obrazu. Na první spuštění to není špatné, ale pravděpodobně byste si chtěli pohrát se strukturou a parametry modelu a zjistit, zda nemůžete dosáhnout lepšího výkonu.
Závěr
Teď, když jste implementovali svou první síť pro rozpoznávání obrazu v Kerasu, by bylo dobré pohrát si s modelem a zjistit, jak změna jeho parametrů ovlivňuje jeho výkon.
To vám dá určitou intuici o nejlepší volbě různých parametrů modelu. Měli byste si při tom také přečíst informace o různých volbách parametrů a hyperparametrů. Jakmile se s nimi seznámíte, můžete zkusit implementovat vlastní klasifikátor obrázků na jiném souboru dat.
Pokud si chcete s kódem pohrát nebo ho prostě jen hlouběji prostudovat, projekt je nahrán na GitHubu!
.