
Dělám tu a tam spoustu projektů souvisejících s Twitchem, zkouším, jaké jsou možnosti. Jeden z mých posledních projektů zahrnoval vytvoření rozšíření Twitch Emote Extension pro Chrome, kde jsem ukázal, jak zdarma získat další „sloty“ pro emoty. To mě přivedlo k rozšířením pro prohlížeče, a tak jsem si řekl, že si ukážeme, jak vytvořit jedno od základu, a to vytvořením filtru sprostých slov pro chat na Twitchi.
Na konci chceme mít rozšíření, které po instalaci zkontroluje sadu označených slov v chatu a nahradí je přívětivějšími verzemi. To by se mohlo hodit například dětem při sledování streamů.
Pokud chcete jen kód tohoto rozšíření, na konci článku najdete odkaz na konečný výsledek.
Dobře, tak se do toho pustíme po hlavě. Vytvořte si někde složku a nazvěte ji profanity-filter. Já jsem tu svou vytvořil na místě, kde se synchronizuji s GitHubem.

Nyní uvnitř této složky vytvořte dva nové soubory: manifest.json a content.js. Uvidíte, jak je budeme používat, až se dostaneme k vytváření rozšíření.
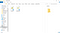
Otevřete manifest.json, což je soubor, ve kterém Google hledá metadata týkající se vašeho rozšíření, a vložte do něj následující:
{ "manifest_version": 2, "name": "Twitch Profanity Filter Extension", "version": "0.1", "content_scripts": , "js": } ]}
Jak vidíte, říkáme Googlu, že toto rozšíření by mělo fungovat na jakékoli stránce z Twitche, a také říkáme, že logika, která by se měla na těchto stránkách spouštět, se nachází v souboru nazvaném content.js. Všimněte si, že jsem uvedl verzi 0.1, protože se jedná o můj první pokus.
Zadání logiky
Nyní otevřete soubor content.js ve vámi zvoleném textovém editoru. Vřele doporučuji Visual Studio Code, je to můj textový editor pro vše, co souvisí s kódováním, a je zdarma.
Nyní to nastavíme v několika krocích. Čeho chceme dosáhnout a jak toho dosáhneme? Víme, že chceme změnit určitá slova na jiná, což znamená číst zprávy chatu, skenovat je a hledat v nich označená slova a pak tato slova aktualizovat na přívětivější. Po načtení stránky tedy chceme, aby naše logika dokázala provést následující:
- Najít chatovací pole
- Při každé nové chatovací zprávě získat zprávu nebo kontejner se zprávami
- Změnit označená slova na jejich přátelské protějšky
Přejděme tedy k tomu. První částí je vlastně aktivace skriptu po načtení stránky, přesněji řečeno okna. V javascriptu se můžete připojit k této události načítání a my to právě uděláme. Aktualizujte svůj content.js tak, aby obsahoval následující:
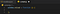
To zajistí, že cokoli vložíme dovnitř této funkce, bude zavoláno, jakmile se stránka načte.
Najít chatbox
Jak tedy najdeme chatbox? No, ve verzi Chrome webové stránky Twitch je chatbox obsažen v elementu <div>, který má třídu chat-scrollable-area__message-container. Tento prvek neboli uzel získáme pomocí javascriptu. Aktualizujte soubor tak, aby vypadal takto:

Důvod, proč za něj přidáme .item(0), je ten, že funkce getElementsByClassName() vrací pole prvků. Protože víme, že tuto třídu má pouze jeden prvek, vezmeme ho z pole tak, že určíme, že chceme první věc (většina programovacích jazyků začíná počítat od 0).
Získat každou novou zprávu v chatu
Toto je trochu složitější na pochopení, pokud nejste zvyklí programovat nebo nejste zvyklí na vzory pozorovatelů. Každou novou zprávu získáme tak, že na uzlu chatboxu, který jsme právě vyzvedli, použijeme MutationObserver. Aktualizujte soubor tak, aby odpovídal následujícímu, a pak si projdeme, co se děje:
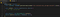
Nejprve na řádku 4 definujeme funkci zpětného volání, která přebírá seznam mutací a pozorovatele, kterého vytvoříme na řádku 8. Na řádku 9 definujeme funkci zpětného volání, která přebírá seznam mutací. Logika této funkce je to, co se zavolá vždy, když se v pozorovaném uzlu něco změní nebo zmutuje.
Na řádku 8 vytvoříme pozorovatele a předáme mu naši funkci zpětného volání. Poté na řádku 9 řekneme pozorovateli, aby začal pozorovat náš cílový uzel, a předáme mu konfiguraci, která říká, že nás zajímají pouze mutace seznamu dětí. Zprávy se zobrazují jako podřízené uzly v uzlu chatbox, který sledujeme, takže naše funkce zpětného volání se spustí pokaždé, když se objeví nová zpráva chatu. To je přesně to, co chceme!
Nyní však ještě potřebujeme získat skutečné prvky zpráv a za tímto účelem přidáme do našeho zpětného volání ještě jeden řádek kódu:
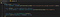
Název se může zdát trochu zvláštní, ale všechny textové části zprávy (neskenujeme emoty, jen skutečné texty) jsou umístěny v <span> elementech HTML, které mají třídu text-fragment. Protože se tato funkce spouští při každé nové zprávě, víme také, že zpráva, kterou chceme, musí být posledním prvkem v uzlu chatboxu, takže proto chytáme lastElementChild.
Změnit označená slova na jejich přátelské protějšky
Přejděme k tomu nejšťavnatějšímu. Pokud chceme měnit označená slova, potřebujeme nejprve něco, co nám řekne, jaká jsou označená slova a jejich protějšky. K tomu nám poslouží jednoduchý slovník. Aktualizujte soubor tak, aby vypadal takto:
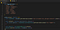
Nyní budeme číst aktuální text ve všech elementech text-fragment, projdeme smyčkou všechna zakázaná slova a případně je nahradíme. Spusťme tuto smyčku, takže aktualizujte svou funkci zpětného volání následujícím způsobem:

Děje se zde to, že procházíme všechny tyto prvky, které obsahují text. Na řádku 18 bereme postupně jeden konkrétní prvek a na řádku 19 z něj získáváme aktuální text malými písmeny, protože naše označená slova jsou také všechna malými písmeny. Je to jednodušší pro účely porovnávání, ale v pokročilejší verzi bychom se postarali o úhledné zachování velkých písmen. Nyní, když máme náš text, chceme projít smyčkou naše označená slova a zkontrolovat, zda jsou přítomna. Pokud ano, odstraníme je. Aktualizujte funkci:

Slovník, který jsme vytvořili, pracuje s dvojicemi klíč-hodnota, kde klíče jsou příznaková slova a hodnoty jsou přívětivá slova, takže na řádku 21 jednoduše získáme pole všech klíčů, což je pole příznakových slov, která chceme procházet. Ve smyčce uchopíme příznakové slovo, na které se právě díváme, a pokud náš text obsahuje jedno nebo více z nich, uchopíme přátelské slovo a aktualizujeme náš text nahrazením příznakových slov. To je téměř vše, nyní stačí vzít náš nový a vylepšený text a vložit jej zpět do elementu, ze kterého jsme jej uchopili:

Na řádku 31 jsme nyní vložili text zpět do elementu a je to! Přejděme k testování v prohlížeči Chrome.
Test
Otevřete Chrome a přejděte na adresu chrome://extensions. Měli byste vidět svá rozšíření a v pravém horním rohu uvidíte režim pro vývojáře. Pokud ještě není, zapněte jej. Poté v pravém horním rohu uvidíte možnost Načíst rozbalené. Tu použijeme k načtení našeho místního rozšíření, aniž bychom zatím museli procházet cestou webového obchodu Chrome. Klikněte na ni a vyberte složku, kde se nacházejí soubory:
Tím by se mělo okamžitě objevit v našem seznamu rozšíření:
Dobře! Nyní přejděme na libovolný kanál, kde si můžeme popovídat. Půjdu na kanál svého kamaráda Bjarkeho, povedeného dánského streamera, a vyzkouším to:

Tady to funguje! Náš vlastní filtr sprostých slov. Nebylo to tak těžké, že? Zbývá ho jen uvolnit do webového obchodu Chrome, pokud chcete. Tento seznam slov budu rozšiřovat a uvolňovat, takže pokud nepotřebujete víc než toto, nemusíte to uvolňovat, vzhledem k tomu, že to vyžaduje poplatek za vstup do programu. Nebudu se zabývat tím, jak uvolnění funguje, ale pokud vás to zajímá, vytvořil jsem rozšíření Twitch Emote Extension, které vám umožní získat vlastní neomezené sloty pro emoty, a na konci tohoto článku je vysvětleno, jak uvolnit rozšíření.
Pokud chcete vidět celý kód tohoto rozšíření, podívejte se na repozitář GitHub zde. Veselé kódování!